端侧部署福利!具身大模型在精度、效率的平衡矛盾被Co-Design Scaling Laws解决了
该研究的核心价值不仅在于实现了端侧 LLM 架构设计的效率与性能突破,更在于首次提出了可落地的端侧 LLM 硬件协同设计定律,构建了 “架构超参数-模型精度-硬件性能” 的统一建模框架,实现了从 “经验式设计” 到 “原理性优化” 的范式转变。建模跨越:首次将损失定律与 Roofline 硬件建模结合,实现了精度-延迟的显性映射,为多约束优化奠定基础;搜索跨越:提出 PLAS 框架,将架构搜索转化
在自动驾驶、移动机器人等具身智能系统的端侧部署赛道中,大语言模型(LLM)始终受困于精度-延迟的双重矛盾——云端优化的模型在边缘设备上要么因高延迟无法满足实时需求,要么因精度妥协丧失任务能力。来自理想汽车、国创决策智能等机构的研究团队提出了基于 Roofline 建模的端侧 LLM 硬件协同设计定律,创新性地将模型损失定律与硬件性能建模结合,构建了精度-延迟的帕累托前沿分析框架,实现了从 “经验式架构选择” 到 “原理性硬件-模型协同优化” 的范式转变,让端侧 LLM 架构设计周期从数月缩短至数天,为资源受限场景下的 LLM 部署提供了全新技术路径。
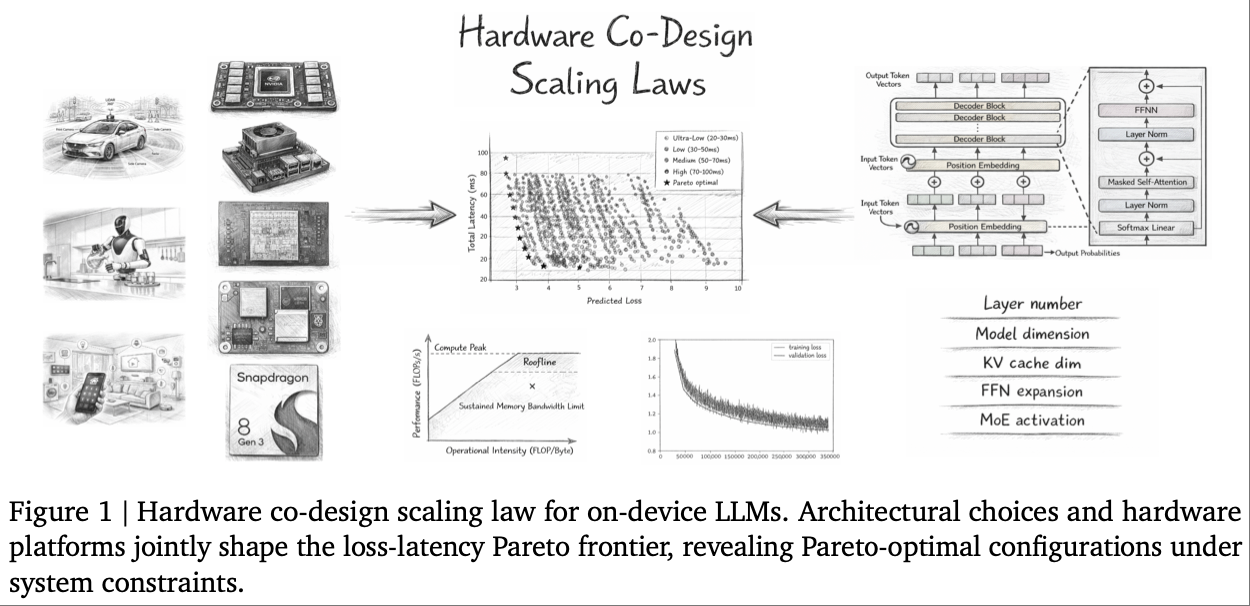
- 论文标题:Hardware Co-Design Scaling Laws via Roofline Modeling for On-Device LLMs
- 作者团队:理想汽车 & 国创决策智能技术研究所
- 论文地址:https://www.arxiv.org/abs/2602.10377
痛点直击:端侧 LLM 部署的三大核心困境
现有端侧 LLM 部署方案多为 “云端模型裁剪+硬件适配” 的被动模式,未从底层实现模型与硬件的协同设计,核心痛点集中在三方面:
| 痛点类型 | 具体表现 | 核心影响 |
|---|---|---|
| 架构-硬件错配 | Transformer 的注意力层受带宽限制、前馈层受计算限制,KV 缓存占用片上内存,模型深度 / 宽度的朴素缩放与硬件特性严重不匹配 | 推理性能远低于硬件理论峰值,算力 / 带宽资源利用率低 |
| 设计效率低下 | 依赖穷举式架构搜索与实测,需对数千种候选架构进行训练和基准测试,时间与计算成本极高 | 无法快速适配不同边缘硬件平台,规模化部署受限 |
| 多目标优化失衡 | 传统神经架构搜索(NAS)仅优化精度单目标,难以在严格的延迟 / 内存约束下平衡精度与效率 | 易出现 “精度达标但延迟超预算” 或 “延迟满足但精度不足” 的问题 |
**核心问题总结:**端侧 LLM 部署缺乏统一的硬件-软件协同建模框架,未建立 “架构超参数-模型损失-推理延迟” 的显性映射关系,无法实现多约束下的最优架构选择。
硬核拆解:Co-Design Scaling Laws的四大核心创新
该研究围绕建模-搜索-优化-验证形成全链路突破,首次提出可落地的端侧 LLM 硬件协同设计定律,核心是通过损失定律建模精度、Roofline 建模刻画延迟,并构建帕累托前沿实现双目标联合优化,每个模块都精准破解传统方案的短板。
核心框架:精度-延迟双建模的协同设计范式
研究摒弃了 “先设计模型,后硬件适配” 的传统思路,构建了以Roofline 模型为基础的硬件-模型协同设计框架,实现架构超参数与硬件性能的深度绑定,整体框架如图3所示。
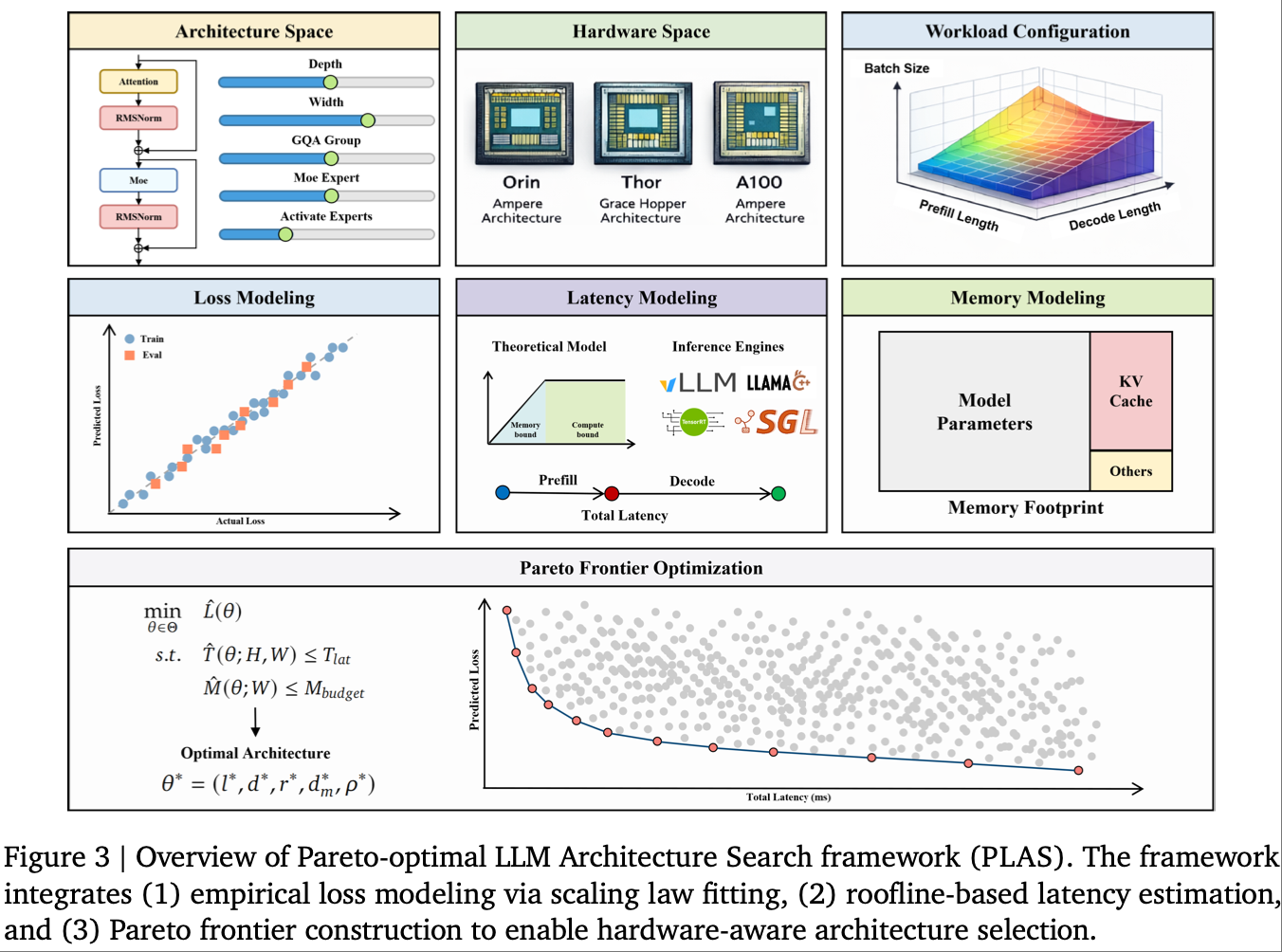
-
双建模核心逻辑:
精度建模(损失定律):将模型验证损失显式建模为架构超参数(层数、维度、KV 缓存维度、FFN 扩展比、MoE 激活率)的可分离函数,通过大量实验拟合出损失预测公式,实现从架构参数到模型精度的直接预测;
性能建模(Roofline 延迟分析):基于 Roofline 模型刻画硬件的计算-带宽瓶颈,将推理延迟分解为预填充(Prefill)和解码(Decode)两个阶段,推导出具身的延迟计算公式,实现从架构参数到推理延迟的精准估计。
-
联合优化目标:在固定硬件约束下,将端侧 LLM 架构设计转化为带约束的损失最小化问题,数学表达为:
min θ ∈ Θ L ( θ ) s.t. T ( θ ; H , W ) ≤ T lat , M ( θ ; W ) ≤ M budget \min_{\theta \in \Theta} \mathcal{L}(\theta) \quad \text{s.t.} \quad T(\theta; H, W) \leq T_{\text{lat}},\quad M(\theta; W) \leq M_{\text{budget}} minθ∈ΘL(θ)s.t.T(θ;H,W)≤Tlat,M(θ;W)≤Mbudget
其中 θ = ( l , d , d m , r , ρ ) \theta = (l, d, d_m, r, \rho) θ=(l,d,dm,r,ρ)为模型架构超参数, T ( θ ; H , W ) T(\theta; H, W) T(θ;H,W)为 Roofline 建模的推理延迟, M ( θ ; W ) M(\theta; W) M(θ;W)为内存消耗,通过该目标实现精度与效率的协同优化。
关键建模:损失定律与 Roofline 延迟的显性表达
精度建模:多维度架构超参数的损失拟合
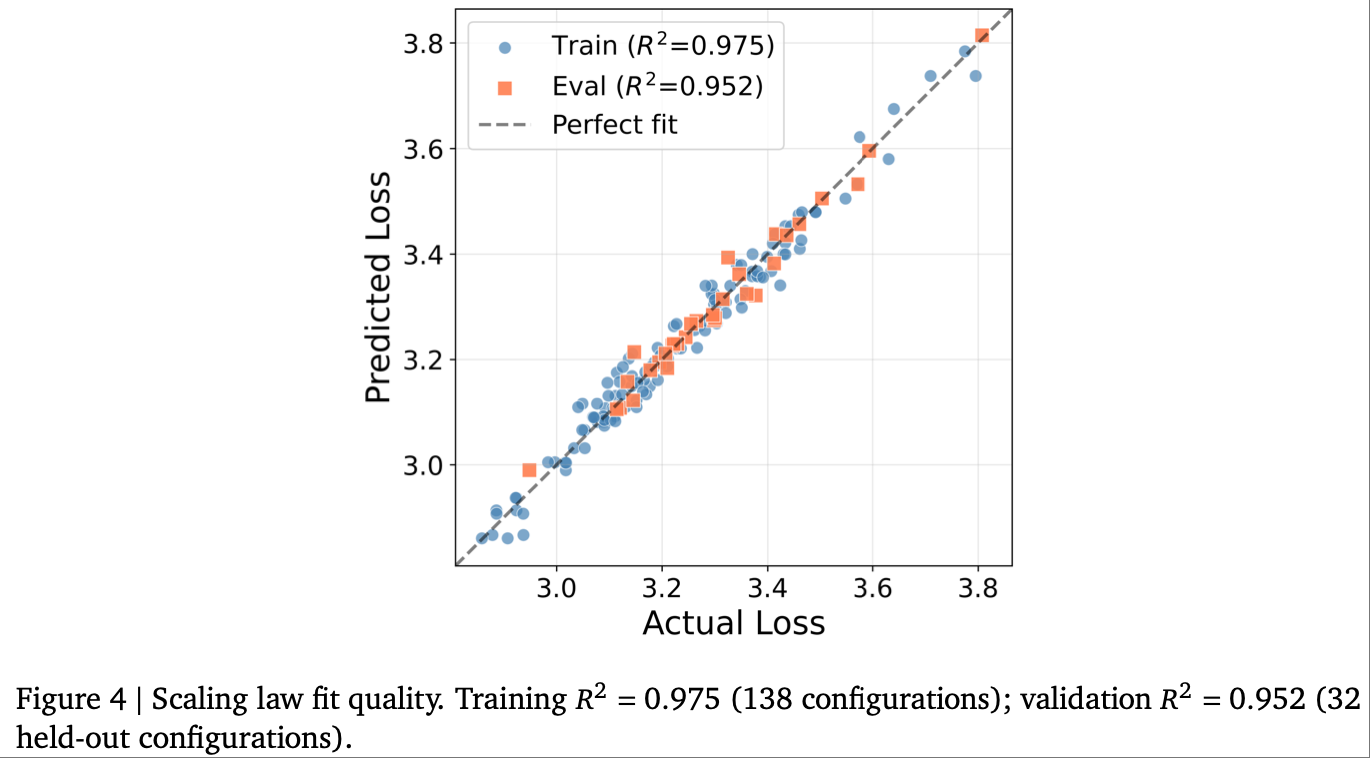
研究通过训练 170 种涵盖稠密 / 稀疏(MoE)的 Transformer 架构(各训练 100 亿 token),拟合出显性的损失预测公式,突破了传统定律仅考虑参数量的局限,覆盖层数、宽度、MoE 激活率、FFN 扩展比、KV 缓存维度等核心架构参数:
L ^ ( θ ) = κ l l α l + κ ρ ⋅ ρ α ρ r α r d β 1 + κ d r α r d β 2 + κ m d m α m + L ∞ \hat{\mathcal{L}}(\theta) = \frac{\kappa_l}{l^{\alpha_l}} + \frac{\kappa_\rho \cdot \rho^{\alpha_\rho}}{r^{\alpha_r} d^{\beta_1}} + \frac{\kappa_d}{r^{\alpha_r} d^{\beta_2}} + \frac{\kappa_m}{d_m^{\alpha_m}} + \mathcal{L}_\infty L^(θ)=lαlκl+rαrdβ1κρ⋅ραρ+rαrdβ2κd+dmαmκm+L∞
该公式将损失分解为层数项、稀疏-宽度项、容量项、KV 缓存项和不可约损失,拟合结果在训练集上 R 2 = 0.975 R^2=0.975 R2=0.975、验证集上 R 2 = 0.952 R^2=0.952 R2=0.952,实现了对模型损失的高精度预测,无需对每个候选架构进行全量训练。
性能建模:Roofline 驱动的端到端延迟推导
基于 Roofline 模型的计算-带宽瓶颈判定(延迟取 “计算耗时” 与 “内存访问耗时” 的最大值),将 LLM 推理延迟拆分为预填充和解码两个阶段,推导出端到端延迟公式:
T ^ θ = T total ( S in , S out ) = l ⋅ T layer pre ( S in ) + ∑ s = 1 S out l ⋅ T layer dec ( S + S in ) \hat{T}_\theta = T_{\text{total}}(S_{\text{in}}, S_{\text{out}}) = l \cdot T_{\text{layer}}^{\text{pre}}(S_{\text{in}}) + \sum_{s=1}^{S_{\text{out}}} l \cdot T_{\text{layer}}^{\text{dec}}(S + S_{\text{in}}) T^θ=Ttotal(Sin,Sout)=l⋅Tlayerpre(Sin)+∑s=1Soutl⋅Tlayerdec(S+Sin)
其中,预填充阶段受计算限制(注意力层O(S2)复杂度),解码阶段受内存带宽限制(权重反复从片外内存加载),该模型能精准捕捉不同架构超参数、硬件特性(峰值算力、持续带宽)和工作负载(批次、序列长度)对延迟的影响,支持 5 万 + 架构配置在 20 分钟内完成延迟评估。
架构搜索:帕累托最优的 PLAS 框架
研究提出PLAS(Pareto-optimal LLM Architecture Search) 框架,将架构搜索转化为帕累托前沿分析,解决了多目标优化下的最优架构选择问题:
帕累托最优定义:一个架构 θ ∗ \theta^* θ∗为帕累托最优,当且仅当不存在其他架构 θ \theta θ,使得 L ( θ ) ≤ L ( θ ⋆ ) ∧ T ( θ ; H , W ) ≤ T ( θ ⋆ ; H , W ) \mathcal{L}(\theta) \leq \mathcal{L}(\theta^\star) \land T(\theta; H, W) \leq T(\theta^\star; H, W) L(θ)≤L(θ⋆)∧T(θ;H,W)≤T(θ⋆;H,W)(至少一个严格成立),所有帕累托最优架构构成精度-延迟帕累托前沿;
前沿构建策略:采用拉丁超立方抽样初始化架构集,通过迭代采样帕累托前沿的稀疏区域和邻域实现精细化搜索,直至前沿稳定;
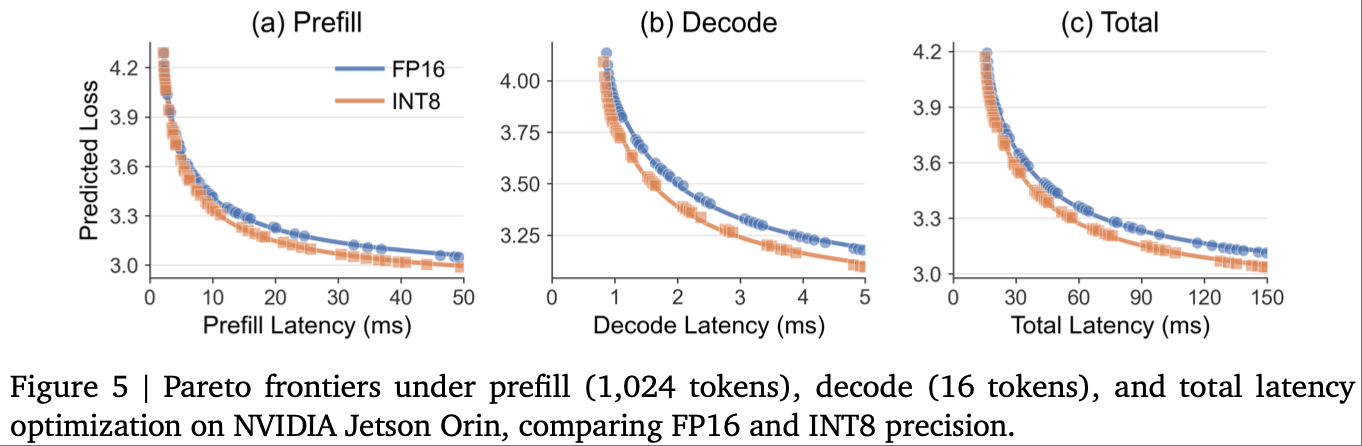
量化协同优化:对比 FP16 和 INT8 精度下的帕累托前沿,如图 5 所示,发现 INT8 量化能显著降低延迟,但因非线性操作(Softmax、层归一化)无法量化,提速效果低于理论 2 倍,为量化与架构的协同优化提供了方向。
理论升华:硬件约束下的最优架构解析解
在实证搜索的基础上,研究进一步推导出不同硬件约束下架构超参数的解析解,实现了从 “实证搜索” 到 “原理性优化” 的跨越,核心针对三类典型约束场景:
仅延迟约束:最优 MoE 激活率 ρ ∗ = ρ m i n ρ^∗=ρ_{min} ρ∗=ρmin(最大化稀疏性),因为稀疏性不增加每 token 计算量,却能提升模型容量,是 “无成本的精度提升”;
仅内存约束:推导出宽度-稀疏性定律 ρ ∗ ∝ d ( β 1 − β 2 ) / α ρ ρ^*\propto d^{(\beta_1−\beta_2)/\alpha ρ} ρ∗∝d(β1−β2)/αρ,即模型宽度翻倍时,激活率需降低约 2.3 倍,为内存受限下的稀疏性分配提供了定量准则;
延迟-内存双约束:分预填充 + 内存、解码 + 内存两种子场景,推导出激活率、层数、FFN 扩展比、GQA(分组查询注意力)的解析公式,揭示了硬件约束对架构参数的定量影响。
实验验证:NVIDIA Jetson Orin 上的全方位性能突破
研究在NVIDIA Jetson Orin(典型边缘 AI 硬件)上完成了全面验证,对 1942 种候选架构进行基准测试,核心围绕架构搜索效率、精度-延迟 trade-off、实际任务性能三大维度展开,对比基线为工业级轻量模型 Qwen2.5-0.5B。
核心实验结果与深度分析
架构搜索效率:从数月缩短至数天
传统穷举式架构搜索需对数千种架构进行全量训练和实测,周期长达数月;而基于该研究的损失定律 + Roofline 延迟建模,仅需训练 170 种代表性架构拟合模型,后续通过理论预测即可完成帕累托前沿构建,架构选择周期从数月缩短至数天,计算成本降低 90% 以上。
精度-延迟 trade-off:帕累托前沿的最优架构特征
通过帕累托前沿分析,发现端侧 LLM 的最优架构存在显著的共性特征,与云端 LLM 的 “深而窄” 设计形成鲜明对比:
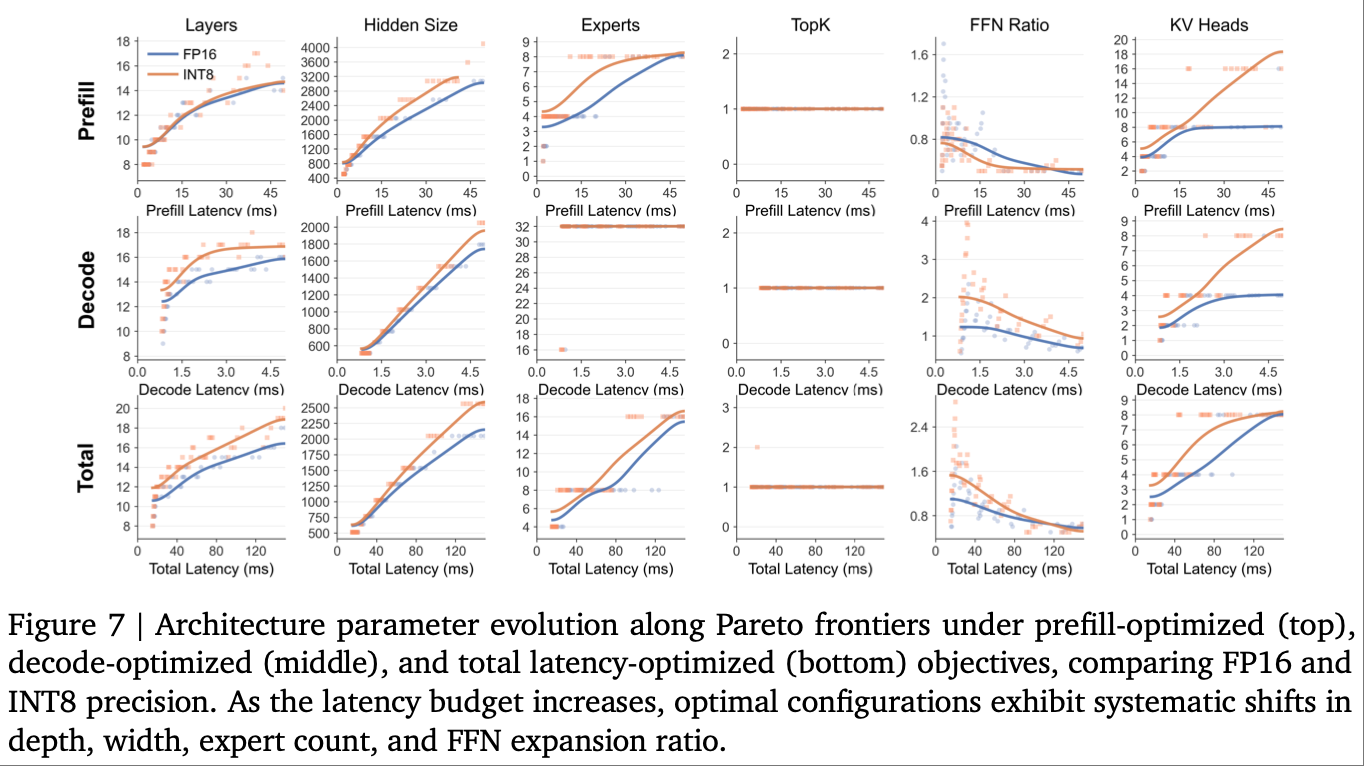
- MoE 稀疏架构占主导:100% 的帕累托最优架构为 MoE 稀疏模型,在 batch=1 的端侧场景下,MoE 能在保持每 token 计算量不变的前提下提升模型容量,实现更优的精度-效率比;
- 宽而浅的设计偏好:最优架构层数通常低于 20 层,宽度显著更大,且宽度的损失降低效率高于层数,因为端侧解码阶段受内存带宽限制,层数增加会线性提升内存访问量,而宽度的边际成本更低;
- 紧凑型 FFN 扩展比:最优 FFN 扩展比远低于传统的 4×,甚至低于 1×,说明端侧场景下,将参数从 FFN 转移至模型宽度或 MoE 专家数,能获得更好的效率;
- 阶段化 MoE 配置:预填充阶段偏好少专家(避免内存瓶颈),解码阶段偏好多专家(无额外延迟且提升容量),总延迟优化需平衡两者。
约束场景下的架构设计准则
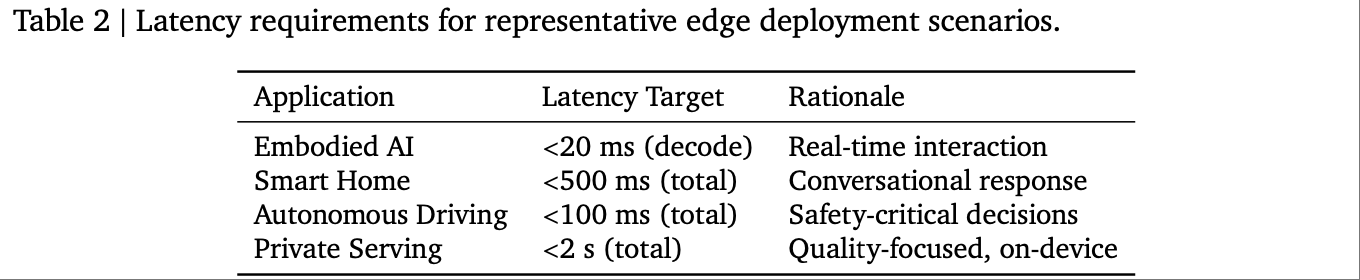
研究针对不同端侧应用场景的延迟需求,给出了可落地的架构选择指南,为实际部署提供直接参考:
跨硬件平台的强大泛化
研究给出了不同硬件平台(Jetson Orin/Thor)上的帕累托最优前沿,验证了“硬件协同设计扩展定律“的跨硬件平台泛化性。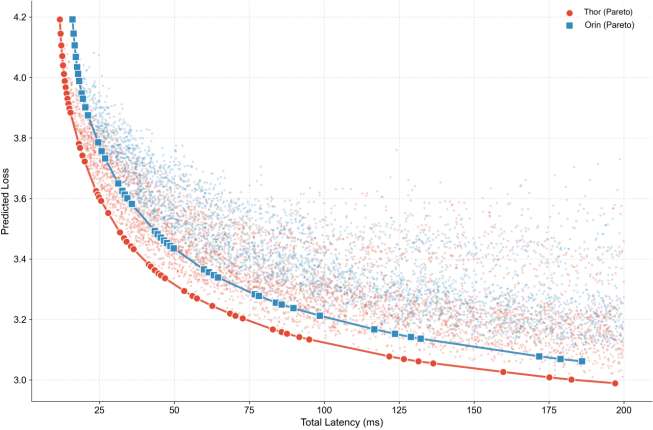
消融与分析:关键设计的必要性验证
研究通过大量消融实验,验证了损失定律拟合、Roofline 延迟建模、MoE 稀疏架构、宽而浅设计等关键模块的必要性:
损失定律的预测精度:拟合公式在未见过的架构上仍能实现 95% 以上的预测精度,避免了大量无效的训练和实测;
Roofline 建模的可靠性:解析延迟与实测延迟的相关性极高,误差在 10-20% 以内,满足架构排序和选择的需求;
MoE 稀疏的不可替代性:稠密架构在端侧 batch=1 场景下,精度-效率比远低于 MoE 架构,无法进入帕累托前沿;
宽而浅 vs 深而窄:在相同延迟约束下,宽而浅的架构损失比深而窄的架构低 15-20%,是端侧场景的最优选择。
实际任务性能:同延迟下精度提升 19.42%
在 NVIDIA Jetson Orin 上,选择与 Qwen2.5-0.5B推理延迟完全匹配的帕累托最优架构,进行同条件训练和测试:
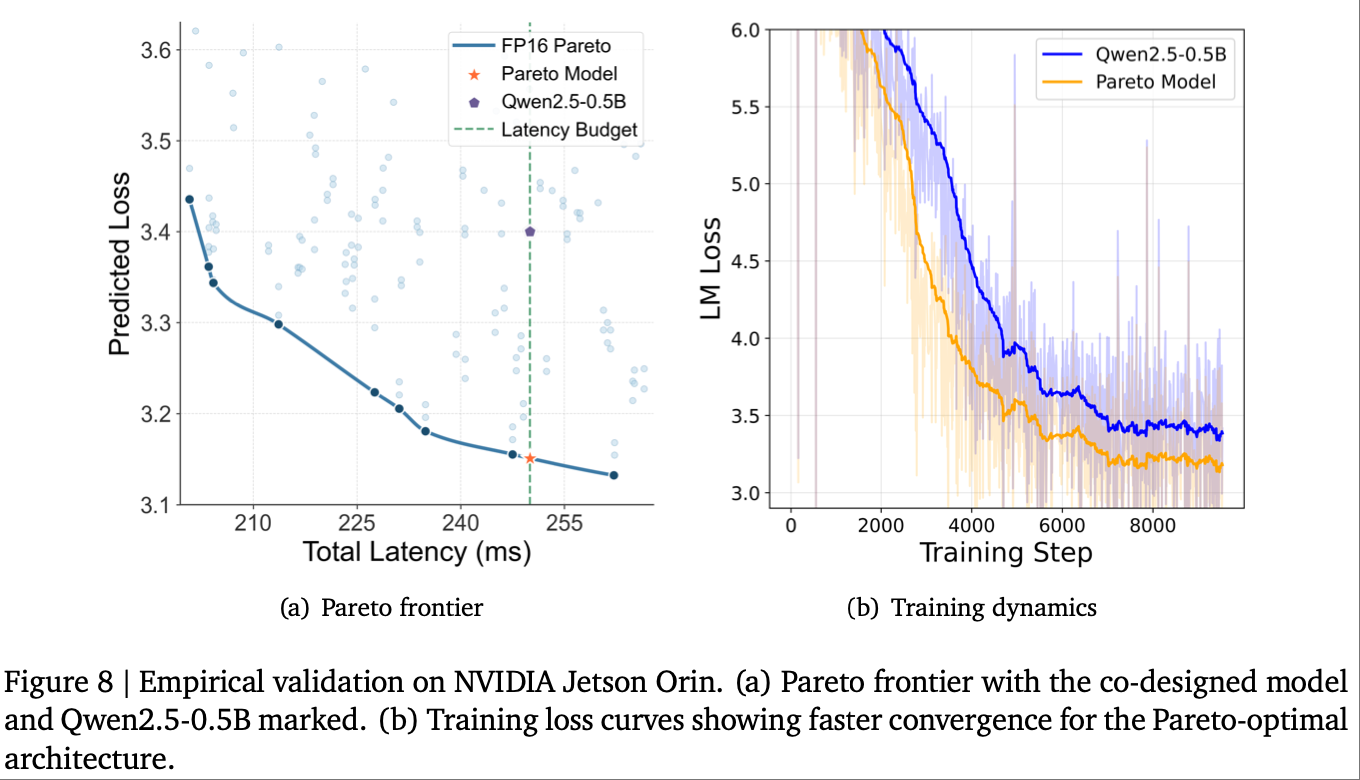
- 训练动态:协同设计的架构在整个训练过程中损失始终更低,模型容量利用效率更高;
- 下游性能:协同设计架构的困惑度(Perplexity)为 50.88,相比 Qwen2.5-0.5B(63.14)降低 19.42%,实现了 “同延迟下的精度显著提升”,验证了硬件协同设计的实际价值。
总结:开启端侧 LLM 的硬件-模型协同设计时代
该研究的核心价值不仅在于实现了端侧 LLM 架构设计的效率与性能突破,更在于首次提出了可落地的端侧 LLM 硬件协同设计定律,构建了 “架构超参数-模型精度-硬件性能” 的统一建模框架,实现了从 “经验式设计” 到 “原理性优化” 的范式转变。其核心贡献可概括为三大跨越:
建模跨越:首次将损失定律与 Roofline 硬件建模结合,实现了精度-延迟的显性映射,为多约束优化奠定基础;
搜索跨越:提出 PLAS 框架,将架构搜索转化为帕累托前沿分析,将设计周期从数月缩短至数天;
理论跨越:推导出不同硬件约束下架构超参数的解析解,给出了可落地的端侧 LLM 设计准则。
尽管目前该框架仍基于 Transformer 架构,尚未扩展至 SSM-Transformer 混合架构等新型结构,且对硬件核函数融合、缓存效应的建模仍可进一步精细化,但该研究已证明:硬件-模型的协同设计是破解端侧 LLM 精度-延迟矛盾的核心关键。未来通过将该框架扩展至更多边缘硬件平台(如 TPU、专用 AI 加速器)、融合新型高效架构、轻量化建模适配低功耗设备,有望加速 LLM 在自动驾驶、移动机器人、智能家居等端侧场景的规模化部署。
重磅!
VLA+RL方向首个系统教程来啦!Online RL/Offline RL/test time RL等~
推荐阅读
我们用低成本的机械臂完成pi0/pi0.5/GR00T/世界模型等VLA任务~
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)