ConsistEdit: Highly Consistent and Precise Training-free Visual Editing
针对 MM-DiT 架构定制的、基于 Vision Token 分离的 Q/K/V 解耦控制算法。它摒弃了以前模糊的 Attention Map 替换,转而通过直接操纵 Self-Attention 的输入矩阵,利用QKQ/KQK锁死几何结构,VVV控制语义渲染,实现了对生成过程的精确 surgical(手术级)干预。这可能是目前 DiT 架构下做 Video-to-Video 或 Image E

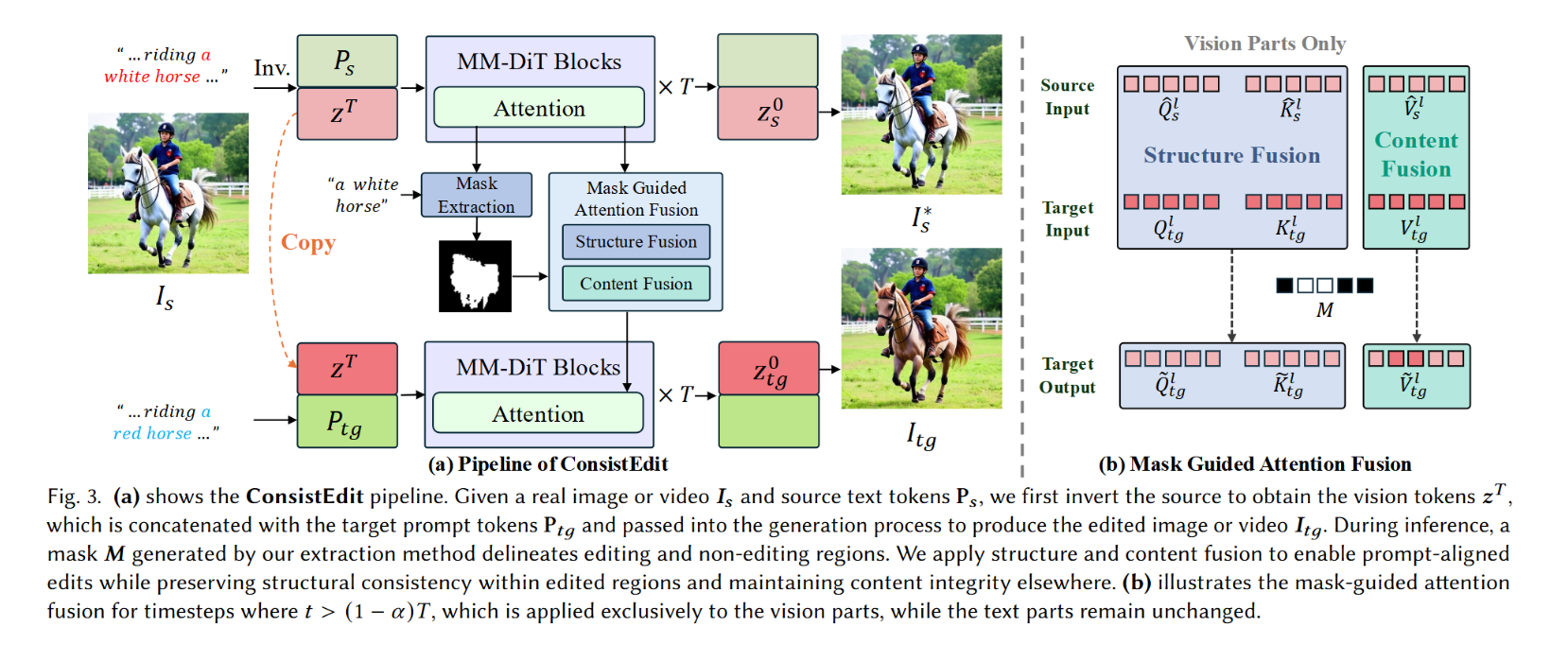



针对 MM-DiT 架构的 Self-Attention 机制,提出了一种仅作用于视觉 Token 的 “Q/K 锁定结构、V 控制内容” 的解耦控制策略,实现了无需训练(Training-free)的高保真结构一致性编辑。
这篇论文介绍了一个叫做 ConsistEdit 的新技术,旨在解决目前 AI 在修图(和修视频)时经常遇到的一个大难题:“改得不准”和“改乱了”。
1. 背景:AI 修图的“新时代”
以前的 AI 绘画模型(比如 Stable Diffusion 1.5)大多用的是一种叫 U-Net 的架构。但最近,更先进的模型(比如 Stable Diffusion 3 (SD3)、Flux、CogVideoX)都换成了一种叫 MM-DiT 的新架构。这种新架构虽然画质更好,但以前那些用来“修图”的老方法在上面不管用了。
2. 痛点:现在的 AI 修图有什么毛病?
在使用新架构模型修图时,通常会遇到两个极端的问题:
- 改不动/改得不自然(结构一致性差): 比如你想把一个人的“红衬衫”改成“蓝衬衫”。现有的方法要么改完后衬衫的褶皱、光影全变了(看起来像贴了一张假图),要么就是把背景里的花草也变色了。
- 不仅改了该改的,还改了不该改的: 比如你只想给那个人换衣服,结果 AI 顺手把他的发型也微调了,或者把背景里的房子变了个样。这在视频编辑里更致命,会导致画面闪烁。
3. ConsistEdit 是怎么解决的?(核心黑科技)
作者发现,新架构(MM-DiT)处理图像和文字的方式和老架构不一样。于是他们设计了一套无需训练(Plug-and-play)的控制方法,核心是像这就好比**“精细化手术”**:
- 只动“视觉”不动“文字”:
以前的方法容易混淆文字指令和图像内容。ConsistEdit 发现,在修图时,只调整图像部分的注意力(Attention),不要去干扰文字部分的理解,效果最好。 - 借用“骨架”(Q 和 K):
在 AI 内部的注意力机制里,有三个关键元素:Query (Q), Key (K), Value (V)。- Q 和 K 掌管结构: 作者发现,如果我们把原图的 Q 和 K 借过来用,就能完美保留原图的结构(比如衣服的褶皱、物体的轮廓)。
- V 掌管内容/颜色: 如果我们想改颜色,就改变 V;如果我们想保留背景不动,就把原图背景的 V 复制过来。
- 智能“蒙版”融合:
它能自动识别哪部分需要改(比如衬衫),哪部分不需要改(比如背景)。在不需要改的地方,它强制使用原图的信息,保证背景一像素都不变。
ConsistEdit 本质上是针对 MM-DiT (Multi-Modal Diffusion Transformer) 架构提出的一种 Training-free Attention Control 机制。
它的核心贡献在于解决了传统的 U-Net Attention Control 方法(如 Prompt-to-Prompt, MasaCtrl)在迁移到 MM-DiT 架构(如 SD3, Flux, CogVideoX)时失效的问题,实现了高保真的结构一致性(Structure Consistency)和背景保持(Content Preservation)。
1. 核心痛点:U-Net 到 MM-DiT 的架构差异
在 U-Net 时代(SD 1.5/SDXL),Attention Control 主要依赖 Cross-Attention(控制语义)和 Spatial Self-Attention(控制布局)的分离。
但在 MM-DiT(如 SD3)中,架构发生了根本变化:
- 模态融合(Joint Modality): 文本 Token (TTT) 和 图像 Token (III) 被拼接(Concatenate)后输入同一个 Transformer Block 进行 Self-Attention。
- 全层语义同质性: U-Net 有明显的 Encoder-Decoder 结构,语义层级分明;而 DiT 结构中,各层的语义和结构信息分布相对均匀。
由此带来的问题: 直接套用 U-Net 的 Attention Control(例如在 Cross-Attn 注入 map),在 MM-DiT 中会因为干扰了文本 Token 的 Self-Attention 导致生成崩溃或控制失效。
2. 核心洞察 (Key Insights)
作者通过对 MM-DiT Attention 机制的消融实验,得出了三个关键结论,这也是 ConsistEdit 的设计基石:
- Vision-Only Control (视觉 Token 隔离):
在进行 Attention 注入时,绝对不能干扰 Text Token 部分的 Q、K、V。必须将 Vision Token 和 Text Token 拆解,仅对 Vision 部分进行 Swap 或 Blend,否则会破坏 Prompt 的语义引导,导致生成崩坏。 - Q/K 决定结构,V 决定外观:
- Q\mathbf{Q}Q (Query) & K\mathbf{K}K (Key): 在 Self-Attention 中计算 Attention Map (Softmax(QKT/d)Softmax(QK^T/\sqrt{d})Softmax(QKT/d)),这直接决定了像素间的空间对应关系(Layout/Structure)。保留 Source 的 QvisQ_{vis}Qvis 和 KvisK_{vis}Kvis 能强行锁住物体的几何结构(如衣服褶皱、姿态)。
- V\mathbf{V}V (Value): 承载了具体的特征信息(颜色、纹理)。
- 全层控制 (All-Layer Control):
不同于 MasaCtrl 仅控制 Decoder 层,MM-DiT 需要在所有 Transformer Block 中应用控制才能达到最佳效果。
3. 方法论:ConsistEdit 算法流程
ConsistEdit 采用经典的 Inversion-Editing 范式(Source Inversion →\rightarrow→ Target Generation)。
在 Target 生成过程的第 ttt 步,其 Attention 计算逻辑被修改为 Mask-Guided Pre-Attention Fusion。不同于某些方法在 Attention Map 上做文章,ConsistEdit 直接在输入 Attention 的 Q、K、V 层面进行操作。
3.1 区域掩码 (Masking)
通过 Cross-Attention Map 或其他分割方法获取编辑区域掩码 M\mathbf{M}M(1 为编辑区,0 为背景区)。
3.2 差异化注入策略 (Differentiated Injection)
对于 Target 生成中的 Vision Tokens (Q^,K^,V^\hat{Q}, \hat{K}, \hat{V}Q^,K^,V^),根据掩码 M\mathbf{M}M 进行如下混合:
-
编辑区域 (Edited Region, M=1M=1M=1) —— 结构保留策略:
- Q,KQ, KQ,K: 替换为 Source 的 Qsrc,KsrcQ_{src}, K_{src}Qsrc,Ksrc。这保证了 Target 生成时关注的空间位置与 Source 完全一致(锁住结构)。
- VVV: 保持 Target 的 VtgtV_{tgt}Vtgt(由 Target Prompt 生成)。这允许颜色、纹理发生变化。
- 公式化表达: Q~=Qsrc,K~=Ksrc,V~=Vtgt\tilde{Q} = Q_{src}, \tilde{K} = K_{src}, \tilde{V} = V_{tgt}Q~=Qsrc,K~=Ksrc,V~=Vtgt
-
非编辑区域 (Unedited Region, M=0M=0M=0) —— 背景保持策略:
- Q,K,VQ, K, VQ,K,V: 全部替换为 Source 的对应特征。这保证背景像素在特征层面与原图完全一致,防止背景漂移或颜色泄漏。
3.3 混合公式 (The Fusion Equation)
将上述逻辑合并,最终输入 Attention 的 Vision Token 计算如下(以 Q 为例):
Q~tgl=M⊙Qsrcl+(1−M)⊙Qsrcl=Qsrcl \tilde{Q}_{tg}^l = M \odot Q_{src}^l + (1-M) \odot Q_{src}^l = Q_{src}^l Q~tgl=M⊙Qsrcl+(1−M)⊙Qsrcl=Qsrcl
(注意:这里实际上根据需求,编辑区用 Source Q/K,背景区必定用 Source Q/K/V。论文中为了强调结构一致性,在编辑区强制使用了 Source 的 Q 和 K)
最终的 Attention 计算仅针对 Vision 部分:
Attention(Q~vis,K~vis,V~vis) \text{Attention}(\tilde{Q}_{vis}, \tilde{K}_{vis}, \tilde{V}_{vis}) Attention(Q~vis,K~vis,V~vis)
而 Text 部分保持原始生成的 Qtxt,Ktxt,VtxtQ_{txt}, K_{txt}, V_{txt}Qtxt,Ktxt,Vtxt 不变。
3.4 一致性强度 (Consistency Strength α\alphaα)
引入超参数 α\alphaα。并非在所有去噪步数都应用此控制,而是在前 α⋅T\alpha \cdot Tα⋅T 步(即生成的主体结构确立阶段)应用。
- High α\alphaα (e.g., 1.0): 强结构约束(如换衣服颜色,保留褶皱)。
- Low α\alphaα (e.g., 0.3): 允许结构形变(如把猫变成老虎)。
4. 实验效果与 SOTA 对比
- 结构一致性 (Structural Consistency): 在 Canny Edge SSIM 指标上,显著优于 RF-Solver 和 FireFlow。
- 背景保留 (Background Preservation): 在 PSNR 指标上大幅领先,解决了背景颜色随主体变化的“颜色泄漏”问题。
- 泛化性 (Generalization):
- SD3 (Image): 完美适配。
- Flux (Image): 证明了该方法在更大规模 DiT 上的有效性。
- CogVideoX (Video): 直接扩展到视频编辑,只需处理 Temporal Dimension 即可,且表现出极佳的时间一致性(不闪烁)。
5. 总结 (Takeaway)
作为算法工程师,你可以将 ConsistEdit 理解为:
针对 MM-DiT 架构定制的、基于 Vision Token 分离的 Q/K/V 解耦控制算法。
它摒弃了以前模糊的 Attention Map 替换,转而通过直接操纵 Self-Attention 的输入矩阵,利用 Q/KQ/KQ/K 锁死几何结构,VVV 控制语义渲染,实现了对生成过程的精确 surgical(手术级)干预。这可能是目前 DiT 架构下做 Video-to-Video 或 Image Editing 最稳健的 Training-free 基线之一。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)