算力调度平台(二):环境准备(Docker + GPU)
本次核心完成了 NVIDIA 驱动安装、NVIDIA Container Toolkit 配置、Docker GPU 透传验证,打通了。系统开展,已提前完成 Docker(24.0.2)与 docker-compose(v2.40.3)的安装配置,本文核心完成。首先需确认宿主机 GPU 硬件识别状态及 NVIDIA 驱动安装情况,为容器 GPU 透传打下基础。无输出则需检查硬件连接或驱动基础配置。
环境搭建是基于Ubuntu 18.04系统开展,已提前完成 Docker(24.0.2)与 docker-compose(v2.40.3)的安装配置,本文核心完成GPU 环境校验 / 安装、NVIDIA Container Toolkit 部署以及Docker GPU 透传配置与验证。
环境搭建目标:
- 宿主机可正常识别 GPU,
nvidia-smi命令能完整输出 GPU 型号、驱动版本、显存等信息; - 容器内可无缝调用宿主机 GPU,
docker run --gpus all ... nvidia-smi命令能正常输出 GPU 相关信息。
一、宿主机 GPU 环境检查与安装
首先需确认宿主机 GPU 硬件识别状态及 NVIDIA 驱动安装情况,为容器 GPU 透传打下基础。
1.1 基础硬件检查
执行以下命令,检查宿主机是否识别 NVIDIA GPU 设备,并查看内核版本:
lspci | grep -i nvidia
uname -r
若命令输出 NVIDIA 设备相关信息,说明硬件识别正常;无输出则需检查硬件连接或驱动基础配置。
1.2 现有 NVIDIA 驱动验证
若已手动安装过 NVIDIA 驱动,直接执行以下命令验证驱动可用性:
nvidia-smi
- 若命令能正常输出GPU 列表、驱动版本、CUDA 版本等信息,说明驱动已安装成功,直接跳至第二章 安装 NVIDIA Container Toolkit;
- 若报错(如
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver),说明驱动未安装 / 未加载,需按以下步骤重装。
1.3 Ubuntu 系统 NVIDIA 驱动安装(推荐方式)
采用 Ubuntu 官方源方式安装,适配性更强,步骤如下:
# 更新软件源
sudo apt update
# 安装驱动管理工具
sudo apt install -y ubuntu-drivers-common
# 查看推荐的驱动版本
ubuntu-drivers devices
执行完ubuntu-drivers devices后,终端会显示系统推荐的 NVIDIA 驱动版本,按推荐版本执行安装:
# 替换<推荐版本>为实际输出的版本号,如nvidia-driver-550
sudo apt install -y nvidia-driver-<推荐版本>
# 重启服务器使驱动生效
sudo reboot
服务器重启后,再次执行nvidia-smi验证,能正常输出 GPU 信息即说明驱动安装成功。
二、安装 NVIDIA Container Toolkit(容器 GPU 调用核心)
NVIDIA Container Toolkit 是实现容器透传宿主机 GPU的关键组件,可让 Docker 容器直接调用 NVIDIA GPU 资源,步骤如下:
2.1 安装 Toolkit 组件
# 更新软件源
sudo apt-get update
# 安装NVIDIA Container Toolkit
sudo apt-get install -y nvidia-container-toolkit
2.2 配置 Docker 使用 NVIDIA Runtime
安装完成后,需将 NVIDIA Runtime 配置为 Docker 的可用运行时,让 Docker 支持 GPU 设备透传:
# 自动配置Docker的NVIDIA runtime
sudo nvidia-ctk runtime configure --runtime=docker
该命令会自动修改 Docker 的核心配置文件/etc/docker/daemon.json,主要添加 / 更新以下内容:
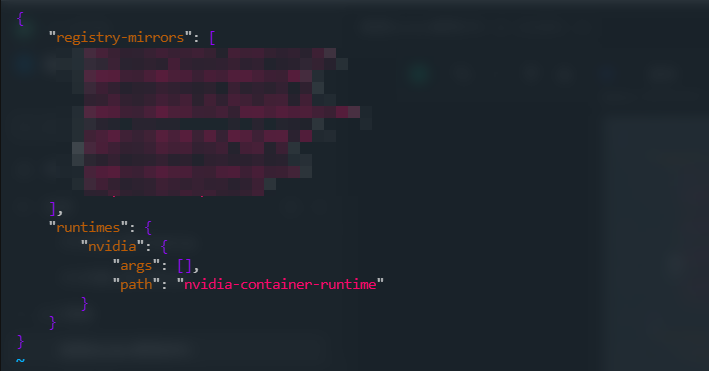
配置完成后,重启 Docker 服务使配置生效:
sudo systemctl restart docker
三、宿主机 + 容器 GPU 环境双重验证
环境配置完成后,需分别验证宿主机和容器内的 GPU 识别状态,确保 GPU 透传链路完全打通,容器内验证为关键验收步骤。
3.1 宿主机 GPU 验证
直接执行经典验证命令,确认宿主机驱动与 GPU 状态正常:
nvidia-smi
正常输出示例包含 GPU 型号、驱动版本、CUDA 版本、显存使用情况等核心信息,说明宿主机 GPU 环境无问题。
3.2 容器内 GPU 透传验证
拉取官方 NVIDIA CUDA 基础镜像,启动临时容器并执行nvidia-smi,验证容器内 GPU 调用能力:
# 启动临时容器,--rm表示容器退出后自动删除,--gpus all表示挂载宿主机所有GPU
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi
输出:
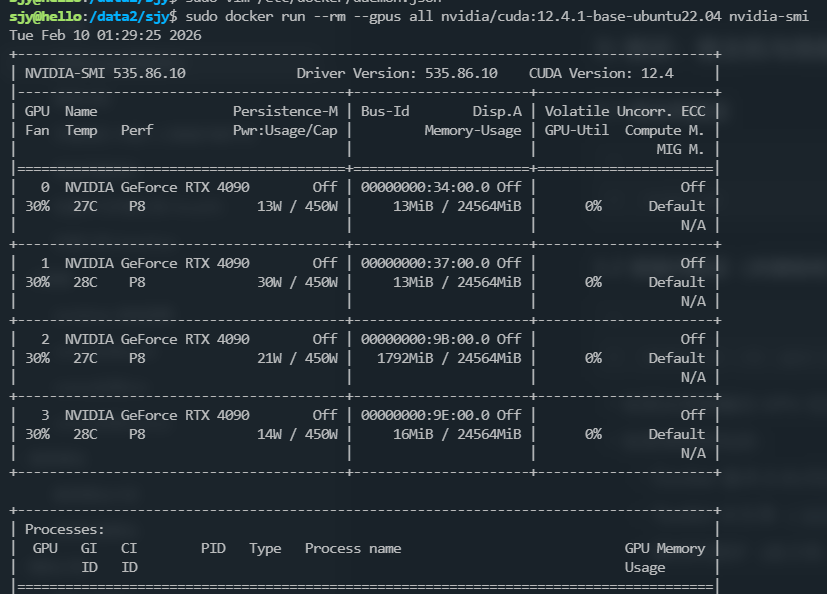
说明Docker GPU 透传链路完全打通,基础环境搭建完成。
常见报错原因排查
若容器内验证报错,优先排查以下 3 点:
- Docker 版本过低,未支持
--gpus参数,需升级 Docker 至 20.10 及以上版本; - NVIDIA Container Toolkit 配置未生效,未执行
nvidia-ctk runtime configure或未重启 Docker; - 宿主机 NVIDIA 驱动安装失败,宿主机执行
nvidia-smi本身即报错,需重新安装驱动。
本文小结
本次核心完成了 NVIDIA 驱动安装、NVIDIA Container Toolkit 配置、Docker GPU 透传验证,打通了宿主机 GPU→Docker 容器的调用链路。现在,服务器已具备 “容器化运行 GPU 训练任务” 的基础能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)