企业级生成式 AI 项目架构全解:从黑客松原型到生产级 RAG 系统的工程化落地
摘要:本文揭示了当前生成式AI项目开发中的核心痛点——黑客松式开发模式导致的架构混乱问题。文章提出了一套经过生产验证的企业级AI项目架构方案,通过五大模块(配置层、数据层、核心抽象层、业务逻辑层、工程化脚本层)实现全链路解耦。该架构严格遵循关注点分离、开闭原则等软件工程理念,特别强调LLM抽象层的设计,使业务代码与具体模型实现完全解耦。文中详细拆解了每个目录的设计逻辑与最佳实践,包括配置外部化、提
Don't build projects like it's a hackathon. 这句话,戳中了当下生成式 AI 行业最普遍的落地痛点。
在大模型与 RAG 技术全面爆发的今天,无数团队都在快速搭建自己的生成式 AI 应用:从智能客服、企业知识库问答,到代码助手、自动化内容生成平台。但绝大多数团队都犯了一个致命的错误:跳过架构设计,直接上手写代码实现 RAG 流水线或者 LLM 集成。
黑客松式的开发,确实能在几个小时里跑通一个看起来能用的原型:硬编码的 API 密钥、散落在各个文件里的提示词模板、和特定大模型深度耦合的业务逻辑、没有任何分层的面条代码。但 6 个月后呢?
你会发现,想把 GPT 换成 Claude,要修改十几个文件的代码;想调整模型的 temperature 参数,要翻遍整个项目的业务逻辑;想优化 RAG 的分块策略,发现数据处理和检索逻辑完全耦合在一起,牵一发而动全身;想排查线上问题,发现日志配置混乱,根本无法定位根因。最终,一个原本充满前景的 AI 项目,变成了无人敢碰的屎山代码。
原型和生产级系统的核心区别,从来不是你选了 GPT-4o 还是 Claude 3.7,也不是你用了 Pinecone 还是 Milvus 向量数据库,而是你如何组织模型之外的整个项目架构。
本文将完整拆解这套经过生产验证的企业级生成式 AI 项目结构,讲清每一个目录的设计逻辑、解决的核心痛点、以及背后的工程化最佳实践,帮你从一开始就搭建出可扩展、可维护、可测试的生产级 AI 系统。
架构概览:一套符合软件工程最佳实践的生成式 AI 项目结构
这套企业级生成式 AI 项目架构,严格遵循关注点分离、依赖倒置、开闭原则三大核心设计理念,把一个完整的 RAG 流水线拆解为配置层、数据层、核心抽象层、业务逻辑层、工程化脚本层五大模块,每个模块、每个文件都有清晰的职责边界,每个组件都独立可测试、可替换。
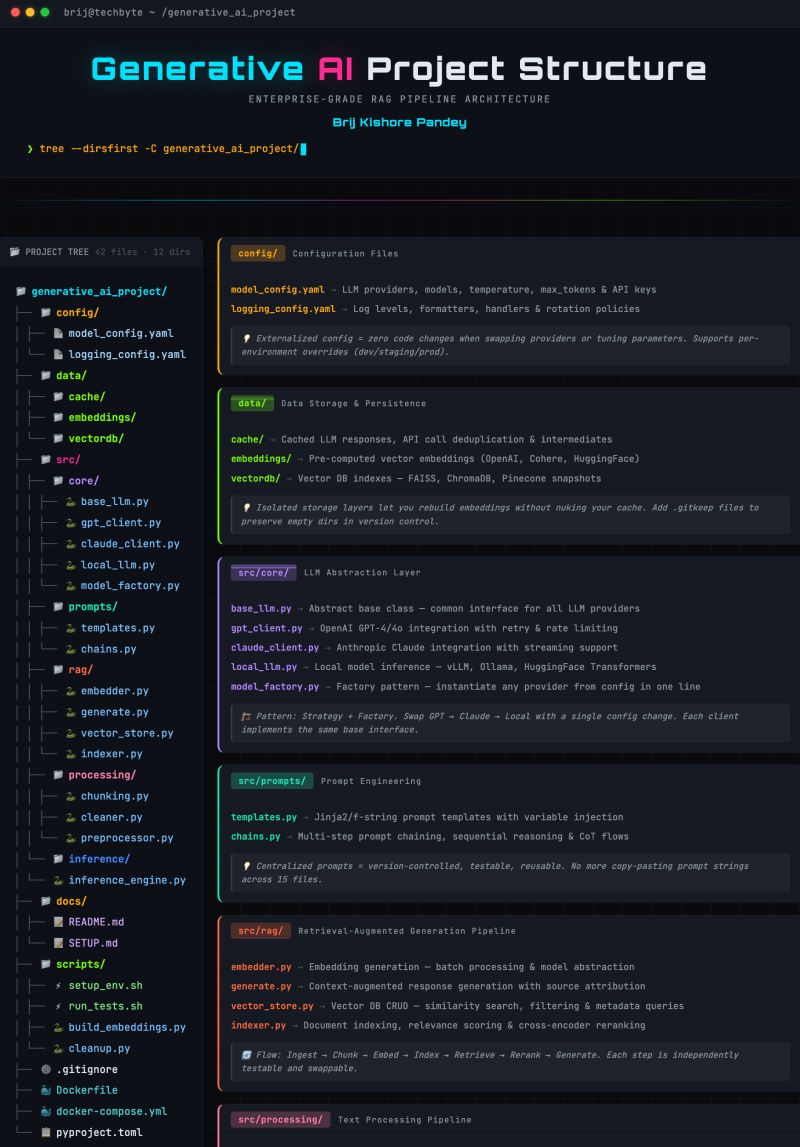
完整的项目树如下:
plaintext
generative_ai_project/
├── config/ # 配置层:外部化所有可变参数
│ ├── model_config.yaml # 大模型提供商、模型参数、API密钥配置
│ └── logging_config.yaml # 日志级别、格式、轮转策略配置
├── data/ # 数据层:隔离不同类型的持久化存储
│ ├── cache/ # LLM响应缓存、API去重、中间结果存储
│ ├── embeddings/ # 预计算的向量嵌入结果
│ └── vectordb/ # 向量数据库索引文件
├── src/ # 源码核心层:全链路分层解耦
│ ├── core/ # LLM抽象层:架构的核心灵魂
│ │ ├── base_llm.py # 抽象基类:所有LLM提供商的统一接口
│ │ ├── gpt_client.py # OpenAI GPT系列客户端实现
│ │ ├── claude_client.py # Anthropic Claude客户端实现
│ │ ├── local_llm.py # 本地模型推理客户端实现
│ │ └── model_factory.py # 工厂模式:一行代码实例化任意LLM提供商
│ ├── prompts/ # 提示词工程层:集中化、可复用管理
│ │ ├── templates.py # Jinja2提示词模板,支持变量注入
│ │ └── chains.py # 多步提示词链、思维链(CoT)流程
│ ├── rag/ # RAG流水线核心层:全环节独立解耦
│ │ ├── embedder.py # 向量嵌入生成逻辑
│ │ ├── generate.py # 上下文增强生成+来源溯源
│ │ ├── vector_store.py # 向量数据库操作、相似度检索
│ │ └── indexer.py # 文档索引、相关性评分、重排
│ ├── processing/ # 文本处理层:决定RAG效果的上限
│ │ ├── chunking.py # 文本分块策略实现
│ │ ├── cleaner.py # 文本清洗、去重、标准化
│ │ └── preprocessor.py # 文档预处理、元数据提取
│ └── inference/ # 推理引擎层:运行时执行中枢
│ └── inference_engine.py # 推理执行、异常处理、限流重试
├── docs/ # 项目文档
│ ├── README.md # 项目介绍、快速开始
│ └── SETUP.md # 环境搭建、部署指南
├── scripts/ # 自动化脚本层:告别手动操作
│ ├── setup_env.sh # 环境初始化、依赖安装
│ ├── run_tests.sh # 自动化测试执行
│ ├── build_embeddings.py # 批量构建向量嵌入、更新索引
│ └── cleanup.py # 缓存清理、过期数据删除
├── .gitignore # Git忽略规则,避免密钥/缓存泄露
├── Dockerfile # 容器化构建配置
├── docker-compose.yml # 容器编排、一键部署配置
└── pyproject.toml # 现代Python依赖管理
逐层拆解:每个目录的设计逻辑与生产级最佳实践
一、config/ 配置层:外部化一切,实现零代码修改参数调整
核心设计目标:把所有可变的配置、参数、密钥,全部从业务代码中抽离出来,实现「配置修改零代码改动」,彻底解决硬编码带来的维护灾难。
这是生产级项目和原型的第一个核心区别:黑客松项目会把 API Key、模型参数、超时时间直接硬编码在代码里,而生产级项目会把所有可变配置完全外部化。
这个目录包含两个核心配置文件:
- model_config.yaml:大模型相关的所有配置,包括 LLM 提供商、模型名称、temperature、max_tokens、API 密钥、重试次数、限流阈值等。它的核心价值是:切换大模型提供商、调整模型参数,只需要修改这个 YAML 文件,一行业务代码都不用改动。同时支持按环境(dev/staging/prod)做配置覆盖,无需修改代码就能适配不同的运行环境。
- logging_config.yaml:日志系统的完整配置,包括日志级别、输出格式、处理器、文件轮转策略、异常日志捕获规则。它解决了生产环境最核心的排查难题:统一的日志规范让你能快速定位线上问题,分级日志可以在不重启服务的情况下调整日志级别,轮转策略避免日志文件占满磁盘空间。
生产级最佳实践:
- 敏感配置(如 API Key)通过环境变量注入,不要明文写在配置文件里,避免密钥泄露;
- 配置文件按环境拆分,基础配置 + 环境覆盖配置分离,避免不同环境的配置互相污染;
- 所有配置都设置默认值,避免配置缺失导致服务崩溃。
二、data/ 数据层:物理隔离存储,避免连锁操作风险
核心设计目标:把不同类型的数据做物理隔离,解决数据操作的连锁风险,同时保障数据持久化的可管理性。
很多 RAG 项目踩过的致命坑:把缓存、嵌入、向量索引存在同一个目录里,重建嵌入的时候,不小心把整个目录清空,连带着缓存了几个月的 LLM 响应、优化了很久的向量索引全部被删除,只能从头再来。
这个目录通过三个子目录实现了完全的存储隔离:
- cache/:缓存 LLM 响应、API 调用去重结果、任务执行的中间数据。核心作用是减少重复的 API 调用,降低成本,提升响应速度;
- embeddings/:预计算的文档向量嵌入结果,和向量数据库索引分离,重建索引时无需重新计算嵌入,大幅节省时间和 API 成本;
- vectordb/:向量数据库的索引文件、持久化数据,单独管理可单独做备份、快照、版本控制。
生产级最佳实践:
- 给每个空目录添加
.gitkeep文件,纳入 Git 版本控制,保证团队协作时目录结构一致,不会出现「路径不存在」的运行错误; - 在
.gitignore中配置忽略缓存、嵌入、向量数据库的实际数据,只保留目录结构,避免把 GB 级的二进制文件提交到 Git 仓库; - 不同存储层设置不同的备份策略:向量索引每日备份,缓存无需备份,嵌入数据按需备份。
三、src/core/ LLM 抽象层:整个架构的秘密武器
核心设计目标:解耦 LLM 提供商与业务逻辑,用「策略模式 + 工厂模式」实现模型提供商的一键切换,彻底解决业务代码与特定 LLM 深度绑定的痛点。
这是这套架构最核心的设计精髓,也是绝大多数 AI 项目最终陷入维护灾难的根源。很多团队的业务代码里,直接硬编码了 OpenAI 的 API 调用逻辑,所有的参数、返回值处理都和 GPT 深度绑定,当想换成 Claude、DeepSeek 或者本地模型时,只能把整个项目推翻重写。
而这套架构通过四层设计,彻底解决了这个问题:
- base_llm.py:抽象基类,定义了所有 LLM 客户端必须实现的统一接口,包括同步对话、流式对话、向量嵌入、工具调用等核心能力。业务代码只依赖这个抽象接口,不依赖任何具体的 LLM 实现,完美符合依赖倒置原则。
- xxx_client.py:具体的 LLM 客户端实现,包括 gpt_client.py、claude_client.py、local_llm.py,每个客户端都继承自 base_llm,按照统一接口实现对应的能力,把不同 LLM 提供商的 API 差异封装在客户端内部,对上层业务代码完全透明。
- model_factory.py:工厂模式的核心实现,只需要传入配置参数,就能一行代码实例化对应的 LLM 客户端,无需在业务代码里写任何初始化逻辑。
- 配置驱动:实例化哪个 LLM 客户端,完全由 config 目录下的配置文件决定,切换模型提供商只需要修改配置,业务代码零改动。
生产级核心价值:
- 极致的扩展性:新增一个 LLM 提供商,只需要新增一个 client 文件,继承基类实现统一接口,完全不影响现有的业务代码;
- 完全的解耦:业务代码和底层 LLM 实现完全分离,底层模型怎么变,上层业务逻辑都不用改;
- 统一的能力封装:重试、限流、异常兜底、日志记录都在客户端里统一实现,不用在每个业务代码里重复写 try-except 和重试逻辑。
四、src/prompts/ 提示词工程层:集中管理,告别复制粘贴的混乱
核心设计目标:解决提示词硬编码、散落在各个文件里、重复复制粘贴的痛点,实现提示词的集中化、标准化、可复用、可测试管理。
提示词是生成式 AI 应用的核心资产,但绝大多数团队的提示词管理都是一场灾难:同一个提示词,在十几个文件里复制粘贴,想优化一个细节,要改十几个地方,还很容易遗漏;提示词和业务代码耦合在一起,想测试提示词的效果,必须跑通整个业务流程。
这个目录通过两个文件,实现了提示词的工程化管理:
- templates.py:基于 Jinja2 实现的提示词模板,支持变量注入、条件判断、循环逻辑,彻底告别字符串拼接的原始提示词写法。所有的提示词模板都集中在这里管理,版本可控,修改一个模板,所有用到的地方都自动生效。
- chains.py:实现多步提示词链、顺序推理、思维链(CoT)、多轮对话流程,把复杂的多步提示词逻辑封装成可复用的函数,业务代码只需调用一次,就能完成完整的推理流程。
生产级最佳实践:
- 每个提示词模板都写对应的单元测试,验证模板的变量注入、输出格式是否符合预期,无需跑通整个业务流程就能优化提示词;
- 模板按场景分类,比如客服、代码、RAG、数据分析,避免一个文件里堆积上百个模板;
- 提示词的版本和代码版本绑定,支持回滚,避免提示词修改后效果回退无法定位问题。
五、src/rag/ RAG 流水线核心层:全链路拆解,每个环节独立可测试
核心设计目标:把完整的 RAG 流水线拆解为独立的组件,每个组件只负责一个环节,实现「摄入→分块→嵌入→索引→检索→重排→生成」的全链路解耦,解决 RAG 优化难、测试难、定位难的痛点。
很多 RAG 项目的核心问题,就是把整个流水线写在一个 main.py 文件里:文档加载、分块、嵌入、检索、生成全耦合在一起。想优化分块策略,要动整个文件;想换向量数据库,整个流水线都要重写;RAG 效果不好,根本不知道是分块的问题、嵌入的问题,还是检索的问题。
这套架构把 RAG 流水线拆分为四个独立的组件,每个组件都有单一的职责:
- embedder.py:负责向量嵌入生成,封装了不同嵌入模型的调用逻辑,统一的输入输出格式,切换嵌入模型只需修改配置,不影响其他环节;
- vector_store.py:负责向量数据库的增删改查、相似度检索、元数据过滤、范围查询,封装了不同向量数据库的差异,上层业务代码无需关心底层用的是 Pinecone 还是 Milvus;
- indexer.py:负责文档索引构建、相关性评分、交叉编码器重排、检索结果过滤,是提升检索准确率的核心环节;
- generate.py:负责上下文增强的响应生成、来源溯源、引用标注,把检索到的上下文和用户问题整合,生成准确、可溯源的回答。
生产级核心价值:
- 独立可测试:每个组件都可以写独立的单元测试,比如单独测试分块策略的合理性、单独测试检索环节的召回率、单独测试嵌入模型的匹配度,无需跑通整个流水线;
- 独立可替换:想换向量数据库,只需要修改 vector_store.py,其他环节完全不用动;想优化重排策略,只需要修改 indexer.py,不影响嵌入和生成逻辑;
- 全链路可追溯:RAG 的每个环节都有独立的日志和输出,效果不好时可以快速定位是哪个环节出了问题,而不是盲目的调参。
六、src/processing/ 文本处理层:决定 RAG 效果上限的幕后英雄
核心设计目标:把文本清洗、分块、预处理的逻辑集中管理,解耦数据处理与检索逻辑,解决 RAG 质量的核心瓶颈。
行业里有一句被反复验证的真理:RAG 的效果上限,从来不是由大模型决定的,而是由数据处理的质量决定的。90% 的 RAG 效果差的问题,根源都在于糟糕的数据处理:分块不合理导致语义断裂、文本清洗不彻底导致噪声过多、元数据缺失导致检索无法过滤。
绝大多数团队把数据处理的逻辑随便写在了检索环节的代码里,没有专门的优化、测试、迭代,最终导致 RAG 的检索准确率始终上不去。而这套架构把文本处理单独拆分为一层,专门负责 RAG 的前置数据处理,包含三个核心文件:
- chunking.py:实现多种文本分块策略,包括固定大小分块、递归分块、语义分块、文档结构感知分块,可根据不同的文档类型选择对应的分块策略;
- cleaner.py:负责文本清洗、去重、去噪、格式标准化、乱码修复、无效内容过滤,把杂乱的原始文档转化为干净、结构化的文本;
- preprocessor.py:负责文档格式转换、元数据提取、结构解析,比如 PDF 的章节提取、表格解析、图片 OCR 结果整合。
生产级最佳实践:
- 针对不同的文档类型(PDF、Word、代码、网页)定制不同的处理流程,不要用一套规则处理所有文档;
- 为分块、清洗逻辑写专门的测试用例,验证分块的语义完整性、清洗的有效性,而不是凭感觉调整;
- 数据处理的全流程保留元数据,比如分块的所属章节、页码、文档信息,为后续的检索过滤、来源溯源提供支撑。
七、src/inference/ 推理引擎层:运行时执行的专属中枢
核心设计目标:把推理执行的逻辑和业务逻辑解耦,统一管理运行时环境、执行策略、异常处理、限流重试,保障生产环境的稳定运行。
在生产环境中,LLM 推理会遇到各种异常情况:API 限流、超时、服务不可用、返回格式异常。如果把这些异常处理写在每个业务代码里,会出现大量的重复逻辑,而且很容易遗漏兜底处理,导致线上服务崩溃。
inference_engine.py 作为统一的推理执行中枢,负责:
- 封装完整的推理执行流程,统一处理重试、熔断、降级、异常兜底,避免业务代码里重复写异常处理逻辑;
- 统一管理推理的会话状态、上下文窗口,保障长周期、多轮对话的稳定执行;
- 统一做 API 限流、并发控制,避免触发 LLM 提供商的速率限制,同时控制成本;
- 统一记录推理的全链路日志、Token 消耗、耗时统计,为成本监控、问题排查提供数据支撑。
八、scripts/ 脚本层:自动化一切,手动操作就是错误的开始
核心设计目标:把所有重复的、手动的操作,都封装为自动化脚本,实现环境搭建、测试、嵌入构建、数据清理的一键执行,避免人工操作带来的不一致、人为错误。
黑客松项目和生产级项目的另一个核心区别,就是有没有完整的自动化脚本。很多团队的项目,新人接手要花几天时间搭环境,构建嵌入要手动执行十几个命令,清理缓存要登录服务器手动删文件,不仅效率极低,还很容易出现人为操作失误。
这个目录包含了生产环境必备的四大自动化脚本:
- setup_env.sh:一键完成环境初始化、依赖安装、虚拟环境配置、环境变量设置,保证团队里每个人的开发环境完全一致,告别「我本地能跑,你那里跑不了」的问题;
- run_tests.sh:一键执行单元测试、集成测试,生成测试覆盖率报告,在提交代码、部署之前自动执行,保障代码质量;
- build_embeddings.py:批量处理文档、构建向量嵌入、更新向量数据库索引,支持增量更新、全量重建,无需手动执行分块、嵌入、索引的每一步;
- cleanup.py:一键清理过期缓存、临时文件、无效嵌入数据、过期日志,释放存储空间,避免磁盘空间占满导致的服务故障。
生产级最佳实践:
- 任何需要手动执行超过 2 次的操作,都应该写成自动化脚本;
- 所有脚本都要加参数校验、异常处理、日志输出,出现问题能快速定位;
- 脚本纳入 Git 版本控制,保证团队所有人用的是同一套自动化流程,操作完全一致。
工程化基建:生产级项目的必备底座
除了核心的源码目录,这套架构还包含了完整的工程化文件,这些是黑客松原型永远不会考虑,但生产级项目必不可少的底座:
- pyproject.toml:现代 Python 项目的依赖管理标准,替代老旧的 requirements.txt,支持依赖版本锁定、开发依赖与生产依赖分离、虚拟环境管理,彻底解决依赖地狱,保证团队协作、不同环境的依赖一致性。
- Dockerfile + docker-compose.yml:容器化部署配置,实现「一次构建,到处运行」,彻底解决环境差异带来的部署问题。同时支持生产环境的容器编排、扩缩容、高可用部署,是企业级落地的必备能力。
- .gitignore:规范的 Git 忽略配置,避免把 API 密钥、缓存文件、向量数据库、环境变量、虚拟环境等不该提交的内容提交到代码仓库,从根源上避免密钥泄露、仓库体积过大的问题。
- docs/:完整的项目文档,包含 README.md(项目介绍、快速开始)、SETUP.md(环境搭建、部署指南),保障项目的可维护性、可交接性,新人接手项目能快速上手,无需到处问人。
这套架构的四大核心设计原则
这套生产级项目结构,本质上是把软件工程的最佳实践,和生成式 AI、RAG 的技术特性做了完美的结合,核心遵循四大设计原则,这也是它能解决绝大多数生产级落地痛点的根源:
1. 关注点分离(Separation of Concerns)
每个目录、每个文件都只有一个单一的职责,配置只负责配置,抽象只负责接口,数据处理只负责数据,业务逻辑只负责业务。彻底告别一个文件里既写了提示词,又写了 LLM 调用,还写了数据处理的面条代码。
2. 开闭原则(Open/Closed Principle)
对扩展开放,对修改关闭。新增一个 LLM 提供商,只需要新增一个 client 文件,不用修改现有的业务代码;新增一种分块策略,只需要修改 processing 的代码,不用动检索和生成的逻辑。系统可以持续扩展,而不用不断修改已有的稳定代码。
3. 依赖倒置原则(Dependency Inversion Principle)
业务代码只依赖抽象,不依赖具体实现。比如业务代码只依赖 base_llm.py 的抽象接口,不依赖具体的 GPT 客户端、Claude 客户端,底层的实现怎么变,上层的业务代码都不用改,彻底解耦了业务逻辑和底层依赖。
4. 可测试性原则
每个组件都是独立的、可单独测试的。你可以给 LLM 抽象层写单元测试,给提示词模板写单元测试,给分块逻辑写单元测试,给检索环节写集成测试,而不是必须跑通整个 pipeline 才能验证效果。这是生产级系统能持续迭代、稳定运行的核心保障。
结尾:生成式 AI 的竞争,本质是工程化的竞争
生成式 AI 的行业发展到今天,早已从「谁能跑通一个原型」,变成了「谁能把 AI 系统稳定、低成本、可扩展地落地到生产环境」。
很多人以为,生成式 AI 项目的核心是大模型,是向量数据库,是 RAG 的算法。但现实是,90% 的 AI 项目最终失败,不是因为模型选的不好,而是因为糟糕的架构设计,让项目在迭代了几个月后,就变成了无法维护、无法扩展、无法排查问题的面条代码。
黑客松式的开发,能让你快速拿到结果,但只有工程化的架构设计,能让你走得更远。这套企业级生成式 AI 项目结构,本质上是把软件工程的最佳实践,和生成式 AI 的技术特性做了完美的融合,从一开始就帮你避开了 90% 的生产级落地陷阱。
记住:原型和生产级系统的区别,从来不是你选了什么模型,而是你如何组织模型之外的一切。 好的架构,不会限制你的创新,反而会让你把更多的精力放在业务逻辑、效果优化上,而不是陷入无休止的代码维护、bug 修复里。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献104条内容
已为社区贡献104条内容

所有评论(0)