FastApi之Pydantic V2使用
Pydantic 是一个基于 Python 类型提示的开源数据验证库,专注于提供简单而强大的数据验证和设置管理功能。类型安全:利用 Python 的类型提示系统,提供编译时类型检查自动数据验证:自动验证输入数据的类型和约束数据转换:自动将输入数据转换为指定的类型错误处理:提供详细的错误信息,便于调试序列化:支持模型与 JSON 等格式的相互转换id: intname: stremail: str
1. Pydantic 基础知识
1.1 什么是 Pydantic
Pydantic 是一个基于 Python 类型提示的开源数据验证库,专注于提供简单而强大的数据验证和设置管理功能。它的核心价值在于:
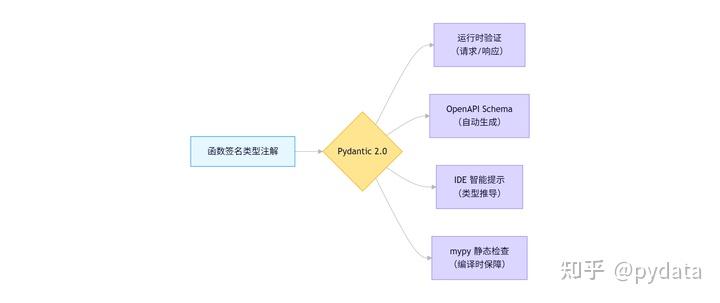
- 类型安全:利用 Python 的类型提示系统,提供编译时类型检查
- 自动数据验证:自动验证输入数据的类型和约束
- 数据转换:自动将输入数据转换为指定的类型
- 错误处理:提供详细的错误信息,便于调试
- 序列化:支持模型与 JSON 等格式的相互转换
Pydantic 与 FastAPI 有着紧密的集成关系:
1.2 基本使用方法
1.2.1 安装与环境配置
# 安装 Pydantic V2
pip install pydantic
# 安装 Pydantic 与 FastAPI 集成
pip install fastapi pydantic1.2.2 基础模型定义
from pydantic import BaseModel, Field
class User(BaseModel):
id: int
name: str
email: str = Field(..., description="用户邮箱")
age: int = Field(None, ge=0, le=120, description="用户年龄")
# 创建模型实例
user = User(id=1, name="Alice", email="alice@example.com", age=30)
print(user)
# 输出: User(id=1, name='Alice', email='alice@example.com', age=30)
# 从字典创建模型实例
user_data = {"id": 2, "name": "Bob", "email": "bob@example.com"}
user2 = User(**user_data)
print(user2)
# 输出: User(id=2, name='Bob', email='bob@example.com', age=None)1.2.3 数据验证与类型转换
# 自动类型转换
user3 = User(id="3", name="Charlie", email="charlie@example.com", age="25")
print(user3)
# 输出: User(id=3, name='Charlie', email='charlie@example.com', age=25)
# 验证错误示例
from pydantic import ValidationError
try:
user4 = User(id="not-an-int", name="David", email="david@example.com")
except ValidationError as e:
print(e)
# 输出验证错误信息1.2.4 基本字段类型
Pydantic 支持多种字段类型,包括:
- 基本类型:
int、float、str、bool、None - 容器类型:
list、dict、tuple、set - 复杂类型:
Optional、Union、Literal、Generic - 自定义类型:通过继承
BaseModel创建
1.2.5 自定义类型
Pydantic 允许创建自定义类型,以满足特定的验证需求。自定义类型可以通过以下方式实现:
1.2.5.1 通过继承 BaseModel 创建复合类型
from pydantic import BaseModel
class Address(BaseModel):
street: str
city: str
zipcode: str
class User(BaseModel):
id: int
name: str
address: Address
# 使用自定义类型
user = User(
id=1,
name="Alice",
address={
"street": "123 Main St",
"city": "New York",
"zipcode": "10001"
}
)
print(user)1.2.5.2 通过实现 get_validators 方法创建自定义类型
from pydantic import BaseModel, field_validator
class PositiveInt:
@classmethod
def __get_validators__(cls):
yield cls.validate
@classmethod
def validate(cls, v):
if not isinstance(v, int):
raise TypeError('必须是整数')
if v <= 0:
raise ValueError('必须是正数')
return v
class Product(BaseModel):
id: PositiveInt
name: str
price: float
# 使用自定义类型
product = Product(id=1, name="Laptop", price=999.99)
print(product)
# 验证失败
try:
product2 = Product(id=-1, name="Phone", price=599.99)
except Exception as e:
print(e)from pydantic import BaseModel, field_validator
import re
class EmailStr(str):
@classmethod
def __get_validators__(cls):
yield cls.validate
@classmethod
def validate(cls, v):
if not isinstance(v, str):
raise TypeError('必须是字符串')
if not re.match(r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$', v):
raise ValueError('邮箱格式不正确')
return v
class User(BaseModel):
id: int
email: EmailStr
# 使用自定义类型
user = User(id=1, email="alice@example.com")
print(user)
# 验证失败
try:
user2 = User(id=2, email="invalid-email")
except Exception as e:
print(e)1.2.5.3 使用 NewType 创建类型别名
from pydantic import BaseModel
from typing import NewType
# 创建类型别名
UserId = NewType('UserId', int)
Email = NewType('Email', str)
class User(BaseModel):
id: UserId
email: Email
# 使用类型别名
user = User(id=UserId(1), email=Email("alice@example.com"))
print(user)1.3 核心概念
1.3.1 模型 (Model)
模型是 Pydantic 的核心概念,通过继承 BaseModel 类创建。模型定义了数据的结构和验证规则。
1.3.2 字段 (Field)
字段是模型的属性,通过 Field 函数可以设置字段的各种参数,如默认值、验证规则、描述等。
1.3.3 验证器 (Validator)
验证器用于自定义验证逻辑,可以对单个字段或整个模型进行验证。
1.3.4 序列化与反序列化
- 序列化:将模型实例转换为字典或 JSON
- 反序列化:将字典或 JSON 转换为模型实例
2. 验证体系与规则
2.1 内置验证器
2.1.1 类型验证机制
Pydantic 会自动验证字段的类型,并在必要时进行类型转换。
from pydantic import BaseModel
class Item(BaseModel):
name: str
price: float
is_available: bool
# 类型转换示例
item = Item(name="Apple", price="1.99", is_available="true")
print(item)
# 输出: Item(name='Apple', price=1.99, is_available=True)
print(item.model_dump())
# {'name': 'Apple', 'price': 3.14, 'is_available': False}2.1.2 内置约束验证
Pydantic 提供了多种内置的约束验证器:
from pydantic import BaseModel, Field
class Product(BaseModel):
id: int = Field(..., gt=0)
name: str = Field(..., min_length=1, max_length=100)
price: float = Field(..., ge=0)
description: str = Field(None, max_length=1000)
tags: list[str] = Field(default_factory=list)
# 验证通过
product1 = Product(id=1, name="Laptop", price=999.99)
# id=1 name='Laptop' price=999.99 description=None tags=[]
# 验证失败
from pydantic import ValidationError
try:
product2 = Product(id=0, name="", price=-100)
except ValidationError as e:
print(e)2.2 自定义验证规则
使用 @field_validator 装饰器可以定义自定义验证规则:
from pydantic import BaseModel, Field, field_validator, ValidationError
class User(BaseModel):
email: str
password: str
age: int = Field(None, ge=18)
@field_validator('email')
@classmethod
def validate_email(cls, v):
if '@' not in v:
raise ValueError('邮箱格式不正确')
return v
@field_validator('password')
@classmethod
def validate_password(cls, v):
if len(v) < 6:
raise ValueError('密码长度至少为6位')
return v
# 验证通过
user = User(email="user@example.com", password="password123")
# 验证失败
try:
user2 = User(email="invalid-email", password="123")
except ValidationError as e:
print(e)2.3 验证器装饰器参数详解
2.3.1 field_validator 装饰器参数
@field_validator 装饰器支持以下参数:
| 参数 | 类型 | 描述 | 示例 |
|---|---|---|---|
| fields | str | 要验证的字段名 | @field_validator('email', 'password') |
| mode | str | 验证模式,可选值:’before’、’after’、’wrap’ | @field_validator('email', mode='before') |
| check_fields | bool | 是否检查字段是否存在 | @field_validator('email', check_fields=False) |
| pre | bool | 是否在其他验证之前执行 | @field_validator('email', pre=True) |
| always | bool | 是否总是执行,即使字段值为 None | @field_validator('email', always=True) |
示例:
from pydantic import BaseModel, field_validator
class User(BaseModel):
email: str
password: str
age: int = None
# 在其他验证之前执行
@field_validator('email', pre=True)
@classmethod
def normalize_email(cls, v):
if isinstance(v, str):
return v.lower()
return v
# 总是执行,即使字段值为 None
@field_validator('age', always=True)
@classmethod
def validate_age(cls, v):
if v is not None and v < 18:
raise ValueError('年龄必须大于等于18岁')
return v2.3.2 model_validator 装饰器参数
@model_validator 装饰器支持以下参数:
| 参数 | 类型 | 描述 | 示例 |
|---|---|---|---|
| mode | str | 验证模式,可选值:’before’、’after’ | @model_validator(mode='after') |
示例:
from pydantic import BaseModel, model_validator
class Order(BaseModel):
product_id: int
quantity: int
unit_price: float
discount: float = 0
# 在字段验证之后执行
@model_validator(mode='after')
def validate_total(self):
total = self.quantity * self.unit_price
discounted_total = total * (1 - self.discount)
if discounted_total < 0:
raise ValueError('折扣后总价不能为负数')
return self
# 在字段验证之前执行
@model_validator(mode='before')
@classmethod
def validate_input(cls, values):
if values.get('quantity') <= 0:
raise ValueError('数量必须大于0')
return values2.4 高级验证技术
2.4.1 递归模型验证
Pydantic 支持嵌套模型的验证:
from pydantic import BaseModel
class Address(BaseModel):
street: str
city: str
zipcode: str
class User(BaseModel):
name: str
address: Address
# 验证通过
user = User(
name="Alice",
address={
"street": "123 Main St",
"city": "New York",
"zipcode": "10001"
}
)
# 验证失败
try:
user2 = User(
name="Bob",
address={
"street": "456 Oak Ave",
"city": "Boston"
# 缺少 zipcode
}
)
except ValidationError as e:
print(e)2.4.2 联合类型验证
使用 Union 类型可以接受多种类型的值:
from typing import Union
from pydantic import BaseModel
class Item(BaseModel):
id: Union[int, str]
name: str
# 验证通过
item1 = Item(id=1, name="Apple")
item2 = Item(id="2", name="Banana")2.4.3 复合验证
复合验证是指涉及多个字段之间关系的验证场景,通常使用 @model_validator 来实现:
2.4.3.1 密码确认验证
from pydantic import BaseModel, model_validator, ValidationError
class UserCreate(BaseModel):
username: str
password: str
confirm_password: str
@model_validator(mode='after')
def validate_password_match(self):
if self.password != self.confirm_password:
raise ValueError('密码和确认密码不匹配')
return self
# 验证通过
user1 = UserCreate(username="alice", password="password123", confirm_password="password123")
print(user1)
# 验证失败
try:
user2 = UserCreate(username="bob", password="password123", confirm_password="different")
except ValidationError as e:
print(e)2.4.3.2 开始日期和结束日期验证
from pydantic import BaseModel, model_validator, ValidationError
from datetime import date
class DateRange(BaseModel):
start_date: date
end_date: date
@model_validator(mode='after')
def validate_date_range(self):
if self.start_date > self.end_date:
raise ValueError('开始日期不能晚于结束日期')
return self
# 验证通过
from datetime import date
range1 = DateRange(start_date=date(2023, 1, 1), end_date=date(2023, 12, 31))
print(range1)
# 验证失败
try:
range2 = DateRange(start_date=date(2023, 12, 31), end_date=date(2023, 1, 1))
except ValidationError as e:
print(e)2.4.3.3 条件验证
from pydantic import BaseModel, model_validator, ValidationError
class Product(BaseModel):
name: str
price: float
is_discounted: bool
discount: float = 0
@model_validator(mode='after')
def validate_discount(self):
if self.is_discounted:
if self.discount <= 0 or self.discount >= 1:
raise ValueError('折扣必须在 0 和 1 之间')
else:
if self.discount != 0:
raise ValueError('非折扣商品的折扣必须为 0')
return self
# 验证通过
product1 = Product(name="Laptop", price=999.99, is_discounted=True, discount=0.1)
print(product1)
product2 = Product(name="Phone", price=599.99, is_discounted=False, discount=0)
print(product2)
# 验证失败
try:
product3 = Product(name="Tablet", price=399.99, is_discounted=True, discount=1.5)
except ValidationError as e:
print(e)
# 验证失败
try:
product4 = Product(name="Headphones", price=199.99, is_discounted=False, discount=0.05)
except ValidationError as e:
print(e)2.4.3.4 依赖字段验证
from pydantic import BaseModel, model_validator, ValidationError
class Order(BaseModel):
product_id: int
quantity: int
is_gift: bool
gift_message: str = None
@model_validator(mode='after')
def validate_gift_message(self):
if self.is_gift and not self.gift_message:
raise ValueError('礼品订单必须包含礼品信息')
elif not self.is_gift and self.gift_message:
raise ValueError('非礼品订单不应包含礼品信息')
return self
# 验证通过
order1 = Order(product_id=1, quantity=2, is_gift=True, gift_message="Happy Birthday!")
print(order1)
order2 = Order(product_id=2, quantity=1, is_gift=False)
print(order2)
# 验证失败
try:
order3 = Order(product_id=3, quantity=1, is_gift=True)
except ValidationError as e:
print(e)
# 验证失败
try:
order4 = Order(product_id=4, quantity=1, is_gift=False, gift_message="This is a gift")
except ValidationError as e:
print(e)2.4.3.5 泛型模型验证
使用 Generic 可以创建泛型模型:
from typing import Generic, TypeVar, List
from pydantic import BaseModel
T = TypeVar('T')
class PaginatedResponse(BaseModel, Generic[T]):
items: List[T]
total: int
page: int
page_size: int
# 使用泛型模型
class User(BaseModel):
id: int
name: str
response = PaginatedResponse[
User
](
items=[User(id=1, name="Alice"), User(id=2, name="Bob")],
total=100,
page=1,
page_size=10
)
print(response)2.4.3.6 异步验证支持
Pydantic V2 支持异步验证:
from pydantic import BaseModel, field_validator
import asyncio
class User(BaseModel):
email: str
@field_validator('email')
@classmethod
async def validate_email(cls, v):
# 模拟异步操作,例如检查邮箱是否已存在
await asyncio.sleep(0.1)
if '@' not in v:
raise ValueError('邮箱格式不正确')
return v
async def main():
user = await User.model_validate_async({"email": "user@example.com"})
print(user)
asyncio.run(main())2.5 验证流程
2.5.1 字段级验证
字段级验证是对单个字段进行的验证,包括类型验证和自定义验证。
2.5.2 模型级验证
模型级验证是对整个模型进行的验证,可以访问多个字段的值:
from pydantic import BaseModel, model_validator
class Order(BaseModel):
product_id: int
quantity: int
unit_price: float
discount: float = 0
@model_validator(mode='after')
def validate_total(self):
total = self.quantity * self.unit_price
discounted_total = total * (1 - self.discount)
if discounted_total < 0:
raise ValueError('折扣后总价不能为负数')
return self
# 验证通过
order = Order(product_id=1, quantity=2, unit_price=100, discount=0.1)
# 验证失败
try:
order2 = Order(product_id=1, quantity=2, unit_price=100, discount=2)
except ValidationError as e:
print(e)2.5.3 验证错误处理
Pydantic 的验证错误会抛出 ValidationError 异常,包含详细的错误信息:
from pydantic import ValidationError
try:
user = User(email="invalid-email", password="123")
except ValidationError as e:
# 获取错误信息
print(e.errors())
# 输出 JSON 格式的错误信息
print(e.json())2.5.4 验证错误消息定制
可以通过 Field 的 error_messages 参数定制错误消息:
from pydantic import BaseModel, Field
class User(BaseModel):
age: int = Field(..., ge=18, error_messages={
'ge': '年龄必须大于等于18岁'
})
# 验证失败
try:
user = User(age=17)
except ValidationError as e:
print(e)3. 字段与模型配置
3.1 字段参数详解
3.1.1 default 与 default_factory
- default:设置字段的默认值
- default_factory:使用函数生成默认值,适用于可变类型
from pydantic import BaseModel, Field
from typing import List
from datetime import datetime
class User(BaseModel):
name: str
# 使用默认值
age: int = 18
# 使用 default_factory
created_at: datetime = Field(default_factory=datetime.utcnow)
tags: List[str] = Field(default_factory=list)
# 创建实例
user = User(name="Alice")
print(user)
# 输出: User(name='Alice', age=18, created_at=datetime.datetime(...), tags=[])3.1.2 alias 与 alias_priority
- alias:设置字段的别名,用于序列化和反序列化
- alias_priority:设置别名的优先级
from pydantic import BaseModel, Field
class User(BaseModel):
user_id: int = Field(..., alias="id")
user_name: str = Field(..., alias="name")
model_config = {
"populate_by_name": True
}
# 使用别名创建实例
user = User(id=1, name="Alice")
print(user)
# 输出: User(user_id=1, user_name='Alice')
# 序列化时使用别名
print(user.model_dump(by_alias=True))
# 输出: {'id': 1, 'name': 'Alice'}3.1.3 title 与 description
- title:设置字段的标题,用于生成 JSON Schema
- description:设置字段的描述,用于生成 JSON Schema
from pydantic import BaseModel, Field
class User(BaseModel):
id: int = Field(..., title="用户ID", description="用户的唯一标识符")
name: str = Field(..., title="用户名", description="用户的名称")
# 生成 JSON Schema
print(User.model_json_schema())3.1.4 数值约束
- gt:大于
- ge:大于等于
- lt:小于
- le:小于等于
from pydantic import BaseModel, Field
class Product(BaseModel):
price: float = Field(..., gt=0, le=10000)
quantity: int = Field(..., ge=1, lt=1000)
# 验证通过
product = Product(price=99.99, quantity=50)
# 验证失败
try:
product2 = Product(price=0, quantity=1000)
except ValidationError as e:
print(e)3.1.5 字符串约束
- min_length:最小长度
- max_length:最大长度
- pattern:正则表达式模式
from pydantic import BaseModel, Field
class User(BaseModel):
name: str = Field(..., min_length=1, max_length=50)
email: str = Field(..., pattern=r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$')
# 验证通过
user = User(name="Alice", email="alice@example.com")
# 验证失败
try:
user2 = User(name="", email="invalid-email")
except ValidationError as e:
print(e)3.1.6 高级参数
- exclude:序列化时排除字段
- include:序列化时包含字段
- discriminator:用于联合类型的鉴别器
3.2 模型配置
3.2.1 model_config 配置类
Pydantic V2 使用 model_config 字典或 ConfigDict 来配置模型:
from pydantic import BaseModel, ConfigDict
class User(BaseModel):
id: int
name: str
email: str
# 使用字典配置
model_config = {
"extra": "forbid",
"frozen": False,
"populate_by_name": True
}
# 或使用 ConfigDict
class Product(BaseModel):
id: int
name: str
price: float
model_config = ConfigDict(
extra="allow",
frozen=True,
populate_by_name=True
)3.2.2 extra 字段处理策略
- forbid:禁止额外字段
- allow:允许额外字段
- ignore:忽略额外字段
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
model_config = {
"extra": "forbid"
}
# 验证失败,因为有额外字段
try:
user = User(id=1, name="Alice", email="alice@example.com")
except ValidationError as e:
print(e)3.2.3 frozen 不可变模型
设置 frozen=True 可以创建不可变模型:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
model_config = {
"frozen": True
}
user = User(id=1, name="Alice")
# 尝试修改字段会抛出异常
try:
user.name = "Bob"
except Exception as e:
print(e)3.2.4 populate_by_name 行为
设置 populate_by_name=True 可以通过字段名或别名创建模型实例:
from pydantic import BaseModel, Field
class User(BaseModel):
user_id: int = Field(..., alias="id")
user_name: str = Field(..., alias="name")
model_config = {
"populate_by_name": True
}
# 可以通过字段名创建
user1 = User(user_id=1, user_name="Alice")
# 也可以通过别名创建
user2 = User(id=2, name="Bob")3.2.5 json_schema_extra 扩展
使用 json_schema_extra 可以向 JSON Schema 添加额外信息:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
model_config = {
"json_schema_extra": {
"examples": [
{
"id": 1,
"name": "Alice"
}
]
}
}
print(User.model_json_schema())3.3 全局配置
Pydantic 允许设置全局配置:
from pydantic import BaseModel, ConfigDict
# 全局配置
class BaseConfig(BaseModel):
model_config = ConfigDict(
extra="forbid",
frozen=False,
populate_by_name=True
)
# 继承全局配置
class User(BaseConfig):
id: int
name: str
class Product(BaseConfig):
id: int
name: str
price: float3.4 model_config 完整配置选项
model_config 支持以下配置选项:
| 配置选项 | 类型 | 描述 | 默认值 | 示例 |
|---|---|---|---|---|
| extra | str | 额外字段处理策略 | “forbid” | "allow", "ignore", "forbid" |
| frozen | bool | 是否为不可变模型 | False | True |
| populate_by_name | bool | 是否通过字段名填充 | False | True |
| json_schema_extra | dict | JSON Schema 额外信息 | None | {"examples": [...]} |
| str_max_length | int | 字符串最大长度 | None | 100 |
| str_min_length | int | 字符串最小长度 | None | 1 |
| int_max | int | 整数最大值 | None | 100 |
| int_min | int | 整数最小值 | None | 0 |
| float_max | float | 浮点数最大值 | None | 100.0 |
| float_min | float | 浮点数最小值 | None | 0.0 |
| validate_assignment | bool | 是否验证赋值 | True | False |
| arbitrary_types_allowed | bool | 是否允许任意类型 | False | True |
| from_attributes | bool | 是否从属性创建模型 | False | True |
| loc_by_alias | bool | 是否按别名定位错误 | False | True |
| protected_namespaces | set | 保护的命名空间 | {“model_”} | {"model_", "db_"} |
| ser_json_timedelta | str | 时间差序列化格式 | “iso8601” | "total_seconds" |
| ser_json_date | str | 日期序列化格式 | “iso8601” | "iso8601" |
| ser_json_datetime | str | 日期时间序列化格式 | “iso8601” | "iso8601" |
| ser_json_bytes | str | 字节序列化格式 | “base64” | "utf-8" |
示例:
from pydantic import BaseModel, ConfigDict
from datetime import datetime, timedelta
class User(BaseModel):
id: int
name: str
created_at: datetime
duration: timedelta
data: bytes
model_config = ConfigDict(
# 基本配置
extra="forbid",
frozen=False,
populate_by_name=True,
# 验证配置
validate_assignment=True,
arbitrary_types_allowed=False,
# 序列化配置
ser_json_datetime="iso8601",
ser_json_timedelta="total_seconds",
ser_json_bytes="utf-8",
# JSON Schema 配置
json_schema_extra={
"examples": [
{
"id": 1,
"name": "Alice",
"created_at": "2023-01-01T00:00:00",
"duration": 3600,
"data": "Hello World"
}
]
}
)
# 创建实例
user = User(
id=1,
name="Alice",
created_at=datetime.utcnow(),
duration=timedelta(hours=1),
data=b"Hello World"
)
# 序列化
print(user.model_dump_json())4. 模型继承与设计
4.1 模型继承
4.1.1 基本继承机制
Pydantic 支持模型继承,子类会继承父类的所有字段:
from pydantic import BaseModel
class BaseUser(BaseModel):
id: int
name: str
class User(BaseUser):
email: str
age: int
# 创建 User 实例
user = User(id=1, name="Alice", email="alice@example.com", age=30)
print(user)
# 输出: User(id=1, name='Alice', email='alice@example.com', age=30)4.1.2 字段覆盖与扩展
子类可以覆盖父类的字段,或添加新字段:
from pydantic import BaseModel, Field
class BaseUser(BaseModel):
id: int
name: str = Field(..., min_length=1)
class User(BaseUser):
# 覆盖父类字段
name: str = Field(..., min_length=2)
# 添加新字段
email: str
# 验证通过
user = User(id=1, name="Alice", email="alice@example.com")
# 验证失败,因为 name 长度不足
try:
user2 = User(id=2, name="A", email="bob@example.com")
except ValidationError as e:
print(e)4.1.3 多继承处理
Pydantic 支持多继承,但需要注意字段冲突:
from pydantic import BaseModel
class BaseModel1(BaseModel):
id: int
name: str
class BaseModel2(BaseModel):
id: int
email: str
class User(BaseModel1, BaseModel2):
age: int
# 创建实例
user = User(id=1, name="Alice", email="alice@example.com", age=30)
print(user)
# 输出: User(id=1, name='Alice', email='alice@example.com', age=30)4.1.4 抽象基类
可以创建抽象基类,作为其他模型的基础:
from pydantic import BaseModel
from abc import ABC
class BaseEntity(BaseModel, ABC):
id: int
created_at: str
class User(BaseEntity):
name: str
email: str
class Product(BaseEntity):
name: str
price: float
# 创建实例
user = User(id=1, created_at="2023-01-01", name="Alice", email="alice@example.com")
product = Product(id=1, created_at="2023-01-01", name="Laptop", price=999.99)4.2 组合与嵌套
4.2.1 嵌套模型
Pydantic 支持嵌套模型:
from pydantic import BaseModel
class Address(BaseModel):
street: str
city: str
zipcode: str
class User(BaseModel):
id: int
name: str
address: Address
# 创建实例
user = User(
id=1,
name="Alice",
address={
"street": "123 Main St",
"city": "New York",
"zipcode": "10001"
}
)
print(user)4.2.2 模型组合
可以通过组合多个模型来创建更复杂的模型:
from pydantic import BaseModel
class PersonalInfo(BaseModel):
name: str
age: int
email: str
class Address(BaseModel):
street: str
city: str
zipcode: str
class User(BaseModel):
id: int
personal_info: PersonalInfo
address: Address
# 创建实例
user = User(
id=1,
personal_info={
"name": "Alice",
"age": 30,
"email": "alice@example.com"
},
address={
"street": "123 Main St",
"city": "New York",
"zipcode": "10001"
}
)
print(user)4.2.3 递归模型
Pydantic 支持递归模型,用于表示树状结构:
from pydantic import BaseModel
from typing import Optional, List
class Category(BaseModel):
id: int
name: str
parent: Optional['Category'] = None
children: List['Category'] = []
# 更新前向引用
Category.model_rebuild()
# 创建递归模型
root = Category(
id=1,
name="Root",
children=[
Category(
id=2,
name="Child 1"
),
Category(
id=3,
name="Child 2",
children=[
Category(
id=4,
name="Grandchild 1"
)
]
)
]
)
# 设置父引用
for child in root.children:
child.parent = root
for grandchild in child.children:
grandchild.parent = child
# 打印模型(注意:直接打印可能会导致递归输出,建议使用 model_dump 并排除父引用)
print("Root category:", root.name)
print("Children count:", len(root.children))
for child in root.children:
print(f"- Child: {child.name}, Grandchildren: {len(child.children)}")
# 安全序列化(排除父引用以避免循环)
root_dict = root.model_dump(exclude={"parent"}, exclude_none=True)
print("Serialized root:", root_dict)4.2.4 模型与字典转换
Pydantic 提供了模型与字典之间的转换方法:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
email: str
# 创建模型实例
user = User(id=1, name="Alice", email="alice@example.com")
# 转换为字典
user_dict = user.model_dump()
print(user_dict)
# 输出: {'id': 1, 'name': 'Alice', 'email': 'alice@example.com'}
# 从字典创建模型实例
user2 = User(**user_dict)
print(user2)
# 输出: User(id=1, name='Alice', email='alice@example.com')4.3 高级模型设计
4.3.1 泛型模型
使用 Generic 可以创建泛型模型:
from typing import Generic, TypeVar, List
from pydantic import BaseModel
T = TypeVar('T')
class PaginatedResponse(BaseModel, Generic[T]):
items: List[T]
total: int
page: int
page_size: int
# 使用泛型模型
class User(BaseModel):
id: int
name: str
class Product(BaseModel):
id: int
name: str
price: float
# 创建用户分页响应
user_response = PaginatedResponse[
User
](
items=[User(id=1, name="Alice"), User(id=2, name="Bob")],
total=100,
page=1,
page_size=10
)
# 创建产品分页响应
product_response = PaginatedResponse[
Product
](
items=[Product(id=1, name="Laptop", price=999.99)],
total=50,
page=1,
page_size=10
)
print(user_response)
print(product_response)4.3.2 动态模型
使用 create_model 可以动态创建模型:
from pydantic import create_model
# 动态创建模型
User = create_model(
'User',
id=(int, ...),
name=(str, ...),
email=(str, None)
)
# 创建实例
user = User(id=1, name="Alice", email="alice@example.com")
print(user)4.3.3 部分模型
使用 model_validate 可以创建部分模型:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
email: str
age: int
# 只提供部分字段
user_data = {"id": 1, "name": "Alice"}
user = User.model_validate(user_data)
print(user)
# 输出: User(id=1, name='Alice', email=None, age=None)4.3.4 代理模型
可以创建代理模型来扩展现有模型:
from pydantic import BaseModel
class BaseUser(BaseModel):
id: int
name: str
class UserProxy(BaseUser):
@property
def full_name(self):
return self.name
def greet(self):
return f"Hello, {self.name}!"
# 创建实例
user = UserProxy(id=1, name="Alice")
print(user.full_name)
print(user.greet())5. 核心方法与执行流程
5.1 核心验证方法
5.1.1 model_validate
model_validate 是 Pydantic V2 的核心验证方法,用于从字典或其他数据结构创建模型实例:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
email: str
# 从字典创建实例
user_data = {"id": 1, "name": "Alice", "email": "alice@example.com"}
user = User.model_validate(user_data)
print(user)
# 从其他对象创建实例
class UserData:
def __init__(self, id, name, email):
self.id = id
self.name = name
self.email = email
user_data_obj = UserData(2, "Bob", "bob@example.com")
user2 = User.model_validate(user_data_obj)
print(user2)参数说明:
obj:要验证的对象,可以是字典、具有属性的对象或其他可转换为字典的数据结构strict:是否严格验证,默认为False。当设置为True时,不允许类型转换,输入数据必须与字段类型完全匹配context:验证上下文,可用于传递额外信息给验证器
使用场景:
- 从 API 请求体创建模型实例
- 从数据库查询结果创建模型实例
- 从配置文件加载数据创建模型实例
- 从其他系统的响应数据创建模型实例
示例:
from pydantic import BaseModel, field_validator
class User(BaseModel):
id: int
name: str
email: str
@field_validator('email')
@classmethod
def validate_email(cls, v):
if '@' not in v:
raise ValueError('邮箱格式不正确')
return v
# 严格模式验证
try:
# 类型不匹配,会抛出验证错误
user = User.model_validate({"id": "1", "name": "Alice", "email": "alice@example.com"}, strict=True)
except Exception as e:
print(f"严格模式验证失败: {e}")
# 非严格模式验证(默认)
user = User.model_validate({"id": "1", "name": "Alice", "email": "alice@example.com"}, strict=False)
print(f"非严格模式验证成功: {user}")
# 使用上下文传递额外信息
class Product(BaseModel):
name: str
price: float
@field_validator('price')
@classmethod
def validate_price(cls, v, info):
# 从上下文获取最低价格
min_price = info.context.get('min_price', 0)
if v < min_price:
raise ValueError(f"价格不能低于 {min_price}")
return v
# 传递上下文
product = Product.model_validate(
{"name": "Laptop", "price": 999.99},
context={"min_price": 500}
)
print(f"带上下文验证成功: {product}")5.1.2 model_validate_json
model_validate_json 用于从 JSON 字符串创建模型实例:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
email: str
# 从 JSON 字符串创建实例
json_str = '{"id": 1, "name": "Alice", "email": "alice@example.com"}'
user = User.model_validate_json(json_str)
print(user)5.1.3 model_validate_async
model_validate_async 是 Pydantic V2 的异步验证方法,用于从字典或其他数据结构异步创建模型实例:
from pydantic import BaseModel, field_validator
import asyncio
class User(BaseModel):
email: str
name: str
@field_validator('email')
@classmethod
async def validate_email(cls, v):
# 模拟异步操作,例如检查邮箱是否已存在
await asyncio.sleep(0.1)
if '@' not in v:
raise ValueError('邮箱格式不正确')
return v
async def main():
# 从字典异步创建实例
user_data = {"email": "user@example.com", "name": "Alice"}
user = await User.model_validate_async(user_data)
print(user)
asyncio.run(main())参数说明:
obj:要验证的对象,与model_validate相同strict:是否严格验证,默认为Falsecontext:验证上下文,可用于传递额外信息
使用场景:
- 当验证逻辑中包含异步操作(如数据库查询、API 调用等)时
- 在异步框架(如 FastAPI)中使用,保持代码风格一致
- 需要在验证过程中执行 I/O 操作时
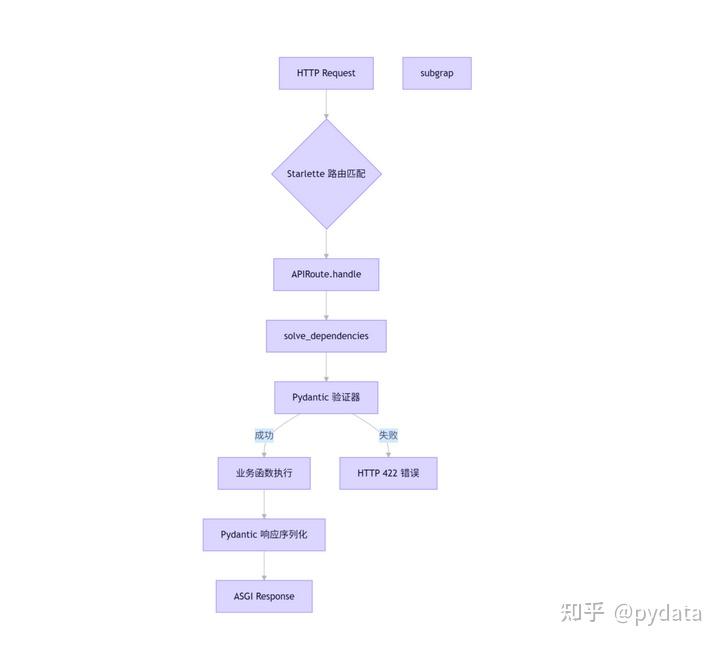
5.1.4 验证流程详解
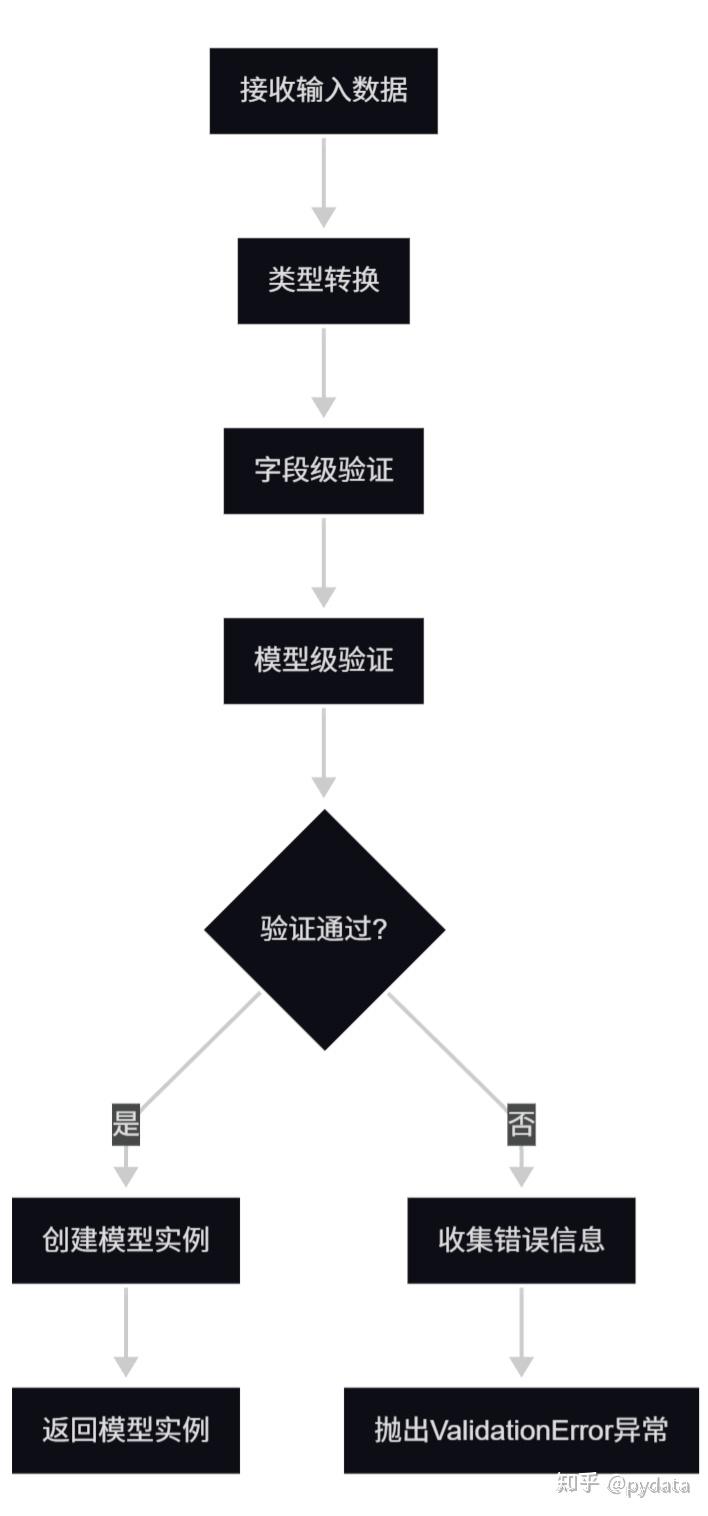
Pydantic 的验证流程包括以下步骤:
- 数据接收:接收输入数据(字典、JSON 或其他对象)
- 类型转换:将输入数据转换为模型字段的类型
- 字段验证:对每个字段进行验证(类型验证、约束验证、自定义验证)
- 模型验证:对整个模型进行验证
- 错误处理:收集验证错误并抛出异常
- 实例创建:创建并返回模型实例
5.2 核心序列化方法
5.2.1 model_dump
model_dump 是 Pydantic V2 的核心序列化方法,用于将模型实例转换为字典:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
email: str
user = User(id=1, name="Alice", email="alice@example.com")
# 转换为字典
user_dict = user.model_dump()
print(user_dict)
# 输出: {'id': 1, 'name': 'Alice', 'email': 'alice@example.com'}
# 排除某些字段
user_dict_no_email = user.model_dump(exclude={"email"})
print(user_dict_no_email)
# 输出: {'id': 1, 'name': 'Alice'}
# 只包含某些字段
user_dict_only_name = user.model_dump(include={"name"})
print(user_dict_only_name)
# 输出: {'name': 'Alice'}参数说明:
include:要包含的字段集合,默认为None(包含所有字段)exclude:要排除的字段集合,默认为None(不排除任何字段)by_alias:是否使用字段别名作为键,默认为Falseexclude_unset:是否排除未设置的字段,默认为Falseexclude_defaults:是否排除具有默认值的字段,默认为Falseexclude_none:是否排除值为None的字段,默认为Falseround_trip:是否确保序列化后的数据可以再次反序列化,默认为Falsewarnings:是否显示警告,默认为True
使用场景:
- 将模型实例转换为字典用于数据库操作
- 准备 API 响应数据
- 生成配置文件内容
- 与其他系统交互时的数据格式转换
示例:
from pydantic import BaseModel, Field
class User(BaseModel):
user_id: int = Field(..., alias="id")
user_name: str = Field(..., alias="name")
email: str
age: int = None
model_config = {
"populate_by_name": True
}
user = User(id=1, name="Alice", email="alice@example.com")
# 使用别名作为键
user_dict_alias = user.model_dump(by_alias=True)
print(user_dict_alias)
# 输出: {'id': 1, 'name': 'Alice', 'email': 'alice@example.com', 'age': None}
# 排除未设置的字段
user_dict_no_unset = user.model_dump(exclude_unset=True)
print(user_dict_no_unset)
# 输出: {'user_id': 1, 'user_name': 'Alice', 'email': 'alice@example.com'}
# 排除值为 None 的字段
user_dict_no_none = user.model_dump(exclude_none=True)
print(user_dict_no_none)
# 输出: {'user_id': 1, 'user_name': 'Alice', 'email': 'alice@example.com'}
# 组合使用多个参数
user_dict_custom = user.model_dump(
include={"user_name", "email"},
exclude_none=True,
by_alias=True
)
print(user_dict_custom)
# 输出: {'name': 'Alice', 'email': 'alice@example.com'}5.2.2 model_dump_json
model_dump_json 用于将模型实例转换为 JSON 字符串:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
email: str
user = User(id=1, name="Alice", email="alice@example.com")
# 转换为 JSON 字符串
json_str = user.model_dump_json()
print(json_str)
# 输出: {"id": 1, "name": "Alice", "email": "alice@example.com"}
# 美化输出
json_str_pretty = user.model_dump_json(indent=2)
print(json_str_pretty)5.2.3 序列化流程详解
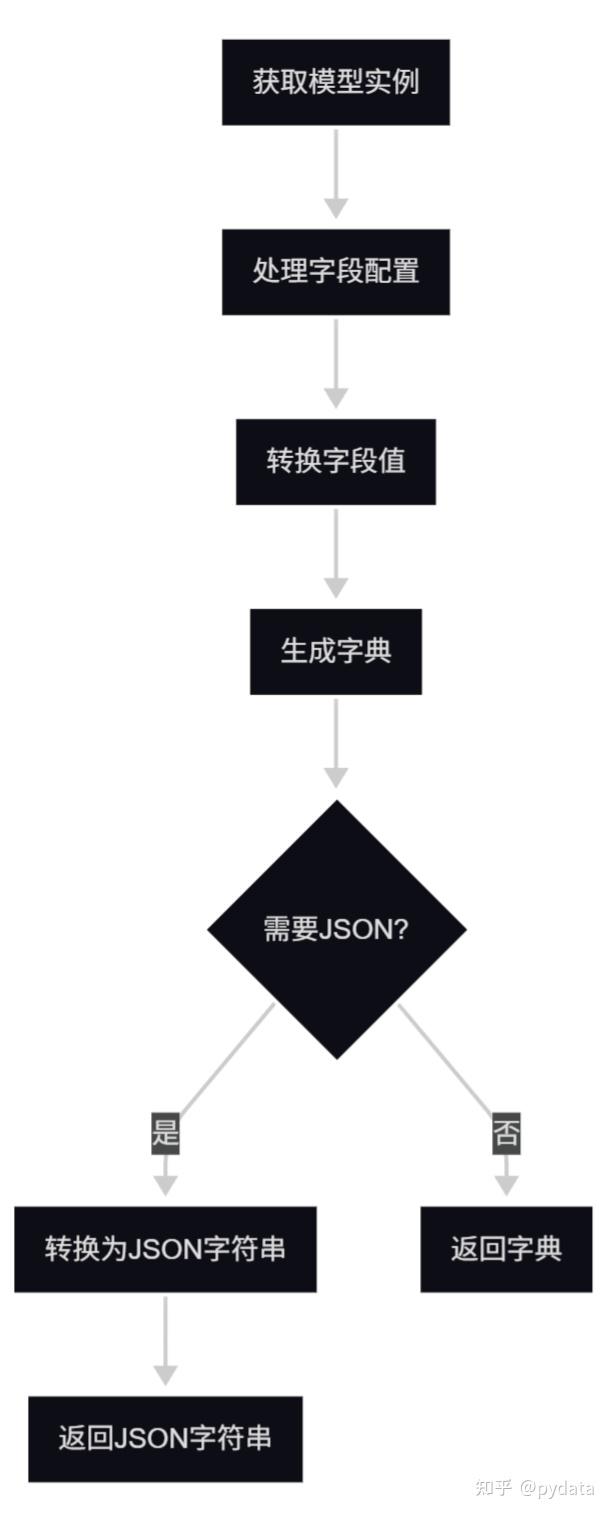
Pydantic 的序列化流程包括以下步骤:
- 实例准备:获取模型实例的所有字段值
- 字段处理:根据配置处理字段(排除、包含、别名等)
- 类型转换:将 Python 类型转换为 JSON 兼容类型
- 字典生成:生成序列化后的字典
- JSON 转换:将字典转换为 JSON 字符串(如果使用
model_dump_json)
5.3 执行原理
5.3.1 数据验证流程
5.3.2 序列化流程
5.3.3 错误处理机制
Pydantic 的错误处理机制包括:
- 错误收集:在验证过程中收集所有错误
- 错误格式化:将错误格式化为结构化的错误信息
- 错误抛出:抛出
ValidationError异常,包含所有错误信息 - 错误访问:通过异常对象的
errors()和json()方法访问错误信息
6. 易错点与调试技巧
6.1 常见错误类型
6.1.1 类型错误
错误表现:输入数据类型与字段类型不匹配
解决方案:确保输入数据类型正确,或使用 Optional 类型
from pydantic import BaseModel, ValidationError
class User(BaseModel):
id: int
name: str
# 类型错误示例
try:
user = User(id="not-an-int", name="Alice")
except ValidationError as e:
print(e)6.1.2 验证错误
错误表现:输入数据不符合验证规则
解决方案:确保输入数据符合所有验证规则
from pydantic import BaseModel, Field, ValidationError
class User(BaseModel):
age: int = Field(..., ge=18)
# 验证错误示例
try:
user = User(age=17)
except ValidationError as e:
print(e)6.1.3 序列化错误
错误表现:模型实例无法序列化为 JSON
解决方案:确保所有字段值都是 JSON 兼容的
from pydantic import BaseModel
from datetime import datetime
class User(BaseModel):
id: int
name: str
created_at: datetime
# 序列化示例
user = User(id=1, name="Alice", created_at=datetime.utcnow())
print(user.model_dump_json())6.1.4 继承错误
错误表现:模型继承时字段冲突或验证失败
解决方案:确保子类字段与父类字段兼容
from pydantic import BaseModel, ValidationError
class BaseUser(BaseModel):
id: int
class User(BaseUser):
# 覆盖父类字段时类型必须兼容
id: str
# 继承错误示例
try:
user = User(id="1")
except ValidationError as e:
print(e)6.2 疑难问题解析
6.2.1 循环引用处理
问题:模型之间存在循环引用,导致验证失败
解决方案:使用字符串类型提示和 model_rebuild()
from pydantic import BaseModel
from typing import Optional
class Category(BaseModel):
id: int
name: str
parent: Optional['Category'] = None
# 更新前向引用
Category.model_rebuild()
# 创建循环引用
parent = Category(id=1, name="Parent")
child = Category(id=2, name="Child", parent=parent)
parent.parent = child # 创建循环引用
print(child)6.2.2 复杂嵌套结构
问题:处理深度嵌套的模型结构
解决方案:使用嵌套模型和合理的模型设计
from pydantic import BaseModel
from typing import List
class Address(BaseModel):
street: str
city: str
class Contact(BaseModel):
email: str
phone: str
class User(BaseModel):
id: int
name: str
address: Address
contacts: List[Contact]
# 复杂嵌套结构
user = User(
id=1,
name="Alice",
address={"street": "123 Main St", "city": "New York"},
contacts=[
{"email": "alice@example.com", "phone": "123-456-7890"},
{"email": "alice.work@example.com", "phone": "987-654-3210"}
]
)
print(user)6.2.3 动态字段处理
问题:处理运行时动态添加的字段
解决方案:使用 extra="allow" 或动态模型
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
model_config = {
"extra": "allow"
}
# 动态字段
user = User(id=1, name="Alice", email="alice@example.com", age=30)
print(user)
print(user.model_dump())6.2.4 性能瓶颈分析
问题:Pydantic 验证在处理大量数据时性能下降
解决方案:使用缓存、减少嵌套层级、优化验证逻辑
6.3 调试技巧
6.3.1 验证错误定位
技巧:使用 e.errors() 获取详细的错误信息
from pydantic import ValidationError
try:
user = User(id="not-an-int", name="")
except ValidationError as e:
# 获取详细错误信息
errors = e.errors()
for error in errors:
print(f"字段: {error['loc']}, 错误: {error['msg']}, 类型: {error['type']}")6.3.2 模型状态检查
技巧:使用 model_dump() 查看模型的当前状态
user = User(id=1, name="Alice")
print(user.model_dump())6.3.3 序列化问题排查
技巧:检查字段值是否为 JSON 兼容类型
from pydantic import BaseModel
from datetime import datetime
class User(BaseModel):
id: int
name: str
created_at: datetime
user = User(id=1, name="Alice", created_at=datetime.utcnow())
# 排查序列化问题
try:
json_str = user.model_dump_json()
print(json_str)
except Exception as e:
print(f"序列化错误: {e}")7. 实际应用场景
7.1 API 数据验证
7.1.1 请求体验证
在 FastAPI 中,使用 Pydantic 模型验证请求体:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class UserCreate(BaseModel):
name: str
email: str
password: str
@app.post("/users/")
def create_user(user: UserCreate):
# 处理用户创建逻辑
return {"user": user}7.1.2 响应模型
使用 Pydantic 模型定义 API 响应:
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List
app = FastAPI()
class User(BaseModel):
id: int
name: str
email: str
class UserResponse(BaseModel):
users: List[User]
total: int
@app.get("/users/", response_model=UserResponse)
def get_users():
# 模拟用户数据
users = [
User(id=1, name="Alice", email="alice@example.com"),
User(id=2, name="Bob", email="bob@example.com")
]
return {"users": users, "total": len(users)}7.1.3 依赖注入
使用 Pydantic 模型进行依赖注入:
from fastapi import FastAPI, Depends
from pydantic import BaseModel
app = FastAPI()
class Pagination(BaseModel):
page: int = 1
page_size: int = 10
@app.get("/items/")
def get_items(pagination: Pagination = Depends()):
# 处理分页逻辑
return {"page": pagination.page, "page_size": pagination.page_size}7.1.4 文档生成
FastAPI 会自动根据 Pydantic 模型生成 API 文档:
from fastapi import FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class UserCreate(BaseModel):
name: str = Field(..., description="用户名")
email: str = Field(..., description="邮箱地址")
password: str = Field(..., description="密码")
@app.post("/users/")
def create_user(user: UserCreate):
"""创建新用户"""
return {"user": user}7.2 配置管理
7.2.1 环境变量集成
使用 Pydantic 管理环境变量配置需要安装 pydantic-settings 包:
pip install pydantic-settings
from pydantic_settings import BaseSettings
from typing import Optional
class Settings(BaseSettings):
# 数据库配置
DATABASE_URL: str
# API 配置
API_KEY: str
API_SECRET: str
# 应用配置
APP_NAME: str = "My App"
DEBUG: bool = False
class Config:
env_file = ".env"
# 加载配置
settings = Settings()
print(settings.APP_NAME)
print(settings.DATABASE_URL)7.2.2 配置分层
使用继承创建分层配置:
from pydantic_settings import BaseSettings
class BaseConfig(BaseSettings):
APP_NAME: str = "My App"
DEBUG: bool = False
class DevConfig(BaseConfig):
DEBUG: bool = True
DATABASE_URL: str = "sqlite:///dev.db"
class ProdConfig(BaseConfig):
DATABASE_URL: str = "postgresql://user:pass@localhost/db"
# 根据环境加载配置
import os
env = os.getenv("ENV", "dev")
if env == "prod":
settings = ProdConfig()
else:
settings = DevConfig()
print(settings.APP_NAME)
print(settings.DATABASE_URL)
print(settings.DEBUG)7.2.3 配置验证
使用 Pydantic 验证配置:
from pydantic_settings import BaseSettings
from pydantic import Field
class Settings(BaseSettings):
# 验证数据库 URL
DATABASE_URL: str = Field(..., description="数据库连接 URL")
# 验证端口号
PORT: int = Field(..., ge=1, le=65535, description="服务端口")
# 验证 API 密钥长度
API_KEY: str = Field(..., min_length=16, description="API 密钥")
# 加载配置
settings = Settings()
print(settings.DATABASE_URL)
print(settings.PORT)
print(settings.API_KEY)7.2.4 多环境支持
使用 Pydantic 支持多环境配置:
from pydantic_settings import BaseSettings
import os
class Settings(BaseSettings):
APP_NAME: str = "My App"
DEBUG: bool = False
DATABASE_URL: str
class Config:
env_file = f".env.{os.getenv('ENV', 'dev')}"
# 加载配置
settings = Settings()
print(settings.APP_NAME)
print(settings.DATABASE_URL)
print(settings.DEBUG)7.2.5 实际项目案例
案例:用户管理系统
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
from typing import List, Optional
app = FastAPI()
# 数据模型
class UserBase(BaseModel):
name: str = Field(..., min_length=1, max_length=50)
email: str = Field(..., pattern=r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$')
class UserCreate(UserBase):
password: str = Field(..., min_length=6)
class User(UserBase):
id: int
# 模拟数据库
users_db = []
next_id = 1
# API 端点
@app.post("/users/", response_model=User)
def create_user(user: UserCreate):
global next_id
# 检查邮箱是否已存在
for u in users_db:
if u.email == user.email:
raise HTTPException(status_code=400, detail="Email already registered")
# 创建新用户
new_user = User(id=next_id, name=user.name, email=user.email)
users_db.append(new_user)
next_id += 1
return new_user
@app.get("/users/", response_model=List[User])
def get_users():
return users_db
@app.get("/users/{user_id}", response_model=User)
def get_user(user_id: int):
for user in users_db:
if user.id == user_id:
return user
raise HTTPException(status_code=404, detail="User not found")8. 源码分析与底层机制
8.1 核心组件
8.1.1 BaseModel 实现
BaseModel 是 Pydantic 的核心类,负责模型的创建、验证和序列化。其主要功能包括:
- 字段定义:通过类型提示定义字段
- 验证逻辑:处理数据验证和类型转换
- 序列化:将模型实例转换为字典或 JSON
- 反序列化:将字典或 JSON 转换为模型实例
8.1.2 BaseModel 核心实现原理
BaseModel 的实现基于以下核心原理:
- 元类机制:使用元类
ModelMetaclass来处理模型的创建过程,包括字段提取、验证器注册等 - 字段系统:通过
FieldInfo存储字段的配置信息,包括默认值、验证规则等 - 验证系统:使用
Validator类处理字段和模型级别的验证 - 序列化系统:使用
Serializer类处理模型实例的序列化 - 类型系统:利用 Python 的类型提示系统,结合
TypeAdapter进行类型转换和验证
8.1.3 BaseModel 主要方法分析
8.1.3.1 __init__ 方法
__init__ 方法是模型实例创建的入口,负责:
- 接收输入数据
- 调用验证逻辑
- 初始化模型实例
# 简化的 __init__ 实现逻辑
def __init__(self, **data):
# 验证输入数据
validated_data = self.__pydantic_validator__.validate_python(data)
# 初始化实例属性
for name, value in validated_data.items():
setattr(self, name, value)
# 调用生命周期钩子
self.model_post_init(None)8.1.3.2 model_validate 方法
model_validate 方法是 Pydantic V2 的核心验证方法,负责:
- 接收任意对象作为输入
- 调用验证器进行验证
- 返回验证后的模型实例
8.1.3.3 model_dump 方法
model_dump 方法负责将模型实例转换为字典:
- 收集模型实例的所有字段值
- 根据配置处理字段(排除、包含、别名等)
- 转换字段值为 Python 原生类型
- 返回序列化后的字典
8.1.3.4 model_post_init 方法
model_post_init 是模型的生命周期钩子,在模型初始化后执行:
- 可以在子类中重写,实现自定义初始化逻辑
- 接收验证上下文作为参数
- 用于数据预处理、依赖注入等场景
8.1.4 BaseModel 性能优化
Pydantic V2 通过以下方式优化 BaseModel 的性能:
- 缓存机制:缓存验证器和序列化器,避免重复计算
- 代码生成:使用 Rust 实现核心验证逻辑,提高性能
- 惰性验证:仅在需要时进行验证,减少不必要的计算
- 内存优化:优化内存使用,减少对象创建
8.1.4.1 示例:自定义 BaseModel 子类
from pydantic import BaseModel, Field
class CustomBaseModel(BaseModel):
"""自定义基础模型"""
def model_post_init(self, __context):
"""初始化后处理"""
# 自定义初始化逻辑
print(f"初始化 {self.__class__.__name__} 实例")
class User(CustomBaseModel):
id: int
name: str
email: str = Field(..., description="用户邮箱")
# 使用自定义基础模型
user = User(id=1, name="Alice", email="alice@example.com")
print(user)8.1.4.2 Field 机制
Field 函数用于配置字段的各种属性,如默认值、验证规则、描述等。其实现原理是:
- 接收各种参数,如
default、ge、le等 - 返回一个特殊的标记对象,包含字段的配置信息
- 在模型创建时,Pydantic 会处理这些标记对象,设置字段的属性
8.1.4.3 Validator 系统
Pydantic 的验证器系统包括:
- 字段验证器:使用
@field_validator装饰器定义,对单个字段进行验证 - 模型验证器:使用
@model_validator装饰器定义,对整个模型进行验证 - 验证流程:按顺序执行验证器,收集验证错误
8.1.4.4 Serializer 实现
Pydantic 的序列化器负责将模型实例转换为字典或 JSON:
- model_dump:将模型实例转换为字典
- model_dump_json:将模型实例转换为 JSON 字符串
- 序列化配置:通过
model_config控制序列化行为
8.2 类型系统
8.2.1 类型提示处理
Pydantic 使用 Python 的类型提示系统来定义字段类型:
- 支持基本类型:
int、float、str、bool - 支持容器类型:
list、dict、tuple、set - 支持泛型类型:
List、Dict、Optional、Union - 支持自定义类型:通过继承
BaseModel创建
8.2.2 类型转换机制
Pydantic 会自动进行类型转换,确保输入数据符合字段类型:
- 字符串转数字:
"123"→123 - 字符串转布尔值:
"true"→True - 列表转元组:
[1, 2, 3]→(1, 2, 3) - 字典转模型:
{"id": 1, "name": "Alice"}→User(id=1, name="Alice")
8.2.3 泛型支持
Pydantic 支持泛型类型,通过 Generic 和 TypeVar 实现:
- 定义泛型模型:
class PaginatedResponse(BaseModel, Generic[T]) - 使用泛型模型:
PaginatedResponse[User] - 泛型类型推断:自动推断泛型参数的类型
8.2.4 联合类型处理
Pydantic 支持联合类型,使用 Union 实现:
- 定义联合类型:
id: Union[int, str] - 类型验证:尝试按顺序匹配联合类型中的每个类型
- 类型转换:将输入数据转换为第一个匹配的类型
8.3 模式生成
8.3.1 JSON Schema 生成
Pydantic 可以生成 JSON Schema,用于 API 文档和数据验证:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
email: str
# 生成 JSON Schema
schema = User.model_json_schema()
print(schema)8.3.2 模式验证
使用生成的 JSON Schema 可以验证数据:
import json
from jsonschema import validate
# 生成 JSON Schema
schema = User.model_json_schema()
# 验证数据
data = {"id": 1, "name": "Alice", "email": "alice@example.com"}
try:
validate(instance=data, schema=schema)
print("数据验证通过")
except Exception as e:
print(f"数据验证失败: {e}")8.3.3 模式扩展
可以通过 json_schema_extra 扩展 JSON Schema:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
model_config = {
"json_schema_extra": {
"examples": [
{
"id": 1,
"name": "Alice"
}
]
}
}
print(User.model_json_schema())9.安全最佳实践
Pydantic 模型在处理用户输入时,需要注意以下安全最佳实践:
9.1 输入验证
始终对所有用户输入进行严格验证,避免注入攻击:
from pydantic import BaseModel, Field
class UserInput(BaseModel):
# 严格验证字符串长度
username: str = Field(..., min_length=3, max_length=50)
# 验证邮箱格式
email: str = Field(..., pattern=r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$')
# 验证密码强度
password: str = Field(..., min_length=8)9.2 敏感数据处理
避免在模型中直接存储敏感数据,或使用适当的处理方式:
from pydantic import BaseModel, Field
from typing import Optional
class User(BaseModel):
id: int
username: str
# 敏感字段,序列化时排除
password: str = Field(..., exclude=True)
# 可选的敏感字段
api_key: Optional[str] = Field(None, exclude=True)
# 创建用户实例
user = User(id=1, username="alice", password="secret123", api_key="key123")
# 序列化时不会包含敏感字段
user_dict = user.model_dump()
print(user_dict) # 输出: {'id': 1, 'username': 'alice'}9.3 避免代码注入
使用 Literal 类型限制输入值的范围,避免代码注入:
from pydantic import BaseModel
from typing import Literal
class Action(BaseModel):
# 限制操作类型
action_type: Literal["create", "update", "delete"]
resource_id: int
# 只有指定的操作类型是有效的
valid_action = Action(action_type="create", resource_id=1)
# 无效的操作类型会触发验证错误
try:
invalid_action = Action(action_type="inject", resource_id=1)
except Exception as e:
print(e)9.4 防止 XSS 攻击
对用户输入进行适当的转义和验证,防止跨站脚本攻击:
from pydantic import BaseModel, field_validator
import html
class Comment(BaseModel):
content: str
author: str
@field_validator('content', 'author')
@classmethod
def sanitize_input(cls, v):
# 转义 HTML 特殊字符
return html.escape(v)
# 输入会被自动转义
comment = Comment(content="<script>alert('XSS')</script>", author="hacker")
print(comment.content) # 输出: <script>alert('XSS')</script>9.5 安全的配置管理
使用 Pydantic 管理配置时,注意保护敏感配置:
from pydantic_settings import BaseSettings
from typing import Optional
class Settings(BaseSettings):
# 公开配置
app_name: str = "My App"
debug: bool = False
# 敏感配置,从环境变量加载
database_url: str
api_key: str
class Config:
env_file = ".env"
# 确保敏感配置不会被意外序列化
fields = {
"database_url": {"exclude": True},
"api_key": {"exclude": True}
}
# 加载配置
settings = Settings()
# 序列化时不会包含敏感配置
settings_dict = settings.model_dump()
print(settings_dict) # 输出: {'app_name': 'My App', 'debug': False}9.6 类型安全
使用 Pydantic 的类型系统确保类型安全,避免类型相关的安全问题:
from pydantic import BaseModel
from typing import List, Optional
class Product(BaseModel):
id: int
name: str
price: float
tags: List[str] = []
# 类型安全的输入处理
def process_product(product: Product):
# 可以安全地使用 product 的属性
return f"Product {product.name} costs ${product.price}"
# 类型错误会在验证阶段被捕获
try:
product = Product(id="not-an-int", name="Laptop", price=999.99)
except Exception as e:
print(e)10 性能优化
10.1 模型缓存
- 缓存模型实例:对于重复使用的模型实例,使用缓存
- 缓存验证结果:对于重复验证的相同数据,使用缓存
10.2 验证器优化
- 减少验证器数量:只添加必要的验证器
- 优化验证逻辑:避免复杂的验证逻辑
- 使用内置验证器:优先使用内置验证器,它们通常更快
10.3 序列化性能
- 减少序列化字段:只序列化必要的字段
- 使用
exclude_unset:只序列化已设置的字段 - 使用
model_dump:对于内部使用,使用model_dump而不是model_dump_json
10.4 内存使用优化
- 减少嵌套层级:避免深度嵌套的模型结构
- 使用
frozen模型:对于不需要修改的模型,使用frozen=True - 清理不再使用的模型实例:及时清理不再使用的模型实例
11 设计模式
11.1 数据模型设计
- 单一职责:每个模型只负责一个功能
- 字段命名:使用 snake_case 命名法
- 验证规则:合理设置验证规则,避免过度验证
- 默认值:为可选字段设置合理的默认值
11.2 验证逻辑分离
- 字段验证:使用
@field_validator验证单个字段 - 模型验证:使用
@model_validator验证整个模型 - 业务逻辑:将业务逻辑与验证逻辑分离
11.3 序列化策略
- 字段选择:使用
include和exclude控制序列化字段 - 别名:使用
alias设置字段的 JSON 名称 - 自定义序列化:实现
__str__和__repr__方法
11.4 错误处理统一
- 错误信息:提供清晰、具体的错误信息
- 错误处理:统一处理验证错误
- 日志记录:记录验证错误,便于调试
12 FastAPI 集成最佳实践
12.1 路径参数验证
from fastapi import FastAPI, Path
from pydantic import BaseModel
app = FastAPI()
@app.get("/items/{item_id}")
def read_item(item_id: int = Path(..., ge=1, description="Item ID")):
return {"item_id": item_id}12.2 查询参数验证
from fastapi import FastAPI, Query
from pydantic import BaseModel
from typing import Optional
app = FastAPI()
@app.get("/items/")
def read_items(
skip: int = Query(0, ge=0, description="Skip items"),
limit: int = Query(10, ge=1, le=100, description="Limit items")
):
return {"skip": skip, "limit": limit}12.3 请求体验证
from fastapi import FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str = Field(..., min_length=1, description="Item name")
price: float = Field(..., gt=0, description="Item price")
description: Optional[str] = Field(None, max_length=1000, description="Item description")
@app.post("/items/")
def create_item(item: Item):
return {"item": item}12.4 响应模型优化
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List
app = FastAPI()
class ItemBase(BaseModel):
name: str
price: float
class ItemCreate(ItemBase):
description: str
class Item(ItemBase):
id: int
@app.post("/items/", response_model=Item)
def create_item(item: ItemCreate):
# 处理创建逻辑
return Item(id=1, name=item.name, price=item.price)
@app.get("/items/", response_model=List[Item])
def get_items():
# 处理查询逻辑
return [Item(id=1, name="Item 1", price=10.0)]13. 高级特性与扩展
13.1 国际化支持
Pydantic V2 本身不内置国际化(i18n)支持,但可以通过自定义错误消息和标准 Python 国际化库来实现多语言支持。
13.1.1 自定义错误消息
from pydantic import BaseModel, Field
class User(BaseModel):
age: int = Field(
...,
ge=18,
error_messages={
'ge': '年龄必须大于等于18岁',
'type': '年龄必须是整数'
}
)
# 验证失败时会使用自定义的错误消息
try:
user = User(age=17)
except Exception as e:
print(e)13.1.2 使用标准 Python 国际化库
from pydantic import BaseModel, Field
import gettext
import os
# 设置语言环境
os.environ['LANG'] = 'zh_CN.UTF-8'
# 安装翻译
trans = gettext.translation('myapp', './locales', fallback=True)
trans.install()
_
class User(BaseModel):
age: int = Field(
...,
ge=18,
error_messages={
'ge': _('年龄必须大于等于18岁'),
'type': _('年龄必须是整数')
}
)
# 验证失败时会使用翻译后的错误消息
try:
user = User(age=17)
except Exception as e:
print(e)13.1.3 多语言错误消息管理
from pydantic import BaseModel, Field
import gettext
import os
# 语言切换函数
def setup_i18n(language='zh_CN'):
os.environ['LANG'] = language
trans = gettext.translation('myapp', './locales', languages=[language], fallback=True)
trans.install()
return trans
# 设置为中文
setup_i18n('zh_CN')
_
class User(BaseModel):
age: int = Field(
...,
ge=18,
error_messages={
'ge': _('年龄必须大于等于18岁'),
'type': _('年龄必须是整数')
}
)
# 验证失败时会使用中文错误消息
try:
user = User(age=17)
except Exception as e:
print(e)
# 切换为英文
setup_i18n('en_US')
_
class UserEn(BaseModel):
age: int = Field(
...,
ge=18,
error_messages={
'ge': _('Age must be at least 18'),
'type': _('Age must be an integer')
}
)
# 验证失败时会使用英文错误消息
try:
user = UserEn(age=17)
except Exception as e:
print(e)13.2 计算字段
13.2.1 基本使用
计算字段是 Pydantic V2 的新特性,用于定义动态计算的字段:
from pydantic import BaseModel, computed_field
from datetime import datetime
class User(BaseModel):
id: int
name: str
birth_date: datetime
@computed_field
@property
def age(self) -> int:
return (datetime.utcnow() - self.birth_date).days // 365
# 创建实例
from datetime import datetime, timedelta
birth_date = datetime.utcnow() - timedelta(days=365 * 30)
user = User(id=1, name="Alice", birth_date=birth_date)
print(user.age)
# 输出: 3013.2.2 缓存策略
计算字段支持缓存策略:
from pydantic import BaseModel, computed_field
class Product(BaseModel):
price: float
tax_rate: float = 0.1
@computed_field(cache=True)
@property
def total_price(self) -> float:
print("计算总价...")
return self.price * (1 + self.tax_rate)
# 创建实例
product = Product(price=100)
print(product.total_price)
# 输出: 计算总价...
# 输出: 110.0
# 再次访问,使用缓存
print(product.total_price)
# 输出: 110.013.2.3 依赖关系
计算字段可以依赖其他计算字段:
from pydantic import BaseModel, computed_field
class Order(BaseModel):
quantity: int
unit_price: float
discount: float = 0
@computed_field
@property
def subtotal(self) -> float:
return self.quantity * self.unit_price
@computed_field
@property
def total(self) -> float:
return self.subtotal * (1 - self.discount)
# 创建实例
order = Order(quantity=2, unit_price=100, discount=0.1)
print(order.subtotal)
# 输出: 200.0
print(order.total)
# 输出: 180.013.3 生命周期钩子
13.3.1 model_post_init
model_post_init 是 Pydantic V2 的生命周期钩子,在模型初始化后执行:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
email: str
def model_post_init(self, __context) -> None:
# 初始化后处理
self.email = self.email.lower()
# 创建实例
user = User(id=1, name="Alice", email="ALICE@EXAMPLE.COM")
print(user.email)
# 输出: alice@example.com13.3.2 自定义钩子
可以定义自定义的生命周期钩子:
from pydantic import BaseModel
class BaseEntity(BaseModel):
id: int
created_at: str
def model_post_init(self, __context) -> None:
# 通用初始化逻辑
print(f"初始化实体 {self.id}")
class User(BaseEntity):
name: str
email: str
def model_post_init(self, __context) -> None:
# 调用父类的初始化逻辑
super().model_post_init(__context)
# 子类特定的初始化逻辑
print(f"初始化用户 {self.name}")
# 创建实例
user = User(id=1, created_at="2023-01-01", name="Alice", email="alice@example.com")13.3.3 应用场景
生命周期钩子的应用场景包括:
- 数据预处理:在模型初始化后对数据进行预处理
- 依赖注入:在模型初始化时注入依赖
- 状态管理:在模型初始化时设置初始状态
- 数据转换:在模型初始化时转换数据格式
13.4 插件与扩展
13.4.1 自定义验证器
可以创建自定义验证器来扩展 Pydantic 的验证功能:
from pydantic import BaseModel, field_validator
class User(BaseModel):
email: str
password: str
@field_validator('email')
@classmethod
def validate_email(cls, v):
if '@' not in v:
raise ValueError('邮箱格式不正确')
return v
@field_validator('password')
@classmethod
def validate_password(cls, v):
if len(v) < 6:
raise ValueError('密码长度至少为6位')
return v13.4.2 序列化扩展
可以自定义序列化逻辑:
from pydantic import BaseModel
from datetime import datetime
class User(BaseModel):
id: int
name: str
created_at: datetime
def model_dump(self, **kwargs):
data = super().model_dump(**kwargs)
# 自定义序列化逻辑
data['created_at'] = self.created_at.strftime('%Y-%m-%d %H:%M:%S')
return data
user = User(id=1, name="Alice", created_at=datetime.utcnow())
print(user.model_dump())13.4.3 类型适配器
使用 TypeAdapter 可以创建自定义类型适配器:
from pydantic import TypeAdapter
from typing import List
# 创建类型适配器
adapter = TypeAdapter(List[int])
# 验证数据
data = [1, 2, 3, "4"]
result = adapter.validate_python(data)
print(result)
# 输出: [1, 2, 3, 4]14. 附录
14.1 常用字段类型参考
| 类型 | 描述 | 示例 |
|---|---|---|
| int | 整数 | id: int |
| float | 浮点数 | price: float |
| str | 字符串 | name: str |
| bool | 布尔值 | is_active: bool |
| Optional[T] | 可选类型 | age: Optional[int] |
| List[T] | 列表 | tags: List[str] |
| Dict[K, V] | 字典 | metadata: Dict[str, Any] |
| Tuple[T1, T2] | 元组 | coordinates: Tuple[float, float] |
| Set[T] | 集合 | roles: Set[str] |
| Union[T1, T2] | 联合类型 | id: Union[int, str] |
| Literal[T] | 字面量类型 | status: Literal["active", "inactive"] |
14.2 验证器装饰器参考
| 装饰器 | 描述 | 示例 |
|---|---|---|
| @field_validator | 字段验证器 | @field_validator('email') |
| @model_validator | 模型验证器 | @model_validator(mode='after') |
14.3 配置选项参考
| 配置选项 | 类型 | 描述 | 示例 |
|---|---|---|---|
| extra | str | 额外字段处理策略 | "forbid", "allow", "ignore" |
| frozen | bool | 是否为不可变模型 | True, False |
| populate_by_name | bool | 是否通过字段名填充 | True, False |
| json_schema_extra | dict | JSON Schema 额外信息 | {"examples": [...]} |
14.4 错误类型参考
| 错误类型 | 描述 |
|---|---|
| value_error | 值错误 |
| type_error | 类型错误 |
| missing | 缺少字段 |
| extra | 额外字段 |
| constraint | 约束错误 |
14.5 核心方法参数参考
| 方法 | 参数 | 描述 |
|---|---|---|
| model_validate | obj | 要验证的对象 |
| strict | 是否严格验证 | |
| model_validate_json | json_data | JSON 字符串 |
| strict | 是否严格验证 | |
| model_dump | exclude | 排除的字段 |
| include | 包含的字段 | |
| by_alias | 是否使用别名 | |
| exclude_unset | 是否排除未设置的字段 | |
| model_dump_json | exclude | 排除的字段 |
| include | 包含的字段 | |
| by_alias | 是否使用别名 | |
| exclude_unset | 是否排除未设置的字段 | |
| indent | JSON 缩进 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)