一文带大家理解各种AI大模型收费指标tokens到底是什么东东
摘要:Token是大语言模型处理文本的最小单位,作为计费基础,输入收费0.6元/百万tokens,输出3.6元/百万tokens。Token本质是文本的数字编码,通过分词器切分,不同语言处理方式各异。其核心技术包括分词器、嵌入层、上下文窗口和推理成本计算。Token数量直接影响模型的理解能力、计算成本和文本处理长度,是模型运行的核心机制。完整流程涵盖文本输入到计费的各个环节,决定了模型的使用效率和

Token收费举例
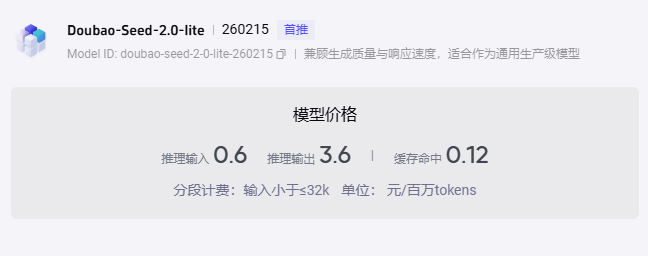
大家在使用各个模型的过程中,一定会关注到,各个模型都是按照使用的tokens进行收费的,例如:
1. 推理输入:0.6 元 / 百万 tokens
-
含义:你向大模型提问、上传文档、粘贴上下文等 “给模型看的内容”,每消耗 100 万个 tokens,收费 0.6 元。
-
通俗例子:你发了一段 1000 字的文章给模型,大约 ≈ 1300 tokens(按 1 字≈1.3 token 粗算)。费用 ≈ 0.6 元 / 1,000,000 × 1,300 ≈ 0.00078 元,几乎可以忽略不计。
2. 推理输出:3.6 元 / 百万 tokens
-
含义:模型生成的回答、代码、文案等 “给你的内容”,每消耗 100 万个 tokens,收费 3.6 元。
-
通俗例子:模型给你写了一篇 1000 字的回答,同样约 1300 tokens。费用 ≈ 3.6 / 1,000,000 × 1,300 ≈ 0.00468 元,比输入贵一些。
Token 到底是什么?
Token 是大语言模型(LLM)处理文本的最小单位,可以理解为模型 “读” 和 “写” 的 “单词 / 字符 / 子词”。它不是一个单一的技术点,而是一套贯穿模型训练、推理和部署的核心机制。
1. 本质:文本的 “数字化编码”
- Token 是模型将人类可读的文本(中文、英文、数字、符号等)切分并编码后得到的数字 ID。
- 模型不直接处理 “汉字” 或 “字母”,而是处理这些数字 ID。
- 切分规则由模型的 ** 分词器(Tokenizer)** 决定,不同模型(如 GPT、Doubao、Claude)的分词规则略有差异。
2. 常见的 Token 类型
- 英文 / 拉丁语言:通常是子词(Subword),例如
unhappiness会被切分为un,happiness。 - 中文:通常是单字或双字词,例如 “我爱中国” 可能被切分为
我,爱,中,国或我爱,中国。 - 特殊符号:空格、标点、换行符等也会被编码为独立的 Token。
3. 一个直观的例子
以 Doubao/OpenAI 的分词器为例:
- 输入文本:
Hello, 我是豆包,一个AI助手。 - 分词结果(Token):
Hello,,,我,是,豆,包,,,一,个,AI,助,手,。 - 每个 Token 对应一个唯一的数字 ID,例如
Hello→15496,我→1770。
Token 对应的核心技术点
1. 分词器(Tokenizer):文本到 Token 的桥梁
- 技术角色:负责将输入文本切分为 Token,并将 Token 映射为模型可处理的数字 ID。
- 关键技术:
- BPE(Byte Pair Encoding):最主流的分词算法,通过统计语料中高频出现的字符组合,逐步合并为子词,平衡词汇表大小和分词效率。
- Unigram 模型:从一个大的初始词汇表中,通过概率模型逐步移除低频 Token,优化分词效果。
- 字节级分词:直接对 UTF-8 字节进行编码,避免处理生僻字或 emoji 时出现 “未知 Token” 的问题。
- 技术意义:分词器的质量直接影响模型对文本的理解能力。好的分词器能准确切分专业术语、方言词汇,避免语义丢失。
2. 嵌入层(Embedding Layer):Token 到向量的转换
- 技术角色:将每个 Token 的数字 ID 转换为一个高维向量(Embedding),这个向量包含了 Token 的语义信息。
- 关键技术:
- 词嵌入(Word Embedding):通过训练学习到的向量,例如
猫和狗的向量在空间中距离较近,因为它们都是动物。 - 位置编码(Positional Encoding):Transformer 模型本身不具备时序感知能力,位置编码会为每个 Token 添加位置信息,让模型知道 “我” 在 “爱” 之前。
- 词嵌入(Word Embedding):通过训练学习到的向量,例如
- 技术意义:嵌入层是模型理解文本语义的第一步,高质量的嵌入能让模型更好地捕捉文本中的上下文关系。
3. 上下文窗口(Context Window):Token 的 “记忆容量”
- 技术角色:模型在一次推理中能处理的最大 Token 数量,包括输入和输出。
- 关键技术:
- 注意力机制(Attention Mechanism):Transformer 模型的核心,通过计算 Token 之间的注意力权重,让模型关注文本中的关键信息。注意力机制的计算复杂度是 O (n²),n 是 Token 数量,因此上下文窗口越大,计算成本越高。
- 滑动窗口(Sliding Window):为了突破上下文窗口的限制,一些模型会采用滑动窗口技术,只关注当前窗口内的 Token。
- KV 缓存(KV Cache):在多轮对话中,模型会缓存之前的 Key 和 Value 向量,避免重复计算,提高推理效率。
- 技术意义:上下文窗口决定了模型能 “记住” 多少信息。256k 的上下文窗口意味着模型可以处理长达 19 万字的文本,这对于长文档理解、代码生成等场景至关重要。
4. 推理成本(Cost):Token 的 “经济价值”
- 技术角色:Token 是计算和存储成本的基本单位。
- 关键技术:
- 计算成本:每个 Token 都需要经过多层 Transformer 块的计算,Token 数量越多,计算时间越长,GPU 资源消耗越大。
- 存储成本:KV 缓存需要存储之前的 Key 和 Value 向量,Token 数量越多,占用的显存越大。
- 缓存命中(Cache Hit):如果输入 Token 序列与之前的请求高度相似,模型可以直接复用之前的计算结果,大幅降低成本。
- 技术意义:Token 数量直接决定了模型的使用成本。优化 Token 数量(例如使用更高效的分词器、压缩文本)是降低大模型部署成本的关键。
Token 技术栈的完整流程
- 文本输入:用户输入
Hello, 我是豆包。 - 分词:Tokenizer 将文本切分为
Hello,,,我,是,豆,包,。,并映射为数字 ID。 - 嵌入:嵌入层将数字 ID 转换为高维向量,并添加位置编码。
- 推理:Transformer 模型通过注意力机制处理这些向量,生成新的 Token 序列。
- 解码:Tokenizer 将生成的 Token 序列转换回人类可读的文本。
- 计费:根据输入和输出的 Token 数量,计算使用成本。
总结:Token 为什么重要?
- 它是模型的 “语言”:模型通过 Token 来理解和生成文本。
- 它是成本的 “标尺”:Token 数量直接决定了模型的计算和存储成本。
- 它是能力的 “边界”:上下文窗口的大小决定了模型能处理的文本长度和复杂程度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)