本地部署大模型
简单来说,大模型是指拥有巨大数量参数(通常在数十亿到数万亿之间),通过在海量数据上进行训练,从而能够学习并执行各种复杂任务的人工神经网络模型。它们是当前人工智能领域,特别是生成式AI浪潮的核心技术。可以把大模型想象成一个超级大脑。这个大脑读过互联网上几乎所有公开的文本、图片、代码等,从中学会了语言、知识、逻辑和模式。然后,你只需要用自然语言跟它“对话”,它就能帮你完成各种事情。
1、什么是大模型
简单来说,大模型是指拥有巨大数量参数(通常在数十亿到数万亿之间),通过在海量数据上进行训练,从而能够学习并执行各种复杂任务的人工神经网络模型。它们是当前人工智能领域,特别是生成式AI浪潮的核心技术。
可以把大模型想象成一个超级大脑。这个大脑读过互联网上几乎所有公开的文本、图片、代码等,从中学会了语言、知识、逻辑和模式。然后,你只需要用自然语言跟它“对话”,它就能帮你完成各种事情。
2、本地部署大模型的核心优势
一句话总结:数据更安全、响应更快、成本更可控、使用更自由。
1. 数据隐私与安全(最大优势)
-
所有数据不离开本地设备 / 内网,不上传第三方云服务器
-
适合敏感数据:企业文档、医疗、金融、法律、个人隐私
-
完全自主可控,无数据泄露、被第三方使用的风险
2. 低延迟、响应更快
-
无需走公网、跨地区网络请求
-
本地直接推理,毫秒级响应,交互更流畅
-
高并发、高频调用也稳定
3. 成本长期更低
-
一次性投入硬件 / 部署,无按 Token 计费
-
适合大量调用、长期使用、批量处理
-
不用依赖外网,断网也能用
4. 完全可控、可定制
-
可微调、二次开发,适配业务场景
-
可修改 prompt 策略、模型参数、安全规则
-
可对接内部系统、私有知识库
-
无平台限制、无 API 限流
5. 离线可用
-
内网、无网环境、机房隔离环境都能稳定运行
-
不受云服务停机、地区限制影响
6. 合规性更强
-
满足数据本地化、行业监管要求(金融、政务、医疗等)
-
日志、审计、权限完全自己管理
3、部署大模型的方式
| 部署方式 | 核心特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 使用开放API | 直接调用云端服务商(如DeepSeek、OpenAI)提供的API接口,模型和数据都存储在服务商的服务器上。 | 零部署成本,开箱即用,按量付费。 | 数据存在第三方,有隐私泄露风险;服务稳定性依赖供应商;长期成本可能较高。 | 个人开发者测试、对数据安全要求不高的应用、快速原型验证。 |
| 云平台部署 | 在公有云(如华为云、阿里云、腾讯云)的虚拟机上,使用工具(如Ollama)自行部署模型。模型可以放在云端,但由你完全掌控。 | 前期投入低,部署方便,网络延迟较低。 | 数据仍存储在第三方云平台,存在一定隐私风险;长期租赁云服务器成本也较高。 | 希望平衡成本、性能和控制力的中小型企业。 |
| 本地/私有化部署 | 将模型部署在企业内部的自有服务器上,完全由企业自己管理和维护。 | 数据完全自主可控,安全性最高;不依赖外部网络,长期运行成本更低。 | 初期硬件投入巨大,需要专业的运维团队,维护复杂。 | 对数据隐私和安全有极致要求的金融、医疗、政务等领域。 |
| 边缘部署 | 将轻量化模型部署在靠近数据源的终端设备上,如手机、摄像头、工业控制器等。 | 响应速度极快(低延迟),节省网络带宽,数据不出设备,隐私性极佳。 | 边缘设备算力有限,难以运行大参数模型;设备分散,维护和升级困难。 | 自动驾驶、工业物联网、端侧AI应用等对实时性要求极高的场景。 |
4、部署大模型的性能要求
| 硬件组件 | 最低配置要求 (适合1.5B-7B小模型) | 推荐配置要求 (适合7B-14B主流模型) | 高阶配置要求 (适合32B-70B+大型模型) | 配置说明与建议 |
|---|---|---|---|---|
| GPU (显卡) | 可选,如有NVIDIA GTX 1060 (4GB显存) 可加速 | 必需,NVIDIA RTX 3060 (12GB显存) 或更高 | 必需,NVIDIA RTX 4090 (24GB显存) 或多卡并联 (如2*RTX 4090) | GPU是核心。显存大小直接决定你能跑多大的模型。7B模型量化后约需6-8GB显存,14B模型需12-16GB,70B模型需40GB以上。NVIDIA卡配合CUDA支持最好。 |
| 内存 (RAM) | 16GB | 32GB | 64GB 或更高 | 内存是显存的备用池。当显存不够时,会占用一部分内存。模型本身加载也需要内存。 |
| CPU (处理器) | 4核以上 (如Intel i5) | 8核以上 (如Intel i7/i9, AMD Ryzen 7/9) | 16核以上 (如高端工作站CPU) | CPU负责数据预处理和调度,核心越多,处理越流畅。尤其在纯CPU模式下,对核心数要求更高。 |
| 存储 (硬盘) | 必需 NVMe SSD,预留50GB以上空间 | 必需 NVMe SSD,预留100GB以上空间 | 必需 NVMe SSD,预留200GB或1TB以上空间 | SSD是必须的,NVMe协议速度更快。模型文件大小:7B模型约4-15GB,70B模型可达40GB以上。 |
5、部署docker desktop
https://www.docker.com/products/docker-desktop/
下载windows的docker
5.1确认cpu已经启动虚拟化
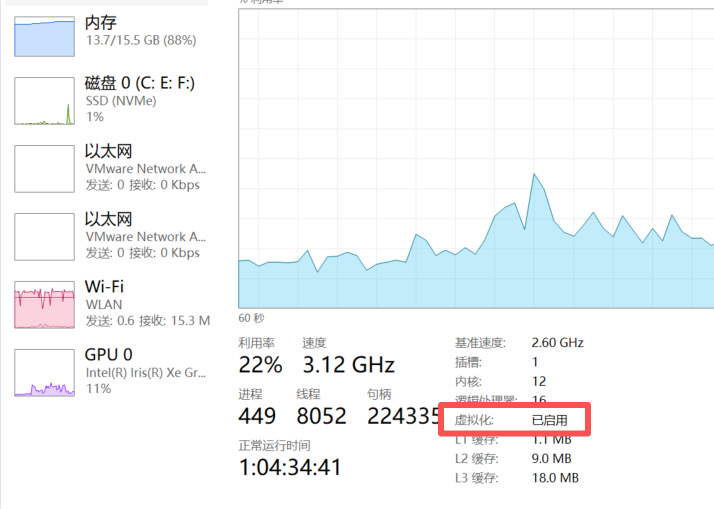
5.2、启用Hyper-V和WSL 2
打开“控制面板” > “程序” > “启用或关闭Windows功能”,勾选 Hyper-V、windows虚拟机监控平台、适用于linux的windows子系统
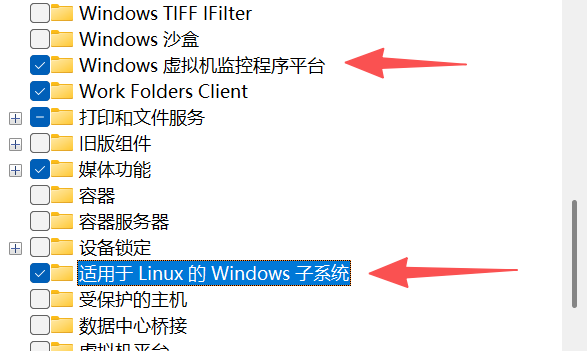
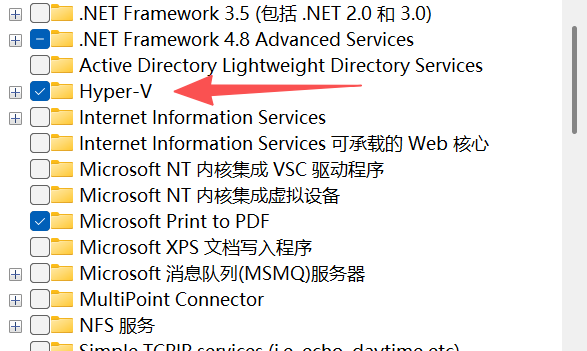
重启电脑
安装wsl
powershell管理员模式运行如下,检查是否安装
PS C:\WINDOWS\system32> wsl --status
未安装适用于 Linux 的 Windows 子系统。可通过运行 “wsl.exe --install” 进行安装。
有关详细信息,请访问 https://aka.ms/wslinstall
PS C:\WINDOWS\system32> wsl.exe --install
正在下载: 适用于 Linux 的 Windows 子系统 2.6.3
正在安装: 适用于 Linux 的 Windows 子系统 2.6.3
已安装 适用于 Linux 的 Windows 子系统 2.6.3。
正在安装 Windows 可选组件: VirtualMachinePlatform部署映像服务和管理工具
版本: 10.0.26100.5074映像版本: 10.0.26200.7840
启用一个或多个功能
[==========================100.0%==========================]
操作成功完成。
请求的操作成功。直到重新启动系统前更改将不会生效。
请求的操作成功。直到重新启动系统前更改将不会生效。PS C:\WINDOWS\system32> wsl --install -d Ubuntu
PS C:\WINDOWS\system32> wsl --set-default-version 2 #设置默认版本为WSL 2
有关与 WSL 2 关键区别的信息,请访问 https://aka.ms/wsl2操作成功完成。
PS C:\WINDOWS\system32>
安装完成后,wsl启动
PS C:\WINDOWS\system32> wsl -l -v
NAME STATE VERSION
* Ubuntu Running 2
docker-desktop Running 2
PS C:\WINDOWS\system32> wsl
wsl: 检测到 localhost 代理配置,但未镜像到 WSL。NAT 模式下的 WSL 不支持 localhost 代理。
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.master@localhost:/mnt/c/WINDOWS/system32$
需要在ubuntu环境中安装docker环境
master@localhost:/mnt/c/WINDOWS/system32$ sudo apt update
master@localhost:/mnt/c/WINDOWS/system32$ sudo apt install docker.io -y
master@localhost:/mnt/c/WINDOWS/system32$ docker --version
Docker version 28.2.2, build 28.2.2-0ubuntu1~24.04.1
master@localhost:/mnt/c/WINDOWS/system32$ docker run hello-world #拉取镜像
Unable to find image 'hello-world:latest' locally
5.3、安装docker desktop
双击下载的docker安装包,
- 勾选 Use WSL 2 instead of Hyper-V(推荐)
- 勾选 Add Docker Desktop to PATH
安装完重启电脑
5.4、检查安装
cmd:
PS C:\WINDOWS\system32> docker --version
Docker version 29.2.1, build a5c7197
PS C:\WINDOWS\system32> docker-compose --version
Docker Compose version v5.0.2
5.5、配置镜像加速
Docker默认从Docker Hub 拉取镜像,国内用户因为某些原因,访问不了。可配置其他镜像源提升速度
登录或者注册后打开
Docker Desktop > Settings > Docker Engine
然后复制一些镜像加速地址
https://www.rockylinux.cn/notes/docker-image-accelerator-and-configuration-guide.html
右下角apply
5.6、配置wsl
- Docker Desktop > Settings > Resources > WSL Integration
6、安装ollama,通过pull拉去ollama镜像
拉取下来可以运行,通过exec连接容器内部,根据你的配置选择模型。我这里选择deepseek-r1:7b
下载完成后就可以直接聊天了
7、部署webUI
如果你不想在命令行里聊天,可以装个图形界面
https://chatboxai.app/zh下载 Chatbox
安装后在设置里选择 Ollama API
它会自动连到你本地的 http://localhost:11434
选择 deepseek-r1:7b 模型,就可以像用 ChatGPT 一样聊天了

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)