【Openclaw】零基础搭建本地AI助手:用OpenClaw + Ollama,告别网络限制
这两款强大工具,在自己的电脑上搭建一个完全私有、随时可用的AI助手。我们将逐步完成环境准备、软件安装、模型部署和系统集成,最终让你体验到流畅、安全的本地化AI服务。:模型文件通常很大(几个GB到几十个GB),下载过程可能需要较长时间,具体取决于你的网络带宽和硬盘读写速度。是一个强大的AI代理框架,它可以将你的本地模型变成一个智能助手,并提供多种交互方式(如聊天机器人、自动化任务等)。是一个极其易用
摘要: 你是否曾因AI服务繁忙、网络延迟或数据隐私问题而感到困扰?本文将手把手教你如何利用 OpenClaw 和 Ollama 这两款强大工具,在自己的电脑上搭建一个完全私有、随时可用的AI助手。我们将逐步完成环境准备、软件安装、模型部署和系统集成,最终让你体验到流畅、安全的本地化AI服务。
关键词: OpenClaw, Ollama, 本地AI, 大语言模型, AI助手, 本地部署
引言:为什么要搭建本地AI?
随着人工智能技术的普及,我们越来越依赖AI助手来回答问题、编写代码、撰写文档等。然而,这些便利的背后常常伴随着一些痛点:
- 网络限制与拥堵:许多云端AI服务在高峰时段会出现“繁忙”提示,导致长时间等待甚至无法使用。
- 数据隐私担忧:将敏感的工作资料或个人信息输入公共AI平台,可能会带来数据泄露的风险。
- 高昂的成本:长期、高频的使用往往伴随着不菲的API费用。
为了解决这些问题,“本地AI”应运而生。顾名思义,就是将AI模型直接运行在你的个人电脑或服务器上。这样做有诸多好处:
- 断网可用:无需互联网连接,随时随地享受AI服务。
- 极致隐私:所有数据处理都在本地完成,确保信息安全。
- 成本低廉:除了硬件投入,没有额外的订阅或调用费用。
- 响应迅速:避免了网络传输延迟,交互体验更加流畅。
今天,我们将使用 Ollama 来管理并运行本地模型,并使用 OpenClaw 将其打造成一个功能丰富的AI助手。
第一步:准备工作——软硬件要求
在开始之前,请确保你的电脑满足以下基本要求:
- 操作系统:Windows 10/11 (64位), macOS, 或 Linux。
- 处理器 (CPU):现代多核处理器。
- 内存 (RAM):至少 16GB,对于运行更大模型(如7B以上)建议 32GB 或更高。
- 显卡 (GPU) (非必需,但强烈推荐):如果你有一块NVIDIA显卡,性能将得到巨大提升。Ollama会自动利用GPU加速。集成显卡也可以运行,但速度会慢很多。
- 存储空间:至少预留 10GB 以上的可用空间用于下载和存放模型文件。
第二步:安装核心工具——Ollama
Ollama是一个极其易用的工具,它简化了在本地运行大型语言模型的过程。你可以把它想象成一个模型的“应用商店”和“运行器”。
-
下载 Ollama:
- 打开你的网页浏览器,访问
Ollama的官方网站:https://ollama.com/ - 点击页面上的 “Download” 按钮,根据你的操作系统(Windows, macOS, Linux)下载对应的安装包。
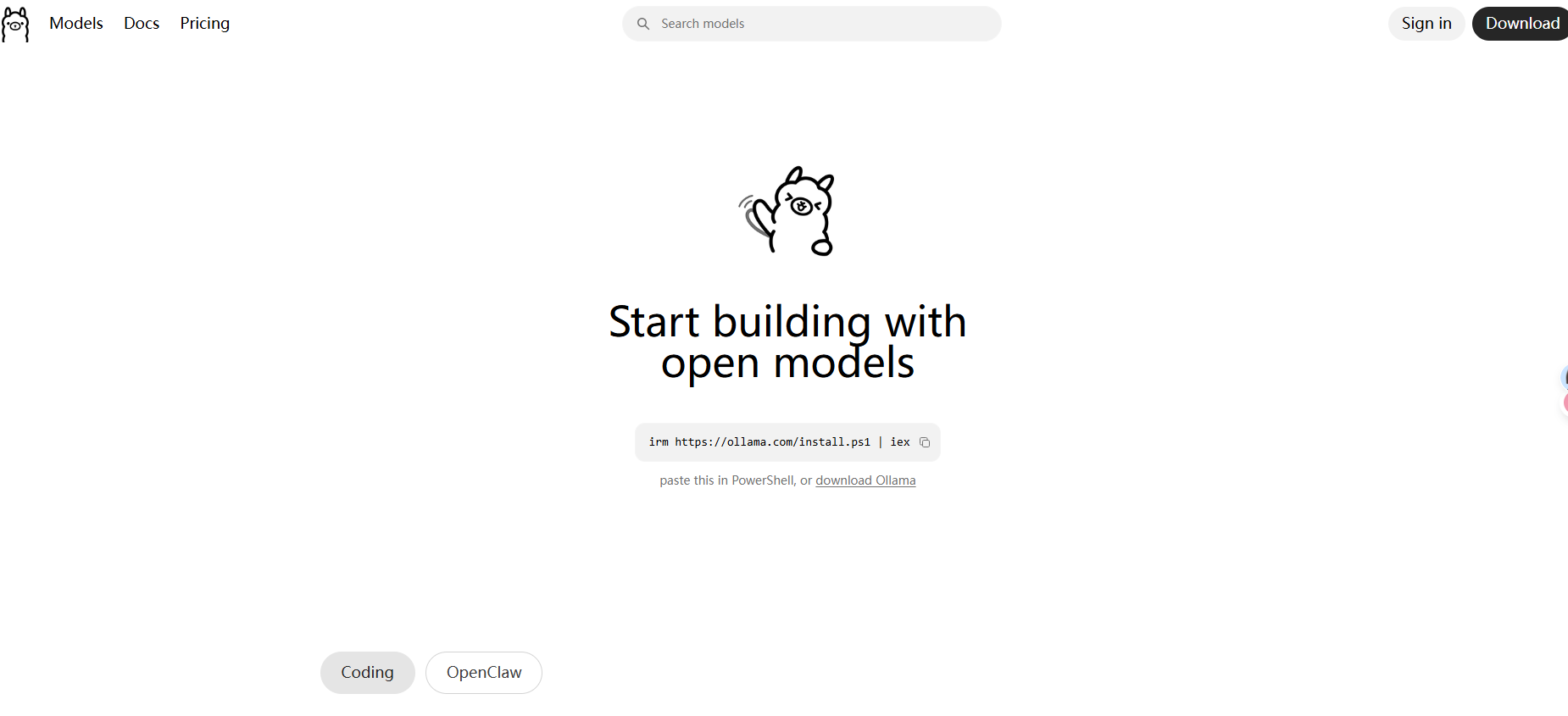
- 打开你的网页浏览器,访问
-
安装 Ollama:
- Windows/macOS: 下载完成后,双击
.exe或.pkg文件,按照安装向导的提示完成安装。 - Linux: 通常会提供一条命令行指令,复制并粘贴到终端执行即可。
- Windows/macOS: 下载完成后,双击
-
启动 Ollama:
- 安装完成后,启动 ollama。在 Windows 上,你可能会看到一个后台进程图标出现在系统托盘。在 macOS/Linux 终端,你可能需要保持一个终端窗口打开,或者将其作为后台服务启动。
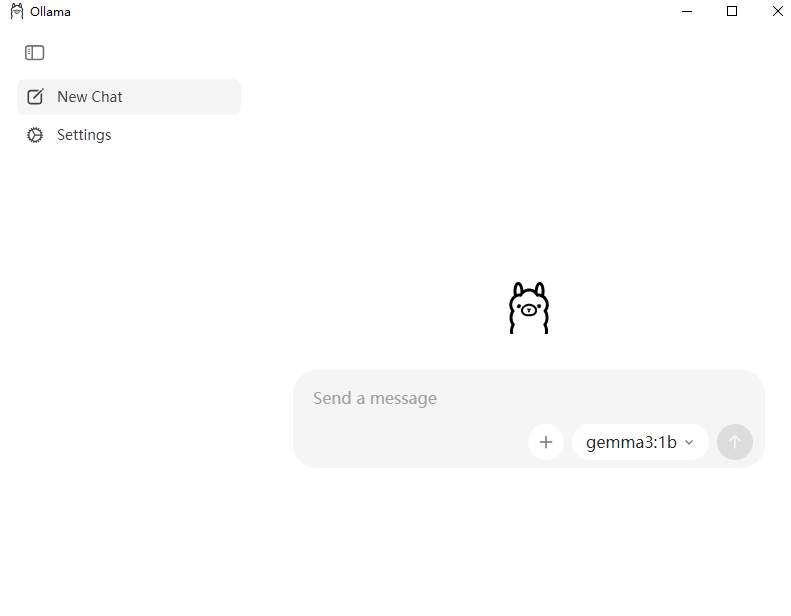
- 安装完成后,启动 ollama。在 Windows 上,你可能会看到一个后台进程图标出现在系统托盘。在 macOS/Linux 终端,你可能需要保持一个终端窗口打开,或者将其作为后台服务启动。
恭喜! 至此,Ollama 已经在你的电脑上准备就绪,等待加载模型。
第三步:选择并下载你的AI模型
Ollama 支持众多流行的大语言模型。对于本地部署,我们需要在模型性能和硬件资源之间找到平衡。一个广受欢迎且性能不错的中文模型是 Qwen3(通义千问)系列。
-
打开命令行工具:
- Windows: 按
Win + R,输入cmd,然后按回车,打开“命令提示符”。或者搜索并打开“PowerShell”。 - macOS/Linux: 打开“终端”应用程序。
- Windows: 按
-
下载模型:
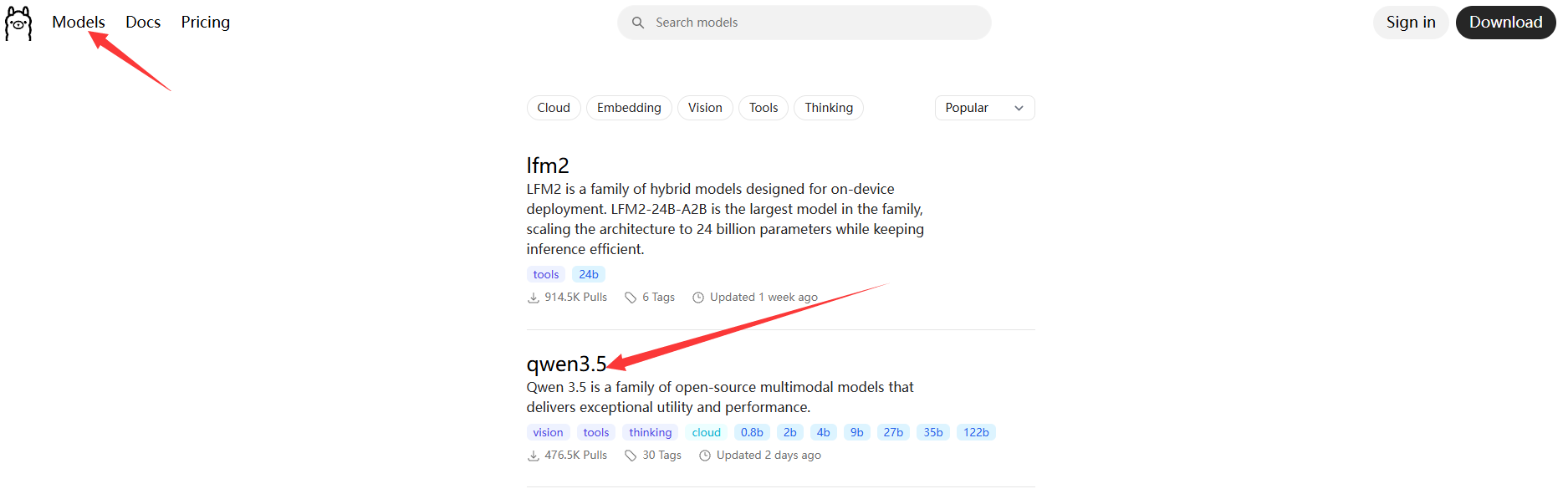
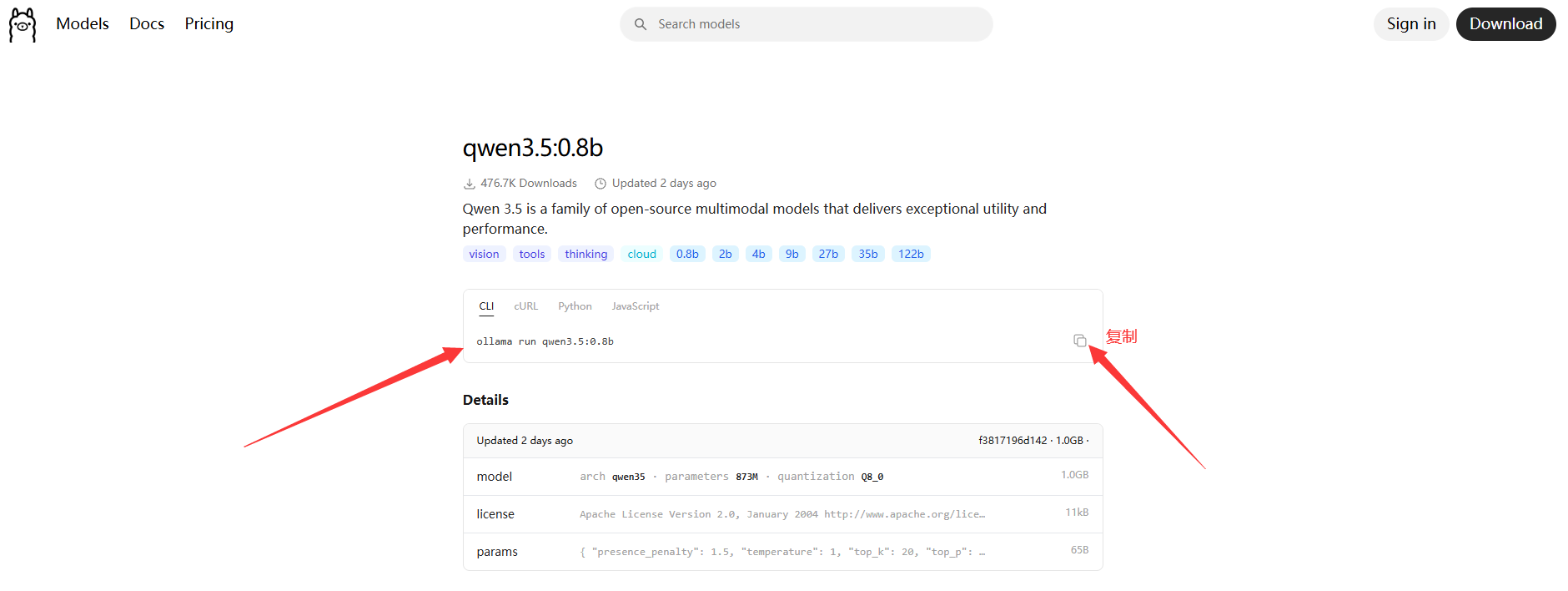
在打开的命令行窗口中,输入以下命令并按回车
-
ollama run qwen3.5:0.8b -
注意:模型文件通常很大(几个GB到几十个GB),下载过程可能需要较长时间,具体取决于你的网络带宽和硬盘读写速度。请耐心等待,直到命令行显示下载完成。
-
验证模型:
ollama list
第四步:安装与配置 OpenClaw
OpenClaw 是一个强大的AI代理框架,它可以将你的本地模型变成一个智能助手,并提供多种交互方式(如聊天机器人、自动化任务等)。
-
安装 OpenClaw:
-
定位配置文件:
OpenClaw的核心配置通常在一个名为openclaw.json的文件中。它的默认位置一般在用户目录下的隐藏文件夹中,例如:- Windows:
C:\Users\[你的用户名]\.openclaw\openclaw.json - macOS:
~/.openclaw/openclaw.json
- Windows:
- 重要:请确保你能够找到并编辑这个文件。你可能需要在文件管理器中启用“显示隐藏文件”的选项才能看到
.openclaw文件夹。
-
编辑配置文件,接入 Ollama:
- 用一个文本编辑器(如记事本、VS Code、Sublime Text等)打开
openclaw.json文件。 - 我们需要修改这个文件,告诉
OpenClaw去连接并使用刚才通过Ollama加载的本地qwen3模型。在配置文件中,找到models.providers这个部分。你需要添加一个名为ollama的提供者配置。
原始配置文件(可能类似于此,但缺少
ollama提供者):{ "models": { "providers": { // 可能有其他提供者配置,如 openai, azure 等 } }, "agents": { "defaults": { "model": { "primary": "..." // 这里指定了主模型 } } } }修改后的配置文件(添加
ollama提供者并设为主模型):{ "meta": { "lastTouchedVersion": "2026.3.2", "lastTouchedAt": "2026-03-05T01:50:42.331Z" }, "wizard": { "lastRunAt": "2026-03-04T10:05:45.591Z", "lastRunVersion": "2026.3.2", "lastRunCommand": "onboard", "lastRunMode": "local" }, "models": { "providers": { "ollama": { "baseUrl": "http://127.0.0.1:11434/v1", "apiKey": "sk-La1F6uiHWTR6S5FNxNUEwdeWJINw4Y4M",# 随意填写,毕竟本地化 "auth": "api-key", "api": "openai-completions", "authHeader": true, "models": [ { "id": "qwen3.5:0.8b", "name": "qwen3.5:0.8b", "api": "openai-completions", "reasoning": false, "input": [ "text" ], "cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 }, "contextWindow": 60000, "maxTokens": 60000 } ] } }, "bedrockDiscovery": { "defaultContextWindow": 1 } }, "agents": { "defaults": { "model": { "primary": "ollama/qwen3.5:0.8b" }, "models": { "qwen-portal/coder-model": { "alias": "qwen" }, "ollama/qwen3.5:0.8b": { "alias": "qwen3.5:0.8b" }, "qwen-portal/vision-model": {} }, "workspace": "C:\\Users\\Administrator\\.openclaw\\workspace" } }, "tools": { "profile": "messaging" }, "commands": { "native": "auto", "nativeSkills": "auto", "restart": true, "ownerDisplay": "raw" }, "session": { "dmScope": "per-channel-peer" }, "hooks": { "internal": { "enabled": true, "entries": { "session-memory": { "enabled": true } } } }, "gateway": { "port": 18789, "mode": "local", "bind": "loopback", "auth": { "mode": "token", "token": "76c38470534edf3c625d4aa0bfdb02730c491a90f16c7053" }, "tailscale": { "mode": "off", "resetOnExit": false }, "nodes": { "denyCommands": [ "camera.snap", "camera.clip", "screen.record", "contacts.add", "calendar.add", "reminders.add", "sms.send" ] } }, "plugins": { "entries": { "qwen-portal-auth": { "enabled": true } } } }- 关键点解释:
"baseUrl": "http://127.0.0.1:11434/v1":127.0.0.1代表本机,11434是Ollama默认监听的端口。OpenClaw会通过这个地址与Ollama通信。"id": "qwen3.5:0.8b":这个ID必须和你通过ollama pull命令拉取的模型名称一模一样。"primary": "ollama/qwen3.5:0.8b":这个路径告诉OpenClaw,当需要AI服务时,优先使用ollama提供者下的qwen3.5:0.8b 模型。
- 用一个文本编辑器(如记事本、VS Code、Sublime Text等)打开
-
保存配置文件:完成编辑后,保存
openclaw.json文件。
第五步:启动你的本地AI助手
一切准备就绪,现在是见证奇迹的时刻!
-
确保 Ollama 正在运行:检查你的系统托盘或后台进程,确保 ollama服务处于活动状态。
-
启动 OpenClaw Gateway:
- 再次打开命令行工具(如
cmd或PowerShell)。 - 输入以下命令并按回车:
openclaw gateway- 你会看到
OpenClaw启动的日志信息。如果配置正确,它会成功连接到Ollama,并加载你指定的qwen3.5:0.8b模型。
- 再次打开命令行工具(如
-
开始使用:
OpenClaw启动后,通常会提供一个本地网页地址(如 http://127.0.0.1:18789/)。- 打开你的浏览器,访问这个地址。你将看到一个聊天界面,现在你就可以开始与你本地的
Qwen3模型进行对话了。所有计算都在你的电脑上完成,没有网络延迟,也没有数据隐私之忧。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)