CVPR 2026 | 推理加速 2.16 倍!港科大等提出 MODES:首个多模态 MoE 动态跳过框架
MODES 的出现,标志着多模态大模型推理进入了“精细化管理”时代。它不仅让我们看到了“偷懒”的艺术——即跳过那些不重要的专家,更通过科学的全局调度和模态感知,证明了高效与精准可以兼得。如果你正在为多模态模型的部署速度头疼,MODES 无疑是一剂良方。
在人工智能领域,多模态大模型(MLLM)如 Qwen2-VL、DeepSeek-VL 等正以前所未有的速度改变我们的生活。然而,随着模型规模的不断膨胀,推理时的计算开销和延迟也成了横在落地应用前的“大山”。
你是否想过,在处理每一条指令、每一张图片时,模型中成百上千个“专家”(Experts)真的都需要全力以赴吗?
由香港科技大学和北京航空航天大学等机构联合提出的 MODES 框架,给出了一个否定的答案。它通过动态专家跳过(Dynamic Expert Skipping),在保持极高准确度的同时,显著提升了推理速度 。

- 论文标题: MODES: Accelerating Mixture-of-Experts Multimodal Large Language Models via Dynamic Expert Skipping
- 论文地址: https://arxiv.org/abs/2511.15690
- 开源地址: https://github.com/ModelTC/MODES)
uu
核心痛点:为什么之前的“跳过”不灵了?
在混合专家(MoE)架构中,每个 token 理论上只由部分专家处理。为了更高效,开发者尝试进一步跳过那些贡献较小的专家。但研究团队发现,直接把纯文本模型的“专家跳过”方法搬到多模态模型上,性能会断崖式下跌 。
核心原因有二:
-
全局贡献不均(Insight i): 浅层专家其实比深层专家重要得多。在浅层犯的小错,会被后续层层放大,引发“误差爆炸” 。
-
模态间存在代沟(Insight ii): 视觉 Token 和文本 Token 在专家层里的表现完全不同。视觉 Token 在经过 FFN(前馈网络)时更新幅度较小,专家对其冗余度更高 。
创新黑科技:MODES 的两大法宝
MODES 是第一个专门为 MoE MLLM 设计的**免训练(Training-free)**加速框架 。它主要靠两个核心机制发力:
1. 全局调制局部路由 (GMLG)
传统的路由只看当前层的局部表现,而 GMLG 引入了“全局视野”。它通过离线校准,给每一层算出一个“重要性系数” α(l)\alpha^{(l)}α(l)。
- 重要性评分公式:
si(l)=α(l)⋅πi(l)s_i^{(l)} = \alpha^{(l)} \cdot \pi_i^{(l)}si(l)=α(l)⋅πi(l)
(其中 πi(l)\pi_i^{(l)}πi(l) 是局部路由概率,α(l)\alpha^{(l)}α(l) 是该层的全局贡献因子)
这样,浅层关键专家的分数会被调高,不容易被跳过;深层冗余专家的分数被调低,更敢于“偷懒” 。
2. 双模态阈值 (DMT)
既然视觉和文本 token 脾气不同,那就因材施教。MODES 为它们分别设定了跳过阈值 τt\tau_tτt(文本)和 τv\tau_vτv(视觉) 。
- 跳过逻辑: 如果一个专家的得分 si(l)s_i^{(l)}si(l) 低于对应模态的阈值,直接跳过!
搜索加速:从“两天”到“两小时”
为了找到最完美的 τt\tau_tτt 和 τv\tau_vτv,研发团队提出了一种前沿搜索(Frontier Search)算法 。利用性能损失和效率之间的单调性,搜索时间直接从 2 天多缩短到不到 2 小时,效率提升惊人 。
实力说话:又快又准的“成绩单”
在 3 个模型系列、13 个基准测试上的实验显示,MODES 堪称全场最强:
-
性能炸裂: 在 Qwen3-VL-MoE-30B 上跳过 88% 的专家时,MODES 的表现比之前的 SOTA 方法高出 10.67%,且依然保留了原模型 95% 以上的精度 。
-
速度飞起: 在推理过程中,Prefilling(预填充)速度提升了 2.16 倍,Decoding(解码)速度提升了 1.26 倍 。
选自论文中的关键图表:
-
图 1 (Figure 1): 清晰展示了在不同专家跳过比例下,MODES 的平均性能曲线远高于 DIEP、MC-MoE 等同类方法 。
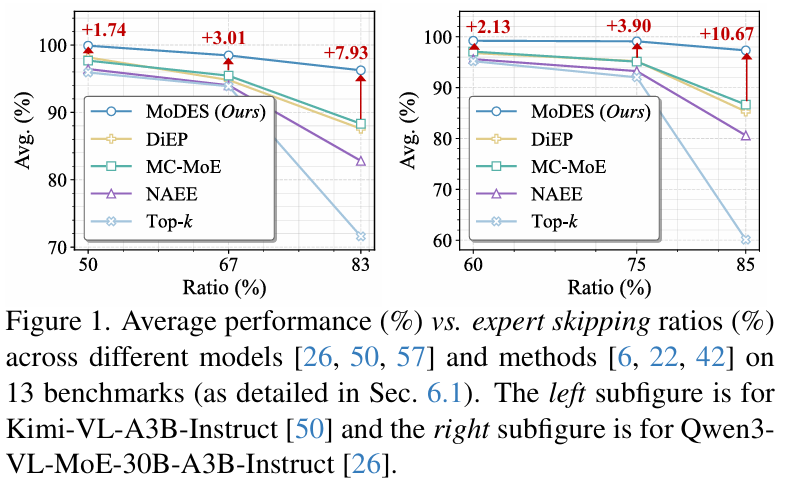
-
图 3 (Figure 3): 揭示了视觉与文本 token 在 FFN 层中的行为差异,验证了双模态处理的必要性 。
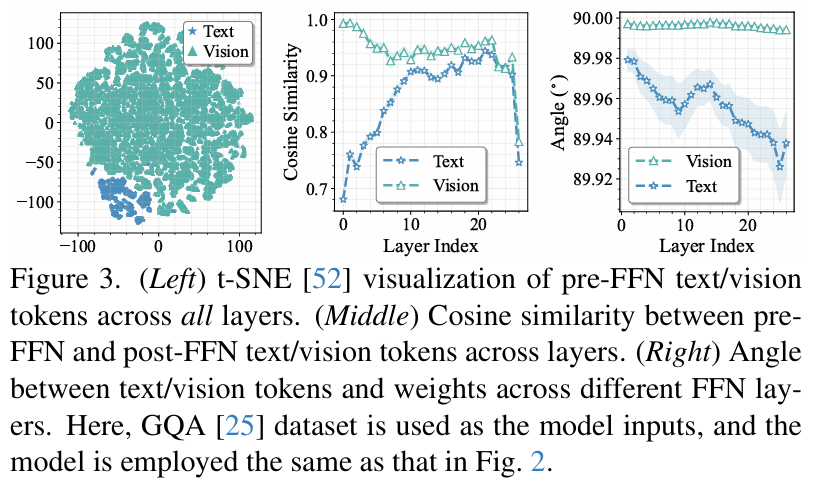
-
图 8 (Figure 8): 直观展示了 MODES 在深层和视觉模态上更积极地进行专家跳过 。
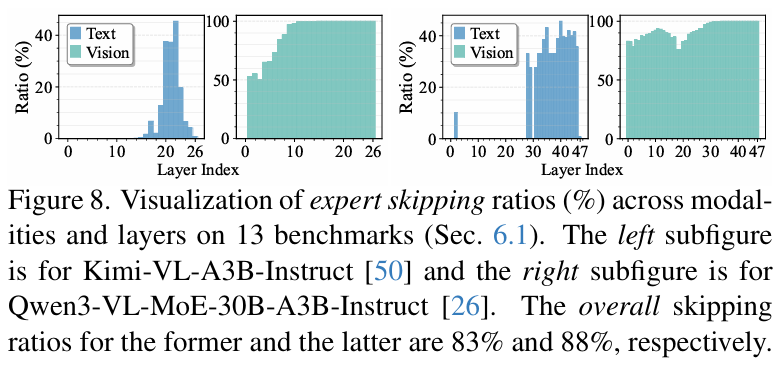
总结
MODES 的出现,标志着多模态大模型推理进入了“精细化管理”时代。它不仅让我们看到了“偷懒”的艺术——即跳过那些不重要的专家,更通过科学的全局调度和模态感知,证明了高效与精准可以兼得。
如果你正在为多模态模型的部署速度头疼,MODES 无疑是一剂良方。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)