智谱新年大模型-GLM-5
智谱开源发布GLM-5技术报告,该模型在GLM-4.5基础上实现了显著升级:参数规模从3550亿扩展至7440亿,预训练数据量从23万亿token增至28.5万亿token。关键创新包括: 采用DeepSeek稀疏注意力机制(DSA)降低推理成本 构建异步强化学习基础设施提升训练效率 提出异步Agent强化学习算法优化决策质量 全面适配国产算力平台 GLM-5在SWE-bench等测试中取得开源模
新年新气象,智谱开源 GLM-5 技术报告,40 页,副标题是“from Vibe Coding to Agentic Engineering”。
arxiv: https://arxiv.org/pdf/2602.15763
github: https://github.com/zai-org/GLM-5

正式发布 GLM-5,旨在应对复杂系统工程和长时域智能体任务。扩展性仍然是提升通用人工智能 (AGI) 智能效率的关键途径之一。与 GLM-4.5 相比,GLM-5 的参数规模从 3550 亿(320 亿活跃参数)扩展至 7440 亿(400 亿活跃参数),预训练数据量也从 23 万亿个 token 增加到 28.5 万亿个 token。GLM-5 还集成了 DeepSeek 稀疏注意力机制 (DSA),在大幅降低部署成本的同时,保持了长时域上下文处理能力。
GLM-5,这是一款旨在推动编程范式从“Vibe Coding”(氛围编程)转向“Agentic Engineering”(智能体工程)的下一代基础模型。GLM-5 在前代模型 GLM-4.5 的智能体、推理与编程(Agentic, Reasoning and Coding, ARC)能力基础上,采用稀疏注意力(DeepSeek Sparse Attention,DSA)以大幅降低推理成本,同时保持长上下文能力无损。为了让模型更好地与各类任务对齐,构建了一套新型异步强化学习(RL)基础设施,通过将生成过程与训练过程解耦,从而大幅提升了后训练的迭代效率。此外,还提出了全新的异步 Agent 强化学习算法,进一步提升强化学习的效果,使模型能够更有效地从复杂、长程交互中学习。基于上述创新,GLM-5 在主流的开放基准测试中实现了 SOTA 性能。最关键的是,GLM-5 在真实世界编程任务中展现出前所未有的能力,在处理端到端软件工程挑战方面超越了此前所有开源基线。代码、模型及更多信息请访问:https://z.ai/blog/glm-5
一、 引言
Vibe Coding 是什么?是你跟 AI 说「帮我写个贪吃蛇」,它给你写出来。
Agentic Engineering 是什么?是你说「这个系统有个 bug」, AI 自己去找问题、改代码、跑测试,全程不用你管。
从“辅助写代码”到“独立完成工程任务”,这个转变对模型训练提出了完全不同的要求。对这份报告进行了解读。
追求 AGI 并非单纯扩张参数规模,而是要从底层重构智能效率与自主演进架构。在 GLM-4.5 中,成功验证了将智能体、推理与编程(ARC)能力融合至单一 MoE 架构的可行性,并在多项基准测试中取得不错的成绩。不过,随着 LLM 从静态知识库向主动问题求解器转变,计算成本与现实适应性成为核心瓶颈,这在复杂的软件工程场景中表现得尤为明显。
为此,推出了下一代旗舰模型 GLM-5 以解决上述问题。GLM-5 在性能与计算效率上实现了跃升,不仅在 ArtificialAnalysis.ai、LMArena 文本与代码等主要榜单中均达到 SOTA 水平,更重塑了真实世界的编程标准。它突破了 SWE-bench 等传统静态测评的考察边界,在处理复杂的端到端软件开发任务时,展现出了前所未有的强大能力。
二、数据验证:
GLM-5 发布后,硅谷顶级风投机构 a16z 发布了一组数据:开源大模型和顶级闭源模型之间的能力差距,正在以肉眼可见的速度快速收窄。
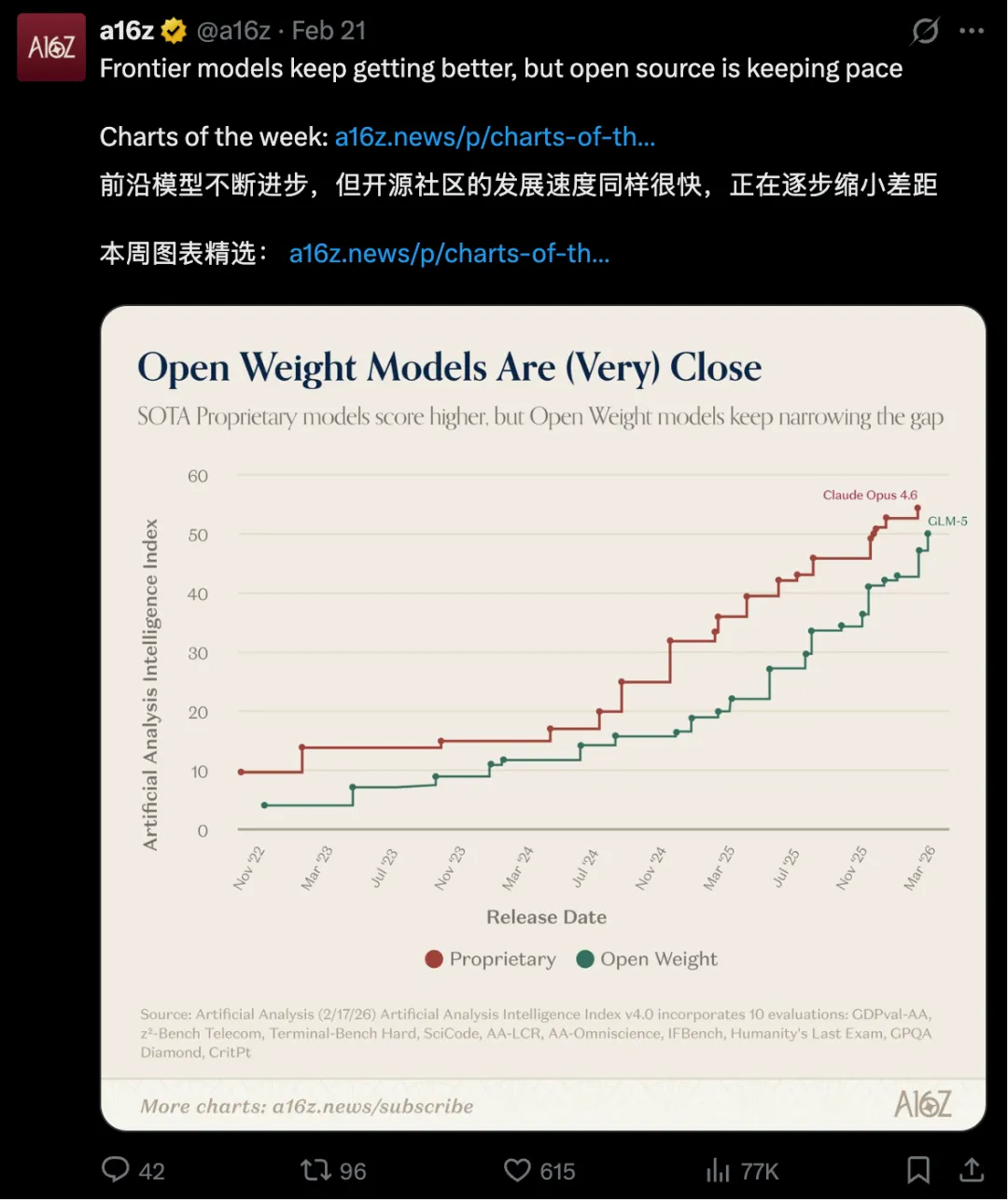
测评:
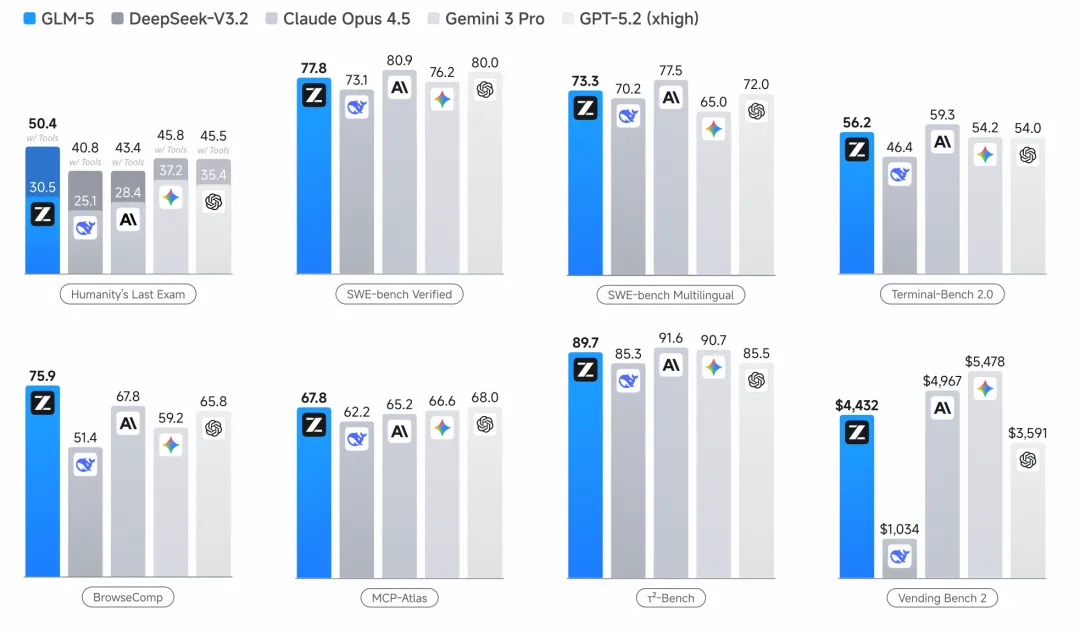
SWE-bench Verified 77.8%,开源模型最高。这个测试要求模型修复真实 GitHub 仓库里的 bug。几万行代码的项目,找问题、理解上下文、写方案、跑通测试,全流程完成。
BrowseComp 75.9%,这是所有模型里最高的。这个任务要求模型自己决定搜什么、点哪些链接、从多个网页提取信息、综合得出答案。
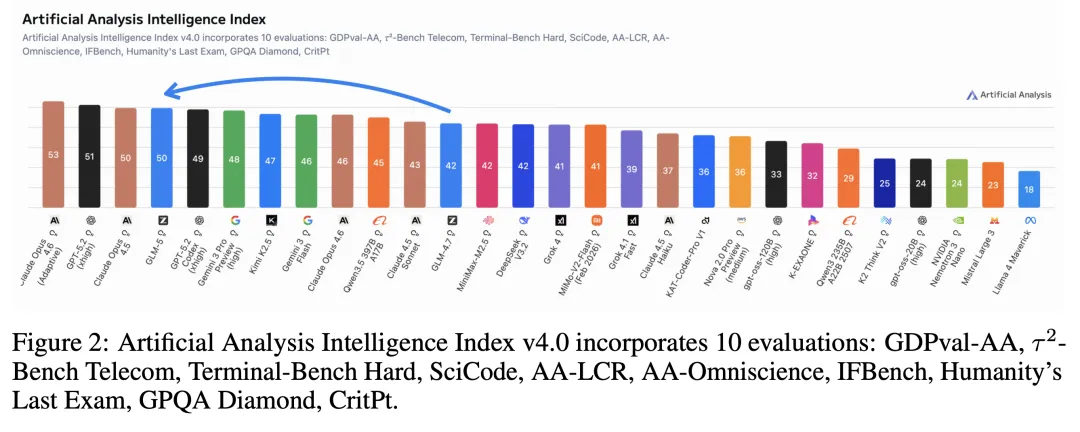
Artificial Analysis Intelligence Index 拿了 50 分,开源模型第一次达到这个水平。
这些数据指向一个方向:GLM-5 是为 Agent 场景优化的。从 a16z 的数据背书,到 LMArena 的真实用户投票,GLM-5 在 coding 和 agentic 能力上,已经站到了全球第一梯队。
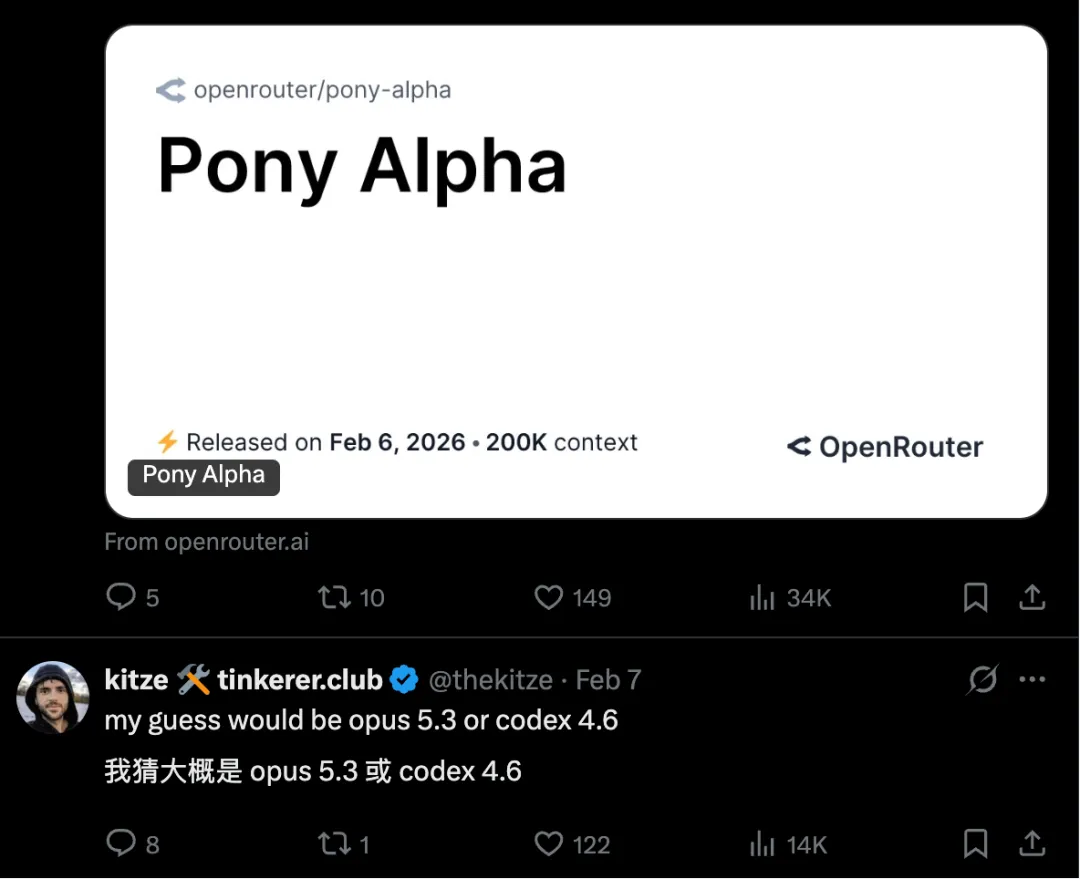
值得一提的是,GLM-5 发布前做过匿名盲测,代号 Pony Alpha,被很多海外大 V 认为是 Claude 或 Grok。而且GLM-5 从发布之初就原生适配了华为昇腾、摩尔线程等七大国产芯片平台,完成了从内核到框架的深度优化。
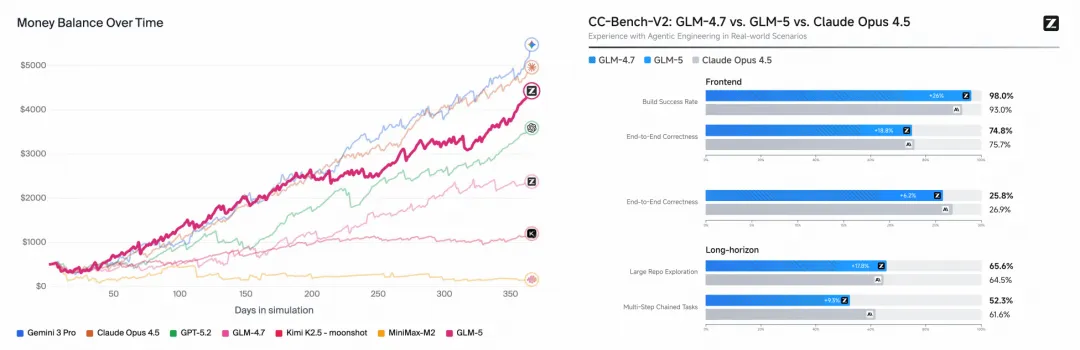
进一步展示了基于内部评估套件 CC-Bench-V2 的测试结果。数据显示,GLM-5 在前端、后端及长程任务上的表现均显著超越了前代 GLM-4.7,进一步缩小了与 Claude Opus 4.5 的差距。
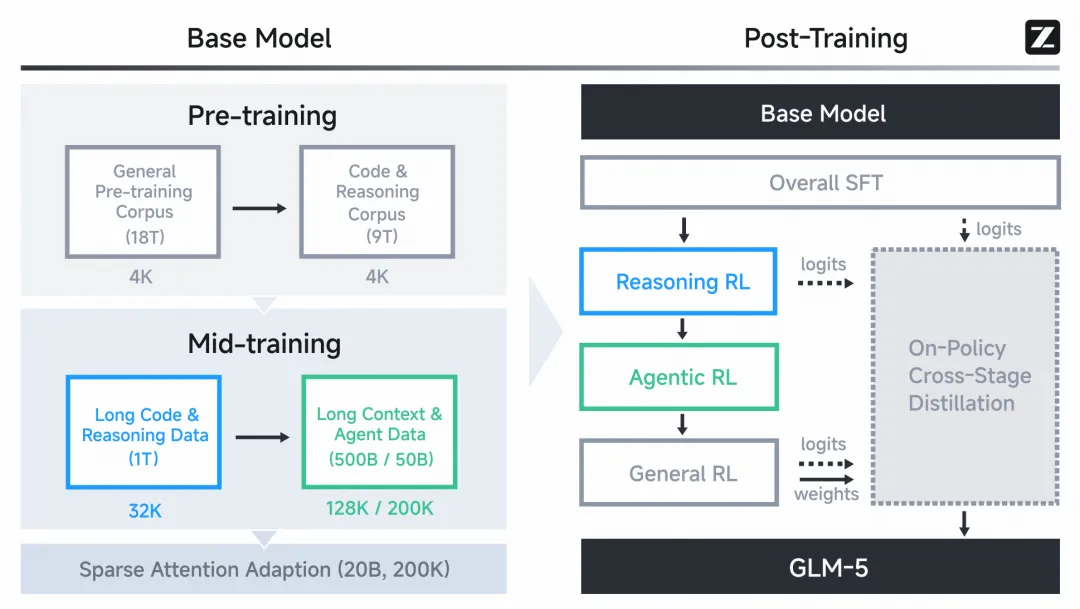
详细展示了 GLM-5 的整体训练流程。在基础模型训练阶段,使用了规模达 27 万亿 token 的海量语料库,并在训练初期重点引入代码与推理数据。随后进入中期训练(Mid-training)阶段,将上下文窗口从 4K 逐步扩展至 200K,并专门针对长上下文 Agent 数据进行训练,以保障模型在复杂工作流中的执行稳定性。在后训练(Post-training)阶段,引入了一套序列化的强化学习(RL)流程:依次在推理、智能体、通用领域进行强化学习。值得注意的是,在全流程中应用了跨阶段在线蒸馏(Cross-stage online distillation)技术,有效克服了灾难性遗忘问题。
总体而言,GLM-5 能够实现性能的大幅跃升,主要得益于以下四大技术创新:
第一,引入 DSA 稀疏注意力机制(DeepSeek Sparse Attention, DSA)。 这一全新架构极大降低了训练与推理成本。此前的 GLM-4.5 依赖标准 MoE 架构提升效率,而 DSA 机制则使 GLM-5 能够根据 Token 的重要性动态分配注意力资源。在不折损长上下文理解和推理深度的前提下,算力开销得以大幅削减。得益于此,将模型参数规模成功扩展至 744B(7440 亿),同时将训练 Token 规模提升至 28.5T(28.5 万亿)。
第二,构建全新的异步 RL 基础设施。 基于 GLM-4.5 时期 slime 框架“训练与推理解耦”的设计,新基建进一步实现了“生成与训练”的深度解耦,将 GPU 利用率推向极致。该系统支持模型开展大规模的智能体(Agent)轨迹探索,大幅减缓了以往拖慢迭代速度的同步瓶颈,让 RL 后训练流程的效率实现了质的飞跃。
第三,提出全新的异步 Agent RL 算法。 该算法旨在全面提升模型的自主决策质量。GLM-4.5 曾依靠迭代自蒸馏和结果监督来训练 Agent;而在 GLM-5 中,研发的异步算法使模型能够从多样化的长周期交互中持续学习。这一算法针对动态环境下的规划与自我纠错能力进行了深度优化,这也正是 GLM-5 能够在真实编程场景中表现卓越的底层逻辑。
第四,全面拥抱国产算力生态。 从模型发布伊始,GLM-5 就原生适配了中国 GPU 生态。已完成从底层内核到上层推理框架的深度优化,全面兼容七大主流国产芯片平台:华为昇腾、摩尔线程、海光、寒武纪、昆仑芯、沐曦与燧原。
凭借上述进步,GLM-5 不仅是一个更强大的模型,更是下一代 AI Agent 更高效、更实用的基础模型。向社区开源 GLM-5,以进一步推动高效的、面向 Agent 的通用人工智能的发展。
三、完整的训练
要训练出真正能干活的 Agent,GLM-5 的构建了一套完整的训练体系。
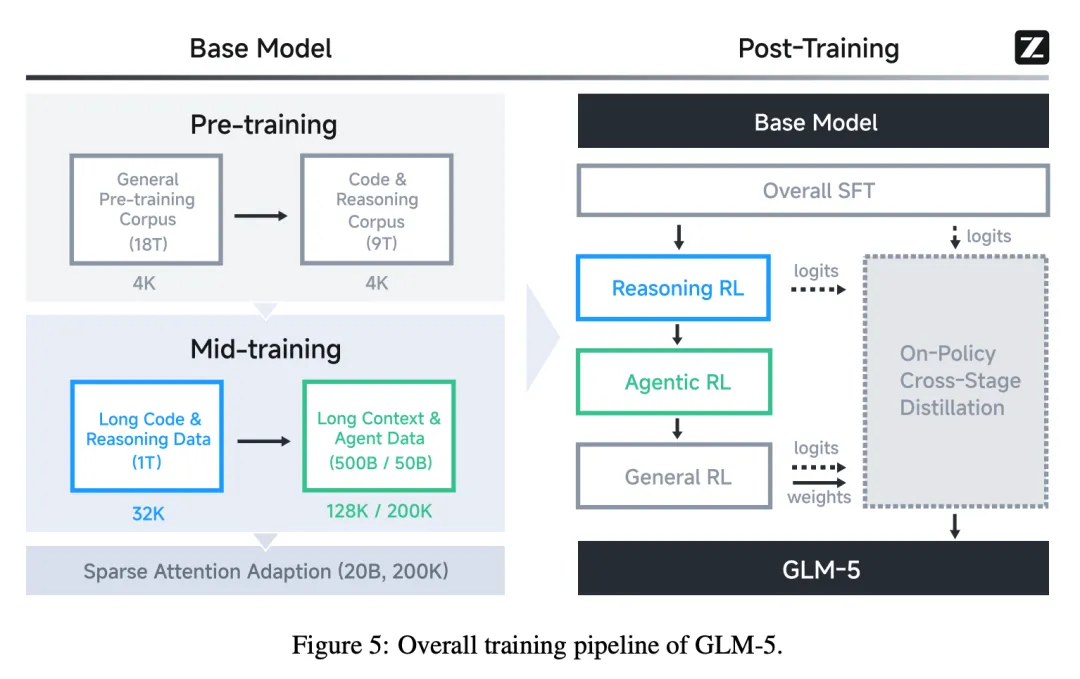
与 GLM-4.5 类似,GLM-5 的基础模型经历两个阶段:用于通用语言和编程能力的预训练,以及用于 Agent 和长上下文能力的中期训练。增加了 GLM-5 所有训练阶段的训练 token 预算,基础模型总训练量达 28.5 万亿 token。
与 GLM-4.5 类似,GLM-5 的基础模型经历两个阶段:用于通用语言和编程能力的预训练,以及用于 Agent 和长上下文能力的中期训练。增加了 GLM-5 所有训练阶段的训练 token 预算,基础模型总训练量达 28.5 万亿 token。
3.1 预训练
与 GLM-4.5 类似,GLM-5 的基础模型经历两个阶段:用于通用语言和编程能力的预训练,以及用于 Agent 和长上下文能力的中期训练。增加了 GLM-5 所有训练阶段的训练 token 预算,基础模型总训练量达 28.5 万亿 token。
3.1.1预训练数据
网页数据。 在 GLM-4.5 数据流程的基础上,完善了海量网页数据集的筛选标准。引入了另一个基于语句嵌入的 DCLM 分类器,以识别和汇聚标准分类器之外的高质量数据。为应对长尾知识挑战,利用世界知识分类器,通过维基百科条目和 LLM 标注数据优化,从原本中低质量数据中筛选有价值信息。
代码数据。 通过更新主要代码托管平台的快照和更大规模的含代码网页集合来扩充代码预训练语料库,使模糊去重后的 token 增加 28%。为提升语料库完整性并减少噪声,修复了 Software Heritage 代码文件中的元数据对齐问题,并采用了更精准的语言分类流程。遵循 GLM-4.5 的质量感知采样策略处理源代码和代码相关网页文档。此外,还为更多低资源编程语言(如 Scala、Swift、Lua 等)训练了专用分类器,提升了这些语言的采样质量。
数学与科学数据。 从网页、书籍和论文中收集高质量数学与科学数据,以进一步增强推理能力。具体而言,完善了网页内容提取流程以及书籍和论文的 PDF 解析机制,以提升数据质量。采用大型语言模型对候选文档进行评分,仅保留最具教育价值的内容。对于长文档,开发了分块聚合评分算法以提升评分精度。过滤流程严格避免使用合成、AI 生成或模板类数据。
3.2 中期训练
在 GLM-4.5 引入的中期训练框架基础上,GLM-5 扩大了训练规模并延长了最大上下文长度,以进一步增强模型的推理、长上下文和 Agent 能力。
扩展上下文与训练规模。 分三个阶段逐步扩展上下文窗口:32K(1T token)、128K(500B token)和 200K(50B token)。与 GLM-4.5 最大 128K 相比,额外的 200K 阶段显著提升了模型处理超长文档和复杂多文件代码库的能力。长文档和合成 Agent 轨迹在后期阶段相应地被上采样。
软件工程数据。 保留了将仓库级代码文件、提交差异、GitHub issues、拉取请求和相关源文件拼接成统一训练序列的范式。在 GLM-5 中,放宽了仓库级过滤标准以扩大合格仓库池,获得约 1000 万个 issue-PR 对,同时加强了单个 issue 级别的质量过滤以降低噪声。还为每个 issue-PR 对检索了更多相关文件,产生了更丰富的开发上下文,并扩大了真实软件工程场景的覆盖范围。过滤后,issue-PR 部分的数据集包含约 160B token。
长上下文数据。 长上下文训练集包含自然数据和合成数据。自然数据从书籍、学术论文和通用预训练语料库文档中精选,采用多阶段过滤(困惑度、去重、长度)并对知识密集型领域进行上采样。在合成数据构建中,受 NextLong 和 EntropyLong 启发,采用多种技术构建长程依赖关系。高度相似的文本通过交错打包聚合成序列,旨在缓解“中间丢失”现象并提升各类长上下文任务的性能。在 200K 阶段,额外加入了少量 MRCR 类数据,并设计了多种变体以扩展 OpenAI 原始范式,以增强扩展多轮对话中的召回能力。
3.3 后训练
GLM-5 的后训练阶段旨在将基础模型转化为具备强大推理、编程和 Agent 能力的高效助手。流程遵循渐进式对齐策略:从引入复杂交错思考模式的多任务 SFT 开始,随后是专门针对推理和 Agent 任务的 RL 阶段,最后是面向人类风格对齐的通用 RL 阶段。通过跨阶段在线蒸馏作为最终精炼步骤,GLM-5 有效减轻了能力退化,同时充分利用了每个训练阶段的性能增益。
GLM-5 的强化学习分三个阶段:
Reasoning RL: 训练推理能力,用数学题、科学问题、算法竞赛这类有标准答案的任务。
Agentic RL: 训练 Agent 能力,用真实软件工程任务、终端操作、多步搜索任务。这里用的就是 Slime 框架。
General RL: 训练对话能力,用开放式对话、创意写作、角色扮演等任务。
RL 算法。 RL 算法以 GRPO 为基础,并引入 IcePop 技术来缓解训练-推理不匹配问题,即 RL 优化过程中推理分布与训练分布之间的差异。明确区分了用于梯度更新的训练模型和用于轨迹采样的 推理模型。与原始 IcePop 公式相比,去除了 KL 正则项,来加速 RL 的改进。训练完全以同策略进行,group 大小为 32,batch 大小为 32。
为提升 GLM-5 的 Agent 性能,开发了一套完全异步且解耦的 RL 框架,并在编程和搜索 Agent 任务上优化了 GLM-5。原生的同步 RL 在长程 Agent rollout 时会导致大量的 GPU 时间浪费。通过 Multi-Task Rollout Orchestrator 将推理引擎和训练引擎解耦,多个的 Agent 任务中实现了高吞吐量的联合训练。
多维优化目标。将通用强化学习(General RL)的优化目标分解为三个维度:正确性、情商、特定任务能力。
正确性维度是回复质量的基石。它针对广泛存在的各种错误类型,例如指令不遵循、逻辑矛盾、事实不准确、知识幻觉、语言不流畅等错误类型,这些错误会破坏回复的可用性。正确性维度的优化目标是降低错误率,使回复质量达到可用的基准线。将其视为其他优化的先决条件:如果回复包含错误(例如事实错误或误解了用户的意图),无论它表面上看起来多么完美,都可能对用户造成实质性的误导。
情商维度在正确性之上进一步优化用户体验。它旨在生成具有同理心、富有洞察力且在风格上接近自然人类交流的回复,从而使与模型的交互更加自然且引人入胜。
特定任务能力维度针对各种具体任务进行细粒度的优化。在正确性的基础上,它旨在将各任务类别中的回复从“仅仅是正确的”提升到“真正高质量的”。该维度涵盖了广泛的任务领域,包括写作、文本处理、主观与客观问答、角色扮演、翻译等各种领域。每个任务领域都需要不同的奖励信号,因此采用了混合奖励系统。
四、 ARC 基准测试评估
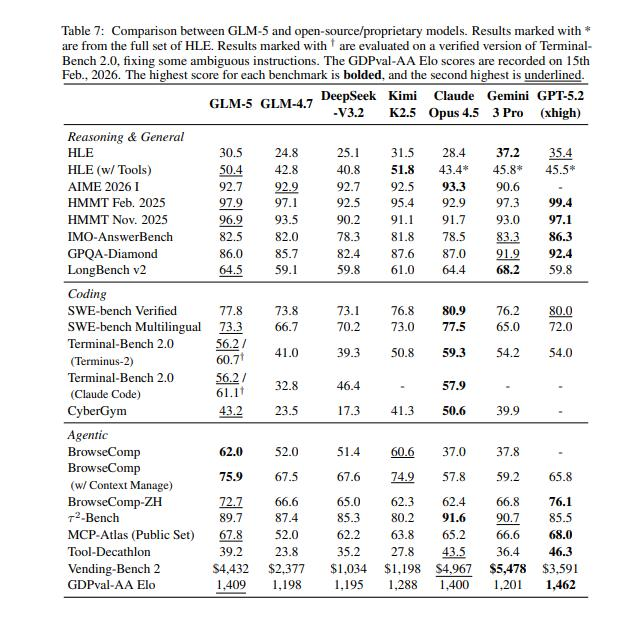
报告了 ARC 基准测试的主要结果,将 GLM-5 与 GLM-4.7、DeepSeek-V3.2、Kimi-K2.5、Claude Opus 4.5、Gemini 3 Pro 和 GPT-5.2(xhigh)进行比较。总体而言,GLM-5 相对 GLM-4.7 实现了显著提升,在开源模型中达到业界最优性能,缩小了与 Claude Opus 4.5 等闭源模型的差距。
五、 结论
从 Vibe Coding 到 Agentic Engineering,这场转变的本质是扩展范式的根本跃迁。 过去训练模型,信奉的是蛮力美学——堆参数、堆数据、堆算力,模型一经炼成、权重发布,便宣告终局。如今训练 Agent,追求的却是精巧的规模化——异步架构(Slime)打破时间的桎梏,稀疏注意力(DSA)突破空间的边界,能力分层、可验证环境、基座优化,每一步都在用结构性的聪明替代粗放式的庞大。 更深层的意义在于,智谱选择将这套方法论全面开源。Agent 训练的神秘黑箱由此被撬开,从少数顶尖团队的密室实验,转变为可复现、可迭代、可超越的公共工程。单一模型的能力或许可以被追赶,但工程范式的开放才是推动整个生态进化的真正引擎。
更多详细内容查看链接

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)