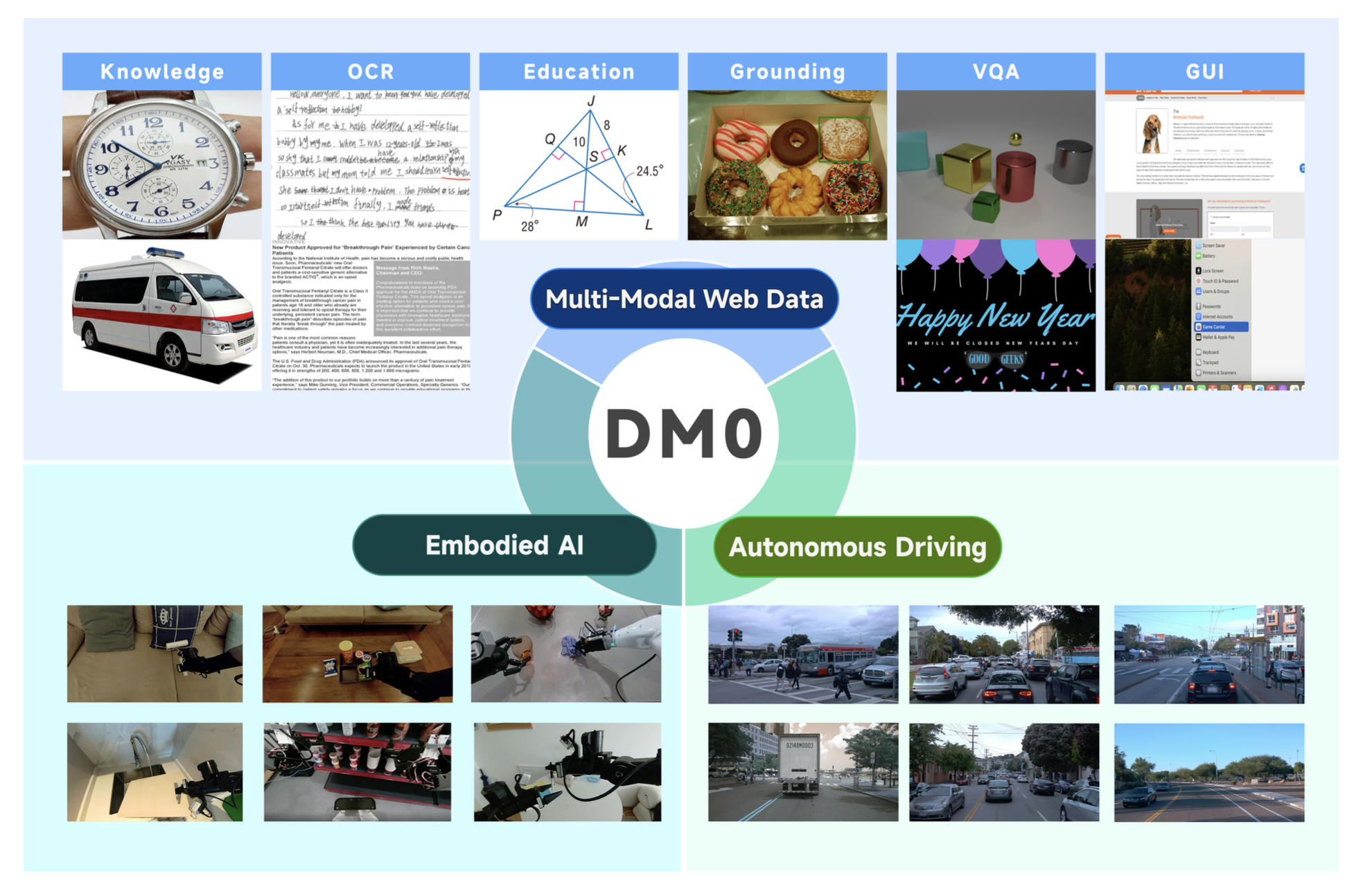
DM0:面向物理人工智能的具身原生视觉-语言-动作模型
26年2月来自原力灵机和阶跃AI的论文“DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI”。本文突破将互联网预训练模型应用于物理任务的传统范式,提出DM0,一个专为物理人工智能设计的具身原生视觉-语言-动作(VLA)框架。与将物理基础事后微调的方法不同,DM0从一开始就通过学习异构数据源,统一具身操作和
26年2月来自原力灵机和阶跃AI的论文“DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI”。
本文突破将互联网预训练模型应用于物理任务的传统范式,提出DM0,一个专为物理人工智能设计的具身原生视觉-语言-动作(VLA)框架。与将物理基础事后微调的方法不同,DM0从一开始就通过学习异构数据源,统一具身操作和导航。其方法遵循一个全面的三阶段流程:预训练、中训练和后训练。首先,用各种语料库(无缝集成网络文本、自动驾驶场景和具身交互日志)对视觉-语言模型(VLM)进行大规模统一预训练,以联合获取语义知识和物理先验。随后,在VLM之上构建一个流匹配动作专家。为了协调高层推理和底层控制,DM0采用一种混合训练策略:对于具身数据,动作专家的梯度不会反向传播到VLM,以保持泛化表征;同时,VLM仍然可以在非具身数据上进行训练。此外,引入一种具身空间支架(scaffolding)策略来构建空间思维链(CoT)推理,从而有效地约束动作解空间。在RoboChallenge基准测试上的实验表明,DM0在Table30上的专家和通用两种场景下均取得了最先进的性能。
DM0如图所示:
模型架构
如图所示,DM0 模型是一个端到端的视觉-语言-动作 (VLA) 模型,支持在涵盖各种任务和数据分布的大规模数据集上进行联合训练,包括网络规模的多模态数据、驾驶场景数据和具身数据。所提出的架构由两个核心组件构成:(i) 基于 Qwen3-1.7B 大语言模型 (LLM) (Yang ,2025a) 构建的视觉-语言模型 (VLM),并增强感知编码器 (PE) (Bolya,2025),从而在机器人环境中实现多模态感知、语义理解和具身推理;(ii) 基于流匹配 (Lipman,2022) 的动作专家,根据从 VLM 主干网络提取的KV缓存生成连续的控制动作。多视角图像被调整为 728 × 728 像素并输入到 PE 中,之后使用两个步长为 2 的 3 × 3 卷积层将图像嵌入下采样 4 倍。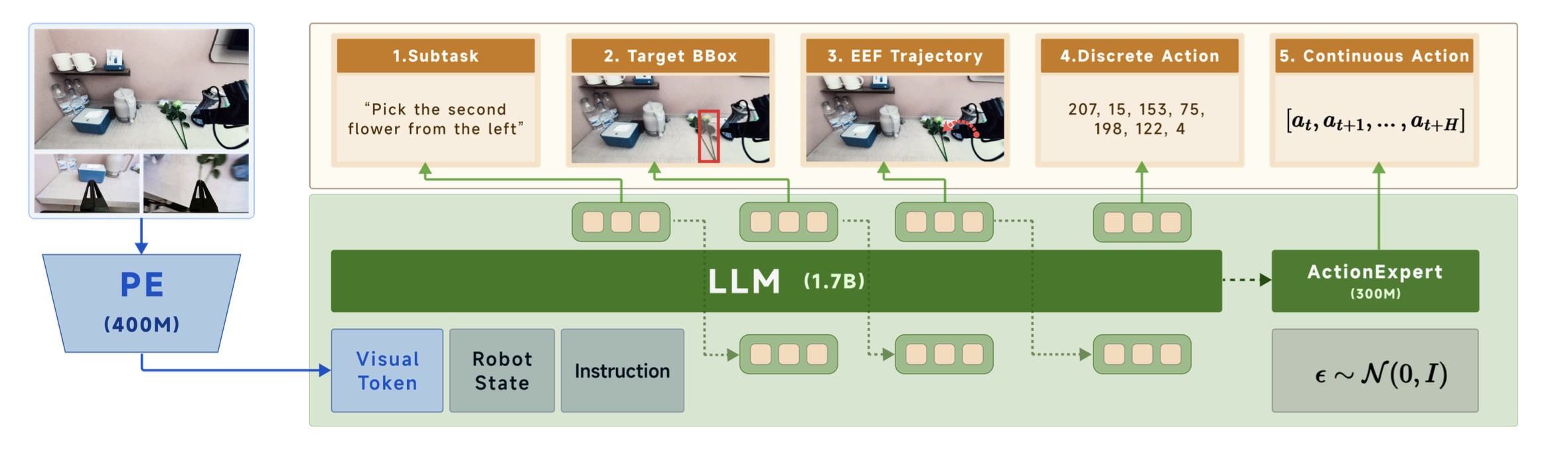
在推理阶段,DM0 支持两种可选的推理模式。在第一种模式下,模型直接从多模态观测和语言指令预测连续动作序列。在第二种模式下,模型首先生成用于具身推理的文本输出,然后根据这些输出对动作专家进行条件化,以生成连续动作。
多源混合训练
一些先前的研究(Driess et al., 2025;Zhang et al., 2026)探讨将视觉-语言模型(VLM)与动作专家相结合的统一训练范式,以实现端到端学习。尽管这些方法架构简洁,但语言和连续控制目标的联合优化已被证实会对预训练VLM中保留的语义表征产生不利影响,从而可能削弱其语言理解和推理能力。
采用一种受知识隔离(KI)(Driess et al., 2025)启发的混合梯度策略,该策略在基于具身数据进行训练时将梯度与动作专家解耦,从而防止预训练VLM中语义知识的流失。同时,VLM继续使用非具身数据进行更新,使模型能够进一步提升其通用语言和视觉理解能力。此外,VLM 还受到监督,用于预测离散动作tokens,从而鼓励其编码与动作相关的语义,这有利于下游动作预测。
VLM 通过最小化自回归交叉熵损失 L_AR 进行训练,以预测具身推理文本和离散动作tokens。动作专家通过最小化流匹配(FM)损失 L_FM 来预测连续动作序列。总体训练目标定义为两种损失的加权组合。
具身空间支架(scaffolding)
在联合训练阶段,引入一组辅助目标,这些目标被组织成一个分层预测框架,以提供结构化的监督。具体来说,模型被训练以按顺序执行以下任务:
(i) 子任务预测:预测细粒度的任务描述,将整体任务分解为一系列可解释和可管理的步骤。
(ii) 目标边框预测:预测视觉观察范围内目标物体或目标相关区域的边界框。
(iii) 末端执行器轨迹预测:预测机器人末端执行器在主摄像头视图中指定视域内的未来轨迹。
(iv) 离散动作预测:预测代表机器人控制指令的离散动作tokens。
这种设计在抽象层次上形成了一种自然的课程,引导模型逐步从高层语义推理过渡到空间基础,最终过渡到低层控制。从理论角度来看,这种分层监督引入了一系列与任务相关的归纳偏置,逐步约束模型的假设空间。每个中间目标都起到结构化信息瓶颈的作用,抑制与任务无关的变异,同时保留语义和几何意义明确的结构。具体而言,子任务预测促使模型编码高层意图,目标边框预测强化以对象为中心的空间定位,而轨迹预测则进一步将学习的表征与动作相关的几何结构对齐。这些目标共同作用,促使表征变得越来越结构化,并与底层视觉运动决策过程在因果关系上更加一致。
DM0 的训练分为三个连续阶段,从通用的视觉-语言能力逐步发展到具身控制,最终达到可部署的策略水平。为此,设计三种训练方案,每种方案都针对其所在阶段的目标量身定制。预训练阶段基于大规模网络、驾驶和具身数据建立强大的多模态基础。中期训练阶段在保持通用对话能力的同时,增加动作预测功能,并将模型应用于跨具身机器人数据。后期训练阶段缩小具身和数据范围,以在少量目标平台上稳定视觉运动对齐。
预训练
预训练的目标是学习一个通用的视觉-语言模型,该模型具有强大的多模态对齐能力、细粒度的感知能力以及在网络、文档、驾驶和具身数据上的广泛推理能力。通过联合训练这些异构数据源,模型可以同时获得语义知识和物理先验知识(例如,空间关系和在真实场景中的应用)。由此得到的VLM作为骨干,在训练过程中通过动作预测和具身认知相关的监督对其进行扩展。
数据构建。为了支持细粒度感知和广义推理,构建一个涵盖以下领域的多模态预训练语料库。
知识。网络交错数据来自 Common Crawl、StepCrawl 和基于关键词的搜索;过滤掉图像下载失败率超过 90% 的页面、二维码图像和极端宽高比的图像。图像-文本对来自开放数据集(LAION (Schuhmann et al., 2022)、COYO (Byeon et al., 2022)、BLIP-CCS (Li et al., 2022)、Zero (Xie et al., 2023)),并通过基于 CLIP 的平衡重采样、关键词检索以及基于 CLIP 相似度和美学评分的交错上下文图像描述挖掘进行整理。还通过将四张图像拼接成一个训练样本来构建马赛克输入。
教育领域。样本涵盖K-12(数学、物理、化学、几何、化学;开放和合成资源,包括CoSyn (Yang et al., 2025b))、大学(STEM、医学、艺术、金融)和成人学习(例如,驾照考试、注册会计师考试、法律考试)。题目来源于授权考试材料和开放题集(Ben Abacha et al., 2019; He et al., 2020; Sujet AI, 2024);辅助内容来自教科书、练习册和教育网站。
OCR。图像-到-文本的转换使用真实图像和合成图像(PaddleOCR (Cui et al., 2025)、SynthDog (Kim et al., 2022))。图像-到-代码的转换涵盖 Markdown、LaTeX、Matplotlib(开源和基于规则的合成图表)以及 TikZ/Graphviz。文档-到-文本的转换使用文档页面(PaddleOCR 或 MinerU 2.0 (Wang et al., 2024));文档-到-代码的转换涵盖 HTML、Markdown 和 LaTeX(web/GitHub/arXiv)以及开放数据集(Chai et al., 2025; Laurençon et al., 2024; Liu et al., 2024; Yuan et al., 2022)。OCR-VQA 子集将开放数据与从其他 OCR 任务生成的问答对相结合。
基础与计数。边框和点级定位数据来源于开放检测数据集(OpenImages (Kuznetsova et al., 2020)、COCO (Lin et al., 2014)、Merlin (Yu et al., 2024, 2025)、PixMo (Deitke et al., 2024))以及内部文档段落检测。计数数据来自公开基准数据集(Kaggle;SakiRinn)以及通过将检测标注转换为计数监督数据获得。
视觉问答 (VQA)。通用 VQA 基于开放基准数据集(Liu et al., 2025;Zellers et al., 2019)以及由图像描述生成的问答对。
图形用户界面 (GUI)。 GUI子集(Yan,2025)包括界面描述、知识VQA、轨迹(跨越原子动作)、接地标注以及带有元素坐标的Web OCR。
驾驶场景。驾驶场景样本包括深度感知检测和接地标注(类别标签、度量深度、归一化[0,1000]坐标系中的边框)。出于隐私合规性考虑,车牌信息在必要时会被掩码。
具身认知。纳入以接地标注和描述QA任务形式构建的具身认知数据(例如,物体和区域定位、基于机器人观测的场景和空间关系描述),以便模型能够获取物理和空间先验知识以及语义知识。
这些领域共同构建感知和推理基础,并在训练过程中与动作监督相结合。
训练设置。预训练在一个阶段内完成,所有参数均进行联合优化。用 AdamW 优化器(Loshchilov & Hutter,2017)(β1 = 0.9,β2 = 0.95,ε = 10⁻⁸,权重衰减 0.01)对 1.2T 个 token 进行优化,迭代 37 万步(全局批次大小为 8,192,长度为 4,096)。学习率的调整分两个阶段进行:第一阶段使用 900B 个 token,学习率从 5 × 10⁻⁵ 线性衰减至 1 × 10⁻⁵,用于通用表征学习;第二阶段使用 300B 个 token,学习率从 1 × 10⁻⁵ 线性衰减至 6 × 10⁻⁶,用于更高质量的混合样本,以增强 OCR、语境识别和推理能力。最终得到的模型作为下一阶段的基础,在下一阶段将添加动作预测和跨具身控制功能。
中训练
在预训练骨干网络的基础上,中期训练引入动作预测,并将模型与物理控制联系起来。此阶段使用单个训练循环,通过动作专家联合监督文本tokens、离散动作tokens和连续动作。因此,模型学会将语言推理与可执行的物理动作相结合。
目标和监督。中期训练优化三个一致的监督目标:(i)多模态对话tokens,(ii)离散化的动作轨迹(动作tokens),以及(iii)来自动作专家的连续动作轨迹。后两者对应于相同的底层序列,分别以量化和连续形式表示。跨具身机器人数据与视觉语言和推理数据混合;还保留一部分来自预训练的高质量视觉语言数据,以保持通用的多模态能力。
数据混合。数据混合(数据概览见上图,混合比例见下图)平衡通用视觉-语言模型 (VLM) 能力的保留和具身特定学习。它分为五类: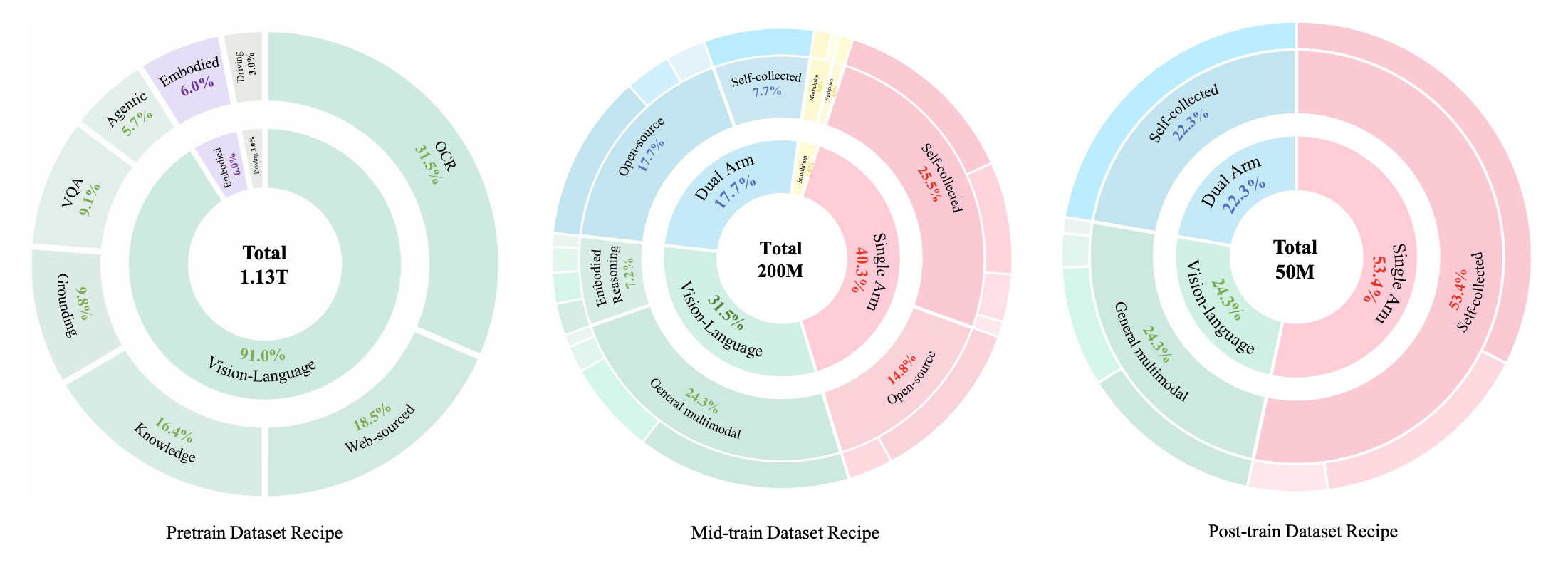
• 视觉-语言数据。为了保留一般的多模态理解能力和指令遵循能力,纳入:(1) Cambrian-737k (Tong et al., 2024);(2) Cambrian-10M(过滤)(Tong et al., 2024),从中剔除低质量样本和与具身学习相关性较低的内容(例如,数学密集型问题、非英语数据、纯粹以写作为中心的内容);(3) LLaVA OneVision (OV) 1.5 (An et al., 2025);以及 (4) 自收集的多模态数据,其中包括来自预训练阶段的重标注具身数据(具身场景基础和空间关系 VQA),以及其他自收集的多模态数据(例如,GUI 基础和 OCR)。
• 具身推理 (ER) 数据。构建ER数据集以增强高级规划和时间推理能力:(1)任务分解,生成完成任务所需的完整步骤序列;(2)子任务预测,预测下一个要执行的子任务;(3)动作质量保证,预测两个帧之间的转换动作;(4)时间推理,识别正在执行的任务并确定下一个子任务;以及(5)任务进度估计,估计当前任务完成进度。
• 仿真数据。纳入以下轨迹:(1)LIBERO(Liu,2023)的四个任务(空间、目标、物体和长距离);(2)包含50个任务的RoboTwin2.0(Chen,2025);以及(3)在Habitat中自行采集的导航轨迹。
• 单臂机器人数据。单臂操作轨迹,包括:(1) 自行采集的涵盖多种机器人形态的数据(例如 Franka、UR5、ARX-5 和 UMI),以及 (2) 开源数据(OXE (Vuong,2023) 和 Fuse (Jones,2025))。
• 双臂机器人数据。双手操作轨迹,包括:(1) 自行采集的 ALOHA 机器人数据,以及 (2) 开源数据(RoboMind (Wu,2025)、Agibot Alpha (Bu,2025) 和 Galaxea Open World (Team, 2025a))。
数据表示和处理。为了支持上述混合监督学习,使用两种表示方法。机器人数据以情景式 JSONL 记录的形式存储,其中每一行对应一个时间步,包含以下内容:(a) 多视角视觉观察(图像或视频帧参考),(b) 语言指令,© 本体感觉状态(用于通过时间偏移推导下一步动作),以及可选的子任务、目标框和 2D 机械臂路径点轨迹。视觉-语言数据可以以可直接训练的对话格式存储,也可以以最小KV形式存储。在后一种情况下,完整的对话是使用对话模板动态构建的。基于这些表示,构建 (i) 多模态多轮对话和 (ii) 连续轨迹数据。多轮对话被组装成一个思维链 (CoT) 序列,而模型最终预测相应的动作轨迹。
• 轨迹表示。对于机器人数据,用每个时间步的轨迹样本进行训练;对于视觉语言和实体识别(ER)数据,使用多轮对话进行训练。多视图图像按确定性顺序排列,并被截断或填充至固定数量的视图(在设置中为三个)。如果可用,则附加二维路径点轨迹和目标框作为辅助监督信息。
• 去除重复数据。为了减少实体识别数据中的冗余,特别是末端执行器(EEF)轨迹,应用关键帧采样。此过程涉及选择捕捉显著状态变化的关键帧,从而在训练之前过滤掉重复或静态片段。
对话增强。所有数据都表示为基于模板的对话,以便相同的监督信息(文本、动作、路径点等)可以用不同的自然语言呈现。
• 模板和监督字段。对于机器人轨迹,对话由任务指令构建而成,并可选择性地包含额外的监督字段:子任务(自然语言描述)、二维路径点轨迹(投影的机械臂路径点)、目标框(目标边框)和动作(包括用于 VLM 的离散化动作标记和用于动作专家的连续动作目标)。如果某个监督字段缺失,会自动选择一个兼容的模板来省略该字段。对于 ER 和导航数据,用针对特定监督类型(例如,QA、推理、进度估计)定制的专用模板系列。
• 模板增强。为了提高泛化能力,为每种特定的数据组合场景设计 500 个不同的对话模板,并对其进行人工润色以确保质量。在训练过程中,为每个样本随机选择一个模板,从而引入语言多样性并防止过拟合特定的提示结构。
动作构建。动作在同一序列的两个对齐视图中进行监督:用于 VLM 的离散tokens和用于动作专家的连续值。每个时间步的下一步动作是通过时间状态转移构建的。构建长度为 50 的短时窗口,对其进行归一化,并将其量化为 255 个区间的词汇表,作为特殊的动作tokens。VLM 预测token化的轨迹,而动作专家则回归连续轨迹。
训练设置。在 64 个 NVIDIA H20 GPU 上进行一个 epoch 的中期训练,使用 AdamW 优化器(学习率从 2.5 × 10−5 衰减到 1 × 10−5),最大序列长度为 4,096,并启用 AMP。每个样本使用三张经过 ColorJitter 增强的图像;每个设备的批次大小为 6。最终模型支持跨多载体的多模态对话和动作轨迹预测。训练后,缩小部署的载体和数据范围。
后训练
后训练从中期训练的模型出发,通过将机器人数据集中在一小部分目标模型上,使其更适合部署。缩小模型多样性可以降低分布方差并稳定跨模态对齐,从而使模型能够学习精细的视觉运动对应关系和动作语义,这对于所选机械臂而言至关重要。
数据策略和混合。数据混合包括:(1) 中期训练视觉-语言数据的重采样子集,以保留通用对话能力;(2) 仅限于目标模型的单臂和双臂机器人数据。数据表示、对话模板和动作表述与中期训练中使用的相同。
训练设置。训练在与中期训练相同的联合监督(文本、离散动作tokens和连续动作专家目标)和相同的优化配置下继续进行。仅修改数据采样和目标模型集。最终得到的模型在保留通用多模态能力的同时,针对目标平台进行专门化。
实验设置
基准测试协议。鉴于 DM0 专注于物理世界交互,用真实世界的 RoboChallenge 基准测试 [(Team, 2025b)] 对其进行评估。该基准测试包含一套全面的 30 多个长时域桌面操作任务。这些任务需要多步骤推理、空间理解和精确的连续控制,涵盖物体拾取、放置、重新排列、工具使用和组合指令执行等领域。
训练设置。在监督式微调 (SFT) 阶段,采用两种不同的训练配置,区别在于它们的数据源和评估范围。
• SFT(专家):此配置仅使用目标任务的数据进行训练。模型在 8 个 H20 GPU 上进行微调,每个 GPU 的批大小为 4,迭代次数为 4 万到 15 万次,具体取决于任务的复杂性。将行动范围设置为 50 步。对于涉及重复子目标的任务,应用进度监督来提高学习效率和性能。
• SFT(通用型):此配置使用从目标机器人平台所有可用任务聚合的数据进行训练,并因此在该机器人的全套任务上进行评估。训练在 16 个 H20 GPU 上进行,每个 GPU 的批大小为 4,迭代次数为 20 万次,行动范围为 50 步。
对比模型。将 DM0 与几个领先的开源模型进行基准测试,包括 GigaBrain-0.1 (GigaAI, 2025)、Spirit-V1.5 (Team, 2026)、𝜋0.5 (Black et al., 2025) 和 𝜋0 (Black et al., 2024)。
基准测试使用成功率和综合任务得分来评估性能。在分析中,报告专科医生设置的成功率,但由于所有模型的成功率都很低,因此也提供全科医生设置的两个指标。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献229条内容
已为社区贡献229条内容

所有评论(0)