收藏 | 从“思想的巨人,行动的矮子”到“万能助手”:小白必学大模型Agent进阶指南
单纯的大模型,只能对话和生成文本,是“思想的巨人,行动的矮子”。配上Agent的大模型,能感知环境、使用工具、执行任务,成为“万能助手”。MCP、Function Calling 和 A2A。这三项技术,并不是有你无我的排斥关系,而是可以通力协作的互补关系。大模型通过 Prompt 学习工具使用,实现非结构化任务处理,克服传统规则的“刚性”,使得AGI(Artificial General Int
大模型虽强大,但缺乏行动力。本文深入解析AI Agent如何通过MCP、Function Calling和A2A三大关键技术,与大模型协作,实现从“思想的巨人,行动的矮子”到“万能助手”的进化。文章详细介绍了AI Agent的构成、三大协议的原理及实现,以及上下文工程的重要性,帮助读者理解和应用Agent技术,提升大模型的应用能力。
在这场关于智能体(AI Agent)的进化革命中,背后隐藏着三个关键“武器”:MCP(Model Context Protocol)、Function Calling和A2A(Agent to Agent protocol)。简单来说,MCP、Function Calling和A2A分别代表三种AI Agent和外界不同的协作方式:
-
MCP
:AI Agent 与 AI Tools 之间的工具发现、注册和调用协议。注意:MCP并不会和LLM直接交互,不要被名字中的Model误导了,看完文章你就明白了。
-
Function Calling
:AI Agent 与 AI Model 之间的工具调用协议
-
A2A
:AI Agent 与 AI Agent 之间的发现与任务分配协议
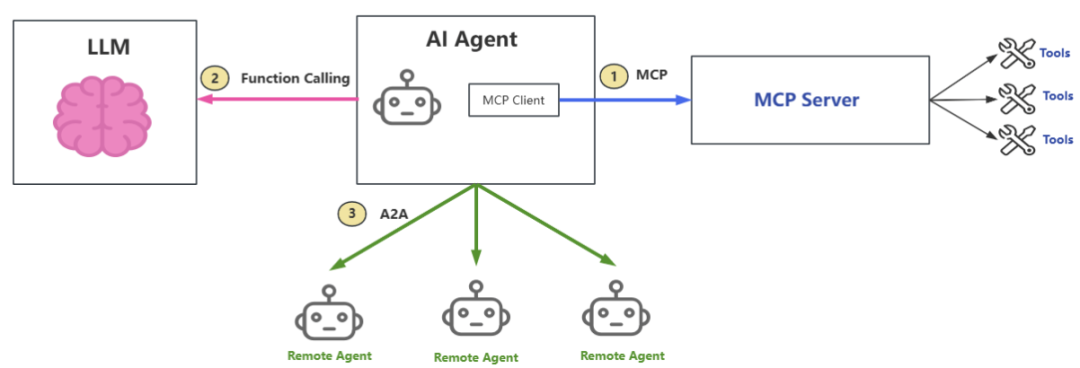
本文会深入解析MCP、Function Calling和A2A的协议细节,揭示其背后的本质,以便我们在工作中可以更好地开发、使用Agent技术。
1、 AI Agent
首先,让我们了解一下什么是AI Agent(人工智能体)?AI Agent 是一种能自主感知环境、自主规划并执行动作,以完成特定任务的智能系统。关于LLM和Agent的关系,有个形象的比喻——LLM是AI Agent的“大脑”,而AI Agent是LLM的“身体”。
-
没有Agent的LLM
,能力被禁锢在对话和文本生成中,是“思想的巨人,行动的矮子”。
-
没有LLM的Agent
,会退化为一个僵硬的、按固定流程行事的自动化脚本,缺乏应对不确定性的智慧和灵活性。
AI Agent区别于传统的SOP(Standard Operation Procedure),workflow在于,传统的方式是基于规则的自动化,有明确的、预设的“如果-那么”规则。而AI Agent是基于目标的自主性,能自主规划、执行、调整。能感知环境变化,动态调整策略。能处理模糊、不确定的任务。其本质在于大模型本身所具备的强大语言理解,推理和泛化能力。
一个完整的Agent除了大脑(LLM)外,还需要:
-
感知模块
: “眼睛和耳朵”,通过API、搜索引擎、文件系统等获取外部信息。
-
工具集
: “手和脚”,可以调用各种函数、API、软件等来影响现实。这就是Function Calling、MCP等技术的用武之地。
-
记忆模块
: “工作日志和经历”,通过向量数据库或记忆流记录过去的历史,用于长期规划和参考。
接下来,让我们一起看看AI Agent是如何用MCP、Function Calling和A2A技术让大模型从“思想的巨人,行动的矮子”变成“万能助手”的。
2、 MCP协议
为了更好的理解MCP(Model Context Protocol,模型上下文协议),我们需要先实现一个特殊的Agent,它能自动记录MCP client和server之间的通信内容。通过解析通信内容,无需多言,你就能明了MCP的真谛。
2.1 实现一个Agent
1)准备工作
- 安装Cline Agent,目前只有VS Code的插件
- 安装Python,以及uv工具(Python包安装器和解析器),设置repository源,在环境变量中,设置UV_INDEX_URL=https://repo.huaweicloud.com/repository/pypi/simple/
- 可用的大模型服务,比如openAI, deepseek,openrouter等
2)创建python项目
mkdir mcpserver
cd mcpserver
# 初始化项目
uv init
# 创建虚环境
uv sync
# 安装mcp
uv add mcp
# 激活虚拟环境(Windows)
.venv\Scripts\activate
3)创建MCP Server
这个MCP Server很简单,模拟一个获取天气信息的工具。其代码如下:
from mcp.server.fastmcp import FastMCP
# 一、创建FastMCP类
mcp = FastMCP("获取天气信息")
# 二、自定义工具(Stdio 模式)
@mcp.tool("获取天气信息")
defget_forecast(city) -> str:
"""
获取天气信息
参数:
city (str): 城市名称
返回:
city_forecast : 当前城市的天气信息
"""
# 这里只是简单的返回一个Mock,真实场景会调用天气API
return city + "明天有大暴雨!"
# 三、初始化MCP Server
if __name__ == '__main__':
# print
print("MCP Server is running...")
mcp.run(transport='stdio')
print("MCP exist")
除了上面这个MCP Server之外,我们还需要一个日志记录工具mcp_logger.py (https://github.com/MarkTechStation/VideoCode/) 用来截获mcp client和mcp server之间的通信(仅限于stdio方式),这个工具可以把通信内容写入到当前目录下的mcp_io.log日志文件
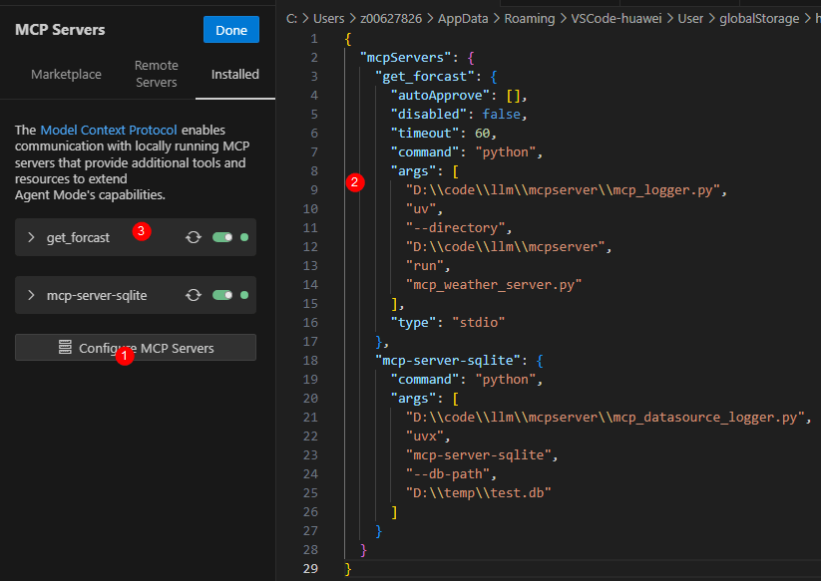
4)在Cline中配置MCP Server
1)在VSCode的Cline插件上点击“Configure MCP Servers”
2)在配置文件中写入启动mcp server的信息,这条配置的意思是:通过“python mcp_logger.py uv run mcp_weather_server.py”命令来运行MCP Server
3)当看到配置界面的get_forcast工具为绿色时,表示MCP Server已经配置并启动成功了
5)验证Agent使用工具
当我们在任务窗口输入“杭州明天的天气如何”,会发现Cline Agent在大模型的帮助下,会主动调用get_forecast工具,然后成功完成任务。
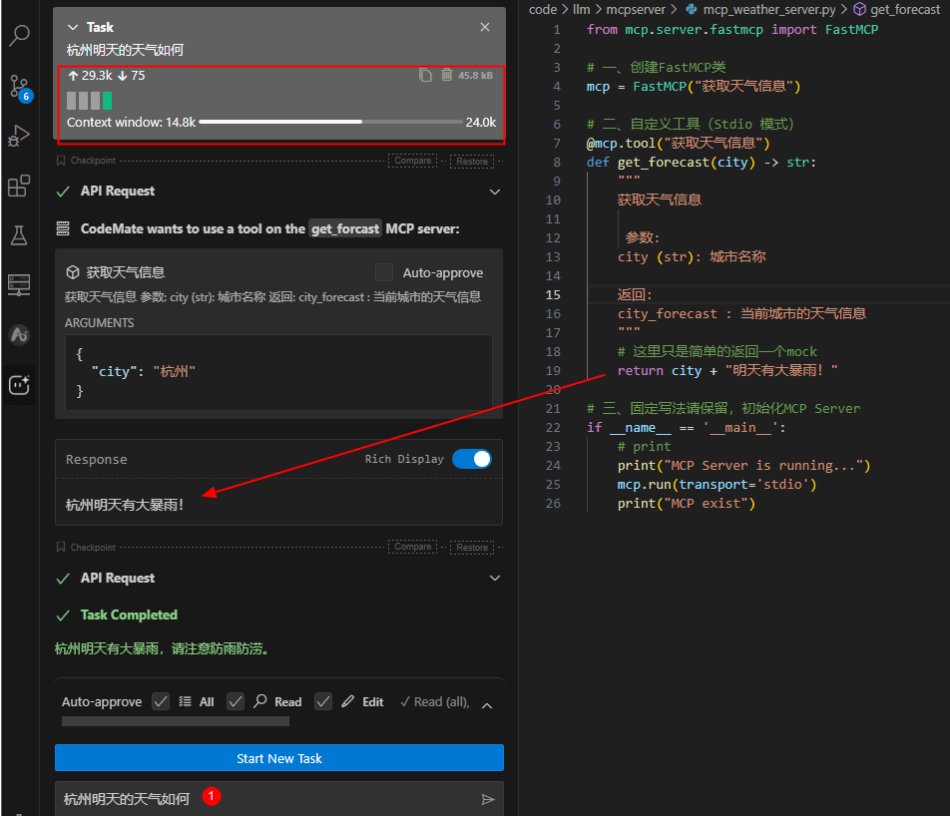
此时查看mcp_io.log,会发现它记录了完整的MCP Client 和 MCP Server之间的通信内容。
== 1. 初始化阶段 ==
MCP Client发送:{"method":"initialize","params":{"protocolVersion":"2025-06-18","capabilities":{},"clientInfo":{"name":"CodeMate","version":"25.2.200"}},"jsonrpc":"2.0","id":0}
MCP Server发送:{"jsonrpc":"2.0","id":0,"result":{"protocolVersion":"2025-06-18","capabilities":{"experimental":{},"prompts":{"listChanged":false},"resources":{"subscribe":false,"listChanged":false},"tools":{"listChanged":false}},"serverInfo":{"name":"获取天气信息","version":"1.16.0"}}}
MCP Client发送:{"method":"notifications/initialized","jsonrpc":"2.0"}
== 2. 工具注册阶段 ==
MCP Client发送:{"method":"tools/list","jsonrpc":"2.0","id":1}
MCP Server发送:{"jsonrpc":"2.0","id":1,"result":{"tools":[{"name":"获取天气信息","description":"\n 获取天气信息\n\n 参数:\n city (str): 城市名称\n\n 返回:\n city_forecast : 当前城市的天气信息\n ","inputSchema":{"properties":{"city":{"title":"city","type":"string"}},"required":["city"],"title":"get_forecastArguments","type":"object"},"outputSchema":{"properties":{"result":{"title":"Result","type":"string"}},"required":["result"],"title":"get_forecastOutput","type":"object"}}]}}
MCP Client发送:{"method":"resources/list","jsonrpc":"2.0","id":2}
MCP Server发送:{"jsonrpc":"2.0","id":2,"result":{"resources":[]}}
MCP Client发送:{"method":"resources/templates/list","jsonrpc":"2.0","id":3}
MCP Server发送:{"jsonrpc":"2.0","id":3,"result":{"resourceTemplates":[]}}
== 3. 工具调用阶段 ==
MCP Client发送:{"method":"tools/call","params":{"name":"获取天气信息","arguments":{"city":"杭州"}},"jsonrpc":"2.0","id":4}
MCP Server发送:{"jsonrpc":"2.0","id":4,"result":{"content":[{"type":"text","text":"杭州明天有大暴雨!"}],"structuredContent":{"result":"杭州明天有大暴雨!"},"isError":false}}
2.2 解析MCP协议
通过日志我们可以看到,MCP通信内容是基于JSON-RPC协议的,JSON-RPC是我见过最简洁的协议,就像其口号说的,simple is better。
我们把日志转换成时序图,不难发现,整个通信过程分为3个阶段:
-
初始化阶段
:也就是MCP Client和 MCP Server的握手过程。通常,MCP Client是以内置组件的形式存在于Agent内部。
-
工具注册阶段
:MCP Client会询问MCP Server,你有哪些可用的tools(工具),resources(资源)、templates(模板)。MCP Server会按照规定的格式返回对应的能力描述。
-
工具调用阶段
:当大模型需要调用工具时,会告诉Agent,你需要用
{"city":"杭州"}这个参数,去调用下get_forecast这个工具。MCP Client知道这个工具是“获取天气信息”这个MCP Server提供的,调用即可。
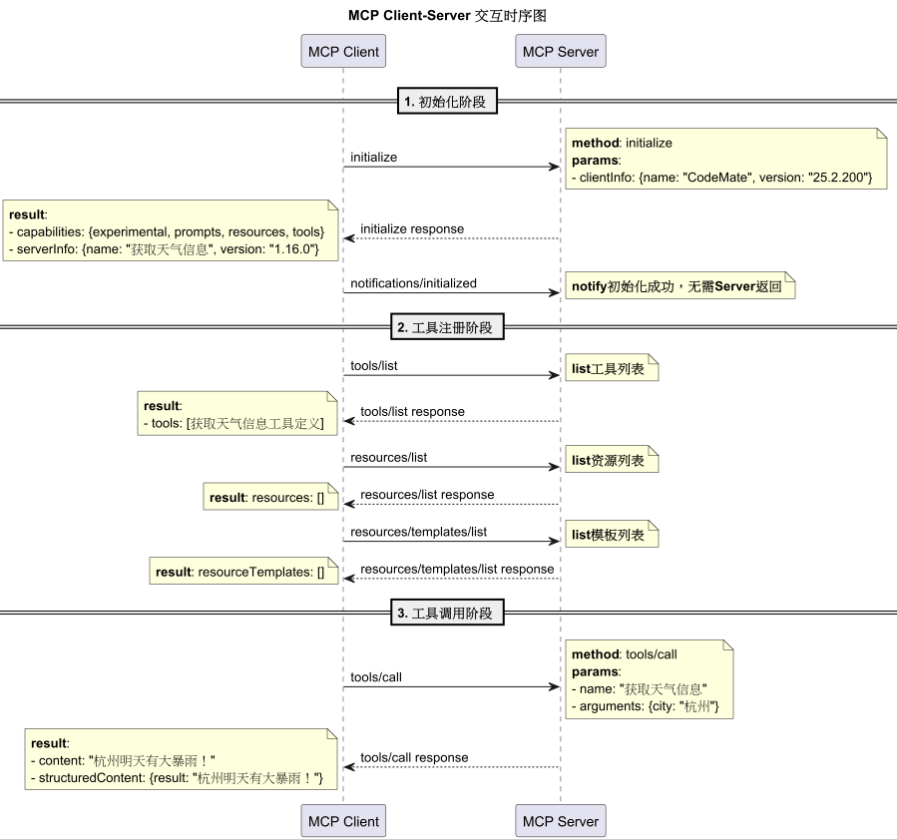
这就是MCP,其本质就是支持AI Agent用一种通用的方式发现、注册、调用外部的工具,从而协助LLM完成用户任务。wait,大模型怎么知道要在什么时候调用工具,以及用什么方式调用工具呢?
3、 Function Calling (大模型为什么知道要调用哪个工具)
当我问“杭州明天的天气如何”的时候,大模型为什么知道要调用get_forecast这个工具呢?实际上,这就是大模型的Function Calling,而这个能力需要我们通过prompt的方式来教大模型。这个能力正是大模型区别传统SOP的关键:用非结构化的“柔性”,完美克服了传统规则的“刚性”。
我们可以通过查看Cline的源码来理解Agent是如何“指导”大模型进行Function Calling的。你可以在此查看:Cline的完整system prompt(https://github.com/cline/cline),整个prompt有600行,将近50K大小,总共13000个字符,会消耗5000个tokens。这就是为什么很多人吐槽Cline Agent烧Token的原因:)。内容比较多,我们截取里面部分内容分析一下,你就明白为什么大模型有能力调用工具了。
3.1 身份声明
首先给模型带个高帽子,你是个软件高手!因为Cline是coding agent,当然要如此声明。可能还有个附加好处,直接激活MoE,帮服务端省点电费。
You are Cline, a highly skilled software engineer with extensive knowledge in many programming languages, frameworks, design patterns, and best practices.
3.2 能力声明
亮明身份之后,还要声明所具备的能力(capabilities),即告诉大模型:
1)你能推理任务,并且step-by-step的使用工具,完成任务。这是客户端能变成Agent的关键,即让模型follow ReAct(Reasoning+Acting)模式,处理用户任务。
2)你能使用工具,且会用XML的格式与我沟通。不同的Agent会选择不同的格式,Cline是用XML,也可以是JSON。
TOOL USE
You have access to a set of tools that are executed upon the user's approval. You can use one tool per message, and will receive the result of that tool use in the user's response. You use tools step-by-step to accomplish a given task, with each tool use informed by the result of the previous tool use.
# Tool Use Formatting
Tool use is formatted using XML-style tags. The tool name is enclosed in opening and closing tags, and each parameter is similarly enclosed within its own set of tags. Here's the structure:
<tool_name>
<parameter1_name>value1</parameter1_name>
<parameter2_name>value2</parameter2_name>
...
</tool_name>
3.3 系统工具能力
Cline作为coding agent,已经内置了一些工具,主要是和写代码相关的。包括execute_command(执行命令),read_file(读文件),write_to_file(写文件)等。这里有一个工作目录(working directory)的概念,为了安全性考虑,文件操作只被允许在working directory下面。因此,在实际使用Cline之前,我们需要搞清楚当前的working directory是在哪里。
## execute_command
## read_file
## list_files
## write_to_file
Description: Request to write content to a file at the specified path. If the file exists, it will be overwritten with the provided content. If the file doesn't exist, it will be created. This tool will automatically create any directories needed to write the file.
Parameters:
- path: (required) The path of the file to write to (relative to the current working directory ${cwd.toPosix()})
- content: (required) The content to write to the file. ALWAYS provide the COMPLETE intended content of the file, without any truncation or omissions. You MUST include ALL parts of the file, even if they haven't been modified.
Usage:
<write_to_file>
<path>File path here</path>
<content>
Your file content here
</content>
</write_to_file>
3.4 MCP扩展工具能力
除了Cline的内建工具之外,当然少不了用户自定义的扩展工具,比如我们案例中的get_forecast工具,之所以我们的Agent会调用MCP Server的get_forecast工具“获取天气信息”。正是因为我们在2.1章节中注册了get_forecast MCP工具。对于Cline Agent而言,所谓的工具注册,就是在Cline发送给大模型的prompt中加入了如下的功能描述信息。这些提示词和内建工具的提示词类似,都是在“指导”大模型,教它有这些工具的能力(capabilities),从而实现Function Calling。
# Connected MCP Servers
When a server is connected, you can use the server's tools via the `use_mcp_tool` tool, and access the server's resources via the `access_mcp_resource` tool.
## weather (python mcp_logger.py uv run mcp_weather_server.py)
### Available Tools
- get_forecast: 获取天气信息
Args: city: 城市名称
Input Schema:
{
"type": "object",
"properties": {
"city": {
"title": "city",
"type": "string"
}
},
"required": [
"city"
],
"title": "get_forecastArguments"
}
3.5 完成任务
当完成所有的subtask,迭代执行完tools,达成任务目标。大模型需要通过<attempt_completion>通知Agent任务完成,并在<result>中呈现最终任务执行结果,如果需要demonstrate(演示)的话,也可以有演示的CLI,但这是可选的。
## attempt_completion
Description: After each tool use, the user will respond with the result of that tool use, i.e. if it succeeded or failed, along with any reasons for failure. Once you've received the results of tool uses and can confirm that the task is complete, use this tool to present the result of your work to the user. Optionally you may provide a CLI command to showcase the result of your work. The user may respond with feedback if they are not satisfied with the result, which you can use to make improvements and try again.
IMPORTANT NOTE: This tool CANNOT be used until you've confirmed from the user that any previous tool uses were successful. Failure to do so will result in code corruption and system failure. Before using this tool, you must ask yourself in <thinking></thinking> tags if you've confirmed from the user that any previous tool uses were successful. If not, then DO NOT use this tool.
Parameters:
- result: (required) The result of the task. Formulate this result in a way that is final and does not require further input from the user. Don't end your result with questions or offers for further assistance.
- command: (optional) A CLI command to execute to show a live demo of the result to the user. For example, use \`open index.html\` to display a created html website, or \`open localhost:3000\` to display a locally running development server. But DO NOT use commands like \`echo\` or \`cat\` that merely print text. This command should be valid for the current operating system. Ensure the command is properly formatted and does not contain any harmful instructions.
Usage:
<attempt_completion>
<result>
Your final result description here
</result>
<command>Command to demonstrate result (optional)</command>
</attempt_completion>
4、Context Engieering
通过上文对Cline System Prompt的解读,你会发现,Agent的本质就是一个精心设计的Prompt。因为大模型本质上是“上下文学习者”:它们没有长期的记忆,每次交互都是独立的。你提供的上下文就是它此次交互的全部世界。
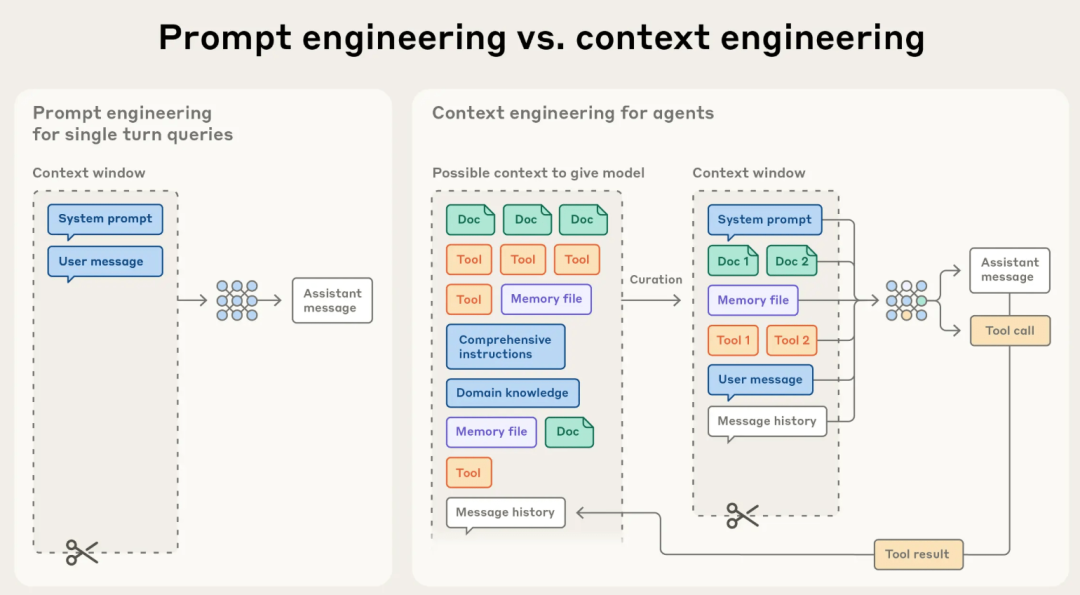
因此,要想实现完整的Agent功能,在传递给LLM的信息中,除了System prompt,user message之外,还要包括Docs(领域知识,工作对象等),工作记忆(Message history)等。把这些内容都汇总起来就是LLM需要的Context(上下文),而这个汇总(精炼、压缩)的工作就叫Context Engineering (https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents)。
这也是Context Engineering和Prompt Engineering的主要区别。
回过头来,你应该就能理解我在开篇说的,MCP是和模型无关的协议。MCP只是一个为了Model的Context而服务的Protocol。它既不和Model交互,也和Model无关。它只是给Context Engineering服务的一环。
5、 A2A协议
Agent的本质是Context,像Cline这样的Agent,通过MCP扩展的工具能力使用说明,都是放在prompt里,工具不多还好,如果很多,可能会撑爆Context Window,即使不会撑爆,过长的Context,也会引发Context Rot (https://research.trychroma.com/context-rot) 问题。这和我们人类的认知类似,信息越多,越难focus,越难抓住重点。
关于如何提供有效的,长度适中的Context,是Contex Engineering的关键。在Context Engineering一文中有详细阐述。常用的技术有Compaction(压缩),Structured Note-taking(结构化笔记),以及Multi-Agent architectures(多Agent架构)。所谓的Multi-Agent,就是从Agent层面做分而治之,从而控制单个Agent的Context长度。
而多agent之间的协作,就涉及到A2A协议,即Agent to Agent协议。
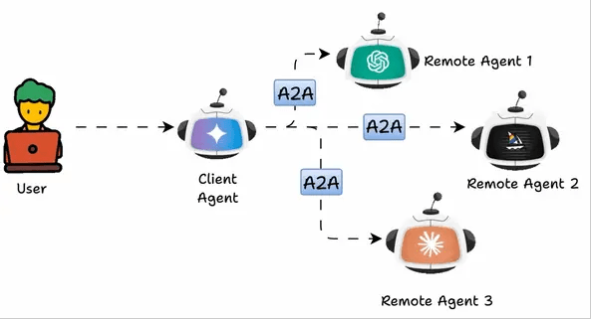
A2A是google开源的开放协议。其包含如下核心概念:
| 概念 | 描述 |
|---|---|
| Agent Card(卡片) | 位于 /.well-known/agent.json,描述能力、技能、端点 URL 和认证要求,用于发现 |
| A2A Server(服务器) | 实现协议方法,管理任务执行 |
| A2A Client(客户端) | 发送请求如 tasks/send 或 tasks/sendSubscribe,消费 A2A 服务 |
| Task(任务) | 核心工作单位,有唯一 ID,状态包括 submitted、working 等 |
| Message(消息) | 通信单位,角色为 user 或 agent,包含 Parts |
| Parts(部分) | 内容单位,包括 TextPart、FilePart、DataPart |
| Artifacts(工件) | 任务输出,包含 Parts |
| 流式传输 | 使用 SSE 事件更新长期任务状态 |
| 推送通知 | 通过 webhook 发送更新 |
和MCP一样,A2A采用的也是JSON-RPC协议,其工作机制也很类似,主要包括Agent的发现、注册和使用,通信细节不再赘述,大致流程如下:
-
发现
:客户端从 /.well-known/agent.json 获取 Agent Card,了解智能体的能力。
-
启动
:客户端发送任务请求:
-
处理
:服务器处理任务,可能涉及流式更新或直接返回结果。
-
交互(可选)
:若任务状态为 input-required,客户端可发送更多消息,使用相同 Task ID 提供输入。
-
完成
:任务达到终端状态(如 completed、failed 或 canceled)。
总结
单纯的大模型,只能对话和生成文本,是“思想的巨人,行动的矮子”。配上Agent的大模型,能感知环境、使用工具、执行任务,成为“万能助手”。AI Agent的核心在于Context Engineering,背后需要依赖三大关键技术:MCP、Function Calling 和 A2A。这三项技术,并不是有你无我的排斥关系,而是可以通力协作的互补关系。大模型通过 Prompt 学习工具使用,实现非结构化任务处理,克服传统规则的“刚性”,使得AGI(Artificial General Intelligence,通用人工智能)成为可能。
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。

👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献492条内容
已为社区贡献492条内容

所有评论(0)