服务器数据恢复实战:联想X3650 M5 RAID5阵列两块硬盘故障,数据还能救回来吗?
摘要:某公司联想服务器因运维人员忽视RAID5阵列中两块硬盘的故障告警,导致阵列崩溃、数据危殆。经专业检测,两块硬盘分别出现磁头磨损和失效问题。通过磁头更换、只读镜像和RAID重组技术,成功恢复所有核心数据。回迁时服务器卡LOGO的意外通过固件升级解决。最终客户确认数据完整恢复。案例警示:RAID5非保险箱,单盘故障后必须及时处理,定期固件更新也很重要,数据备份才是根本保障。(149字)
目录
一、事故背景:一次“拖延症”引发的数据危机
客户公司一台联想X3650 M5服务器,配置了3块2TB SAS机械硬盘组建RAID5阵列,承载着公司核心数据库、业务软件及大量办公文档。据客户描述,其中一块硬盘其实早就出现故障告警,但运维人员没有及时处理——这种“坏了一块没事,反正RAID5还能扛”的心态,在IT圈并不少见。然而,当第二块硬盘也亮起红灯时,阵列直接瘫痪,服务器无法启动,数据危在旦夕!

此时客户才意识到问题的严重性:如果数据丢失,公司业务将面临全面停摆。于是,他们第一时间联系到我们广州数据恢复中心,带着服务器主机和备份盘紧急上门求助。
二、初诊评估:两块硬盘“双重暴击”
按照标准流程,我们首先对服务器进行断电,将所有硬盘按原顺序标记后取出,逐一接入专业检测设备进行物理状态评估。检测结果与客户描述一致:
-
硬盘1:故障时间最长,磁头组件已严重磨损,盘片表面出现划伤——基本宣告物理死亡,数据恢复希望渺茫。
-
硬盘2:第二块损坏的硬盘,虽然盘片完好,但磁头也已失效,无法正常读取数据。在RAID5阵列中,只要还有一块盘能工作,理论上阵列仍可降级运行,但两块同时故障,阵列必然崩溃。
三、恢复方案:磁头更换 + 只读镜像 + RAID重组
对于硬盘2,盘片完好是关键。我们决定采用“磁头更换”技术:找到同型号的配件盘,在洁净环境下将损坏的磁头更换为正常磁头,成功使硬盘2恢复可读状态。这一步非常考验经验和技术,稍有偏差就可能造成盘片二次损伤。
随后,所有硬盘接入专业数据恢复设备,以只读方式进行全盘镜像——确保不对原始数据造成任何修改。基于完整的镜像文件,我们开始底层分析RAID5阵列参数:
-
条带大小(Stripe Size)
-
数据旋转方向(Rotation)
-
校验块分布(Parity Pattern)
通过自主研发的分析算法,我们成功重组出原始RAID5逻辑卷,提取出完整的文件系统结构。最终,客户的核心数据库和所有业务文件均被完整恢复!
四、意外插曲:服务器卡Logo,固件升级解难题
数据恢复完成后,我们准备将数据回迁至原服务器,却在开机时遇到诡异现象:服务器开机自检卡在联想Logo界面,按F1/F9进入BIOS也直接死机。这种故障在以往案例中非常少见,难道服务器主板也出问题了?
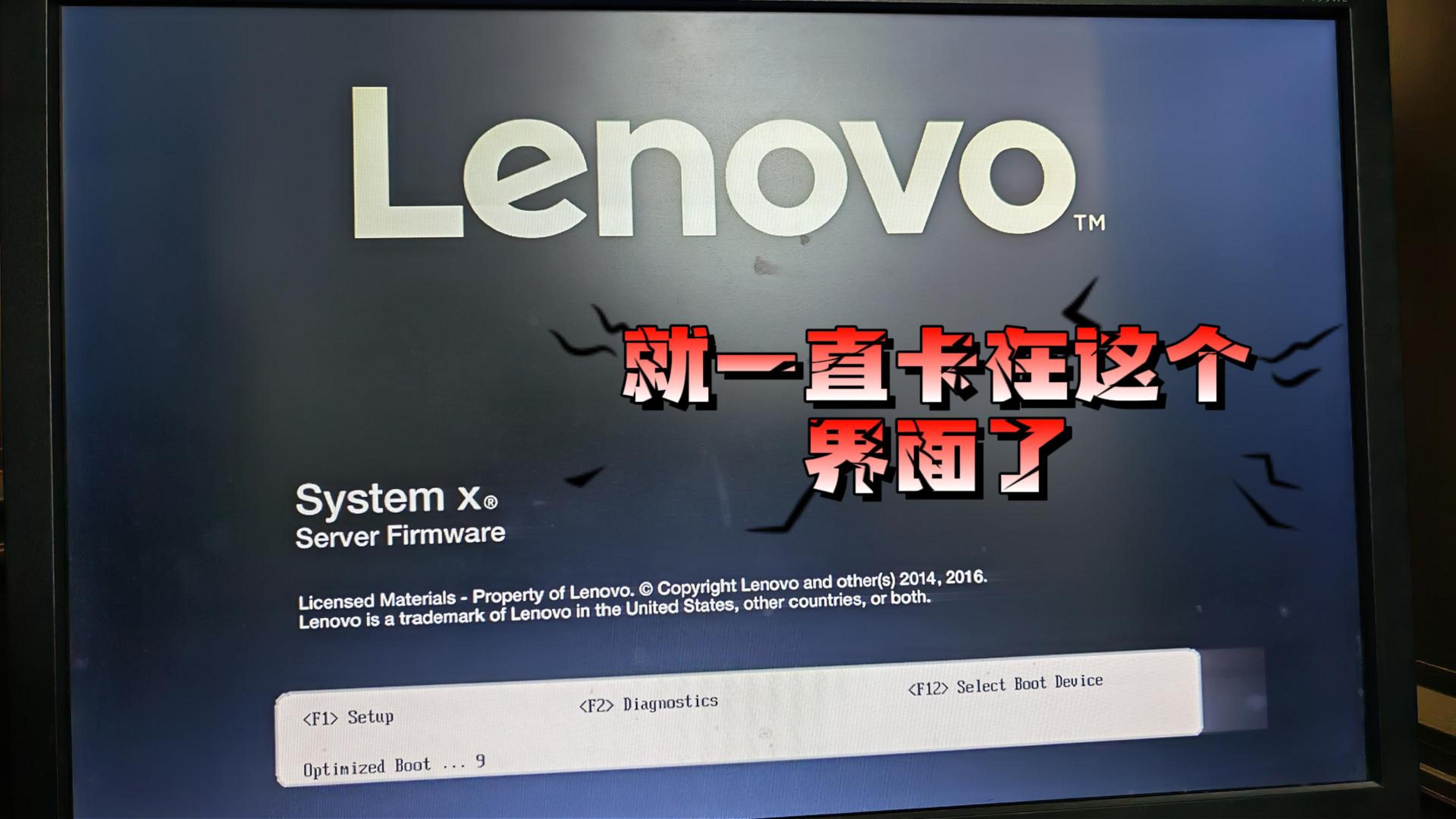
冷静分析后,我们考虑到这台X3650 M5服役已近十年,固件版本可能过于陈旧。查阅联想官方文档,发现该型号早期固件存在某些兼容性问题,尤其是在更换硬盘或大量读写后可能引发启动挂起。于是我们下载了最新版固件,通过U盘强制刷新BIOS/UEFI。重启后,服务器顺利通过自检,进入系统!
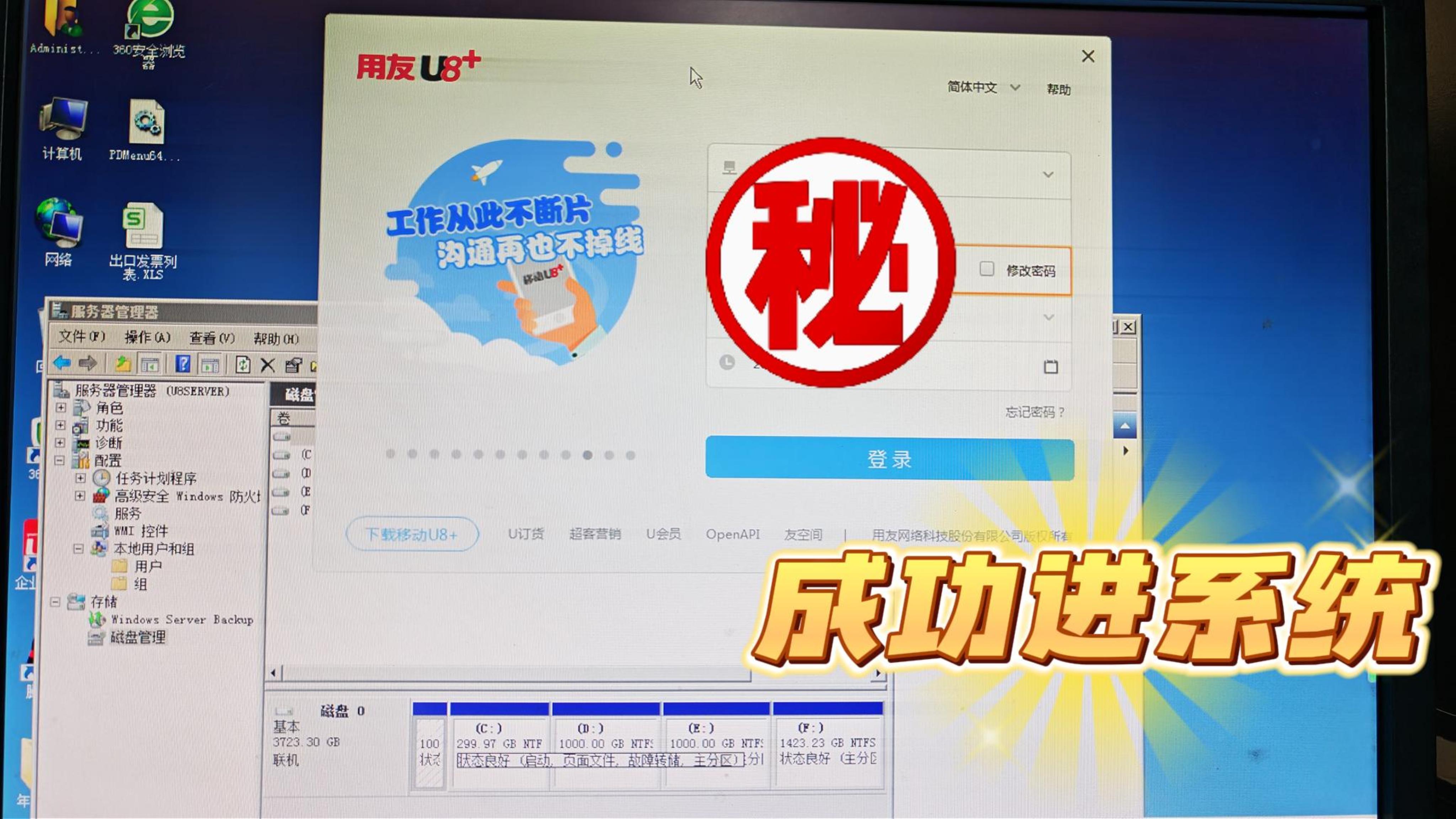
五、最终验收:客户远程确认,数据完整无误
将恢复的数据完整拷贝回服务器,配置好原有RAID阵列和系统环境后,我们邀请客户远程登录验证。客户现场打开数据库、运行业务软件、抽查办公文档,所有文件均能正常访问,数据完整无误。看到客户松了一口气,我们也倍感欣慰。

六、经验总结:RAID不是保险箱,备份才是王道
-
RAID不能替代备份:RAID5只能容忍一块硬盘故障,两块同时损坏时数据即刻面临风险。尤其当第一块故障后,阵列处于“脆弱的降级状态”,第二块盘随时可能因负载增大而损坏。
-
及时处理硬件告警:服务器硬件告警绝不能拖延,更换故障盘并重建阵列是标准操作。拖延只会让风险无限放大。
-
数据恢复需找专业机构:一旦发生阵列崩溃,不要盲目尝试重建或强制上线,这可能导致数据永久丢失。应立即联系专业数据恢复公司,由工程师进行物理检测和底层分析。
-
固件更新也重要:老旧服务器固件可能隐藏兼容性问题,定期升级固件有助于提高系统稳定性。
数据无价,防患于未然永远是最佳策略。希望这个案例能给各位运维同行敲响警钟,也祝愿所有数据都能被温柔以待!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)