LangChain框架:三大模型应用全解析
本文围绕 LangChain 框架对大语言模型(LLMs)的集成与使用展开,核心梳理三类核心模型的应用逻辑:
- 1)LLMs 的介绍和使用。
- 2)Chat Models 的介绍和使用。
- 3)Embeddings Models 的介绍和使用。

LangChain 是「大模型应用开发框架」,LangChain 学习开始之前必须要先了解大模型的一些核心概念:LLM, Prompt, Prompt Engineering, Token, System Prompt, Few-shot Learning, Embedding,RAG,Chain,Agent等。
一 大语言模型 LLMs
大模型有非常多,LangChain模型组件提供了各种模型的集成,并未所有模型提供一个精简的统一接口。其支持以下三类模型:
- LLMs 大语言模型。LLMs 是技术范畴的统称,指的是基于大参数量 海量文本训练的 Transformer 架构模型。核心能力是理解和生成自然语言。
- Chat Models 聊天模型。Chat Models 是应用范畴的细分,是专门为对话场景优化的 LLMs ,核心能力是模拟人类对话的轮次交互,主要服务于聊天场景。
- Embeddings Models 嵌入模型。Embeddings Models 是将自然语言文本转化为对应向量的模型。
1.1 LLMs 模型的使用
LangChain 访问大模型 LLMs 的两种方式
① langchain_community 包访问云平台
from langchain_community.llms.tongyi import Tongyi
llm = Tongyi(model="qwen-max", temperature=0.9)
res = llm.invoke("请介绍一下你自己") ② 本地部署的 ollama 方式
from langchain_ollama import Ollama
llm= Ollama(model="gpt4all", temperature=0.9)
res = llm.invoke("请介绍一下你自己")1.2 LLMs 的流式输出
invoke 输入方式,是等到大模型全部回答完之后再返回结果。
import os
from langchain_openai import AzureChatOpenAI
from dotenv import load_dotenv
load_dotenv("peizhi.env")
ENDPOINT = os.getenv("ENDPOINT")
DEPLOYMENT = os.getenv("DEPLOYMENT")
SUBSCRIPTION_KEY = os.getenv("SUBSCRIPTION_KEY")
API_VERSION = os.getenv("API_VERSION")
llm = AzureChatOpenAI(
azure_endpoint=ENDPOINT,
deployment_name=DEPLOYMENT,
openai_api_key=SUBSCRIPTION_KEY,
openai_api_version=API_VERSION,
temperature=0.9
)
res = llm.invoke("请介绍一下你自己")
print(res.content)这里使用的模型是 Azure 提供的服务,其构建模型使用的是 LangChain 中的AzureChatOpenAI,并且由于我并没有将大模型的 key 等信息放入环境变量,而是写在了 peizhi.env 文件中。
其实我这里使用的是聊天模型,只是这里将聊天模型当作大语言模型来使用了,主要为了体验 invoke 方式和 stream 方式的不同输出效果。
将 invoke 方式改为stream 方式 ,其返回结果将会像我们平常使用的AI类似,一个一个的蹦字出来。
res = llm.stream(input = "请介绍一下你自己")
for chunk in res:
print(chunk.content, end="", flush=True)二 Chat Models(聊天模型)
聊天模型本身也是大语言模型,只是将大语言模型针对聊天做了对应优化,聊天模型的信息输入一般包含着以下几个部分的信息:
- AI message : 就是 AI 自己输出的消息 (OpenAI 库中的 Assistant 角色)
- HumanMessage : 就是用户消息,由人类给出发送给 LLMs 的信息 (OpenAI 库中的 User 角色)
- SystemMessage : 用于指定模型的角色扮演,相关背景等的定义话语 (OpenAI 库中的 System 角色)
# chat 模型 输入 message 列表
import os
from dotenv import load_dotenv
from langchain_openai import AzureChatOpenAI
load_dotenv("peizhi.env")
ENDPOINT = os.getenv("ENDPOINT")
DEPLOYMENT = os.getenv("DEPLOYMENT")
SUBSCRIPTION_KEY = os.getenv("SUBSCRIPTION_KEY")
API_VERSION = os.getenv("API_VERSION")
chat = AzureChatOpenAI(
azure_endpoint=ENDPOINT,
deployment_name=DEPLOYMENT,
openai_api_key=SUBSCRIPTION_KEY,
openai_api_version=API_VERSION,
temperature=0.9
)
messages = [
{"role": "system", "content": "你是我的人工智能助手,协助我解答问题。"},
{"role": "user", "content": "请介绍一下你自己"}
]
res = chat.stream(messages)
for chunk in res:
print(chunk.content, end="", flush=True)此次对于大模型的输入就是 message 的消息列表。包含着 system 和 user 的信息 content 。
三 Embeddings Models (文本嵌入模型)
Embeddings Models 的实现原理和基础知识可以参考以下文章
揭秘RAG技术:如何让大模型更聪明?-CSDN博客![]() https://blog.csdn.net/2401_84080967/article/details/158652390?spm=1001.2014.3001.5501里面介绍了RAG的实现原理:通过 Embeddings Models 将自然语言数据转化为向量,进而将自然语言数据库变为向量数据库。
https://blog.csdn.net/2401_84080967/article/details/158652390?spm=1001.2014.3001.5501里面介绍了RAG的实现原理:通过 Embeddings Models 将自然语言数据转化为向量,进而将自然语言数据库变为向量数据库。
Embeddings Models : 将自然语言数据转化为计算机能识别的(能看懂的)向量
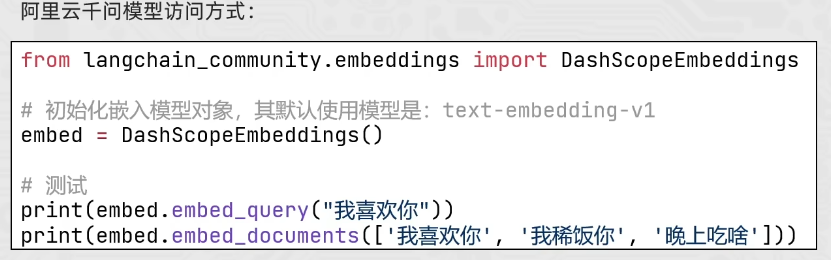
通过查看DashScopeEmbeddings的源码也能发现其默认使用 text-embedding-v1模型进行向量化。
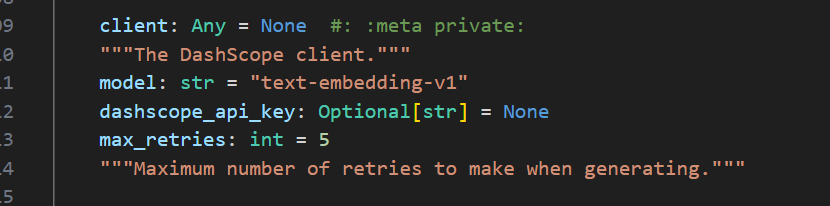
由于我并没有购买千文大模型的服务,Azure也没有购买对应的 token ,在这里使用huggingface上免费的版本进行实验。
from langchain_huggingface import HuggingFaceEmbeddings
embed = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)
v1 = embed.embed_query("请介绍一下你自己")
v2 = embed.embed_query("これは日本語のテストです")
print(len(v1), v1[:8])
print(len(v2), v2[:8])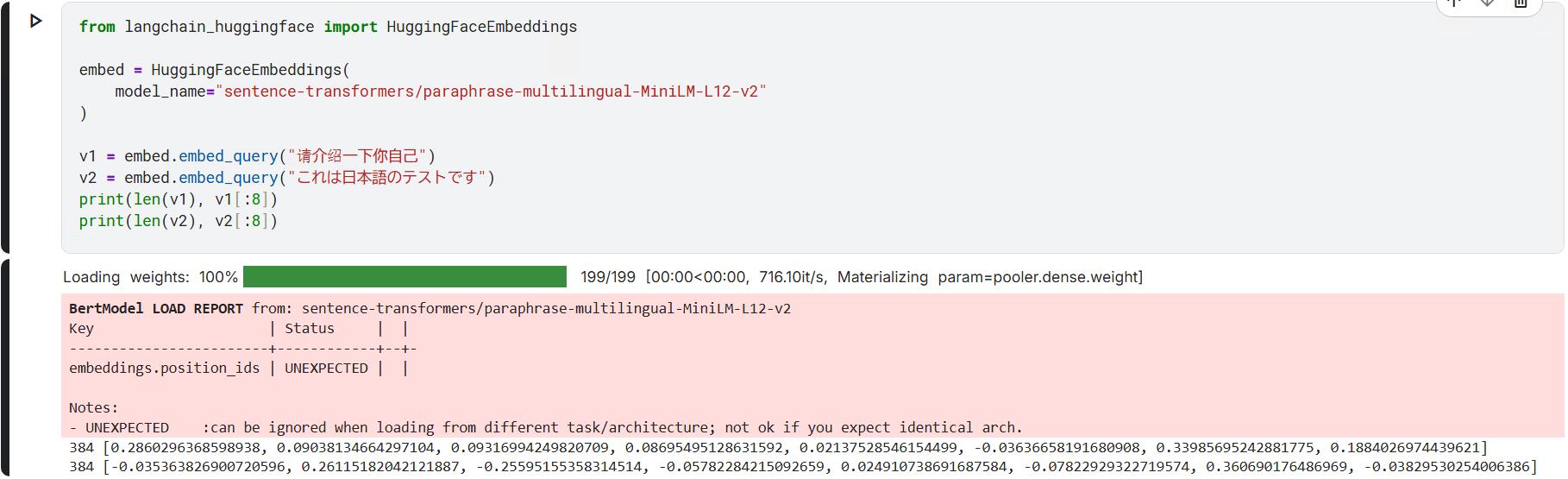
可以看见 “请你介绍一下自己” 和 “これは日本語のテストです” 被转化为了对应的向量 384 维度;说明该 Embedding 模型转化维度为384维的,在384个角度上去考察一个句子的语义,得到最后的句子向量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)