论文洞察:大规模LLM服务集群环境下KV Cache特征分析与优化策略
研究通过分析阿里云通义千问大模型服务集群的两类生产环境负载轨迹(Production Traces),系统性地揭示了KV Cache在实际云环境中的工作负载特征,并提出负载感知的缓存淘汰策略,以指导LLM服务中的KV Cache管理,实现吞吐量提升与延迟降低。研究通过分析阿里云通义千问大模型服务集群的两类生产环境负载轨迹(Production Traces),系统性地揭示了KV Cache在实际云
01 研究背景与数据来源
研究背景
本文基于上海交通大学、阿里巴巴在USENIX ATC25上联合发表的研究成果《KV Cache in the Wild: Characterizing and Optimizing KV Cache at a Large Cloud Provider》。
研究通过分析阿里云通义千问大模型服务集群的两类生产环境负载轨迹(Production Traces),系统性地揭示了KV Cache在实际云环境中的工作负载特征,并提出负载感知的缓存淘汰策略,以指导LLM服务中的KV Cache管理,实现吞吐量提升与延迟降低。
两类核心数据集包括:
- 面向消费者场景的Trace A:to-C,涵盖聊天机器人、文件分析、多模态交互等服务,具备显著的人机交互特征
- 面向企业API调用的Trace B:to-B,纯自动化API请求
02 核心问题识别
现有LRU(Least Recently Used)、FIFO(First In First Out)等负载无关(Workload-Agnostic)的缓存淘汰策略存在显著局限:其未充分考虑LLM服务中KV Cache复用的独特特征,包括单轮与多轮请求的差异性、短暂的生命周期,以及请求类型对复用模式的影响。
03 核心设计与创新
针对上述问题,研究提出基于负载特征的优先级计算机制:
KV Cache优先级计算
综合三项关键指标计算KV块(KV Block)优先级: - 复用概率分布:基于请求类别拟合指数分布,预测复用概率;
- 空间局部性:赋予前缀匹配更高的优先级权重;
- 生命周期约束:基于短暂的生命周期特征,限制概率计算的时间窗口。
算法实现
优先级最低者优先淘汰。系统为每个负载类别维护按其最后访问时间排序的KV Cache块优先级队列,将淘汰决策复杂度从O(N)降至O(W)(W为负载类别数,通常为数十量级),显著降低运行时性能开销。
04 KV Cache工作负载核心特征
复用率特征
生产环境中KV Cache呈现较高的重用率,但低于理论预期:to-C场景复用率为62%,to-B场景为54%,均低于部分文献报告的80%缓存命中率理想值。
对话模式与复用来源 - to-C场景:以多轮交互为主,多轮对话占比47%-51%。
- to-B场景:几乎为单轮API请求(多轮占比仅0.08%),但单轮对话贡献了97%的缓存命中。其核心原因在于API调用任务通常共享系统级Prompt或特定文档内容,且QPS较高(>10QPS),能够高频复用具有相同前缀的KV Cache。
跨用户复用局限性
跨用户的KV Cache复用较为有限,多数复用发生在用户内部。这表明用户倾向于使用自定义Prompt而非标准化第三方模板,导致跨用户共享概率降低。
分布式偏斜性
KV Cache复用呈现显著的偏斜分布:to-C场景中19%的用户请求贡献90%的复用量,to-B场景中该比例仅为4%。成因包括:请求在用户间分布不均(to-B场景15%的用户贡献90%的请求量);特定用户的请求模式产生更高复用(如偏好多轮对话的用户)。
时间局限性
KV Cache复用周期极短:to-C场景80%的复用发生在10分钟内,to-B场景80%的复用在10秒内完成。给定时间段与请求类别下,复用时间遵循指数分布,具备基于历史数据的可预测性。
空间局限性
从头开始缓存(Prefix Caching)可实现最优空间局部性。文本与多模态请求表现出显著的空间局部性;而文件分析、搜索类请求因系统Prompt高度依赖用户输入,缺乏空间局部性。
容器需求特征
to-B场景中KV Cache生命周期极短(P99生命周期仅97秒)。研究表明,采用LRU策略时,每GPU配备2倍于其HBM容量的KV Cache存储,即可在常见GQA模型上接近无限容量下的理想命中率,无需引入复杂的CPU-RDMA-SSD多级存储架构。
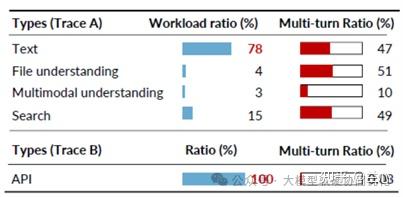
图:工作负载类型和请求的多轮比例
05 实验验证与结论
研究在vLLM框架中集成该策略,并针对Qwen2-7B、Llama2-13B、Llama3-70B模型进行测试。
- 相较LRU、LFU、S3-FIFO等基线策略,KV Cache命中率提升8.1%-23.9%,最高达23.9%;
- 队列化首Token时间(QTTFT, Queued Time To First Token)降低28.3%-41.9%。
研究价值
本研究为LLM服务的KV Cache系统设计提供了数据驱动的优化指导,在性能与资源成本之间实现有效平衡,对大规模智算中心的KV Cache管理具有重要实践意义。
论文链接:
https://www.usenix.org/conference/atc25/presentation/wang-jiahao
以上内容转载自微信公众号—大模型软硬协同优化,链接:01 研究背景与数据来源unsetunset
研究背景
本文基于上海交通大学、阿里巴巴在USENIX ATC25上联合发表的研究成果《KV Cache in the Wild: Characterizing and Optimizing KV Cache at a Large Cloud Provider》。
研究通过分析阿里云通义千问大模型服务集群的两类生产环境负载轨迹(Production Traces),系统性地揭示了KV Cache在实际云环境中的工作负载特征,并提出负载感知的缓存淘汰策略,以指导LLM服务中的KV Cache管理,实现吞吐量提升与延迟降低。
两类核心数据集包括:
- 面向消费者场景的Trace A:to-C,涵盖聊天机器人、文件分析、多模态交互等服务,具备显著的人机交互特征
- 面向企业API调用的Trace B:to-B,纯自动化API请求unsetunset
02 核心问题识别
现有LRU(Least Recently Used)、FIFO(First In First Out)等负载无关(Workload-Agnostic)的缓存淘汰策略存在显著局限:其未充分考虑LLM服务中KV Cache复用的独特特征,包括单轮与多轮请求的差异性、短暂的生命周期,以及请求类型对复用模式的影响。unsetunsetunset
03 核心设计与创新
针对上述问题,研究提出基于负载特征的优先级计算机制:
KV Cache优先级计算
综合三项关键指标计算KV块(KV Block)优先级:
- 复用概率分布:基于请求类别拟合指数分布,预测复用概率;
- 空间局部性:赋予前缀匹配更高的优先级权重;
- 生命周期约束:基于短暂的生命周期特征,限制概率计算的时间窗口。
算法实现
优先级最低者优先淘汰。系统为每个负载类别维护按其最后访问时间排序的KV Cache块优先级队列,将淘汰决策复杂度从O(N)降至O(W)(W为负载类别数,通常为数十量级),显著降低运行时性能开销。
04 KV Cache工作负载核心特征unset
复用率特征
生产环境中KVCache呈现较高的重用率,但低于理论预期:to-C场景复用率为62%,to-B场景为54%,均低于部分文献报告的80%缓存命中率理想值。
对话模式与复用来源
- to-C场景:以多轮交互为主,多轮对话占比47%-51%。
- to-B场景:几乎为单轮API请求(多轮占比仅0.08%),但单轮对话贡献了97%的缓存命中。其核心原因在于API调用任务通常共享系统级Prompt或特定文档内容,且QPS较高(>10QPS),能够高频复用具有相同前缀的KV Cache。
跨用户复用局限性
跨用户的KV Cache复用较为有限,多数复用发生在用户内部。这表明用户倾向于使用自定义Prompt而非标准化第三方模板,导致跨用户共享概率降低。
分布式偏斜性
KV Cache复用呈现显著的偏斜分布:to-C场景中19%的用户请求贡献90%的复用量,to-B场景中该比例仅为4%。成因包括:请求在用户间分布不均(to-B场景15%的用户贡献90%的请求量);特定用户的请求模式产生更高复用(如偏好多轮对话的用户)。
时间局限性
KV Cache复用周期极短:to-C场景80%的复用发生在10分钟内,to-B场景80%的复用在10秒内完成。给定时间段与请求类别下,复用时间遵循指数分布,具备基于历史数据的可预测性。
空间局限性
从头开始缓存(Prefix Caching)可实现最优空间局部性。文本与多模态请求表现出显著的空间局部性;而文件分析、搜索类请求因系统Prompt高度依赖用户输入,缺乏空间局部性。
容器需求特征
to-B场景中KV Cache生命周期极短(P99生命周期仅97秒)。研究表明,采用LRU策略时,每GPU配备2倍于其HBM容量的KV Cache存储,即可在常见GQA模型上接近无限容量下的理想命中率,无需引入复杂的CPU-RDMA-SSD多级存储架构。
图:工作负载类型和请求的多轮比例
05 实验验证与结论
研究在vLLM框架中集成该策略,并针对Qwen2-7B、Llama2-13B、Llama3-70B模型进行测试。
- 相较LRU、LFU、S3-FIFO等基线策略,KV Cache命中率提升8.1%-23.9%,最高达23.9%;
- 队列化首Token时间(QTTFT, Queued Time To First Token)降低28.3%-41.9%。
研究价值
本研究为LLM服务的KV Cache系统设计提供了数据驱动的优化指导,在性能与资源成本之间实现有效平衡,对大规模智算中心的KV Cache管理具有重要实践意义。
论文链接
https://www.usenix.org/conference/atc25/presentation/wang-jiahao
以上内容转载自微信公众号—大模型软硬协同优化,链接:https://mp.weixin.qq.com/s/AJnG

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)