大模型“饥饿游戏“:2026年,谁掌握高质量数据集,谁就掌握AI门票
大模型训练对数据的需求呈现指数级增长态势。GPT-4训练过程中消耗约13万亿tokens语料,而传闻中GPT-5的训练数据需求或将达到200万亿tokens,该数值相当于当前互联网公开文本总量的数倍。Epoch AI研究发布的预测显示,全球高质量文本数据将在2028年面临枯竭。在AI产业竞争中,算力可通过资本投入采购,算法能够借助技术研发持续优化,但高质量、合规且多样化的训练数据已成为稀缺战略资源
大模型训练对数据的需求呈现指数级增长态势。GPT-4训练过程中消耗约13万亿tokens语料,而传闻中GPT-5的训练数据需求或将达到200万亿tokens,该数值相当于当前互联网公开文本总量的数倍。Epoch AI研究发布的预测显示,全球高质量文本数据将在2028年面临枯竭。在AI产业竞争中,算力可通过资本投入采购,算法能够借助技术研发持续优化,但高质量、合规且多样化的训练数据已成为稀缺战略资源。数据供给能力直接影响大模型的迭代效率与应用落地效果,成为2026年AI产业竞争的关键影响因素。
一、高质量数据的核心评价标准:“AI 就绪度”
并非所有数据都能满足大模型训练需求,驱动模型持续进化的语料需符合“AI就绪度”标准。这一概念虽尚未形成官方定义,但在行业实践中已形成共识,主要包含四个核心维度:

(一)质量维度
数据标注准确率需达到99%以上,关键信息完整性超过95%。准确且完整的数据是保障模型训练效果的基础,数据偏差或信息缺失会直接影响模型输出结果的可靠性,增加算法优化的难度。
(二)规模维度
单场景数据集规模应达到十亿级,且需支持持续迭代更新。充足的数据规模能够覆盖场景内的各类情况,为模型提供全面的训练样本,支撑模型在特定领域的深度优化。
(三)多样性维度
数据需覆盖多语言、多方言、多地域及多行业专业变体。多样化的数据能够避免模型训练过程中的场景偏见,提升模型在不同应用场景下的适配能力,拓展模型的应用边界。
(四)合规维度
数据需完成隐私脱敏、版权清理与授权追溯,符合《生成式人工智能服务管理暂行办法》等相关政策要求。合规性是数据应用的前提,能够有效规避法律风险,保障数据使用过程中的安全性与合法性。
从“有数据”到“有可用数据”,这是2026年AI落地的关键分水岭。
二、我国高质量数据供给体系的国家战略布局
面对全球高质量数据短缺的现状,我国从国家战略层面推进系统性布局,通过六大核心方向构建全方位的高质量数据供给体系,为 AI 产业发展提供制度保障与资源支撑。
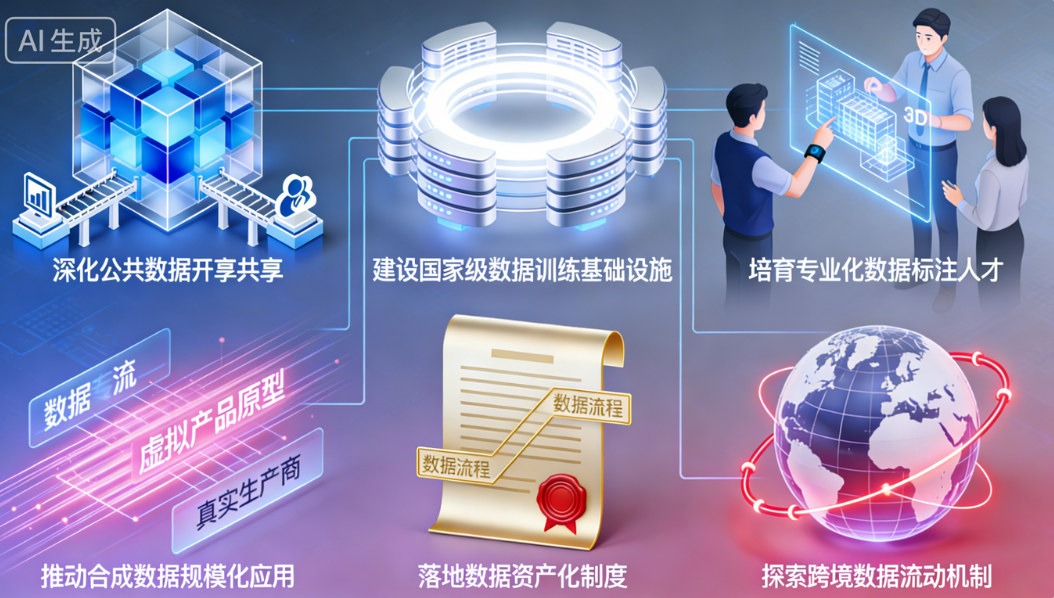
(一)深化公共数据开放共享
国家数据局牵头推动气象、交通、医疗、司法等20余个高价值领域的数据有序开放。截至2024年底,国家公共数据资源体系已汇聚数百个国家级数据集,数据总量超过400PB。北京、上海、浙江等地区率先落地公共数据授权运营机制,结合具体应用场景开发形成超百个数据产品,实现公共数据资源的高效利用。
(二)建设国家级数据训练基础设施
北京亦庄、深圳河套、合肥等地区重点打造“人工智能数据训练基地”,探索“数据可用不可见、模型安全可审计”的创新模式。其中,北京亦庄的“北京人工智能数据训练基地”已吸引智谱AI等100余个生态伙伴入驻,提供一站式数据训练服务,使大模型训练周期缩短30%以上。该基地首创的人工智能数据沙盒机制,有效降低企业数据使用的合规成本,降幅约40%。
(三)培育专业化数据标注人才
河南、贵州、山西(大同)、重庆(永川)等地区建成规模化数据标注产业基地,全国7个国家级标注基地总从业人员达5.8万人,累计带动就业超5万人。中国信通院《数据标注产业发展研究报告(2025 年)》显示,2024年全国专业数据标注人员规模约50万,从业人员正逐步向数据审核、清洗、建模等 “数据工程师” 方向转型,人均产值提升约80%,人才结构优化为数据质量提升提供支撑。
(四)推动合成数据规模化应用
Gartner预测数据显示,2024年AI及分析项目中约60%的数据为合成生成,到2026年这一占比将进一步提升。合成数据技术在金融风控、自动驾驶、工业质检等数据采集难度大、成本高的领域已成熟应用。百度、阿里、华为等企业已具备大规模合成数据生产能力,华为自动驾驶合成数据引擎每日可生成100万公里极端场景数据,百度、阿里在大模型训练和金融领域的合成数据生产能力达到同等量级。
(五)落地数据资产化制度
2024年1月《企业数据资源相关会计处理暂行规定》实施后,全年A股与新三板企业数据资产入表金额约25.44亿元,涉及122家企业,其中包括100家A股上市公司和22家新三板公司。深圳、北京、上海等地数据交易所挂牌数据资产超5000个,2024年三地数据资产交易额突破100亿元,数据资产化制度的落地促进了数据要素的市场化流通。
(六)探索跨境数据流动机制
海南自贸港、上海临港新片区试点推进数据跨境流动分级分类管理机制,建立“一般数据清单+负面清单”相结合的全流程服务管理体系。2024年,临港新片区重点推进智能网联汽车、公募基金、生物医药三大领域的国际数据服务试点项目,海南自贸港开通“来数加工”数据跨境应用场景,为全国范围内数据跨境安全有序流动积累实践经验。
三、地方实践案例:北京、合肥的创新探索
国家战略的落地离不开地方层面的实践创新,北京亦庄与合肥基于自身资源优势,形成了各具特色的高质量数据供给模式。
(一)合肥:科研驱动的中文语料建设模式
针对国产大模型在古汉语、少数民族语言、科研论文等特色领域的语料短板,中科大、科大讯飞等23家单位联合组建“高质量中文语料联盟”。依托高校与科研机构的学术资源,联盟在两个月内积累超千亿token语料,重点补充了中文语料中的稀缺类型,为国产大模型的训练提供了重要的中文数据支撑。
(二)北京亦庄:技术驱动的数据训练基础设施模式
北京亦庄“人工智能数据训练场”采用隐私计算与联邦学习技术,构建“数据不动模型动”的训练模式。企业在不接触原始数据的前提下即可完成模型训练,既保障了数据所有权人的权益,又降低了企业数据使用的合规风险。截至目前,该训练场已服务15家企业,处理数据超10PB,未发生安全事故。
四、产业发展趋势:高质量数据集引领的三大增长方向
《数据要素发展报告(2025年)》显示,在国家发展改革委《关于促进数据产业高质量发展的指导意见》引导下,数据产业进入体系化构建阶段。2024 年全国数据生产总量达41.06泽字节(ZB),同比增长25%,其中用于AI开发训练的数据量同比增长40.95%,高质量数据集相关产业呈现三大明确增长方向。

(一)高质量数据集开发与运营
高质量数据集建设已从概念阶段进入实操阶段,重点行业的数据开发加速推进。工业制造领域盘活设备声纹、质检图像等非结构化数据,构建故障诊断、智能运维数据集;医疗卫生领域融合影像、临床科研、医学术语等多模态数据,形成辅助诊疗专业语料;交通运输领域整合车载传感、路侧感知、卫星定位等数据,支撑智能驾驶与智慧交通发展;低空经济作为新兴场景,飞行数据、地理信息、物流轨迹等数据集的市场需求快速增长。
供给端形成多元主体协同格局:开源社区提供基础通用数据集;专业服务商聚焦垂直领域,打造行业精品数据集,并在年报中列示数据资产账面价值;四川成都、辽宁沈阳等7大标注基地已产出上百个高质量数据集;北京国际大数据交易所等26家交易场所开设数据集专区,其中北数所已发布约300个高质量数据集,覆盖10余个应用领域。
(二)智能数据服务与DataOps转型
数据标注产业正从劳动密集型向技术密集型转型。基于DataOps(数据研发运营一体化)理念,企业构建“AI预标注+专家质检”的自动化处理流程,数据处理效率提升3倍,成本下降50%,头部企业在医疗、法律等高精度需求领域的标注准确率达到99.5%。数据编织(Data Fabric)技术实现多源异构数据的逻辑集中管理,打破数据孤岛,推动数据治理从“规则+人工”模式向“模型+自主”模式转型,有效激活企业非结构化数据的价值。
(三)数据资产化与价值变现
数据要素价值显性化取得初步成效。2024年A股100家上市公司完成数据资源入表,总金额21.64亿元,其中三大通信运营商合计入表金额13.66亿元。非上市公司通过数据资产融资的项目达112个,合计融资金额14.12亿元,首单数据资产ABS产品“平安-如皋第1期”于2025年4月在深交所设立,规模1.3亿元。数据资产化不仅为企业提供了新的融资渠道,更构建了“数据生产-价值变现-再投入”的良性循环。
五、AI 时代数据要素配置的协同机制:政策、产业与企业的互动
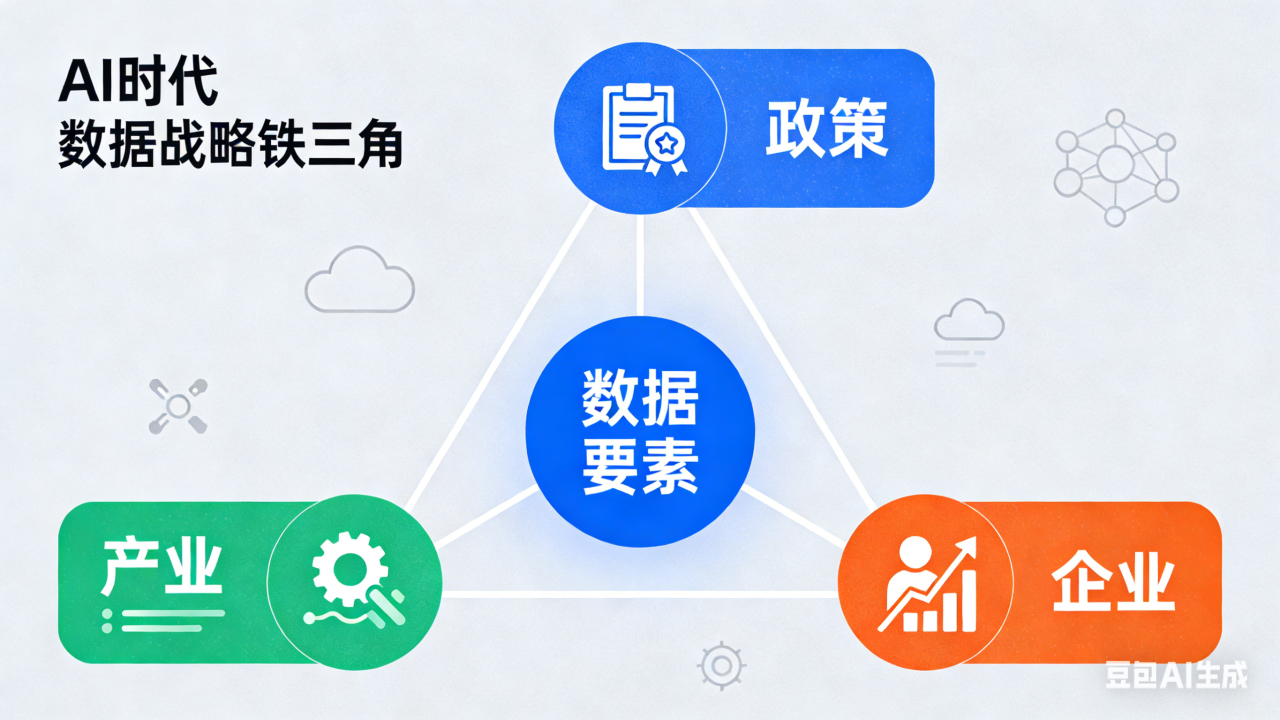
数据要素市场化配置是AI产业发展的必然趋势,政策、产业、企业三方构建的协同机制,推动数据要素从资源向资产、资本转化。政策端以“1+3”政策体系、《政务数据共享条例》为核心,通过公共数据开放、数据资产化制度、跨境数据流动试点等制度创新,将分散数据转化为可量化、可审计的AI战略资产,为发展划定边界、提供保障。产业端依托 DataOps、数据编织、合成数据等技术创新,推动数据处理从劳动密集型向技术密集型转型,为企业提供高效合规、低成本的数据服务,降低 AI 开发门槛。企业端按规模形成差异化路径:大型科技公司设立首席数据官(CDO),加大数据治理投入,构建垂直领域十亿级AI-ready数据集;中小企业通过对接官方平台、采购合成数据、接入地方训练基地获取优质数据;创业者聚焦细分场景构建差异化数据优势。AI 技术贯穿全程,形成“数据驱动智能、智能优化数据”的共生关系,持续释放数据要素价值。
六、结论
2026年AI产业竞争的核心是高质量数据集的获取与应用能力。我国已通过国家战略布局、地方实践创新与产业技术升级,构建起多维度高质量数据供给体系。数据要素价值的实现,关键在于从积累向转化的跨越,即将数据转化为模型训练资源、产业支撑要素与价值变现资产。未来,需持续深化政策、产业、企业三方协同,以“AI就绪度”提升数据质量,以技术创新优化处理效率,以制度保障完善流通机制,实现从“数据存量” 到“智能增量”的突破,推动我国AI产业从跟跑向领跑转变,为全球AI高质量发展提供中国方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)