DeepSeek V3.2 正式版:强化 Agent 能力,融入思考推理
DeepSeek V3.2正式版推出两大模型:标准版(DeepSeek-V3.2)和增强版(DeepSeek-V3.2-Speciale)。标准版在推理能力上达到GPT-5水平,优化了输出长度,适合日常应用;增强版融合数学证明能力,在国际竞赛中表现优异。该版本首次实现思考模式与工具调用的深度融合,通过创新的训练数据合成方法提升了Agent能力。模型已在HuggingFace和ModelScope开
DeepSeek V3.2 正式版:强化 Agent 能力,融入思考推理
概述
DeepSeek V3.2 是 DeepSeek 系列模型的最新正式版本,在推理能力和 Agent 能力方面实现了重大突破。该版本同时发布了两个模型:DeepSeek-V3.2(标准版)和 DeepSeek-V3.2-Speciale(增强版),为不同应用场景提供了差异化的解决方案。
DeepSeek-V3.2-Exp 实验版本经过广泛的对比测试验证,未发现其在任何特定场景中显著差于 V3.1-Terminus,充分验证了 DSA 稀疏注意力机制的有效性。
核心特性
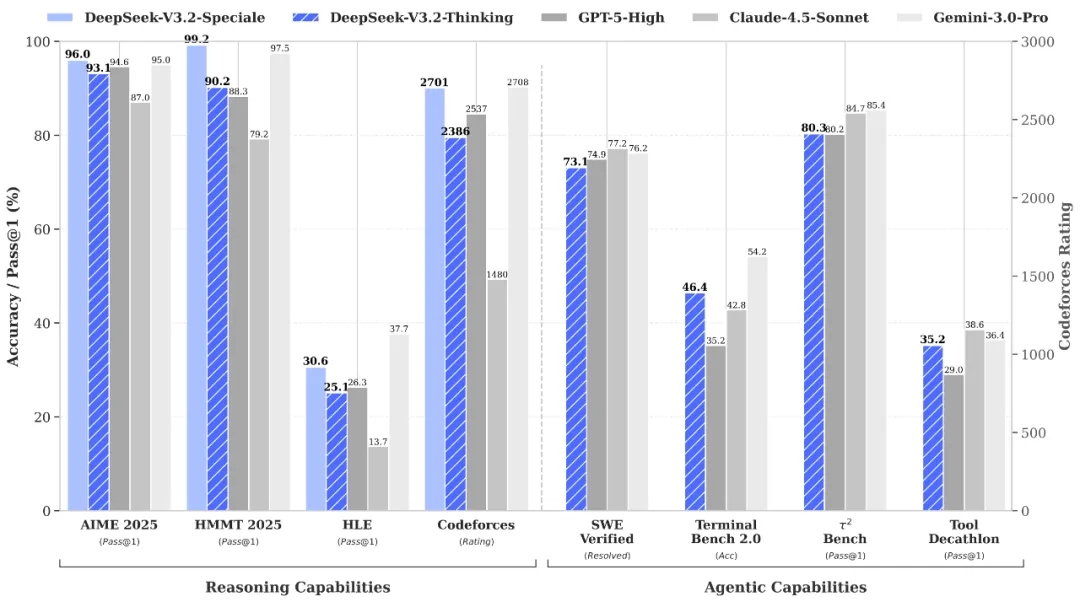
推理能力全球领先
DeepSeek-V3.2 标准版
定位:平衡推理能力与输出长度,适用于日常问答场景和通用 Agent 任务场景。
技术优势:
- 在公开的推理类 Benchmark 测试中达到 GPT-5 水平
- 性能仅略低于 Gemini-3.0-Pro
- 相比 Kimi-K2-Thinking,输出长度大幅降低
- 显著减少计算开销与用户等待时间
- 更适合实际生产环境部署
DeepSeek-V3.2-Speciale 增强版
定位:将开源模型的推理能力推向极致,探索模型能力的边界。
技术架构:
- 基于 DeepSeek-V3.2 的长思考增强版本
- 融合 DeepSeek-Math-V2 的定理证明能力
- 具备出色的指令跟随能力
- 支持严谨的数学证明与逻辑验证
竞赛成绩:
| 竞赛名称 | 成绩 | 备注 |
|---|---|---|
| IMO 2025(国际数学奥林匹克) | 🥇 金牌 | - |
| CMO 2025(中国数学奥林匹克) | 🥇 金牌 | - |
| ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛) | 🥇 金牌 | 达到人类选手第二名水平 |
| IOI 2025(国际信息学奥林匹克) | 🥇 金牌 | 达到人类选手第十名水平 |
使用建议:在高度复杂任务上,Speciale 模型表现大幅优于标准版本,但消耗的 Tokens 也显著更多。该版本仅供研究使用,不支持工具调用,暂未针对日常对话与写作任务进行专项优化。
思考融入工具调用
突破性创新
DeepSeek-V3.2 是首个将思考模式与工具使用深度融合的模型,打破了过往版本在思考模式下无法调用工具的局限。该模型同时支持思考模式与非思考模式的工具调用,为复杂任务处理提供了更强大的能力支撑。
推理能力全球领先
DeepSeek-V3.2 的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用 Agent 任务场景。在公开的推理类 Benchmark 测试中,DeepSeek-V3.2 达到了 GPT-5 的水平,仅略低于 Gemini-3.0-Pro;相比 Kimi-K2-Thinking,V3.2 的输出长度大幅降低,显著减少了计算开销与用户等待时间。
DeepSeek-V3.2-Speciale 的目标是将开源模型的推理能力推向极致,探索模型能力的边界。V3.2-Speciale 是 DeepSeek-V3.2 的长思考增强版,同时结合了 DeepSeek-Math-V2 的定理证明能力。该模型具备出色的指令跟随、严谨的数学证明与逻辑验证能力,在主流推理基准测试上的性能表现媲美 Gemini-3.0-Pro(见下表)。更令人瞩目的是,V3.2-Speciale 模型成功斩获 IMO 2025(国际数学奥林匹克)、CMO 2025(中国数学奥林匹克)、ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛)及 IOI 2025(国际信息学奥林匹克)金牌。其中,ICPC 与 IOI 成绩分别达到了人类选手第二名与第十名的水平。
Tips:在高度复杂任务上,Speciale 模型大幅优于标准版本,但消耗的 Tokens 也显著更多,成本更高。目前,DeepSeek-V3.2-Speciale 仅供研究使用,不支持工具调用,暂未针对日常对话与写作任务进行专项优化。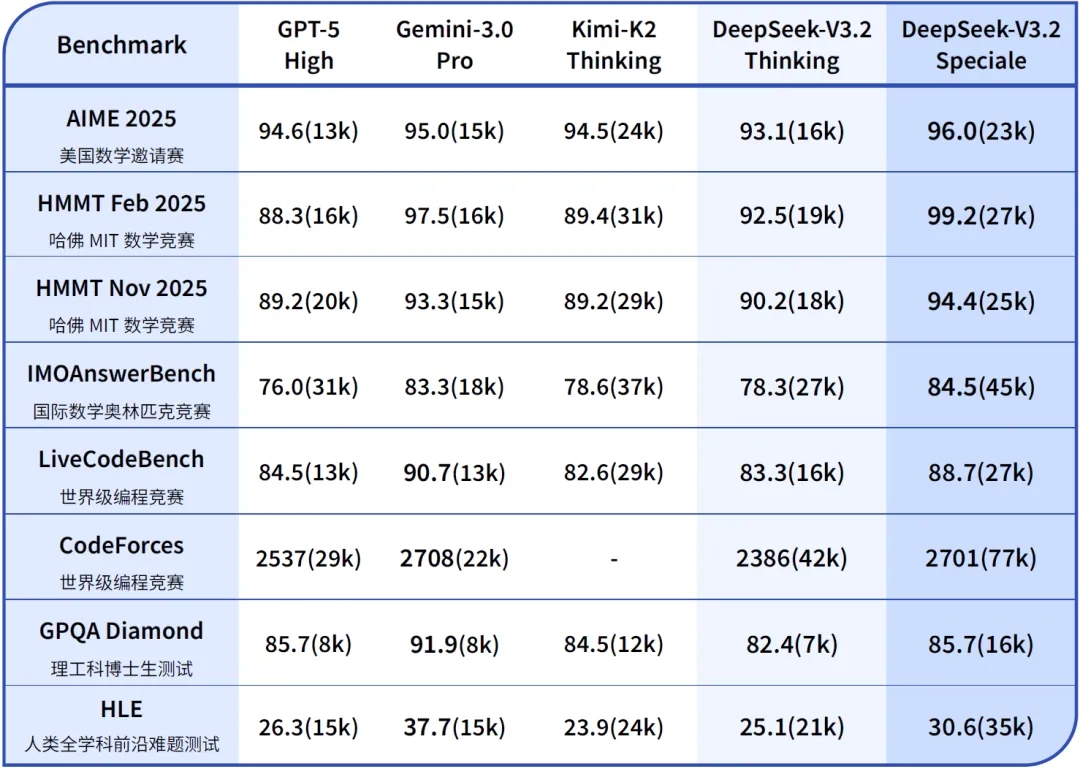
大规模 Agent 训练数据合成
DeepSeek 提出了一种创新的大规模 Agent 训练数据合成方法,核心技术特点:
| 特性 | 规模 |
|---|---|
| 强化学习任务类型 | 「难解答,易验证」 |
| 环境覆盖 | 1800+ |
| 复杂指令数量 | 85,000+ |
该方法大幅提高了模型的泛化能力,使其能够适应多样化的实际应用场景。
智能体评测表现
DeepSeek-V3.2 在智能体评测中达到了当前开源模型的最高水平,大幅缩小了开源模型与闭源模型的差距。值得注意的是,V3.2 并没有针对这些测试集的工具进行特殊训练,因此在真实应用场景中能够展现出较强的泛化性。
模型对比
推理能力对比
| 模型 | 推理能力 | 输出长度 | 适用场景 |
|---|---|---|---|
| DeepSeek-V3.2 | GPT-5 水平 | 优化 | 日常问答、通用 Agent |
| DeepSeek-V3.2-Speciale | Gemini-3.0-Pro 水平 | 较长 | 复杂推理、数学证明 |
| Kimi-K2-Thinking | 优秀 | 较长 | 深度思考场景 |
功能支持对比
| 功能 | V3.2 | V3.2-Speciale |
|---|---|---|
| 思考模式 | ✅ | ✅ |
| 工具调用 | ✅ | ❌ |
| 日常对话 | ✅ | ⚠️ 未优化 |
| 数学证明 | ✅ | ✅ 增强 |
| 最大输出长度 | 默认 | 128K |
思考融入工具调用
不同于过往版本在思考模式下无法调用工具的局限,DeepSeek-V3.2 是我们推出的首个将思考融入工具使用的模型,并且同时支持思考模式与非思考模式的工具调用。我们提出了一种大规模 Agent 训练数据合成方法,构造了大量「难解答,易验证」的强化学习任务(1800+ 环境,85,000+ 复杂指令),大幅提高了模型的泛化能力。
表2:DeepSeek-V3.2 与其他模型在各类智能体工具调用评测集上的得分
如上表所示,DeepSeek-V3.2 模型在智能体评测中达到了当前开源模型的最高水平,大幅缩小了开源模型与闭源模型的差距。值得说明的是,V3.2 并没有针对这些测试集的工具进行特殊训练,所以我们相信,V3.2 在真实应用场景中能够展现出较强的泛化性。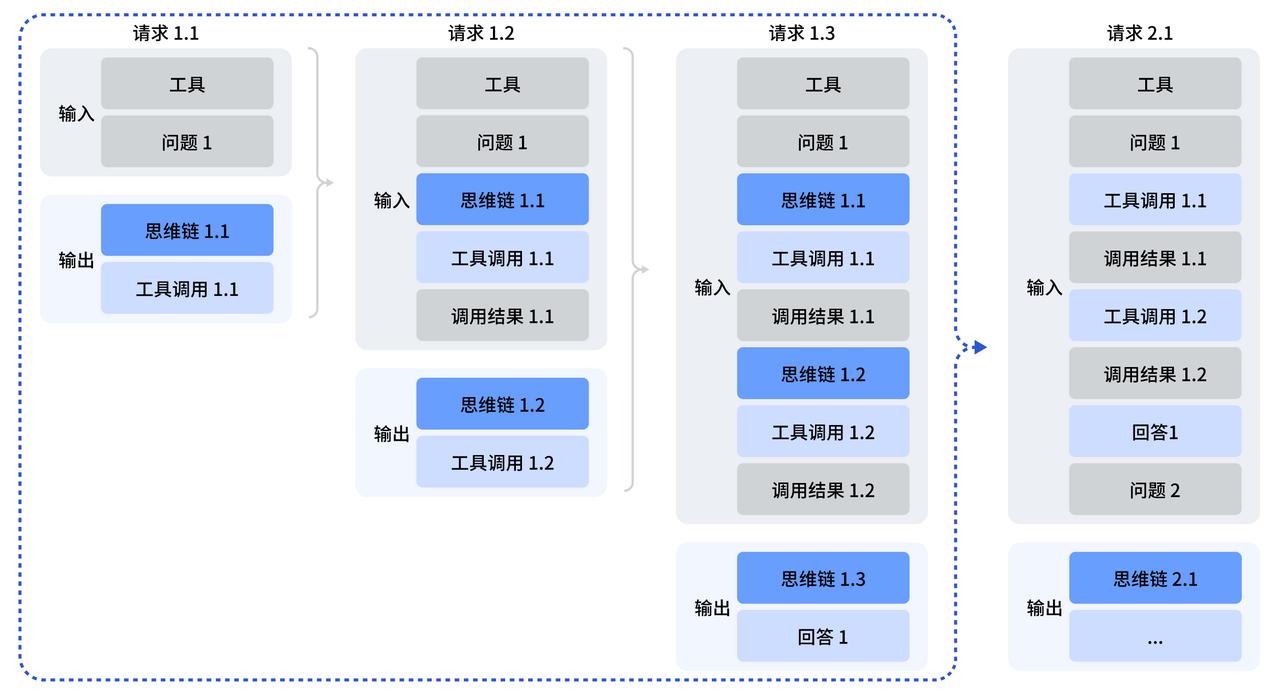
开源资源
DeepSeek-V3.2
| 平台 | 地址 |
|---|---|
| HuggingFace | https://huggingface.co/deepseek-ai/DeepSeek-V3.2 |
| ModelScope | https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2 |
DeepSeek-V3.2-Speciale
| 平台 | 地址 |
|---|---|
| HuggingFace | https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale |
| ModelScope | https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Speciale |
API 接入指南
标准版 API
DeepSeek-V3.2 是当前正式提供服务的模型,官方网页、APP、API 模型均已升级为正式版本,使用方式保持不变。
Speciale 版本 API
为支持社区评测与研究,DeepSeek 提供了 V3.2-Speciale 的临时 API 服务:
# Python 示例代码
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215"
)
response = client.chat.completions.create(
model="deepseek-v3.2-speciale",
messages=[
{"role": "user", "content": "请证明费马大定理"}
]
)
API 限制说明:
| 项目 | 说明 |
|---|---|
| 价格 | 与标准版相同 |
| 支持功能 | 仅思考模式下的对话功能 |
| 工具调用 | 不支持 |
| 最大输出长度 | 128K |
| 服务截止时间 | 北京时间 2025-12-15 23:59 |
思考模式工具调用详解
工作原理
DeepSeek-V3.2 支持在思考模式下进行多轮「思考 + 工具调用」,通过迭代推理最终给出更详尽准确的回答。
API 请求流程
┌─────────────────────────────────────────────────────────┐
│ 问题处理流程 │
├─────────────────────────────────────────────────────────┤
│ │
│ 问题 1 处理: │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 请求1.1 │───▶│ 请求1.2 │───▶│ 请求1.3 │──▶ 最终答案 │
│ │思考+调用│ │思考+调用│ │思考+调用│ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ │ │ │ │
│ └──────────────┴──────────────┘ │
│ 回传 reasoning_content │
│ │
│ 问题 2 开始: │
│ ┌─────────┐ │
│ │ 请求2.1 │──▶ 删除之前思维链,保留其他内容 │
│ └─────────┘ │
│ │
└─────────────────────────────────────────────────────────┘
关键实现要点
-
思维链回传:在多轮对话过程中,需要将
reasoning_content(思维链内容)回传给 API,使模型能够继续深度思考 -
思维链清理:处理新的用户问题时,需要删除之前的思维链内容,仅保留其他上下文信息
-
上下文管理:合理管理对话上下文,确保模型能够准确理解用户意图
代码示例
# 思考模式工具调用示例
messages = [{"role": "user", "content": "请帮我查询北京明天的天气"}]
# 第一轮请求
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=messages,
tools=tools,
stream=False
)
# 处理响应并继续对话
if response.choices[0].message.tool_calls:
# 执行工具调用
tool_result = execute_tool(response.choices[0].message.tool_calls)
# 回传思维链和工具结果
messages.append({
"role": "assistant",
"content": response.choices[0].message.content,
"reasoning_content": response.choices[0].message.reasoning_content
})
messages.append({
"role": "tool",
"content": str(tool_result)
})
更多资源
详细的 API 使用方法请参考官方文档:
- API 文档:https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
- 技术报告:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2/resolve/master/assets/paper.pdf
应用场景
DeepSeek-V3.2 适用场景
| 场景类型 | 具体应用 |
|---|---|
| 日常问答 | 智能客服、知识问答、信息检索 |
| Agent 任务 | 自动化流程、任务编排、多工具协同 |
| 代码开发 | 代码生成、代码审查、Bug 修复 |
| 数据分析 | 数据处理、报告生成、可视化建议 |
DeepSeek-V3.2-Speciale 适用场景
| 场景类型 | 具体应用 |
|---|---|
| 数学研究 | 定理证明、数学建模、算法验证 |
| 科研工作 | 论文写作、文献分析、实验设计 |
| 复杂推理 | 逻辑分析、决策支持、风险评估 |
| 竞赛训练 | 数学竞赛、编程竞赛、逻辑推理竞赛 |
总结
DeepSeek-V3.2 的发布标志着开源大模型在推理能力和 Agent 能力上的重要里程碑:
| 维度 | 成就 |
|---|---|
| 🧠 推理能力 | 达到 GPT-5 水平,媲美 Gemini-3.0-Pro |
| 🤖 Agent 能力 | 开源模型最高水平,支持思考+工具调用融合 |
| 🏆 竞赛表现 | IMO/CMO/ICPC/IOI 四项国际金牌 |
| 💰 成本效益 | 输出长度优化,显著降低计算开销 |
| 🔓 开源生态 | HuggingFace 和 ModelScope 双平台开源 |
| 🛠️ 工具支持 | 思考模式下完整支持工具调用 |
DeepSeek-V3.2 为开发者和研究人员提供了强大的 AI 能力支撑,是构建智能应用和研究探索的理想选择。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)