【claude+weelinking中转服务】Anthropic重磅升级skill-creator:告别“草台班子“时代
2026年3月,Anthropic对官方skill-creator进行重磅升级,将软件工程中的测试、基准评估和迭代机制引入Skill创作流程,全程无需编写代码。升级后的skill-creator支持评估机制(evals)自动验证Skill质量、多智能体并行测试、A/B对比盲测、触发器精准度优化等功能,让普通领域专家也能创建经过严格验证的高质量Skill。本文详解skill-creator新特性、两

作者:小枫
发布时间:2026年3月4日
适合人群:Claude用户、AI Agent开发者、Skill创作者、提效工具爱好者
📌 摘要
2026年3月,Anthropic对官方skill-creator进行重磅升级,将软件工程中的测试、基准评估和迭代机制引入Skill创作流程,全程无需编写代码。升级后的skill-creator支持评估机制(evals)自动验证Skill质量、多智能体并行测试、A/B对比盲测、触发器精准度优化等功能,让普通领域专家也能创建经过严格验证的高质量Skill。本文详解skill-creator新特性、两类Skill的区别、评估与基准测试用法,以及多智能体架构的实战应用。国内用户可通过weelinking中转服务稳定访问Claude,快速上手Skill创作。
📋 目录
- 一、为什么skill-creator需要升级?
- 二、如何安装和使用skill-creator
- 三、理解两类不同的Skill
- 四、用评估机制测试并改进Skill
- 五、多智能体支持与触发器优化
- 六、下一步:Skill的未来走向
- 七、推荐阅读
🔴 🔴 🔴 国内丝滑使用 Claude? 👉 weelinking 大模型中转服务,全系模型支持 👈
一、为什么skill-creator需要升级?
随着Agent技术的深入应用,编写Skill成为当下热门的实践。Anthropic在去年的实践中发现,大多数Skill的作者是垂直领域的专家,而非工程师。他们清楚自己的工作流,却缺乏工程化工具来验证这些Skill是否依然适配新模型、能否在正确的时机触发,或者在修改之后是否真有改善。
过去创建Skill更像是一种"草台班子"式的操作——写好了觉得能用就行,缺少系统性的测试和验证手段。这次升级的核心目标,就是将软件开发中严谨的测试、基准评估和迭代机制引入Skill创作过程中,且全过程不需要作者编写任何代码。
所有skill-creator的更新现已在Claude.ai和Cowork中上线,用户只需向Claude提出使用skill-creator即可开始。
二、如何安装和使用skill-creator
Claude Code用户可以安装官方插件或从代码库获取相关资源。安装非常简单:
/plugin install {plugin-name}@claude-plugin-directory
或者通过交互方式安装:
/plugin > Discover
安装完成后,就可以开始愉快地创建Skill了。
三、理解两类不同的Skill
在探讨测试工具之前,需要厘清Skill的两种主要类型,因为它们需要测试的原因各不相同。
3.1 能力提升型Skill
这类Skill主要帮助Claude完成基础模型做不到或表现不够稳定的任务,例如特定的文档生成模式。
随着底层模型能力的进化,这类Skill可能会变得不再必要,因此需要通过测试来判断模型是否已经掌握了这些能力。
3.2 偏好编码型Skill
这类任务Claude本身具备完成各环节的能力,但需要Skill将其按照团队特定流程进行编排,例如:
- 按既定标准审核NDA
- 结合多个MCP的数据起草周报
这类Skill的生命周期较长,测试的核心在于验证其是否忠实于你的实际工作流。
无论属于哪一类,引入测试都能让看起来有效的Skill,变成真正被验证有效的Skill。
四、用评估机制测试并改进Skill
更新后的skill-creator能够帮助用户建立评估机制(evals)。用户只需设定测试提示词,并描述预期的理想结果,skill-creator就会验证该Skill是否达到标准。
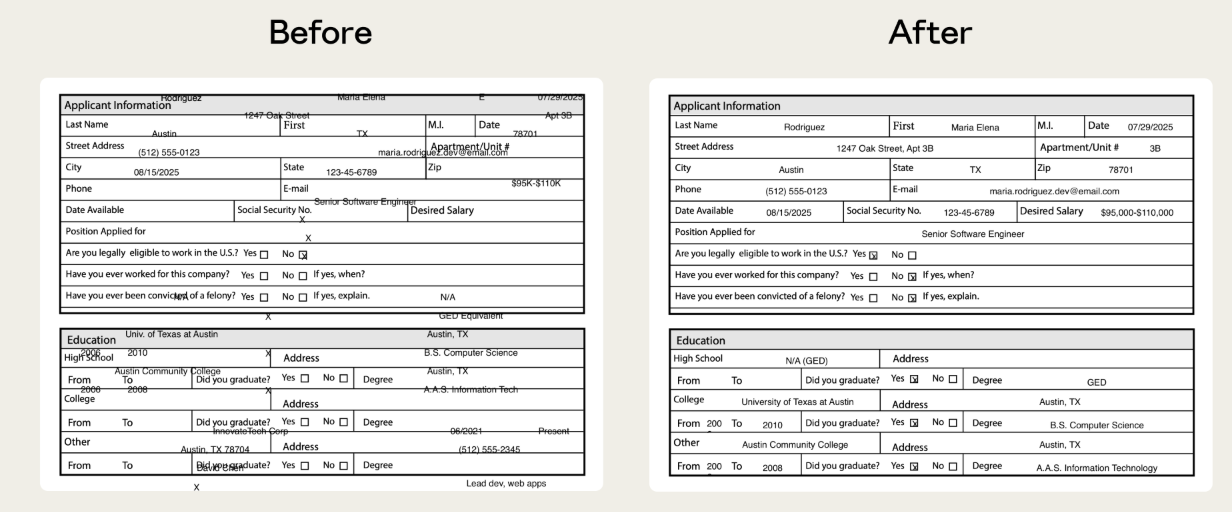
4.1 实际案例:PDF文本定位
以处理非填表类PDF为例,原先Claude难以在没有预设字段的情况下精准放置文本。Anthropic团队正是通过评估机制锁定了这个缺陷,随后发布了修复方案,改为通过提取文本坐标来锚定位置。
4.2 评估机制解决的两个核心问题
问题一:捕捉质量衰退
当模型或底层基础设施发生变化时,上个月表现良好的Skill今天可能会出现异常。针对新模型运行测试,可以在影响实际工作前提供预警信号。
问题二:了解模型进展
这主要针对能力提升型Skill。如果基础模型在不加载Skill的情况下也能通过测试,说明该Skill的技术方法可能已经被吸收进了模型的默认行为中。这不代表Skill坏了,只是不再被需要。
4.3 基准评估模式
除评估机制外,Anthropic还加入了基准评估模式。这是一种标准化评估流程,适合在模型更新或Skill迭代后运行,它会系统追踪:
| 追踪指标 | 说明 |
|---|---|
| 测试通过率 | 验证Skill功能是否正常 |
| 运行耗时 | 监控性能变化 |
| Token用量 | 控制成本开销 |
这些测试和结果数据归用户所有,支持本地存储,也可接入仪表盘或持续集成(CI)系统。
五、多智能体支持与触发器优化
5.1 多智能体并行测试
顺序运行测试通常较慢,且上下文的不断积累容易在测试用例间产生干扰。为提升效率与准确性,skill-creator现已支持多智能体机制,可以启动独立的智能体并行运行测试。
每个智能体都在一个干净的上下文中工作,拥有独立的Token和时间统计。
5.2 A/B对比盲测
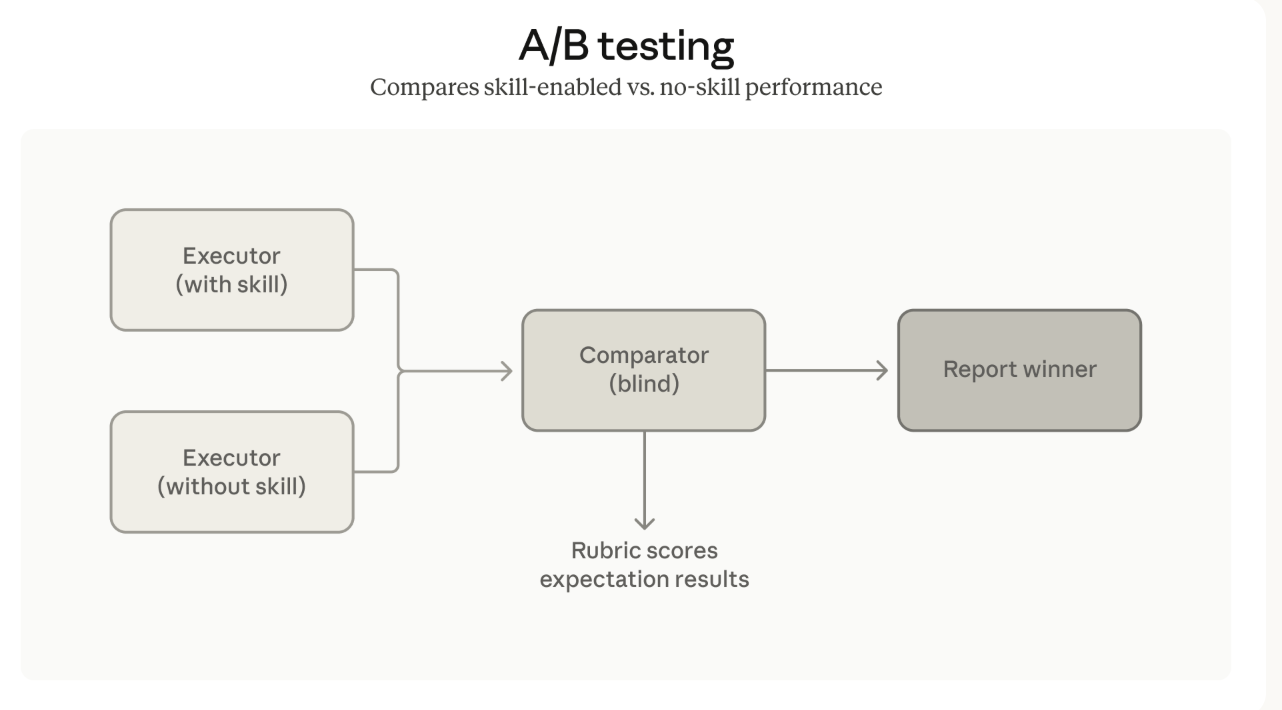
同时新增的还有对比智能体,专门用于进行A/B测试。对比智能体可以:
- 在不知道对照组信息的情况下盲测不同版本的Skill
- 对比使用和不使用Skill的输出差异
从而直观判断某项修改是否真的带来了提升。
5.3 触发器精准度优化
除了输出质量,Skill是否在正确的时间触发同样关键。随着用户持有的Skill数量增加,描述的精准度变得至关重要:
- 描述太宽泛 → 误触发
- 描述太狭窄 → 永远不触发
skill-creator现在会比对现有的描述和示例提示词,并提供修改建议。在Anthropic的内部测试中,这项功能优化了6个公开文档创建Skill中的5个,有效降低了误报和漏报率。
六、下一步:Skill的未来走向
随着模型的持续改进,Skill和规范说明之间的界限将会逐渐模糊。
目前的SKILL.md文件本质上还是一个执行方案,详细指示Claude应该如何做某事。在未来,用户可能只需要用自然语言描述Skill应该做什么,模型就能自行解决具体的实现过程。
今天发布的评估框架,正是向这一方向过渡的步骤之一。
个人建议:与其不断折腾龙虾、养龙虾OpenClaw,不如把怎么创建Skill学好。这是一个对日常工作非常有用的大杀器,掌握Skill创作能力将在Agent时代获得巨大的效率优势。
📖 推荐阅读
如果这篇对你有帮助,以下文章你也会喜欢:
- Claude Code 省 Token 终极指南:从烧钱到精打细算 — 接了
weelinking按量付费,做到终极省钱 - CC Switch 完全安装指南:5 分钟配置好 Claude Code 的多 API 切换神器,全程接入 weelinking — 可以丝滑无缝切换多平台的API
- 把 Claude Code 用成工程工具:8 条黄金法则与一套可复用工作流 — CC Switch 配置好之后,这 8 条法则能让你的 Claude Code 效率再翻一倍
🔴 🔴 🔴 国内丝滑使用 Claude? 👉 本文全系使用 weelinking,全系模型支持 👈

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)