SCBench A KV Cache-Centric Analysis of Long-Context Methods
摘要长上下文大型语言模型(LLMs)已经支持了许多下游应用,但也带来了计算和内存效率相关的重大挑战。为了解决这些挑战,基于KV Cache对长上下文推理进行优化设计。然而,现有的基准测试通常在单请求下进行评估,忽视了KV Cache在实际使用中的完整生命周期。这一疏忽尤其关键,因为KV Cache复用已经在LLMs推理框架(如vLLM和SGLang)以及LLM提供商(包括OpenAI、微软、谷歌和
摘要
长上下文大型语言模型(LLMs)已经支持了许多下游应用,但也带来了计算和内存效率相关的重大挑战。为了解决这些挑战,基于KV Cache对长上下文推理进行优化设计。然而,现有的基准测试通常在单请求下进行评估,忽视了KV Cache在实际使用中的完整生命周期。这一疏忽尤其关键,因为KV Cache复用已经在LLMs推理框架(如vLLM和SGLang)以及LLM提供商(包括OpenAI、微软、谷歌和Anthropic)中广泛采用。为了解决这一差距,我们引入了SCBENCH(SharedContextBENCH),这是一个从KV Cache视角来评估长上下文方法的全面基准测试:1)KV Cache生成,2)KV Cache压缩,3)KV Cache检索,4)KV Cache加载。具体来说,SCBench使用具有共享上下文的测试用例,涵盖12个任务和两种共享上下文模式,覆盖四类长上下文能力:字符串检索、语义检索、全局信息和多任务。通过SCBench,我们对8类长上下文解决方案进行了广泛的KV Cache分析,包括Gated Linear RNNs(Codestal-Mamba)、Mamba-Attention hybrids(Jamba-1.5-Mini)以及稀疏注意力、KV Cache丢弃、量化、检索、加载和提示压缩等高效方法。评估在六个基于Transformer的长上下文LLMs上进行:Llama-3.1-8B/70B、Qwen2.5-72B/32B、Llama-3-8B-262K和GLM-4-9B。研究结果表明,sub-O(n)内存方法在多轮场景中表现不佳,而具有O(n)内存的稀疏编码和sub-O(n2)预填充计算表现稳健。动态稀疏性比静态模式产生更具表达力的KV Cache,混合架构中的层级别稀疏性在保持强大性能的同时减少了内存使用。此外,我们还发现了长生成场景中的注意力分布偏移问题。
1引言
长上下文能力正成为LLM的标准,许多模型支持从128K到10M tokens的上下文窗口。这些扩展的上下文窗口解锁了广泛的实际应用,如仓库级代码理解和调试、长文档问答、多样本上下文学习以及长生成链式思维(CoT)推理。
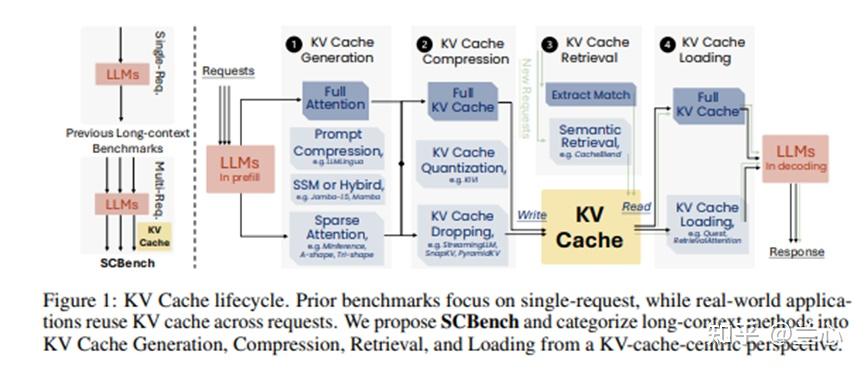
尽管如此,长上下文输入由于高计算成本和内存需求给LLM推理带来了独特的挑战,但也促使了利用KV Cache各个阶段稀疏性的高效长上下文解决方案的发展。在本文中,我们从KV Cache视角引入了一个统一的高效长上下文分析框架,包括KV Cache的四个基本阶段:1)KV Cache生成,2)KV Cache压缩,3)KV Cache检索,以及4)KV Cache加载。首先,KV Cache生成,也称为Prefill,处理输入提示并生成用于Decode阶段的KV Cache。在这个阶段,很多研究者提出了稀疏注意力方法以减少注意力操作的复杂度。其次,KV Cache压缩技术修剪KV状态以减少Decode阶段的内存成本。第三,KV Cache检索旨在跳过传入请求的KV Cache生成,而是从历史KV Cache池中检索和复用KV Cache以实现更高效的推理。最后,KV Cache加载旨在在每个Decode阶段中仅加载部分KV Cache以节省内存和计算成本。
然而,这些方法仅在单请求基准测试上进行评估,未能涵盖实际应用中KV Cache的完整生命周期。通常,实际应用往往需要复用KV Cache并涉及多个请求或多轮交互。KV Cache的复用(前缀缓存),已经是主流推理框架中的关键组件,并被LLM 提供商使用。此外,对于前面提到的长上下文方法,使用多个请求进行测试尤为重要,因为许多方法通过查询条件压缩来实现效率。例如,Arora 等人(2024)报告称,Mamba 根据当前查询对先前信息的压缩可能会阻止其回答后续查询。
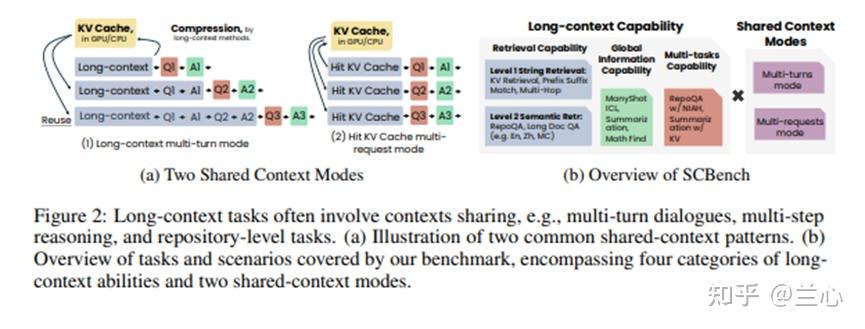
为了解决这一差距,我们引入了SCBench,这是一个旨在评估高效长上下文方法的基准,涵盖了真实场景中KV Cache的整个生命周期,特别是对于共享上下文和多轮交互,其中KV Cache被复用于后续查询。如图2b所示,SCBench在12个任务中评估了四种关键的长上下文能力,并具有两种共享上下文模式。每个测试用例包括一个共享上下文和多个后续查询。四种长上下文能力和它们对应的任务是:
- 字符串检索能力:长上下文大语言模型的一个基本要求是从长输入中检索出精确匹配的上下文。我们引入三个全面字符串检索任务:键值检索,前缀-后缀检索,以及多跳检索。
- 语义检索能力:实际应用通常要求长上下文大语言模型在检索成功之前理解语义含义。考虑了不同领域中的各种语义检索场景,构建了四个不同的测试:RepoQA(和long-form QA(涵盖英语、中文和多项选择题)。
- 全局信息处理能力:我们还通过三个任务评估长上下文大语言模型处理和聚合全局信息的能力:多样本上下文学习、摘要和长数组统计。
- 多任务处理能力:在实际应用中,大语言模型通常需要处理多个任务,这些任务共享长上下文输入。我们的基准测试通过两个任务评估这种能力:RepoQA with NIAH以及summarization with KV retrieval。
此外,如图2a所示,我们的基准测试包括两种典型的共享上下文模式:多轮模式,其中上下文在单个会话中进行缓存;多请求模式,其中上下文在多个会话中进行缓存。通过SCBench,我们进行了广泛的KV Cache分析。具体来说,我们在八个开源长上下文大语言模型上评估了13种长上下文方法,包括Llama-3.1-8B/70B、Qwen2.5-72B/32B、Llama-3-8B-262K、GLM-4-9B-1M、 Codestal Mamba和Jamba-1.5-mini。这些方法包括Gated Linear RNNs(Codestal Mamba)、Mamba-Attention hybrids(Jamba-1.5)、稀疏注意力(例如A-shape, Tri-shape, MInference)、提示压缩(LLMLingua-2)、KV Cache丢弃(StreamingLLM、SnapKV、KV Cache量化)、语义检索(CacheBlend)以及KV Cache加载(Quest)、RetrievalAttention),详见表1。此外,我们设计了Tri-shape,这是一种新颖的、无需训练的稀疏注意力方法,在我们的评估中展示了改进方法的性能。
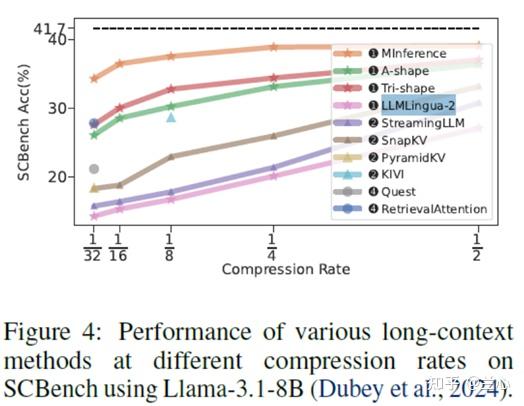
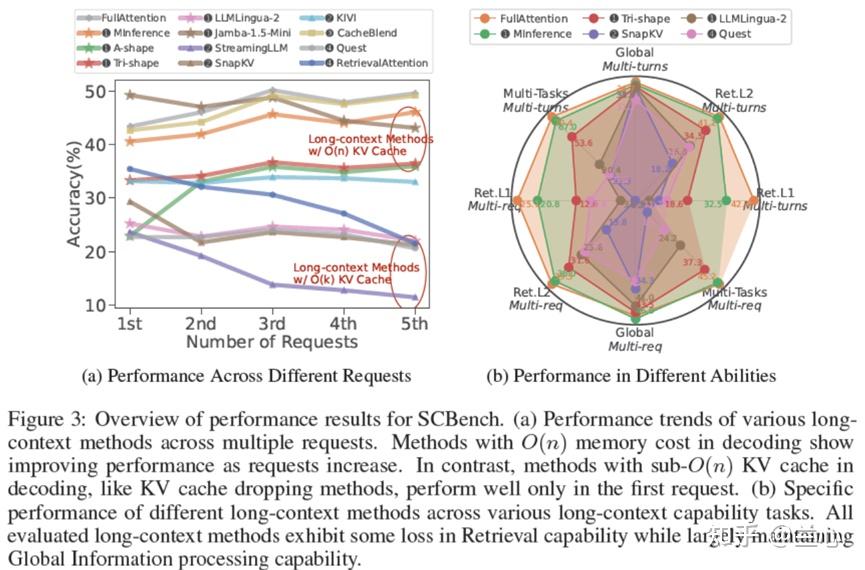
实验结果显示:1)如图3所示,多轮Decode中sub-O(n)内存几乎不可行。稀疏Decode方法(sub-O(n)内存)在首次查询时表现良好,但在后续请求中失去准确性(KV cache dropping:StreamingLLM、SnapKV)。相比之下,稀疏Encode方法(Prefill期间具有O(n)内存和O(n2)计算)可以在多个查询中近似全注意力精度(Jamba-1.5-Mini、CacheBlend)。2)如图3b所示,任务类性能以不同速率下降。稀疏KV Cache方法在全局信息的任务中表现出色,而 O(n)内存对于精确匹配检索任务至关重要。3)如图4所示,所有长上下文方法在预算减少时都会退化。然而,sub-O(n)内存方法在1/4压缩率时性能急剧下降。RetrievalAttention和KIVI方法通过稀疏解码保持 O(n)内存,即使在更高压缩率下也能维持较高性能。4)长生成场景表现出分布偏移问题。随着生成长度和轮数的增加,KV Cache的重要性分布发生显著变化。这种分布外(OOD)问题导致性能下降,即使对于像 RetrievalAttention这样的O(n)内存方法也是如此,如图3所示。
我们的贡献如下:
- 我们提出了一种新的基准测试SCBench,用于评估长上下文方法在多轮和多请求两种典型的KV Cache复用情况,提供更现实的评估。
- 我们设计了一套广泛的下游任务,涵盖了12个子任务中的四个长上下文能力,涉及各种领域。
- 我们从KV Cache视角系统地分类了长上下文方法,并使用SCBench在八个最先进的开源长上下文LLMs上评估了13种不同的长上下文方法(包括我们新提出的稀疏注意力方法Tri-shape)。我们的全面分析揭示了编码和解码中的稀疏性、任务复杂性等关键见解。
2一种KV Cache中心视角的长上下文方法
最近,一系列工作探索了各种策略以降低长上下文LLM的推理成本,使其能够以较低的计算开销应用于下游任务。在长上下文LLM推理中,KV Cache可以有效减少Decode阶段的计算开销。
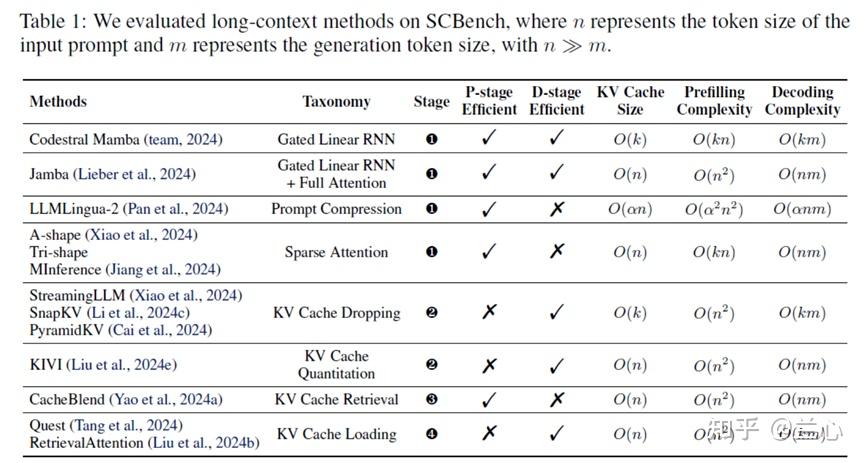
在这项工作中,我们提出了一种新的视角:这些长上下文方法可以被视为在不同阶段的KV Cache优化。具体来说,我们引入了一个KV Cache框架,该框架系统地将长上下文方法分为四个阶段:KV Cache生成、压缩、检索和加载,如图1所示。具体来说,KV Cache中心框架的四个阶段定义如下:
- KV Cache生成:此阶段优化推理过程中KV Cache的高效生成。技术包括稀疏注意力(A-shape, Tri-shape, MInference, NSA, MoBA), SSM或混合方法(Mamba), 提示压缩(LLMLingua-2)。
- KV Cache压缩:KV Cache生成后,KV Cache被压缩存储。包括KV Cache丢弃(StreamingLLM)、SnapKV和KV Cache量化(KIVI)。
- KV Cache检索:根据请求的前缀从存储池中检索相关的KV Cache块,减少TTFT。方法包括语义检索方法如CacheBlend。
- KV Cache加载:此阶段动态加载KV Cache并计算稀疏注意力,从KV Cache存储(例如VRAM、DRAM、SSD或RDMA)到GPU片上SRAM,包括Quest、RetrievalAttention和MagicPIG。
在我们的工作中,我们评估了13种长上下文方法的四个阶段,如表1所示。此外,我们列出了每种方法的KV Cache大小、Prefill阶段复杂度、Decode阶段复杂度,以及在Prefill阶段和Decode阶段是否执行了高效操作。
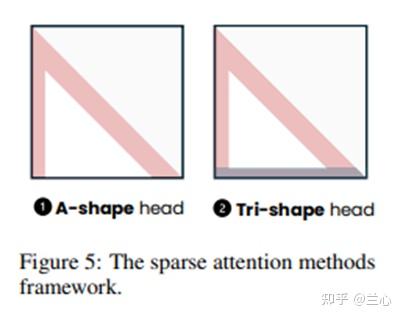
Tri-shape Sparse Attention:我们引入了Tri-shape,一种新型的无训练稀疏注意力方法,可提高首次准确率(图5)。与仅保留sink token和局部窗口的A-shape不同,Tri-shape还保留了最后一个窗口查询区域,形成了预填充的三角形稀疏注意力模式。受SCBench发现的启发,A-shape在密集解码后经过多次请求后性能有所提高,Tri-shape增强了turn-0和多请求性能,同时保持了LLM指令跟随能力。
3基准构建
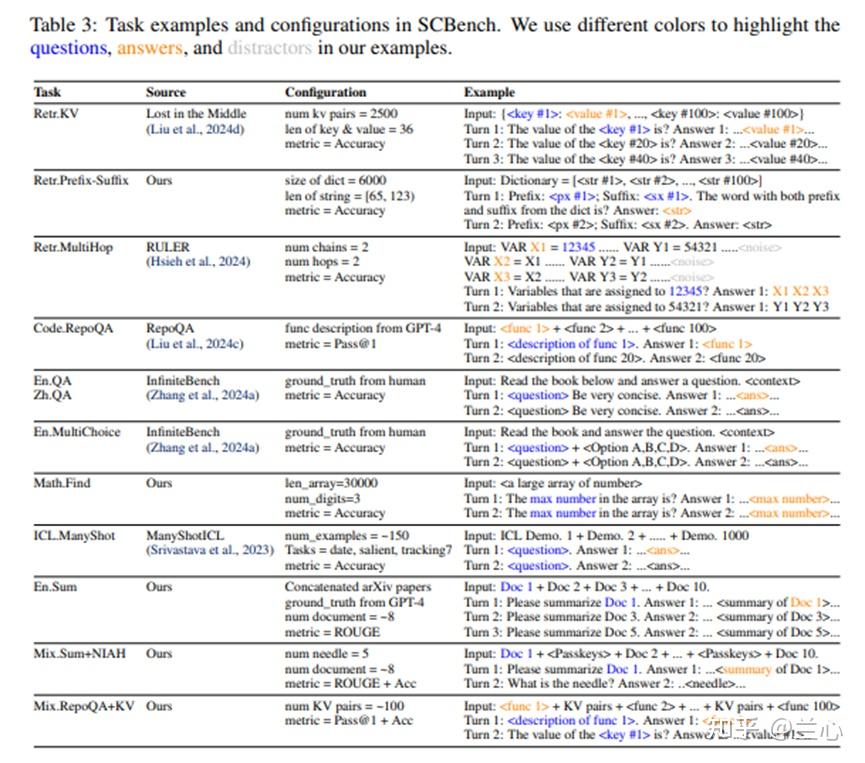
SCBench包含12个任务,评估四种长上下文能力:字符串检索、语义检索、全局信息处理和多任务处理,涵盖两种共享上下文模式——多轮和多请求。这些任务涵盖多个领域,包括代码、检索、问答、摘要、上下文学习和多跳追踪(图2b)。总计,SCBench 包含931个多轮会话,共4853个查询,平均每会话5轮。任务统计信息见表2,示例和配置见表3。下面描述基准构建。
3.1 长上下文任务详情
字符串检索:长上下文LLM的核心需求是从冗长且可能嘈杂的输入中检索相关信息。字符串检索任务通常用于此评估。我们的基准测试借鉴了算法问题解决(例如LeetCode)的复杂度分析,设计了三个不同难度级别的任务。

此外,通过改变目标字符串的位置,我们评估模型如何充分利用其完整上下文窗口。
(i)Retrieve.KV:给定一个包含大量键值对的大型JSON对象,模型必须准确检索指定键的值。随机的KV对长上下文LLM提出了挑战,因为输入通常无法压缩,需要严格的O(n)空间进行存储。此任务特别适用于评估长上下文方法中的记忆模糊性。每个会话检索五个KV对,目标KV均匀分布在输入中。
(ii)Retrieve.Prefix-Suffix:给定一个包含可变长度字符串的大型列表,模型必须检索匹配指定前缀和后缀的字符串。此任务特别具有挑战性,需要类似于前缀树的复杂函数。存在仅共享前缀或后缀的干扰项,防止模型依赖简单的查找或归纳头进行有效检索。
(iii)Retrieve.MultiHop:首次在RULER中提出,该任务评估LLM在长输入提示中的多跳追踪能力。模型必须跟踪和回忆关键信息变化,使其非常适合测试KV Cache复用中的长上下文方法。上下文中嵌入了五个多跳变量赋值链,每个测试轮次需要检索确切的多跳链,即所有分配给特定值的变量。
语义检索:除了字符串检索之外,许多现实世界的长上下文应用需要语义理解,例如从文本描述中检索函数或从长文档中回答问题。这些任务在SCBench中至关重要,因为有损的长上下文方法在多请求场景中往往难以抽象或理解信息。
(i)Code.RepoQA:该任务要求模型根据精确的自然语言描述从长源代码块中检索特定函数(包括其名称、输入参数和完整实现)。与原始 RepoQA 基准不同,我们的输入扩展到64K标记,目标函数在代码库中按位置均匀分布。函数描述是使用GPT-4基于函数本身生成的。我们还扩展了仓库和编程语言的范围,包括 Python、C++、 Java、PHP、Rust、Go 和TypeScript。每个测试会话涉及一个GitHub 仓库,模型需要在5轮中每轮检索一个函数。
(ii) En.QA, Zh.QA, En.MultiChoice:这些任务扩展自InfiniteBench,该基准提供了基于虚构小说的高质量、人工标注的QA测试,以消除外部知识的影响。这些任务要求模型从长输入中定位和处理信息,通过聚合或过滤进行推理。主要的两种问题类型是:1)聚合,编译输入中分散的信息(例如,“A总共在食物上花了多少钱?”);2)过滤,从更大的集合中识别特定细节(例如,“A第二次见到B时穿了什么颜色的裙子?”)。在SCBench中,共享相同输入上下文的QA对被组合以创建共享上下文测试会话。
全局信息处理:除了检索之外,一些长上下文任务需要利用和聚合全局上下文信息,例如摘要、统计任务和上下文学习(ICL)。我们的基准包括三个任务,以评估不同长上下文方法在多请求中处理全局信息的能力。
(i)多示例ICL:我们使用来自Big-Bench Hard的数据集来评估多示例ICL能力。这包括三个子任务:日期理解、显著错误翻译检测和跟踪七个打乱的对象。多示例ICL上下文在测试会话的回合之间共享,所有子任务都以四个选项的多项选择题形式呈现。
(ii) Math.Find:我们扩展了来自 InfiniteBench的数学发现任务,将其从仅查找最大值扩展到多个统计值。给定一个大型数组,LLM必须找到最小值或中位数,这需要有效理解全局上下文、比较和统计操作。
(iii) En.Sum:此任务使用来自arXiv的学术论文作为输入,文档长度范围从8K到20K标记。真实摘要平均为654个标记,使用GPT-4为每个文档生成简洁的一句话摘要。每轮中的目标文档在完整上下文长度上均匀分布。
多任务处理:在实际应用中,LLM通常在单个会话中使用共享的输入上下文处理多个任务。例如,用户可能同时请求摘要和内容检索。为了反映这一点,SCBench包括两个多任务处理任务:
(i) Mix.Sum+NIAH:此任务结合了文档摘要和Haystack任务,使用共享输入提示。随机needle均匀插入En.Sum任务。模型在每次测试会话中交替进行摘要和NIAH检索。
(ii) Mix.RepoQA+KV:此任务将RepoQA任务与使用共享输入提示的KV检索相结合。多个KV对均匀插入到RepoQA输入(一大块源代码)中,包括100个KV对,其中四个为目标KV,其余为干扰项。模型在每次测试会话中交替进行RepoQA和KV检索。
3.2 共享上下文模式
除了精心设计的长上下文任务外,我们还包含两种共享上下文模式:多轮和多请求。
(i)多轮模式:包括长上下文聊天、多步推理和长生成CoT。此模式与KV Cache复用的长上下文方法相关,因为不同轮次间可能导致KV Cache信息丢失。我们使用真实答案而不是模型生成的内容作为后续轮次的上下文。
(ii)多请求模式:跨会话或用户的上下文共享,例如共享代码库的协作者。模型可以共享上下文并在请求之间复用KV Cache。评估长上下文方法至关重要,因为一些方法依赖于查询进行稀疏编码/解码。例如,MInference和SnapKV使用输入的最终段(通常是查询)来估计稀疏模式,评估其在没有查询访问时的泛化能力。
4实验与结果
模型与实现细节:我们选择了六个开源长上下文LLMs:Llama-3.1-8B/70B、 Qwen2.5-72B/32B、Llama-3-8B-262K和GLM-4-9B-1M,以及两个门控线性模型:Codestal Mamba 7B和Jamba-1.5-Mini。这个选择涵盖了Transformer、SSM和SSM-Attention混合模型,代表了领先的开源长上下文LLM。为了稳定性,所有实验在四个NVIDIA A100 GPU上使用BFloat16的贪婪解码。我们通过HuggingFace或vLLM使用FlashAttention-2评估模型,并利用MInference减少GPU内存开销。
长上下文方法:我们在基准测试中评估了八种长上下文解决方案类别:门控线性RNN(例如 Codestral-Mamba)、SSM-注意力混合模型(例如Jamba)、稀疏注意力、KV Cache丢弃、提示压缩、KV Cache量化、检索和加载,详见表1。所有方法均在基于Transformer的长上下文 LLM上进行了测试,Codestral-Mamba和Jamba除外。
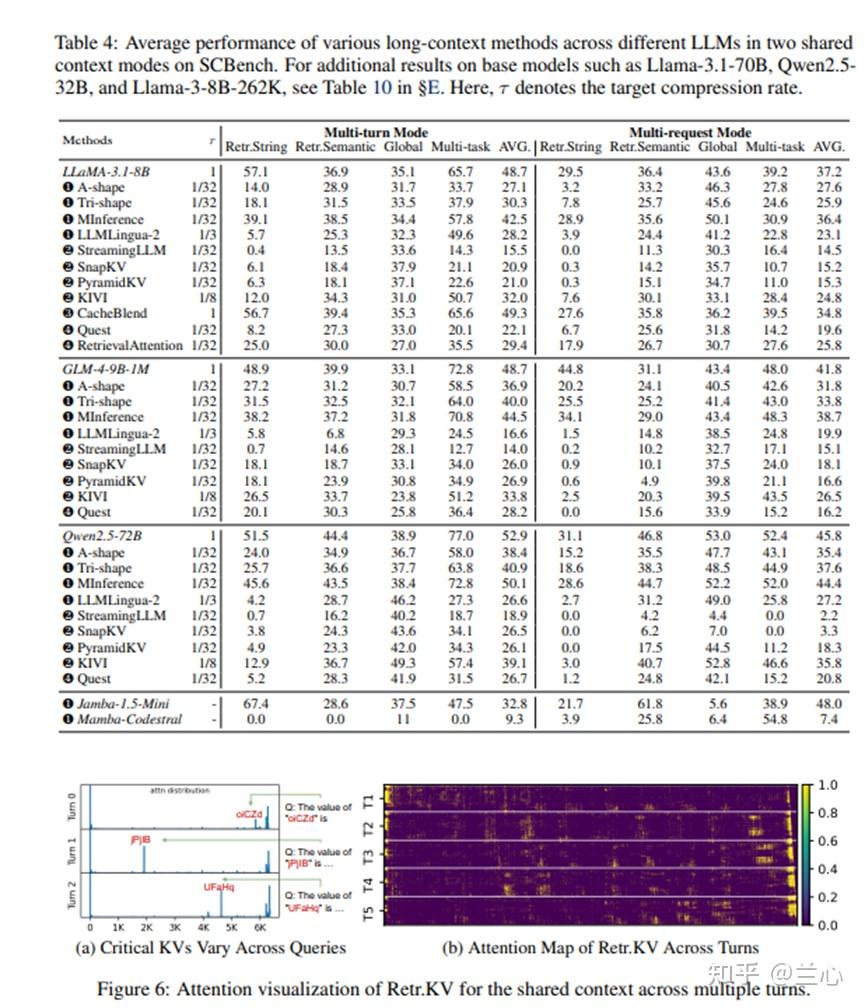
主要结果:包括:1)在检索任务中,除了MInference外,大多数方法表现不佳,尤其是在字符串匹配等精确检索任务中。2)随着请求轮次的增加,稀疏注意力优于稀疏解码,A-shape表现最佳。Tri-shape在A-shape基础上增加了密集底部查询令牌,提高了第一轮性能,但对后续轮次影响不大。它在任务中表现良好,仅次于MInference。我们的分析表明,三角形提高了第一轮指令跟随,从而提升了整体性能,而A-shape破坏了指令信息,导致随机输出。3)KV Cache压缩方法在共享场景中表现不佳,仅在第一轮提供微小的好处。4)提示压缩提高了多示例ICL等全局信息任务的性能,但显著降低了检索相关性能。5)SSM-注意力混合模型在单轮交互中表现良好,但在多轮任务中准确率下降,尤其是在RepoQA和数学任务中。门控线性RNN模型在共享上下文模式中表现不佳。
5分析
Sub-O(n)内存几乎在多轮解码中不可行。图 6b可视化了Retr.KV任务在各轮次中的注意力图。虽然重要的KV在一轮内保持稳定,但在不同查询之间变化显著。这解释了为什么O (k) KV Cache压缩方法在单查询测试中表现良好,但在后续查询中失败。然而,SSM-注意力混合模型Jamba通过使用SSM层并保持O(n)内存以供未来查找,显示出降低内存成本的潜力。另一种有前景的方法是CPU-GPU协作,其中完整的O(n)内存存储在CPU内存中,动态加载相关KV到GPU进行Sub-O(n)解码(。
编码和解码中的稀疏性。我们研究了Sub-O(n)稀疏解码在共享上下文场景中难以维持多个请求的准确性。有趣的是,如果解码保持密集,稀疏方法在编码中表现良好。如图3a所示,使用密集解码(O(n)内存),Tri-Shape和A-Shape实现了强大的多请求性能。相反,将稀疏模式扩展到解码会严重降低性能(例如,StreamingLLM)。即使使用密集编码,稀疏解码方法,特别是KV Cache压缩,在共享上下文场景中表现不佳。这可能源于编码输出中的冗余,而解码在生成中起着至关重要的作用。由于冗余的输入提示,稀疏编码仍然可以捕获关键信息,但稀疏解码削弱了每层的连接性,限制了对关键token的关注。由于稀疏解码依赖于代理token进行全局访问,它限制了复杂注意力函数。我们强调需要更先进的稀疏模式用于稀疏注意力。动态稀疏注意力可以改善连接性并加速信息传播,与静态稀疏模式相比,更好地近似全注意力性能(图9)。
可压缩和不可压缩任务。虽然 O(n)内存对于具有共享上下文的多请求场景至关重要,但对于更简单任务中的高度可压缩输入可以放宽要求。例如,Needle-in-the-Haystack基准测试关键信息(needle)嵌入重复噪声(haystack)中,由于噪声的高可压缩性,允许Sub-O(n)方法实现合理的准确率。类似地,摘要任务涉及可压缩上下文,使Sub-O(n)方法能够平衡效率和性能。然而,对于动态和复杂的输入,Sub-O(n) 方法通常无法保留所有必要信息,导致在具有挑战性的检索任务中表现不佳。涉及随机和不可压缩的键值对和字符串的任务(如Retr.KV和 Retr.Prefix-Suffix)要求模型充分利用其上下文窗口。总之,虽然可压缩任务可能高估模型的能力,但由于效率,Sub-O(n)方法对于更简单的任务仍然可行。
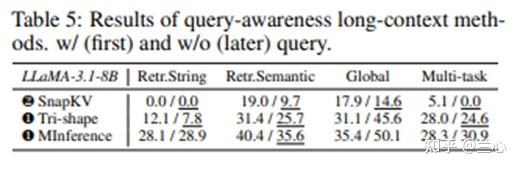
不依赖查询的稀疏方法。在KV Cache复用场景中,长上下文方法依赖查询进行压缩以实现高效的编码或解码。然而,在实际应用中,单个上下文通常在多个查询之间共享,这要求这些方法在没有查询访问的情况下运行。这引发了问题:依赖查询的长上下文方法能否在没有查询的情况下有效泛化?表5比较了三种依赖查询的长上下文方法在有无查询时的性能,突出了在没有查询时性能下降的情况(下划线)。我们发现,KV Cache压缩方法SnapKV和静态稀疏注意力方法Tri-Shape在没有查询时难以保持准确性。相比之下,动态稀疏注意力方法MInference表现出更强的泛化能力,这可能归因于其自适应稀疏模式,特别是注意力图中的对角连接。
6结论
本文解决了评估长上下文方法中的一个关键空白,这些方法传统上专注于单轮交互,而忽略了共享长上下文场景——这在现实世界的LLM应用中很常见。为了弥补这一差距,我们引入了SCBench,这是一个全面的基准测试,评估了12个任务中的长上下文方法,涵盖了字符串检索、语义检索、全局信息处理和多任务处理,并在两种共享上下文模式下进行评估。使用我们的基准测试,我们将长上下文方法分为四个KV Cache中心阶段:生成、压缩、检索和加载。我们在八个最先进的LLM上评估了八种方法类别(例如,门控线性RNN、混合模型、稀疏注意力、KV缓存丢弃、量化、检索、加载和提示压缩),包括Llama-3.1-8B/70B、Qwen2.5-72B/32B、 Llama-3-8B-262K、GLM-4-9B、Codestal Mamba和Jamba-1.5。我们的结果揭示了一个明显的KV Cache管理权衡:O(n)方法在多请求场景中表现出色,而Sub-O(n)方法在单轮设置中表现良好,但在复杂交互中表现不佳。这些发现强调了在共享上下文、多轮场景中评估长上下文方法的必要性,提供了一个更现实的基准和有价值的见解,以改进未来的长上下文模型和架构。
论文来源:https://arxiv.org/abs/2412.10319
以上内容转载自微信公众号—大模型软硬协同优化,链接:https://mp.weixin.qq.com/s/i7nO

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)