【MICCAI2025】解决多专家标注分歧:形态学强化扩散模型 MoDiff 深度解析

【MICCAI2025】解决多专家标注分歧:形态学强化扩散模型 MoDiff 深度解析
在医疗影像分割领域,我们经常面临一个非常现实的困境:“模糊性”(Ambiguity)。同一张肺部 CT 结节或者脑部 MRI 病灶,四个不同的资深医生可能会画出四个不一样边界的轮廓 。这种“金标准”本身就不唯一的情况,让 AI 模型在学习时无所适从。
为了解决这个问题,基于扩散模型(Diffusion Models)的概率分割技术应运而生,但它们往往会导致生成的预测结果边缘模糊、形态不一致 。如何让模型既能理解这种“模糊和不确定性”,又能画出清晰、符合人体解剖学形态的边界?这篇发表在MICCAI2025名为 MoDiff 的论文给出了一套极具启发性的解决方案。
1. 研究背景:医疗影像的“薛定谔边界”
医疗影像天生自带模糊属性(设备噪声、低分辨率、组织结构相似等) 。为了应对这种不确定性,以往的研究(如 Probabilistic U-Net 或传统的条件扩散模型)会通过学习概率分布,针对同一张图生成多个不同的分割结果 。
然而,现有的概率分割模型存在两个致命痛点:
(1) 形态一致性差: 扩散模型在反复采样去噪的过程中,容易放飞自我,导致生成的器官或肿瘤边界在不同采样结果间差异过大,甚至违背解剖学常识 。
(2) 标注信息浪费: 以前的模型在训练时,通常是每次从多个医生的标注中**随机抽取一个(One-hot 格式)**作为参考标签。这不仅增加了训练迭代次数,还割裂了多位医生标注间的内在联系 。
2.核心创新:概率标签与形态学强化
为了打破上述僵局,MoDiff(Morphology-Emphasized Diffusion Model)提出了两个维度的底层创新:
创新1: 放弃 One-hot,拥抱“概率标签”: 模型不再随机挑选某一个医生的标注,而是将所有医生的标注叠加求平均,生成一个基于概率分布的连续值标签图 。这让模型一眼就能看出“哪里是医生有共识的绝对病灶,哪里是存在争议的模糊边界”。
创新2: 引入频域过滤与形态学交叉注意力: 构建了两个全新的即插即用模块——**LDF(可学习离散频率滤波器)**和 MCA(基于形态学的交叉注意力网络),在去噪过程中强势注入边界和形态约束 。
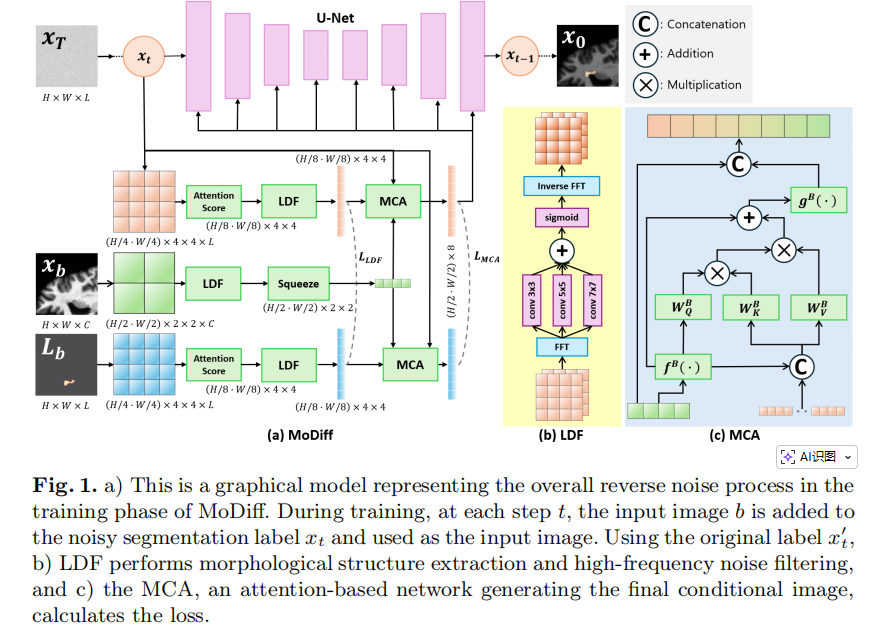
3.模型方法深度解析
3.1 MCA:基于形态学的交叉注意力
医疗影像对比度低,传统的边缘提取算子(如 Canny、Sobel)很难抓准器官轮廓 。MCA 通过交叉注意力机制将“原始清晰图像”的信息注入到“充满噪声的分割图”中。
模型将原图切分成 2×22 \times 22×2 的大 Patch 作为 Query(Q),将带噪的标签图切分成 4×44 \times 44×4 的小 Patch 作为 Key(K)和 Value(V) 。其注意力得分计算公式为:
xt′m=(xtmWq)(xtmWk)⊤d{x_{t}^{\prime}}^{m} = \frac{(x_t^m W_q)(x_t^m W_k)^\top}{\sqrt{d}}xt′m=d(xtmWq)(xtmWk)⊤
请注意!这里作者故意去掉了传统 Transformer 中必备的 Softmax 归一化操作 。为什么?因为 Softmax 的作用是“平滑”,而在带噪的扩散过程中,我们需要的是“锐化”——极致放大真实标签信号与噪声信号的对比度,从而更暴力地剥离噪声 。
3.2 LDF:可学习离散频率滤波器
由于直接在空间域(像素点)去噪容易破坏图像的边缘细节,作者把目光投向了频域。
LDF(yB)=F−1(σ(F(yB)∗H))LDF(y^B) = \mathcal{F}^{-1}(\sigma(\mathcal{F}(y^B) * H))LDF(yB)=F−1(σ(F(yB)∗H))
其中 F\mathcal{F}F 代表快速傅里叶变换 FFT,F−1\mathcal{F}^{-1}F−1 代表逆变换,σ\sigmaσ 是 Sigmoid, HHH 是高频滤波器。这就好比我们修音频时的“高级均衡器(EQ)”。F\mathcal{F}F 把图像从像素画面变成了“声波频率”。随后,模型用一个由 3×33\times33×3、5×55\times55×5、7×77\times77×7 卷积组成的自适应滤波器 HHH(你可以理解为智能降噪旋钮)把干扰的高频噪点压制住,同时保留代表组织边缘的特定高频信息,最后再用 F−1\mathcal{F}^{-1}F−1 变回图像 。
3.3 三管齐下的损失函数 (Loss)
除了扩散模型常规的去噪损失 Lsimple\mathcal{L}_{simple}Lsimple,MoDiff 增加了 LLDF\mathcal{L}_{LDF}LLDF(逼近理想形态学特征)和 LMCA\mathcal{L}_{MCA}LMCA(注意力正则化,防止模型只死盯住某几个 Patch) 。
4.实验结果:在模糊中寻找精准
研究团队在两个极具挑战的模糊医学数据集上进行了测试:LIDC-IDRI(肺结节,12位医生标注)和 MS-MRI(多发性硬化症脑病灶) 。
(1) 精准性与一致性双赢: 在衡量分布差异的 GED、HM-IoU 指标,以及衡量结构相似度的 NCC 和 CI 指标上,MoDiff 全面超越了 cFlow、MOSE、CIMD 以及 CCDM 等 SOTA 概率分割模型 。
(2) 轮廓之美: 定性结果显示,对比其他模型生成的“坑坑洼洼”的边缘,MoDiff 捕捉到的病灶细节更加丰富,边缘更加平滑且符合人体真实解剖结构 。
(3) 传统算子降维打击: 在消融实验中,作者将自研的 LDF 模块与经典的 Canny、Sobel 边缘检测算子进行替换对比,结果证明 LDF 在提取有效边界特征时具有压倒性的优势 。

5.几个问题的思考
问题1:为什么要使用概率标签?
简单来说,这是教 AI 认知世界方式的底层逻辑转变:从“非黑即白”的死板,变成了“接受灰度”的灵活。可以通过一个具体的临床场景来拆解这两种标签的区别。
假设有一张肺结节的 CT 图,请了 4 位顶尖的三甲医院资深影像科医生来勾画结节的轮廓。因为图像边缘很模糊,4 位医生画的圈大小都不完全一样。结节的最中心区域:4 位医生都画进去了。结节的边缘模糊地带只有 2 位医生认为这里是结节,另外 2 位认为这是正常组织。面对 4 位医生的不同标注,传统模型通常会这么做:
(1) 随机抽签(盲盒模式): 模型在第一轮训练时,随机抽了医生 A 的标注(边缘画得大)告诉 AI:“边缘这里是病灶(1)!”;到了第二轮训练,又随机抽了医生 B 的标注(边缘画得小)告诉 AI:“边缘这里不是病灶(0)!”。
(2) 结果: AI 模型直接精神分裂了。对于同一个边缘像素,昨天告诉它是 1,今天告诉它是 0,导致模型在预测边缘时疯狂震荡,最后只能胡乱猜一个均值,给出的轮廓自然“坑坑洼洼”。
MoDiff 的创新是接受模糊的“软标签”,把 4 张标注图叠在一起,算一个平均值 。这样
结节的中心像素, 4 位医生都画了,得分是 4/4=1.04/4 = 1.04/4=1.0。AI 学到这里 100% 是病灶,绝对不能漏掉。
结节的边缘像素,只有 2 位医生画了,得分是 2/4=0.52/4 = 0.52/4=0.5。AI 学到这里有 50% 的概率是病灶,处于争议地带。
远离结节的正常肺部没有医生画,得分是 0/4=0.00/4 = 0.00/4=0.0。AI 学到这里 100% 安全。
医疗影像本身就是充满噪声和伪影的,有些边界连神仙难断。概率标签真实地保留了这种“人类专家的不确定性(Uncertainty)” 。传统方法随机选一个医生的标注,等于浪费了另外 3 位医生的心血。概率标签一次性融合了所有专家的共识,数据利用率达到 100% 。模型再也不会因为每次看到的“标准答案”打架而困惑。它明确知道哪里该笃定(概率接近 1 或 0),哪里该谨慎(概率在 0.5 左右),从而生成更加平滑、符合人体真实解剖形态的预测结果 。
问题2:为什么是向概率标签图 LbL_bLb 加噪,而不是原始图片?
要回答这个问题,需要明确当前 AI 模型的“终极任务”是什么。
(1) 扩散模型的核心逻辑:你想生成什么,就向什么加噪。
如果是“图像生成”任务(比如 Midjourney 根据文字生成一幅画):模型需要无中生有地生成一张原始图片。这时,前向过程是向“原始图片”加噪,直到变成纯噪声;反向过程则是从纯噪声开始,一步步去噪还原出“图片”。如果是“图像分割”任务(比如 MoDiff):我们已经有了完美的“原始医疗图片”(CT 或 MRI),我们不需要去生成它 。我们真正需要模型无中生有生成的是——“病灶的分割标签(Mask)”。
在MoDiff 中,我们希望模型学会一套手艺:“看着原图,画出标签”。于是原图是“提示词”,标签才是“画布”。加噪过程(破坏阶段)拿完美的概率标签图 LbL_bLb(作为 x0x_0x0),向它里面不断注入高斯噪声,直到它变成一堆毫无意义的雪花噪点(xTx_TxT)。去噪过程(生成阶段)模型从这堆雪花噪点(xTx_TxT)开始,试图把它还原回清晰的标签图 x0x_0x0。但如果在毫无提示的情况下盲目去噪,模型不知道画什么。此时,“原始医疗图片 xbx_bxb” 就作为最关键的条件(Condition)被送入模型(通过 MCA 等模块) 。
6.批判性分析
尽管 MoDiff 在处理模糊性标注上交出了亮眼的答卷,但在实际临床落地前,可能有如下几个问题:
(1) 计算效率与推理延迟(致命痛点): 扩散模型的通病在于采样速度慢。MoDiff 的推理时间步长设置为了 T=250T=250T=250 。虽然增加了采样步数带来了精度的提升,但这以牺牲庞大的计算效率为代价 。未来必须引入如 DDIM、DPM-Solver 等更高级的噪声调度策略(Noise Scheduling),或者蒸馏技术,将采样步数压缩到 10 步甚至 5 步以内 。
(2) 硬编码的分块策略泛化性存疑: 在 MCA 模块中,作者固定将原图切分为 2×22 \times 22×2,将标签图切分为 4×44 \times 44×4 。这种硬编码的 Patch 比例在处理 128×128128 \times 128128×128 的小尺寸图像时表现良好,但如果迁移到 1024×10241024 \times 10241024×1024 的高清病理切片或 3D 医疗体素数据时,尺度信息可能会严重失配,需要引入动态自适应的分块机制。
(3) 缺乏多模态融合的深度探索: 论文在 MS-MRI 数据集上提到了包含四种模态(FLAIR、T2 等) ,但模型设计上并未专门针对跨模态特征(如 T1 与 T2 的互补信息)进行深度融合机制的设计。正如作者在 Future Work 中提到的,引入多模态结构(Multimodal structures)将是下一步的重要发力点 。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)