主流嵌入模型总览以及技术选型(2026)
主流嵌入模型分为商用API和开源本地部署两类,商用API(如OpenAI、Cohere)适合即开即用但成本高,开源模型(如BGE-M3、GTE)适合私有化部署且中文优化更好。核心差异包括:向量类型(稠密/稀疏/混合)、中文适配性、长文本支持及部署成本。BGE-M3因混合向量和中文优化成为中文RAG首选,兼顾语义理解和关键词匹配。选型需考虑场景、成本及数据隐私,中文场景优先选择国产开源模型,混合向量
目前主流嵌入模型可分为商用 API与开源本地部署两大类,核心差异在中文适配、向量类型、长文本支持、成本与部署方式。下面按类别详解主流模型、核心区别与选型建议。
一、主流嵌入模型总览(2026)
1. 商用 API 模型(开箱即用,无需部署)
表格
| 模型 | 厂商 | 核心特点 | 向量维度 | 最大长度 | 中文支持 | 定价(每百万 token) | 适用场景 |
|---|---|---|---|---|---|---|---|
| text-embedding-3-large | OpenAI | 可变维度、MTEB 领先、生态成熟 | 256/1024/3072 | 8191 | 一般 | $0.13 | 通用 RAG、多语言、高并发 |
| text-embedding-3-small | OpenAI | 高性价比、轻量 | 512/1536 | 8191 | 一般 | $0.02 | 低成本检索、轻量应用 |
| Cohere embed-v4.0 | Cohere | 长文本、多语言、检索优化 | 1024 | 10240 | 一般 | $0.10 | 长文档 RAG、跨语言检索 |
| Gemini Embedding-001 | 多模态、长文本 | 768 | 8192 | 一般 | $0.15 | 多模态检索、Google 生态 | |
| Voyage-4 | Voyage AI | 检索精度高、性价比 | 1024 | 16384 | 一般 | $0.06 | 高精度 RAG、长文本 |
2. 开源本地模型(可私有化部署,中文优先)
表格
| 模型 | 机构 | 核心特点 | 向量类型 | 最大长度 | 中文优化 | 开源 | 适用场景 |
|---|---|---|---|---|---|---|---|
| BGE-M3 | 智源研究院 | 混合向量(稠密 + 稀疏 + 多向量)、中文第一、100 + 语言 | 混合 | 8192 | ✅✅✅ | ✅ | 中文 RAG、检索、跨语言 |
| GTE | 阿里通义 | 全能型、多任务、中文强 | 稠密 | 8192 | ✅✅✅ | ✅ | 中文通用、信息检索 |
| Qwen3-Embedding | 阿里通义 | 119 语种、长文本、代码检索强 | 稠密 | 16384 | ✅✅✅ | ✅ | 多语言、代码、长文本 |
| E5-large-v2 | 微软 | 学术派、英文强、训练数据丰富 | 稠密 | 512 | ✅ | ✅ | 英文科研、跨领域分析 |
| Jina Embeddings | Jina AI | 跨语言、长文本、轻量 | 稠密 | 8192 | ✅✅ | ✅ | 多语言、轻量部署 |
| Nomic-embed-text | Nomic AI | 超轻量、长文本(10k+) | 稠密 | 10240 | ✅ | ✅ | 资源受限、长文本 |
二、核心区别深度解析
1. 向量类型:稠密 vs 稀疏 vs 混合
- 稠密向量(OpenAI、E5、GTE):捕捉深层语义,适合语义相似度计算;但无法直接做关键词匹配,对噪音敏感。
- 稀疏向量(BM25、BGE-M3):基于词频统计,擅长关键词精确匹配;但无法理解同义词 / 语义关联。
- 混合向量(BGE-M3):同时生成稠密 + 稀疏 + 多向量,兼顾语义理解与关键词匹配,RAG 降噪首选。
2. 中文适配:开源国产 vs 海外商用
- BGE-M3、GTE、Qwen3:专为中文优化,在 C-MTEB(中文评测)中常年第一,对中文成语、古文、专业术语理解更好。
- OpenAI、Cohere:中文支持为通用多语言,无专项优化,中文检索精度低于国产模型。
3. 长文本支持:序列长度与处理能力
- Cohere、Voyage、Qwen3:最大长度 10k+,适合长文档(如书籍、报告)RAG。
- BGE-M3、GTE:8k 长度,平衡性能与效率,适配多数场景。
- E5:仅 512,需严格切分,不适合长文本。
4. 部署与成本:API vs 本地
- 商用 API:零部署、即开即用、高并发稳定;但按 token 计费,长期成本高、数据需上传第三方。
- 开源本地:一次性部署、零调用成本、数据隐私可控;但需 GPU/CPU 资源、维护模型更新。
5. 降噪能力(你最关心的点)
- BGE-M3:混合向量天然支持降噪 —— 稀疏向量过滤无关关键词,稠密向量保留语义,二次优化效果最好。
- GTE/Qwen3:通过对比学习优化语义纯度,适合对检索到的 chunk 做提取 / 总结降噪。
- OpenAI/Cohere:依赖 prompt 工程做降噪,无内置稀疏匹配,对大量噪音 chunk 处理较弱。
三、选型建议(按场景)
- 中文 RAG / 检索(首选):BGE-M3 → 混合向量、中文第一、降噪最强、开源免费。
- 低成本轻量应用:text-embedding-3-small(API)或 GTE-small(本地)。
- 长文档 / 跨语言:Qwen3-Embedding(开源)或 Cohere embed-v4.0(API)。
- 英文科研 / 学术:E5-large-v2 或 Nomic-embed-text。
- 数据隐私 / 私有化:BGE-M3、GTE、Qwen3 → 本地部署,数据不出内网。
四、选型时考虑因素(重要重要!!!!)
4.0 场景
因为我们是中国人 服务大部分是国内用户。 首选对中文优化的模型。
结论 0 BGE-M3对中文支持最友好、因为是为中文开发的
4.1 向量的基础概念
稠密向量:在向量数据库做检索的时候 根据 语义匹配,无法根据关键字匹配。
稀疏向量:在向量数据库做检索的时候 根据 关键词词频匹配,无法根据语义进行匹配。
多向量: 例如文章10W个字,超过基础模型的token的限制后,将10W字的文章拆分为10篇文章 每个文章用一个向量来表示,然后在将10个向量合并起来。就叫做向量。
混合向量:语义相似 + 关键词匹配 + 多向量
结论1:混合向量是首选 BGE-M3
4.2 选择商用还是本地部署,考虑的维度有哪些 ?
人员能力提升:首选择本地部署,可以更深入的学习。
开发效率:首选商用,稳定、开发成本低。
应用场景:
公司内部使用 (控制成本优先)
对外部C端用户(用户体验优先,前期是公司有钱)
结论3: BGE-M3、GTE、Qwen3-Embedding 依次选择。
BGE的模型有很多,看下的内容作为参考。
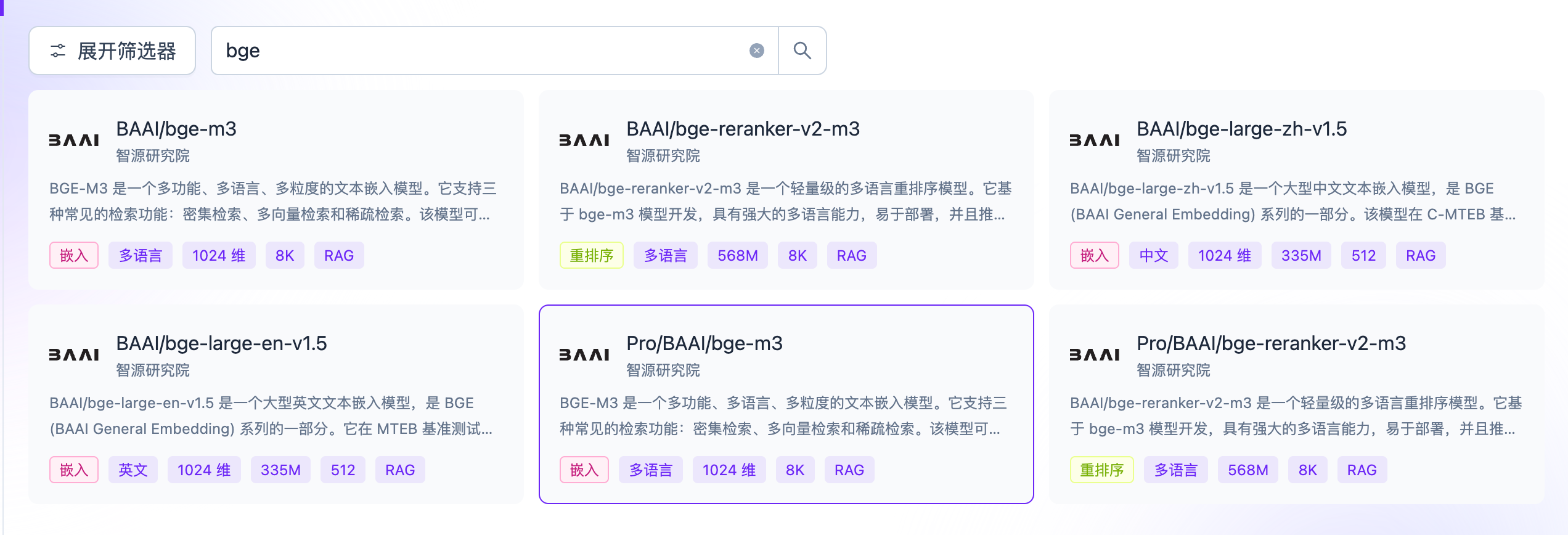

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)