【ComfyUI】Qwen + Lotus 深度引导图生图
本文介绍了一个基于ComfyUI的AI图像生成工作流,通过扩散模型(UNet)和变分自编码器(VAE)的协同工作,实现输入图像到潜在空间的编码解码与重构变换。该流程包含9个关键节点,涵盖模型加载、条件控制、采样迭代到结果输出的完整链路,支持参数调节和多样化输出。工作流适用于艺术创作、数据增强和学术研究等领域,提供可视化实验环境,助力理解生成原理。文末附有ComfyUI开发教程和相关资源链接,便于深
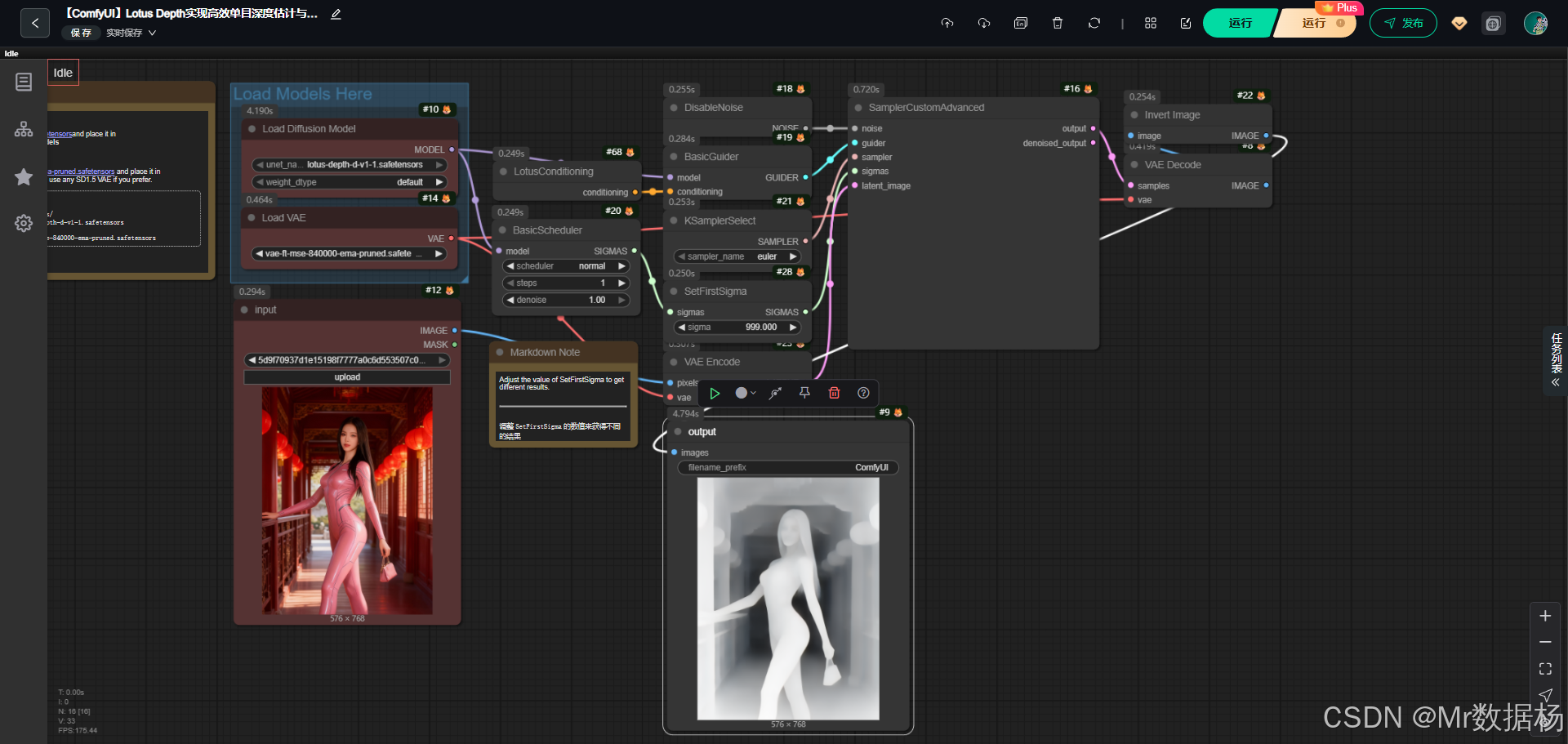
今天带来的是一个基于 ComfyUI 的工作流展示,该流程的目标是通过加载扩散模型与VAE组件,对输入图像进行潜在空间的编码与解码,再结合采样器、调度器以及条件控制实现生成与变换。效果图能够直观展现输入图像如何在潜在层级被重构与翻转,最终输出结果存储到指定目录中。

整个过程展示了从模型加载到结果保存的完整链路,使得初学者能够快速理解 ComfyUI 工作流在实际图像生成任务中的运行方式。
工作流介绍
该工作流由扩散模型、变分自编码器(VAE)、调度采样器与图像处理节点共同构成。整体设计通过 UNet 扩散模型 负责核心生成逻辑,VAE 模型 实现图像与潜在空间的双向映射,而 Conditioning 与 Sampler 的组合则保证了生成过程中条件约束与迭代更新的稳定性。最终配合图像翻转与保存节点,实现了可调节参数下的多样化输出。这种结构为图像编辑、风格迁移与潜在表示探索提供了灵活的实验路径。
核心模型
工作流核心依赖于两个关键模型:一是 Lotus 深度扩散模型,负责潜在空间的生成推理;二是 VAE 模型,保障了图像与潜在表示之间的高保真映射。扩散模型在引导条件的作用下完成去噪和重建,而VAE则在潜在与像素之间提供高效桥梁。
| 模型名称 | 说明 |
|---|---|
| lotus-depth-d-v1-1.safetensors | 用于深度引导的扩散模型,支持潜在空间生成与多轮迭代采样 |
| vae-ft-mse-840000-ema-pruned.safetensors | 变分自编码器模型,用于图像与潜在特征的编码与解码 |
Node节点
节点的组织覆盖了模型加载、潜在空间编码与解码、采样控制、图像翻转与结果保存。LoadImage 负责导入输入图像,VAEEncode/Decode 在图像与潜在空间之间完成映射,SamplerCustomAdvanced 结合噪声与调度器执行多轮采样迭代,ImageInvert 为结果提供反转处理,最后由 SaveImage 输出成品。每个节点通过输入输出的连接,形成稳定而清晰的数据流。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载输入图像,提供像素数据 |
| UNETLoader | 加载扩散模型,执行潜在空间生成 |
| VAELoader | 加载VAE模型,支持潜在空间映射 |
| VAEEncode | 将图像编码到潜在空间 |
| VAEDecode | 将潜在表示解码为图像 |
| BasicScheduler | 提供采样过程的时间步调度 |
| KSamplerSelect | 选择采样方法(如 euler) |
| SamplerCustomAdvanced | 综合噪声、条件和调度完成迭代采样 |
| LotusConditioning | 提供扩散模型的条件输入 |
| DisableNoise | 屏蔽初始噪声输入 |
| ImageInvert | 对生成图像执行翻转处理 |
| SaveImage | 保存最终生成结果 |
工作流程
该工作流的执行链路紧密衔接了输入、潜在空间变换、条件引导、采样生成以及最终输出环节。流程以图像加载为起点,通过VAE编码进入潜在空间,扩散模型与调度器共同发挥作用,在条件与噪声的控制下完成多轮采样与重建。解码后的结果在图像翻转节点中得到处理,最后由保存节点输出可视化成果。整体结构既展示了标准扩散流程的完整性,又通过参数调节提供了可控的实验空间。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 输入准备 | 导入待处理的图像并生成像素数据 | LoadImage |
| 2 | 模型加载 | 加载UNet扩散模型与VAE模型,建立潜在与像素的映射基础 | UNETLoader, VAELoader |
| 3 | 编码映射 | 将输入图像转换为潜在特征表示 | VAEEncode |
| 4 | 条件控制 | 加载LotusConditioning 作为扩散引导条件 | LotusConditioning |
| 5 | 调度与采样 | 配置调度器与采样器,屏蔽初始噪声并设定迭代步长 | BasicScheduler, DisableNoise, KSamplerSelect |
| 6 | 迭代生成 | 通过高级采样器综合条件、噪声与潜在特征完成去噪与重建 | SamplerCustomAdvanced |
| 7 | 解码重构 | 将生成的潜在特征还原为图像 | VAEDecode |
| 8 | 图像处理 | 对结果图像进行翻转或增强处理 | ImageInvert |
| 9 | 成果输出 | 将最终生成的图像保存到指定路径 | SaveImage |
大模型应用
LotusConditioning 生成语义的核心控制入口
这个节点负责将模型内部预设的语义条件结构化输出,用作整条流程的生成指导。Lotus 系列模型并不依赖文字 Prompt,而是通过此节点生成特定的“深度引导语义”,让模型理解该图像应如何被重构、增强或反转。
由于没有文本 Prompt,LotusConditioning 的输出成为唯一的语义驱动来源,决定模型在采样阶段如何理解输入图像的结构信息、深度关系与内容偏向。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| LotusConditioning | (无 Prompt,用模型内置条件) | 输出 Lotus 模型的内部语义结构,决定深度感、结构保留强度与生成方向,是整个流程的主要语义来源。 |
使用方法
这条工作流依靠 Lotus 深度模型进行图像结构重建,不使用文本 Prompt。用户只需要提供一张输入图像,系统会自动对其进行深度结构分析,并将图像编码成潜空间。LotusConditioning 输出模型的结构语义,再由 BasicGuider 将这些语义与 UNet 绑定,使采样器在生成过程中遵循原图的深度关系与结构特征。
BasicScheduler 负责生成采样步长序列,SetFirstSigma 决定噪声初始强度,DisableNoise 则允许无噪声方式启动采样,从而实现基于结构的“重绘式生成”。最终生成的潜空间由 VAE 解码为图像,并可自动保存。
整个流程完全自动化,用户只需替换输入图片即可立即生成对应的结构增强或特殊风格的输出图像。SetFirstSigma 的数值则用于控制结果的偏离程度,越大越“变形”,越小越贴近原图。
| 注意点 | 说明 |
|---|---|
| 模型不支持文本 Prompt | 所有风格变化依赖 LotusConditioning 和噪声设定 |
| 输入图清晰度影响深度结构质量 | 越清晰的图越能输出准确的深度引导 |
| SetFirstSigma 控制画面变化幅度 | 值大时偏离原图更多,值小时更贴近原图 |
| DisableNoise 会强制无噪声合成 | 适合结构保持,但可能减少创意变化 |
| VAE 模型决定图像细节风格 | 可替换其他 SD1.5 VAE 改变细节呈现 |
| 仅支持单图输入生成 | 不支持文本与多模态融合 |
应用场景
该工作流在多个实际任务中具有可扩展价值。在艺术创作中,可以用于对已有图像进行重构与风格化处理;在数据增强中,能够通过翻转和采样生成多样化的图像变体;在研究实验中,则可用于探索潜在空间的特征表现与采样策略的差异。对于AI绘画爱好者,它提供了可视化的交互式实验环境;对于图像处理研究者,它是一个可复现的实验框架;而在教育展示中,则能直观呈现扩散模型与VAE协作的工作原理。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 艺术创作 | 对输入图像进行风格化改造与生成 | 数字艺术设计师 | 原始图像与生成结果对比 | 风格多样化与创意呈现 |
| 数据增强 | 扩展训练集图像样本的多样性 | 机器学习工程师 | 不同参数下的输出样本 | 模型泛化能力提升 |
| 学术研究 | 探索采样算法与潜在空间特征 | 深度学习研究者 | 潜在特征与采样输出的可视化 | 理论与实验结合验证 |
| 教学展示 | 演示扩散模型与VAE的协同作用 | 教育培训讲师 | 从输入到输出的流程图与案例 | 帮助学习者理解生成原理 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 35
35 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)