pdd小程序纯算逆向分析(codex版)
pdd小程序与M端逆向分析+AI自动还原纯算
【🏠作者主页】:吴秋霖
【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python与爬虫领域研究与开发工作!
【🌟作者推荐】:对爬虫领域以及JS逆向分析感兴趣的朋友可以关注《爬虫JS逆向实战》《深耕爬虫领域》
未来作者会持续更新所用到、学到、看到的技术知识!包括但不限于:各类验证码突防、爬虫APP与JS逆向分析、RPA自动化、分布式爬虫、Python领域等相关文章
作者声明:文章仅供学习交流与参考!严禁用于任何商业与非法用途!否则由此产生的一切后果均与作者无关!如有侵权,请联系作者本人进行删除!
1. 写在前面
Windows小程序跟M端的话走的是同一套API跟JS加解密防护逻辑,而Mac跟ios上小程序则又是独立的一套(且数据未加密以明文展示)如果是补环境的话稍微耗时有多个JS文件又臭又长,本期为了继续测试验证大模型的逆向分析与算法还原能力,作者在此之前对该小程序的补环境与纯算法还原都进行了研究分析,为了更好的测试验证大模型的能力
在之前的文章中作者有针对逆向场景测试过Cursor跟Claude,感兴趣的小伙伴可以看看: 某网站x-s逆向分析(Cursor补环境版),本期将使用codex5.3来测试一下效果
2. 接口分析
这里我们简单的抓包看看它这个详情的接口headers中有一个经典的anti_content基本很多web站点都有,最新的目前网上教程出来的虽然前缀一样,但基本很少能够适用,抓包可以看到详情的数据是经过加密的,如下所示:
anti_content这个参数在M端目前生成方式有部分字段参与了计算并对一些环境相关的数组进行了运算(这里感兴趣可以自己去研究,不多赘述),下面是M端最新纯算(供参考),如下所示:
import json
import zlib
import time
import random
# 环境数据各段长度
ENV_SEGMENT_LENGTHS: List[int] = [...]
BASE64_ALPHABET = "编码表"
ANTI_CONTENT_PREFIX = "0as"
ANTI_CONTENT_MAGIC_SUFFIX = [...]
PAYLOAD_HEADER = [...]
def _timestamp_to_bytes() -> List[int]:
binary = "0000000" + bin(abs(int(time.time() * 1000)))[2:]
num_bytes = -(-len(binary) // 8)
return [int(binary[i * 8 : (i + 1) * 8], 2) for i in range(num_bytes)]
def _build_env_payload(
request_url: str,
user_agent: str,
nano_fp: str,
pdduid: str,
api_uid: str,
pdd_vds: str,
) -> List[int]:
param_concat = "".join(
s or ""
for s in (request_url, user_agent, nano_fp, pdduid, api_uid, pdd_vds)
)
param_bytes = list(param_concat.encode("utf-8")) if param_concat else []
stream_pos = 0
segments: List[List[int]] = []
for seg_index, seg_len in enumerate(ENV_SEGMENT_LENGTHS):
if seg_len <= 0:
segments.append([])
continue
if seg_index == 0:
segment = _timestamp_to_bytes()
if len(segment) < seg_len:
segment.extend(random.randint(0, 255) for _ in range(seg_len - len(segment)))
else:
segment = segment[:seg_len]
else:
segment = []
for _ in range(seg_len):
if stream_pos < len(param_bytes):
segment.append(param_bytes[stream_pos])
stream_pos += 1
else:
segment.append(random.randint(0, 255))
segments.append(segment)
return [b for seg in segments for b in seg]
def _base64_budget(index: int, threshold: int) -> int:
if index == 64:
return 64
if index == 63:
return threshold
if index >= threshold:
return index + 1
return index
def _custom_base64_encode(
data: List[int],
index_transform: Optional[Callable[[int, int], int]] = None,
) -> str:
alphabet = list(BASE64_ALPHABET) + ["="]
threshold = -1
if index_transform is not None:
threshold = int(0.1 * 64)
result = []
i = 0
while i < len(data):
b1 = data[i]
b2 = data[i + 1] if i + 1 < len(data) else None
b3 = data[i + 2] if i + 2 < len(data) else None
idx0 = b1 >> 2
idx1 = (b1 & 3) << 4
idx2 = 64
idx3 = 64
if b2 is not None:
idx1 |= b2 >> 4
idx2 = (b2 & 15) << 2
if b3 is not None:
idx2 |= b3 >> 6
idx3 = b3 & 63
if index_transform is not None:
idx0 = index_transform(idx0, threshold)
idx1 = index_transform(idx1, threshold)
idx2 = index_transform(idx2, threshold)
idx3 = index_transform(idx3, threshold)
result.append(alphabet[idx0] + alphabet[idx1] + alphabet[idx2] + alphabet[idx3])
i += 3
encoded = "".join(result).replace("=", "")
if threshold >= 0 and threshold < len(BASE64_ALPHABET):
encoded += BASE64_ALPHABET[threshold]
return encoded
def _encode_length_16bit(length: int) -> List[int]:
if length == 0:
return [0, 0]
if length <= 255:
return [0, length]
bits = bin(length)[2:].zfill(16)
return [int(bits[:8], 2), int(bits[8:16], 2)]
def build_anti_content(
request_url: str,
user_agent: str,
api_uid: str,
pdduid: str,
nano_fp: str,
pdd_vds: str,
) -> str:
env_payload = _build_env_payload(
request_url, user_agent, nano_fp, pdduid, api_uid, pdd_vds
)
length_bytes = _encode_length_16bit(len(env_payload))
payload = bytes(PAYLOAD_HEADER + length_bytes + env_payload)
compressed = list(zlib.compress(payload)) + ANTI_CONTENT_MAGIC_SUFFIX
encoded = _custom_base64_encode(compressed, _base64_budget)
return ANTI_CONTENT_PREFIX + encoded
小程序端的anti_content参数纯算还原如下所示(供参考):
import random
import time
import zlib
from dataclasses import dataclass, field
from typing import List, Optional
RANDOM_ALPHABET = "" # 自行获取
ENCODE_ALPHABET = "" # 自行获取
TOKEN_PREFIX = "0as"
LOCATION_INFO_HASH = [139, 160, 51, 7]
F_SUFFIX_BYTES = [150, 55, 164, 240]
def _now_ms() -> int:
return int(time.time() * 1000)
def _utf8_bytes(text: str) -> List[int]:
return list(text.encode("utf-8"))
def _char_code(text: str) -> List[int]:
raw = _utf8_bytes(text)
ln = len(raw)
if ln <= 255:
return [0, ln] + raw
return [(ln >> 8) & 0xFF, ln & 0xFF] + raw
def _sc(text: str) -> List[int]:
return _char_code(text)[2:]
def _es(text: str) -> List[int]:
cut = (text or "")[:255]
raw = _sc(cut)
return [len(raw)] + raw
def _va(num: int) -> List[int]:
n = int(num)
if n < 0:
n = 0
out: List[int] = []
while True:
b = n & 0x7F
n >>= 7
if n:
out.append(b | 0x80)
else:
out.append(b)
break
return out
def _nc(num: int) -> List[int]:
n = abs(int(num))
bits = bin(n)[2:]
if not bits:
return [0]
pad = (8 - len(bits) % 8) % 8
bits = ("0" * pad) + bits
return [int(bits[i : i + 8], 2) for i in range(0, len(bits), 8)]
def _crc32(text: str) -> int:
return zlib.crc32(text.encode("utf-8")) & 0xFFFFFFFF
def _pbc(text: str = "") -> List[int]:
raw = _nc(_crc32((text or "").replace(" ", "")))
if len(raw) >= 4:
return raw
return ([0] * (4 - len(raw))) + raw
def _ek(tag: int, payload=None) -> List[int]:
if not tag:
return []
data: List[int] = []
size = 0
if payload != "":
if isinstance(payload, list):
data = payload
size = len(payload)
elif isinstance(payload, str):
data = _sc(payload)
size = len(data)
elif isinstance(payload, (int, float)):
data = _nc(int(payload))
size = len(data)
head = (tag << 3) | (size if 0 < size <= 7 else 0)
out = [head]
if size > 7:
out.extend(_va(size))
out.extend(data)
return out
def _budget(idx: int, salt: int) -> int:
if idx == 64:
return 64
if idx >= 63:
return salt
return idx if idx < salt else (idx + 1)
def _encode_custom(data: bytes, rng: random.Random, use_budget: bool) -> str:
chars = list(ENCODE_ALPHABET) + ["="]
salt = int(rng.random() * 64) if use_budget else -1
out: List[str] = []
i = 0
ln = len(data)
while i < ln:
b1 = data[i]
i += 1
b2 = data[i] if i < ln else None
i += 1 if i < ln else 0
b3 = data[i] if i < ln else None
i += 1 if i < ln else 0
s1 = (b1 >> 2) & 0x3F
s2 = ((b1 & 0x03) << 4) | (((b2 or 0) >> 4) & 0x0F)
s3 = 64 if b2 is None else (((b2 & 0x0F) << 2) | (((b3 or 0) >> 6) & 0x03))
s4 = 64 if b3 is None else (b3 & 0x3F)
if use_budget:
s1 = _budget(s1, salt)
s2 = _budget(s2, salt)
s3 = _budget(s3, salt)
s4 = _budget(s4, salt)
out.extend([chars[s1], chars[s2], chars[s3], chars[s4]])
token = "".join(out).replace("=", "")
if use_budget:
token += chars[salt]
return token
def _right_pad(text: str, ln: int, ch: str = " ") -> str:
if len(text) >= ln:
return text
return text + (ch * (ln - len(text)))
@dataclass
class AntiContentGenerator:
href: str = "" # 自行填写
port: str = ""
screen_width: int = 1536
screen_height: int = 834
user_agent: str = # 自行填写
visibility_state: str = "visible"
rng: random.Random = field(default_factory=random.Random)
_counter: int = 0
_client_base_ms: int = field(default_factory=_now_ms)
_server_time_ms: int = field(default_factory=_now_ms)
_init_ms: int = field(default_factory=_now_ms)
_nano_value: str = ""
def __post_init__(self) -> None:
self._nano_value = self._gen_nano_value(self._init_ms)
def update_server_time(self, ts_ms: Optional[int] = None) -> None:
self._client_base_ms = _now_ms()
self._server_time_ms = int(ts_ms if ts_ms is not None else _now_ms())
def _rand_from_64(self, ln: int = 21) -> str:
return "".join(RANDOM_ALPHABET[int(self.rng.random() * 64)] for _ in range(ln))
def _gen_nano_value(self, ts_ms: int) -> str:
sec10 = str(int(ts_ms))[:10]
rnd = self._rand_from_64(21)
checksum = sum(ord(ch) for ch in (sec10 + "_" + rnd)) % 1000
tail = _right_pad(str(checksum), 3, "0")
encoded = _encode_custom((sec10 + tail).encode("latin1"), self.rng, use_budget=False)
return encoded.replace("=", "") + "_" + rnd
def _pack_x(self) -> List[int]:
out = _ek(7)
url = (self.href or "")[:128]
if not url and not self.port:
return out + LOCATION_INFO_HASH
s = _sc(url)
out.extend(_va(len(s)))
out.extend(s)
out.extend(_va(len(self.port)))
if self.port:
out.extend(_sc(self.port))
out.extend(LOCATION_INFO_HASH)
return out
def _pack_z(self) -> List[int]:
return _ek(8) + _va(self.screen_width) + _va(self.screen_height)
def _pack_g(self) -> List[int]:
n = int(self.rng.random() * (2**52)) + int(self.rng.random() * ((2**30) + 1))
return _ek(9, f"{n}-{self._server_time_ms}")
def _pack_l(self) -> List[int]:
return _ek(10) + _va(1179648)
def _pack_k(self) -> List[int]:
return _ek(11) + _pbc(self.href)
def _pack_t(self) -> List[int]:
return _ek(12, "y")
def _pack_b(self) -> List[int]:
return _ek(13, "y")
def _pack_v(self) -> List[int]:
return _ek(14, _now_ms() - self._client_base_ms)
def _pack_j(self) -> List[int]:
if not self.user_agent:
return []
return _ek(15, self.user_agent)
def _pack_n(self) -> List[List[int]]:
return [_ek(16, self._nano_value)]
def _pack_i(self) -> List[int]:
return []
def _pack_a(self) -> List[int]:
return []
def _pack_y_cookie(self) -> List[int]:
return []
def _pack_u(self) -> List[int]:
return _ek(21, self._counter)
def _pack_z_time(self) -> List[int]:
return _ek(22, self._init_ms)
def _pack_d(self) -> List[int]:
return []
def _pack_e(self) -> List[int]:
return _ek(26) + _va(0)
def _pack_j_visible(self) -> List[int]:
vis = 1 if self.visibility_state == "visible" else 0
return _ek(27) + _va(vis)
def _pack_f_media(self) -> List[int]:
return _ek(28) + _va(3) + _va(3)
def get_anti_content(self, server_time_ms: Optional[int] = None) -> str:
self.update_server_time(server_time_ms)
self._counter += 1
e: List[int] = []
e.extend(self._pack_x())
e.extend(self._pack_z())
e.extend(self._pack_g())
e.extend(self._pack_l())
e.extend(self._pack_k())
e.extend(self._pack_t())
e.extend(self._pack_b())
e.extend(self._pack_v())
e.extend(self._pack_j())
for item in self._pack_n():
e.extend(item)
e.extend(self._pack_i())
e.extend(self._pack_a())
e.extend(self._pack_y_cookie())
e.extend(self._pack_u())
e.extend(self._pack_z_time())
e.extend(self._pack_d())
e.extend(self._pack_e())
e.extend(self._pack_j_visible())
e.extend(self._pack_f_media())
packet = bytes(self._build_packet_from_payload(e))
compressed = zlib.compress(packet)
raw = compressed + bytes(F_SUFFIX_BYTES)
return TOKEN_PREFIX + _encode_custom(raw, self.rng, use_budget=True)
def _build_packet_from_payload(self, e: List[int]) -> List[int]:
ln = len(e)
if ln == 0:
c = [0, 0]
elif ln <= 255:
c = [0, ln]
else:
bits = bin(ln)[2:].rjust(16, "0")
c = [int(bits[:8], 2), int(bits[8:], 2)]
return [2, 1, 0, 0] + c + e
def get_anti_content(server_time_ms: Optional[int] = None) -> str:
return AntiContentGenerator().get_anti_content(server_time_ms)
这两个参数感觉不是太强制校验,就算空也是能拿到结果的。但是多了以后不行会出现异常,具体可以自己研究测试
3. 纯算还原
这里来说一下解密,由于两端的风控都很高,调试的账号目前出现了售罄,暂时无法复现之前的调试并给出贴图,直接把之前拿下来的JS针对性讲解一下,核心就是第一个生成原始对称密钥rawKey(32字节)跟随机跟rawIV(16字节)后用同一把RSA公钥对其进行加密得到encryptedData,核心逻辑(包含解密)均被包装到了一个自定义的VM中执行,配置如下所示:
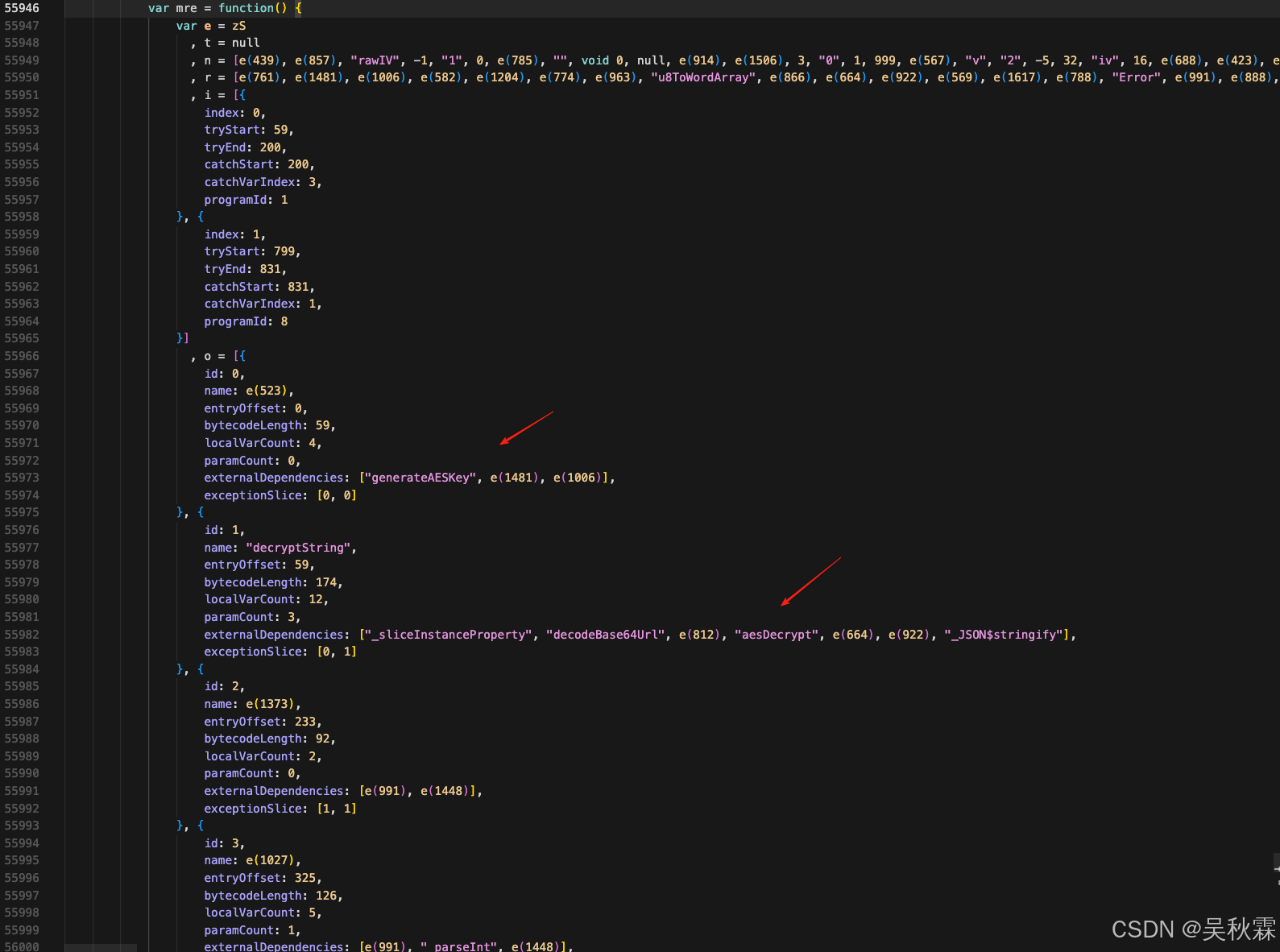
其中e(523)通过混淆依赖生成generateAESKey|generateIV|rsaEncrypt,VM在执行字节码时通过externalDependencies调用!最终胜出随机的24字节密钥、以及16字节IV、然后基于publicKey做一个rsaEncrypt得到encryptedData(即请求参数中的csr_risk_token),请求需要生成后一致请求再同步解密才有效,如下所示:
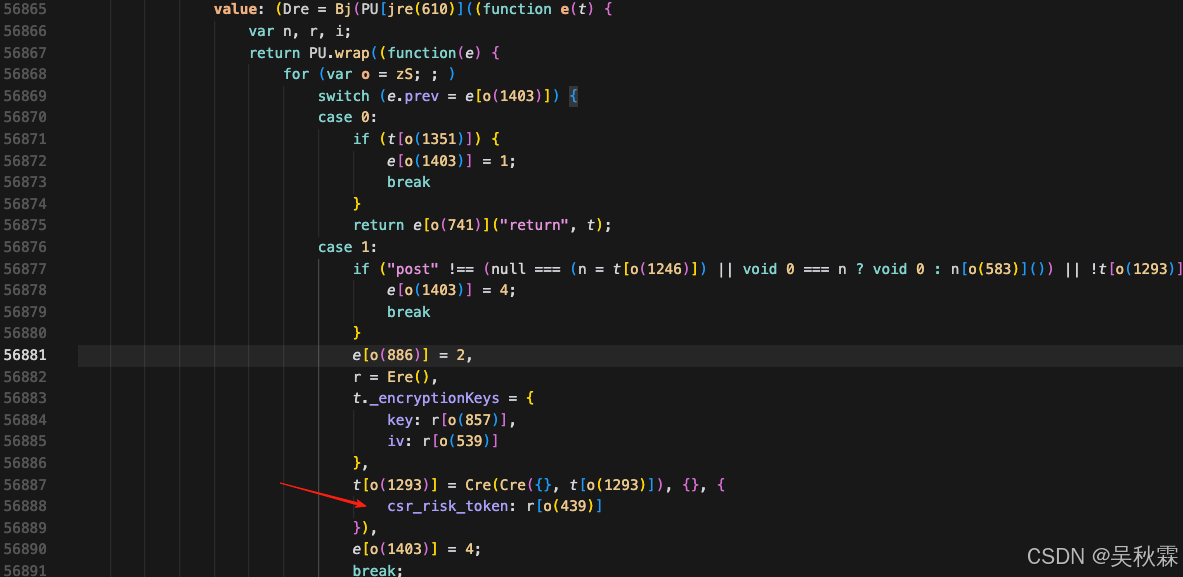

generateAESKey动态采样结果表现为固定模式v2 + 13位毫秒时间戳 + "000" + 14位字符,JS补环境导出调用示例如下:
v217725983698350002EJmbbh4T6394A
generateIV通过采样Date.now() 与输出 rawIV 对照,满足如下:
rawIV = sha256(str(timestamp_ms) + "iv").hexdigest()[:16]
rsaEncrypt底层是JSEncrypt包装,公钥在JS源码的数组字符串中可以看到,纯算分析的时候作者测试了Cursor不能很智能的帮助你主动抽取,只能是自己提取(并且还原纯算的过程需要自己多次提示词纠错才能够指导其正确完成还原)
这里根据分析先使用Python实现密钥相关的信息生成算法,实现代码如下所示:
import time
import secrets
import hashlib
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_v1_5
# 自行获取
NANOID_ALPHABET = ""
# 自行获取
PDD_RSA_PUBLIC_KEY = b"""-----BEGIN PUBLIC KEY----- -----END PUBLIC KEY-----"""
_RSA_CIPHER = PKCS1_v1_5.new(RSA.import_key(PDD_RSA_PUBLIC_KEY))
def _nanoid(size: int = 14) -> str:
return "".join(NANOID_ALPHABET[b & 63] for b in secrets.token_bytes(size))
def _generate_aes_key() -> str:
ts = int(time.time() * 1000)
# 原始 JS 在当前运行环境里 counter 恒为 "000"
return f"v2{ts}000{_nanoid(14)}"
def _generate_iv() -> str:
ts = str(int(time.time() * 1000))
return hashlib.sha256(f"{ts}iv".encode("utf-8")).hexdigest()[:16]
def encrypt() -> dict:
raw_key = _generate_aes_key()
raw_iv = _generate_iv()
encrypted_data = _RSA_CIPHER.encrypt((raw_iv + raw_key).encode("utf-8"))
return {
"encryptedData": base64.b64encode(encrypted_data).decode("utf-8"),
"rawKey": raw_key,
"rawIV": raw_iv,
}
至此请求可以正常拿到接口返回的密文数据encrypt_info,再调用Are方法进行解密,接受三个参数(一个密文数据另外两个o、a分别为key跟iv)如下所示:
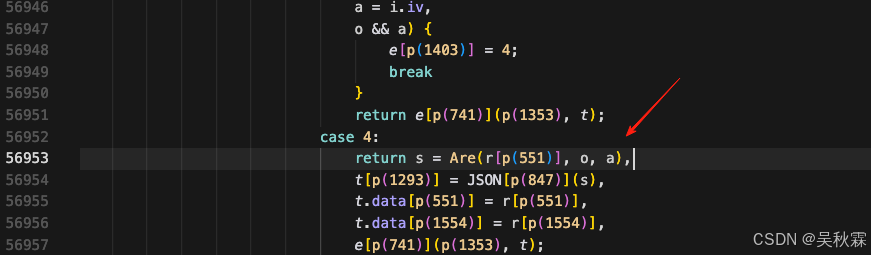
解密算法同样调用VM,密钥信息都有了解密就没什么难度了,唯一需要注意的地方就是解encrypt_info的时候流程上有一个细节,最后1 位是模式标记,不参与base64url的解码!完整算法实现如下:
import zlib
import base64
from Crypto.Cipher import AES
def _base64url_decode(data: str) -> bytes:
data = data.replace("-", "+").replace("_", "/")
data += "=" * ((4 - len(data) % 4) % 4)
return base64.b64decode(data)
def _pkcs7_unpad(data: bytes) -> bytes:
if not data:
raise ValueError("empty data")
pad_len = data[-1]
if pad_len < 1 or pad_len > 16 or data[-pad_len:] != bytes([pad_len]) * pad_len:
raise ValueError("invalid pkcs7 padding")
return data[:-pad_len]
def decrypt(encrypt_info: str, raw_key: str, raw_iv: str) -> str:
if not encrypt_info:
raise ValueError("{}")
mode_flag = encrypt_info[-1]
cipher_text = encrypt_info[:-1]
try:
cipher_bytes = _base64url_decode(cipher_text)
plain_padded = AES.new(raw_key.encode("utf-8"), AES.MODE_CBC, raw_iv.encode("utf-8")).decrypt(cipher_bytes)
plain_bytes = _pkcs7_unpad(plain_padded)
if mode_flag == "1":
plain_bytes = zlib.decompress(plain_bytes, zlib.MAX_WBITS | 32)
return plain_bytes.decode("utf-8")
except Exception as exc:
raise ValueError("{}") from exc
Ere跟Are两个核心方法,并不是普通的function,均通过mre.createStub(programId)间接去执行:
Ere -> createStub(0)Are -> createStub(1)
mre 内部实现了字节码解释器:
execute(…)、runLoop(…)、opcodes[…]
并通过program metadata声明每个program的名称与依赖。关键依赖信息(从 metadata 可直接读到):
- program 0(generate):依赖
generateAESKey、generateIV、rsaEncrypt - program 1(decryptString):依赖
decodeBase64Url、u8ToWordArray、aesDecrypt、decompress
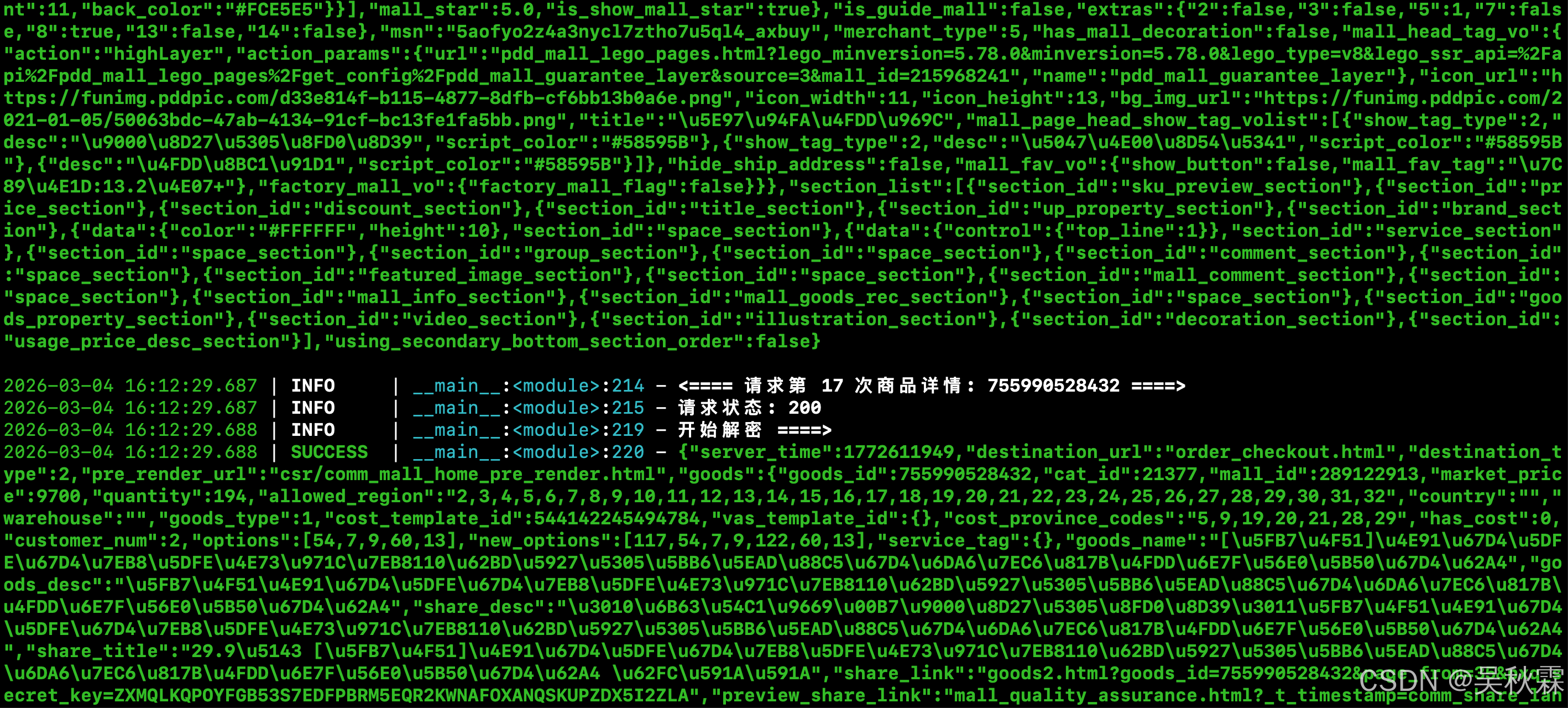
最终测试一下codex5.3针对长达7W多行的JS花费了十多分钟分析,还原出来的纯算效果(一次通过),整个分析的过程,它不光对你的静态代码进行分析来确认哪些是常量,还会结合动态调试取值,通过在Node沙箱运行,拿到调用链,这个很关键!最终不断的像我们自己扣代码一样,在当前目录下反复测试|记录|拆解从而达到最终落地!运行结果如下所示:

大模型正在重写逆向规则、改变逆向玩法!干就完了~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)