第2章 爬虫的实现原理和技术
本文系统介绍了网络爬虫的工作原理与应用。通用爬虫通过URL队列递归抓取网页,搜索引擎则在此基础上进行数据存储、预处理和排名。聚焦爬虫通过算法过滤无关链接。文章详细解析了robots.txt和Sitemap.xml文件的作用,并提出了应对防爬虫策略的多种方法,如伪装User-agent、使用代理IP等。同时阐述了Python作为爬虫开发语言的优势,包括接口简洁、处理高效等特点。全文为网络爬虫技术提供
1、爬虫实现原理
通用爬虫工作原理
通用爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
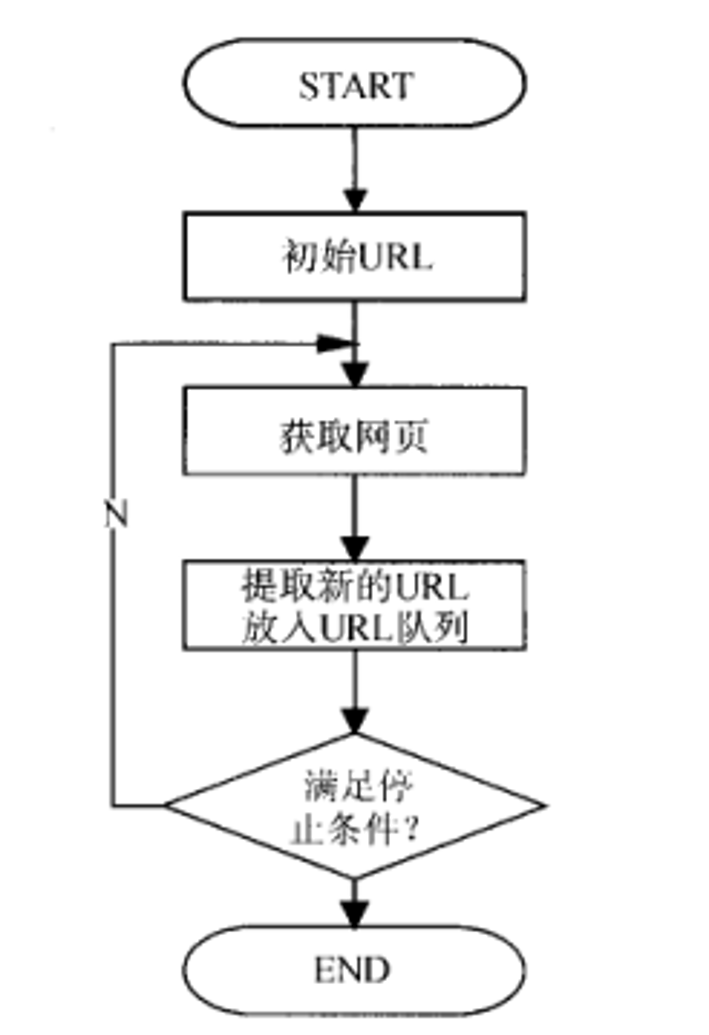
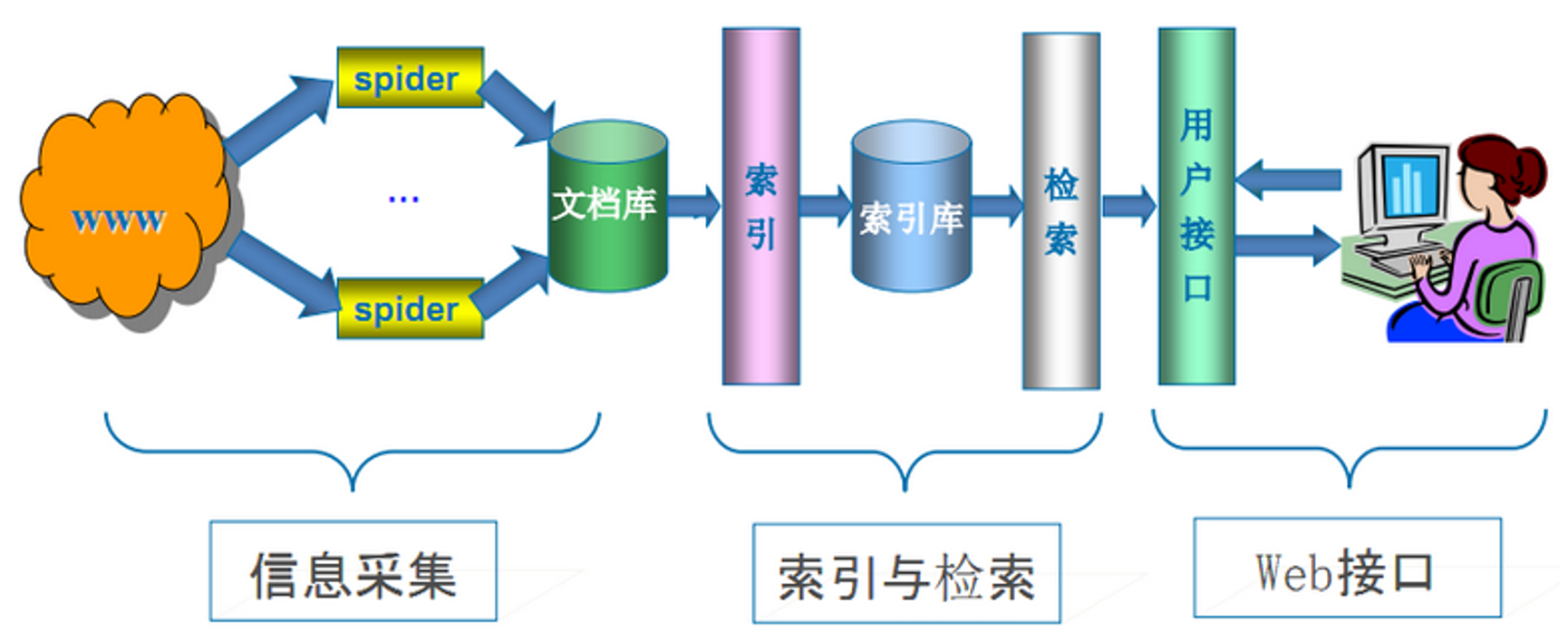
搜索引擎的工作流程
抓取网页
搜索引擎使用通用爬虫来抓取网页,其基本工作流程与其他爬虫类似。
数据存储
搜索引擎将数据存入原始页面数据库,其中的页面数据与浏览器得到的HTML是完全一样的。
预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。
检索和排名
搜索引擎为用户提供关键字检索服务,同时会根据页面的PageRank值来进行网站排名。
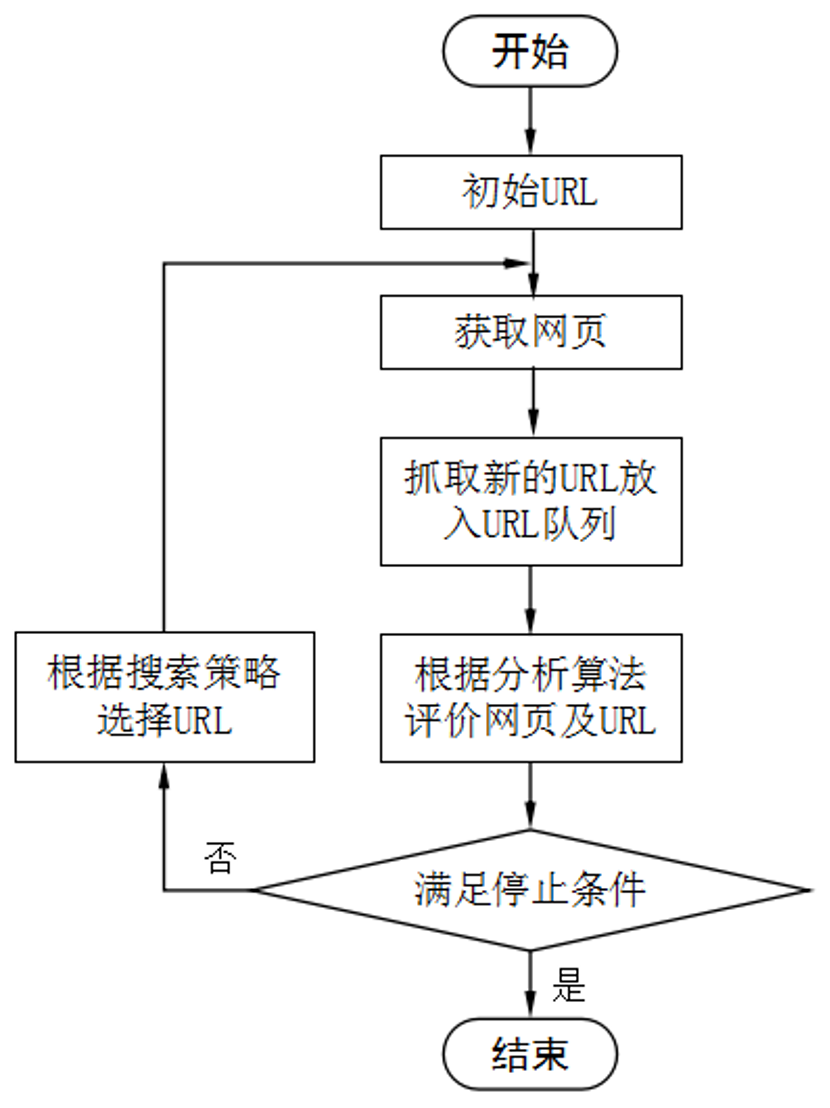
聚焦爬虫工作原理
聚焦爬虫需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
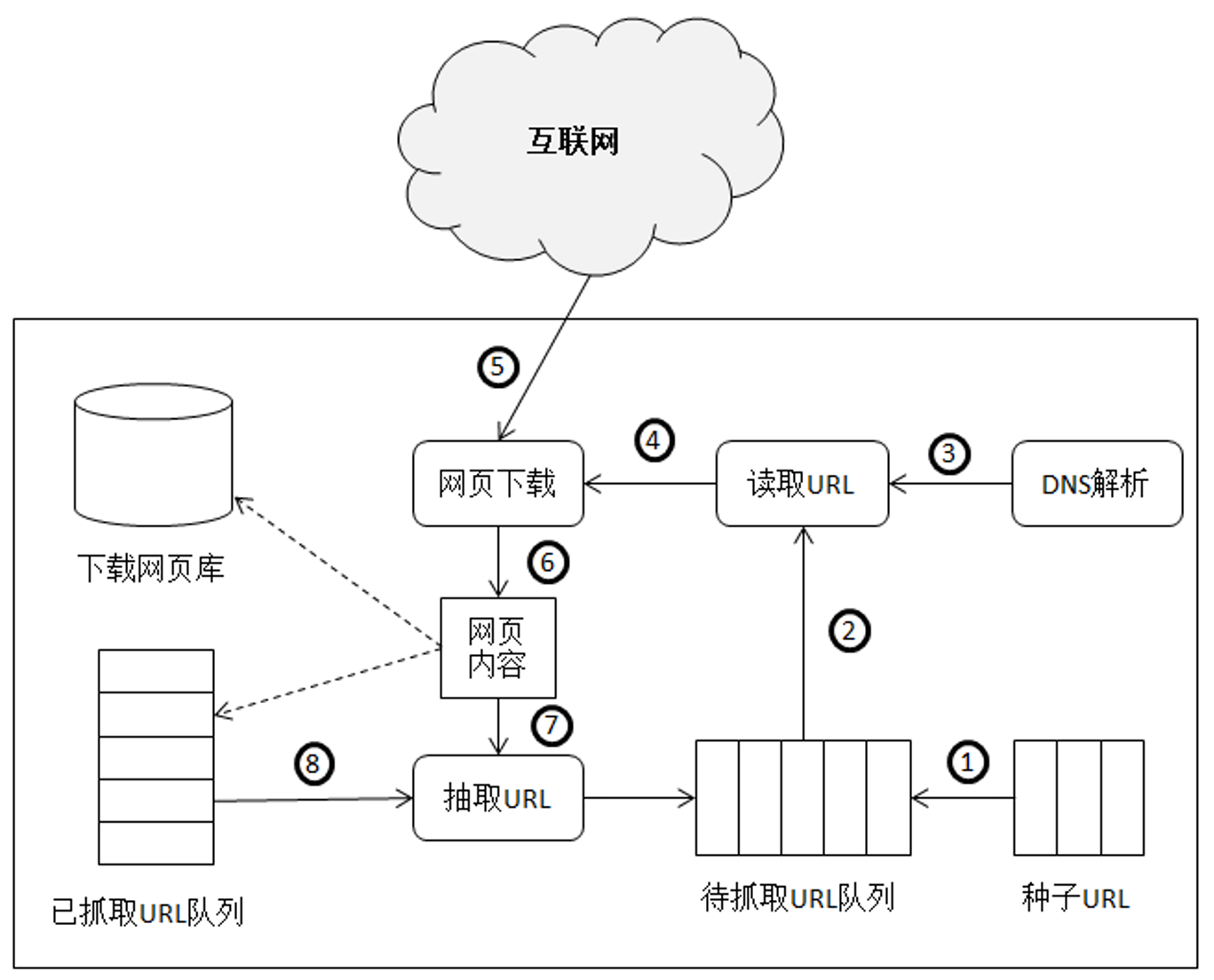
2、爬虫抓取网页的详细流程
3、通用爬虫中网页的分类
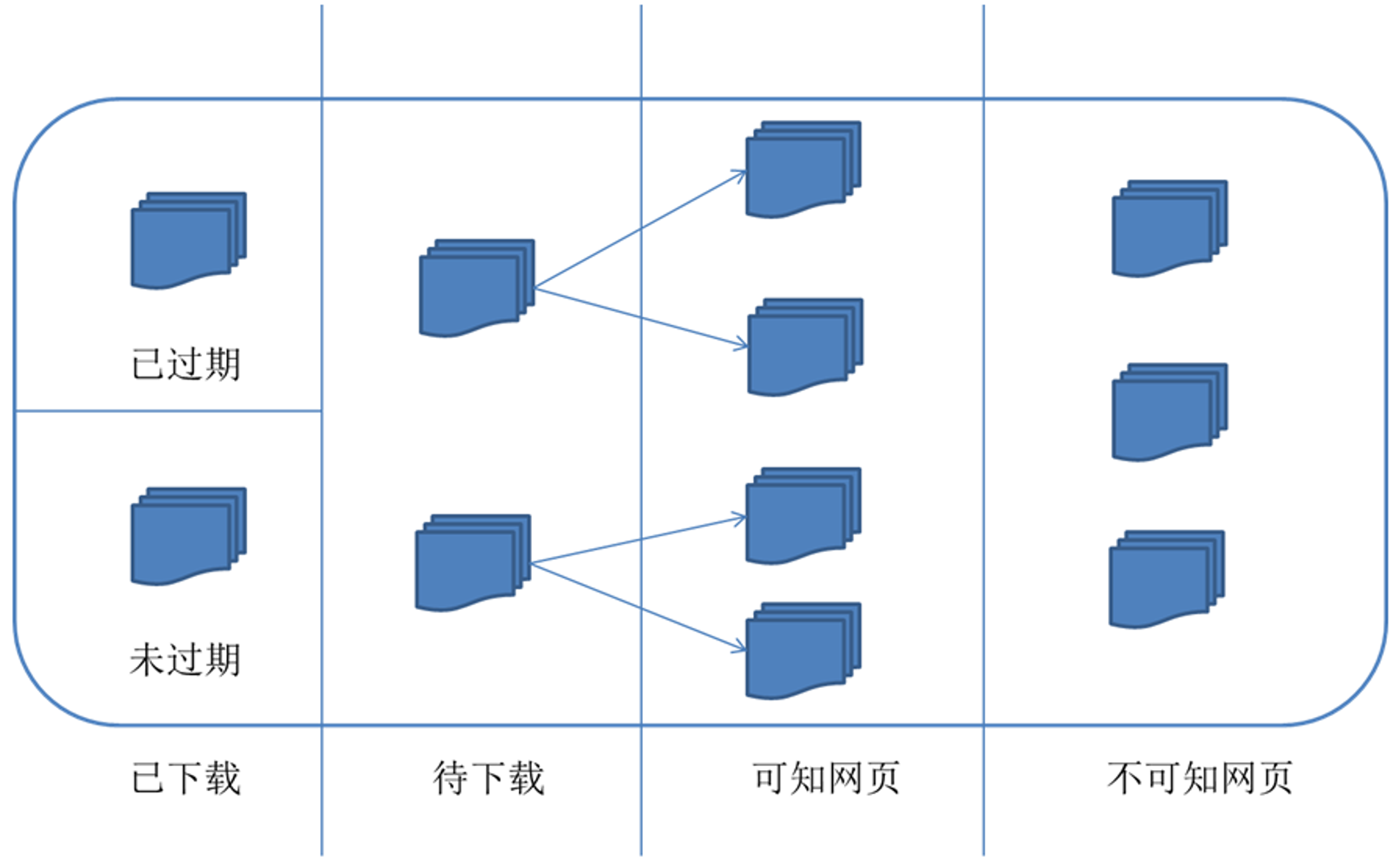
4、通用爬虫相关网站文件
robots.txt文件
网站通过robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
当一个网络爬虫访问一个站点时,它会先检查该站点根目录下是否存在robots.txt文件。
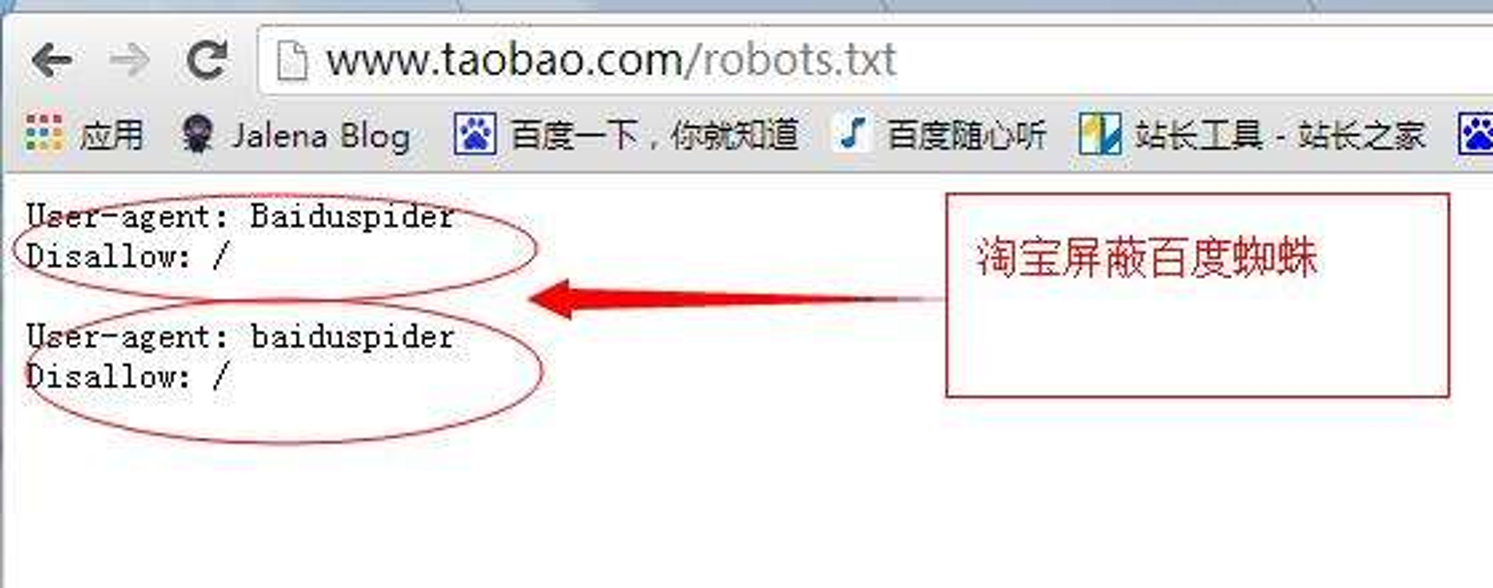
robots.txt文件使用#号进行注释。
Robots协议只是一种建议,它没有实际的约束力,网络爬虫可以选择不遵守这个协议,但可能会存在一定的法律风险。
Sitemap.xml文件
为了方便网站管理员通知爬虫遍历和更新网站的内容,而无需爬取每个网页,网站提供了Sitemap.xml文件(网站地图)。
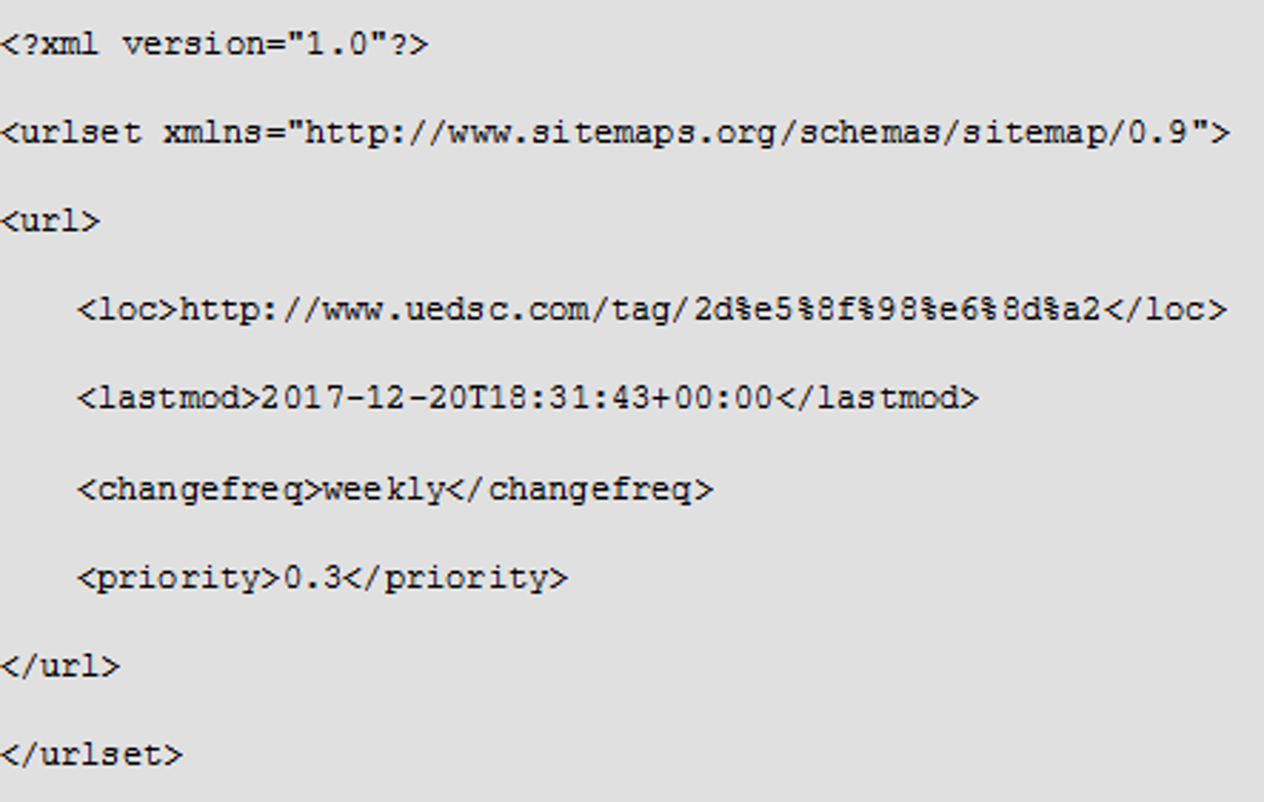
尽管Sitemap.xml文件提供了爬取网站的有效方式,但仍需要对其谨慎对待,这是因为该文件经常会出现缺失或过期的问题。
5、防爬虫应对策略
很多网络爬虫对网页的爬取能力很差,现在的网站会采取一些防爬虫措施来阻止爬虫的不当爬取行为。
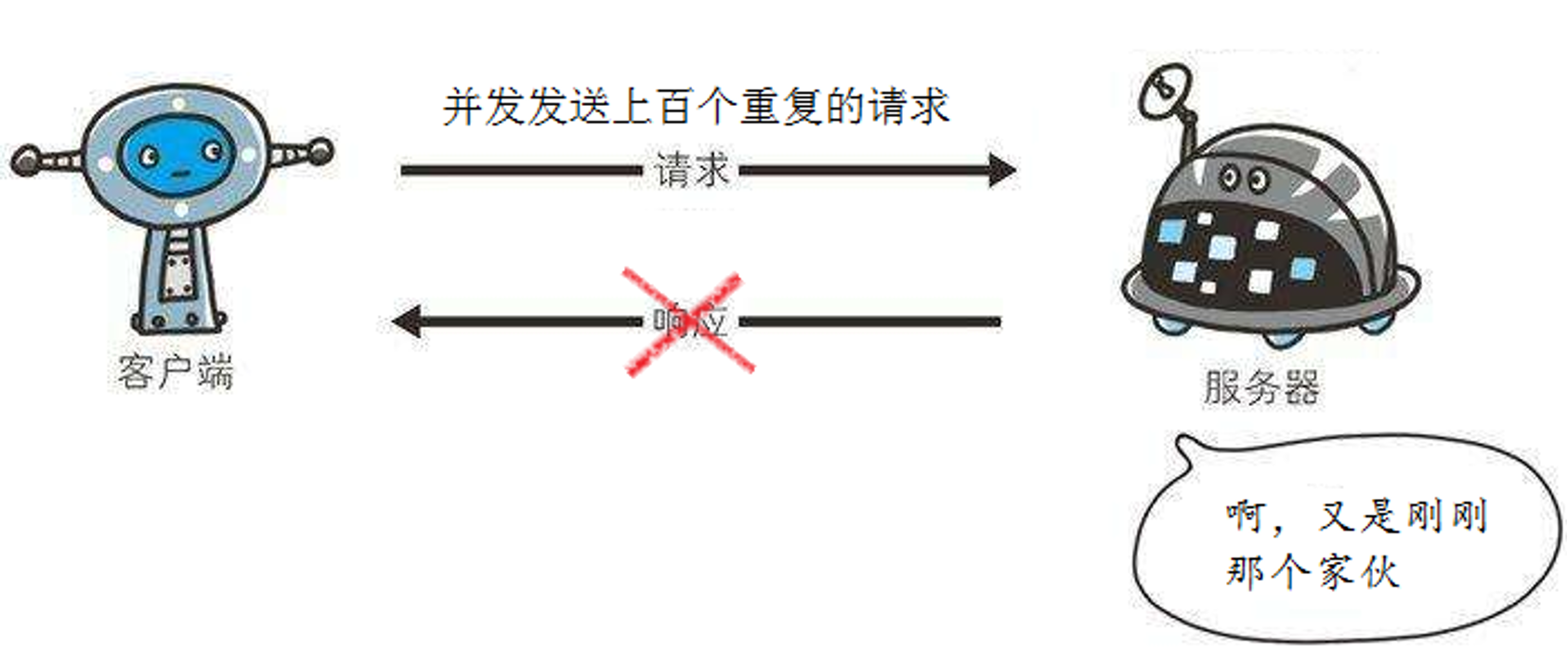
对于采取了防爬虫措施的网站,爬虫程序需要采取相应的应对策略,才能成功地爬取到网站上的数据。
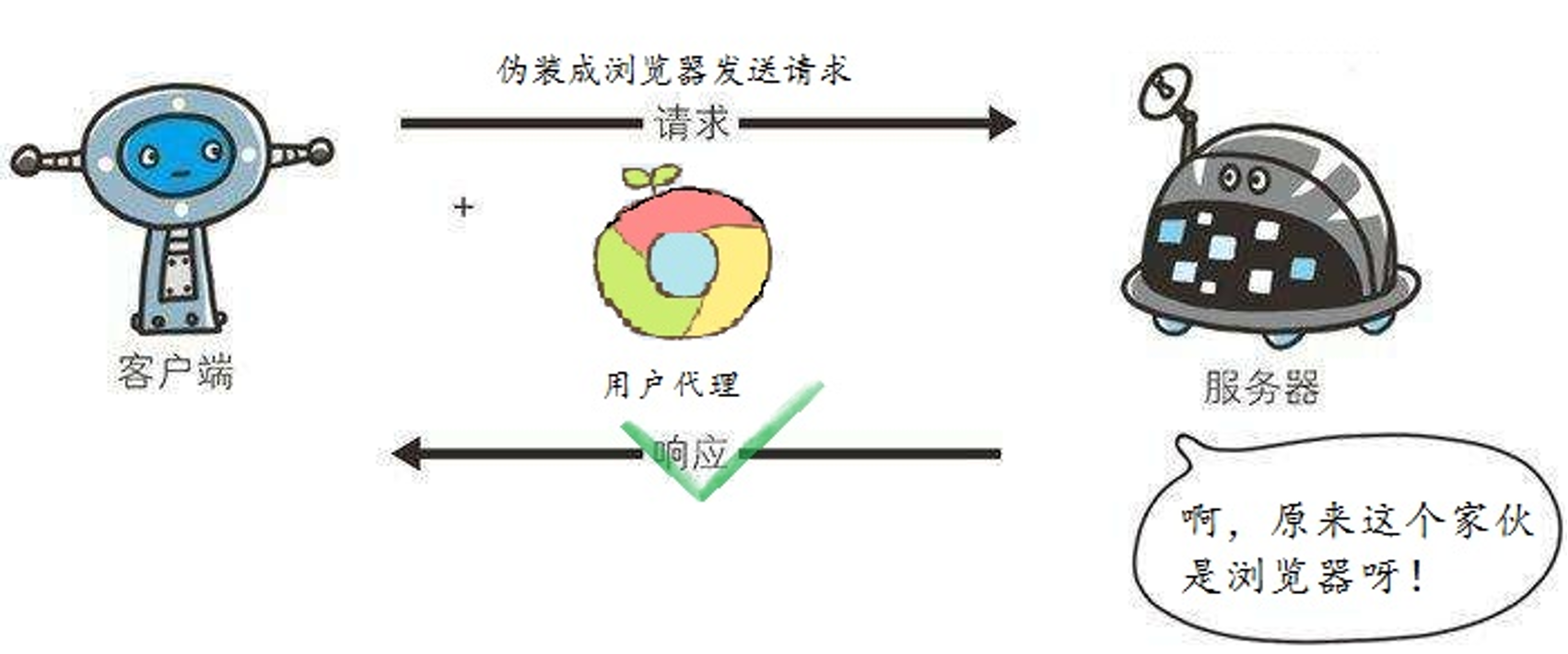
伪装User-agent
User-agent表示用户代理,是HTTP协议中的一个字段,其作用是描述发出HTTP请求的终端信息。每个正规的爬虫都有固定的User-agent,只要将这个字段设为知名的用户代理,就能够成功伪装。
使用代理IP
代理IP就是介于用户和网站之间的第三者,即用户先将请求发送给代理IP,之后代理IP再发送到服务器。服务器会将代理IP视为爬虫的IP,同时用多个代理IP,可以降低单个IP地址的访问量,极有可能逃过一劫。
降低访问频率
如果没有找到既免费又稳定的代理IP,则可以降低访问网站的频率,防止对方从访问量上认出爬虫的身份,不过爬取效率会差很多。为了弥补这个缺点,我们可以基于这个思想适时调整具体的操作。例如,每抓取一个页面就休息若干秒,或者限制每天抓取的页面数量。
验证码限制
虽然有些网站不登陆就能访问,但是它一检测到某IP的访问量有异常,就会马上提出登陆要求,并随机提供一个验证码。碰到这种情况,大多数情况下需要采取相应的技术识别验证码,只有正确输入验证码,才能够继续爬取网站。不过,识别验证码的技术难度还是比较大的。
6、为什么选择Python做爬虫
抓取网页的接口更简洁
Python的urllib包提供了较为完整的访问网页文档的API;相比与其他静态编程语言(如Java、C#、C++),Python抓取网页文档的接口更简洁。
网页抓取后的处理更简单
Python的Beautiful Soup提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
开发效率高
因为爬虫的具体代码得根据网站不同而修改的,而Python这种灵活的脚本语言特别适合这种任务。
上手快
网络上Python的教学资源很多,便于大家学习,出现问题也很容易找到相关资料。另外,Python还有强大的成熟爬虫框架的支持,比如Scrapy。
7、八爪鱼工具的使用案例

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)