AI应用开发学习(java方向)(第一天)
背景:
传统java的环境太卷了,并且AI的出现提升了编程的效率,市场对于传统java程序员的需求减少,越来越多的java岗的要求落地部署过AI应用的项目。学习AI也能让我们的思想跟进时代,有AI项目的简历优势很大。
前置知识
-
Java基础
-
Maven
-
MySQL
-
MyBatis-Plus
-
SpringBoot
一、LangChain4j 入门(第一天)
1、简介
LangChain4j 的目标是简化将大语言模型(LLM - Large Language Model)集成到 Java 应用程序中的过程。
1.2、主要功能
与大型语言模型和向量数据库的便捷交互
通过统一的应用程序编程接口(API),可以轻松访问所有主要的商业和开源大型语言模型以及向量数据库,使你能够构建聊天机器人、智能助手等应用。
专为 Java 打造
借助Spring Boot 集成,能够将大模型集成到ava 应用程序中。大型语言模型与 Java 之间实现了双向集成:你可以从 Java 中调用大型语言模型,同时也允许大型语言模型反过来调用你的 Java 代码
智能代理、工具、检索增强生成(RAG)
为常见的大语言模型操作提供了广泛的工具,涵盖从底层的提示词模板创建、聊天记忆管理和输出解析,到智能代理和检索增强生成等高级模式。
1.3、应用示例
-
你想要实现一个自定义的由人工智能驱动的聊天机器人,它可以访问你的数据,并按照你期望的方式运行:
-
客户支持聊天机器人,它可以:
-
礼貌地回答客户问题
-
-
-
处理 / 更改 / 取消订单
-
教育助手,它可以:
-
教授各种学科
-
-
解释不清楚的部分
-
评估用户的理解 / 知识水平
-
-
你想要处理大量的非结构化数据(文件、网页等),并从中提取结构化信息。例如:
-
从客户评价和支持聊天记录中提取有效评价
-
从竞争对手的网站上提取有趣的信息
-
从求职者的简历中提取有效信息
-
-
你想要生成信息,例如:
-
为你的每个客户量身定制的电子邮件
-
为你的应用程序 / 网站生成内容:
-
博客文章
-
故事
-
-
-
你想要转换信息,例如:
-
总结
-
校对和改写
-
翻译
-
2、创建SpringBoot项目
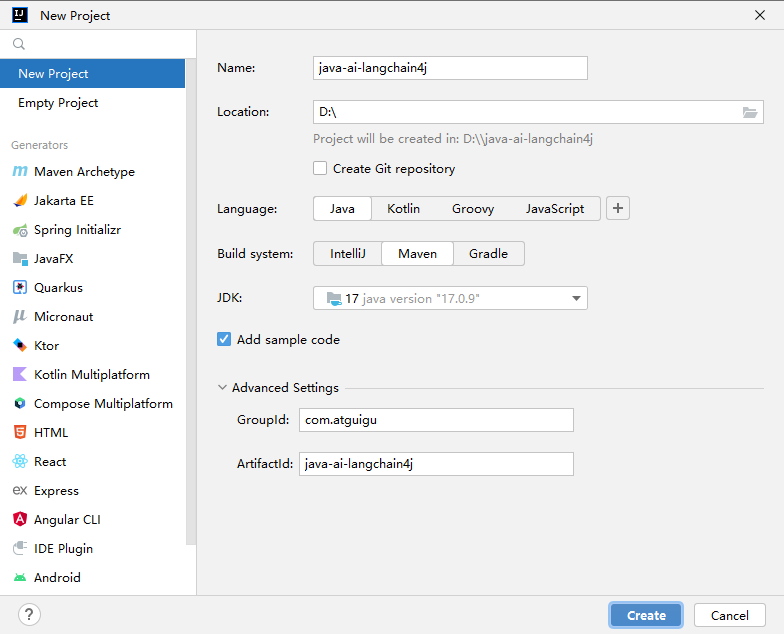
2.1、创建一个Maven项目
java-ai-langchain4j
2.2、添加SpringBoot相关依赖
在pom.xml的 <project> 节点下填加如下依赖
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-boot.version>3.2.6</spring-boot.version>
<knife4j.version>4.3.0</knife4j.version>
<langchain4j.version>1.0.0-beta3</langchain4j.version>
<mybatis-plus.version>3.5.11</mybatis-plus.version>
</properties>
<dependencies>
<!-- web应用程序核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 编写和运行测试用例 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 前后端分离中的后端接口测试工具 -->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>${knife4j.version}</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!--引入SpringBoot依赖管理清单-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
2.3、创建配置文件
在resources下创建配置文件application.properties
# web服务访问端口 server.port=8080
2.4、创建启动类
package com.atguigu.java.ai.langchain4j;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class XiaozhiApp {
public static void main(String[] args) {
SpringApplication.run(XiaozhiApp.class, args);
}
}
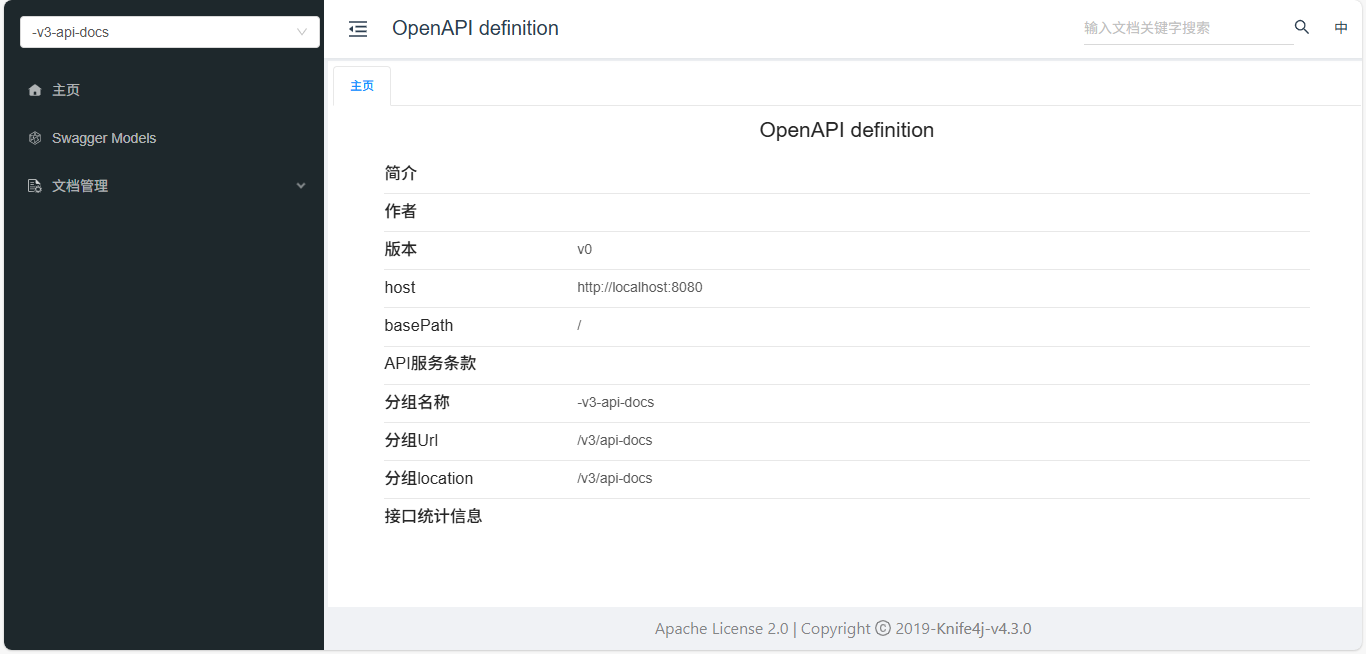
2.5、启动启动类
访问 http://localhost:8080/doc.html 查看程序能否成功运行并显示如下页面
3、接入大模型
-
参考文档: Get Startedhttps://docs.langchain4j.dev/get-started
3.1、LangChain4j 库结构
LangChain4j 具有模块化设计,包括:
-
langchain4j-core 模块,它定义了核心抽象概念(如聊天语言模型和嵌入存储)及其 API。
-
主 langchain4j 模块,包含有用的工具,如文档加载器、聊天记忆实现,以及诸如人工智能服务等高层功能。
-
大量的 langchain4j-{集成} 模块,每个模块都将各种大语言模型提供商和嵌入存储集成到 LangChain4j 中。你可以独立使用 langchain4j-{集成} 模块。如需更多功能,只需导入主 langchain4j 依赖项即可。
3.2、添加LangChain4j相关依赖
<properties>
<langchain4j.version>1.0.0-beta3</langchain4j.version>
</properties>
<dependencies>
<!-- 基于open-ai的langchain4j接口:ChatGPT、deepseek都是open-ai标准下的大模型 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!--引入langchain4j依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
3.3、创建测试用例
接入任何一个大模型都需要先去申请apiKey。
如果你暂时没有密钥,也可以使用LangChain4j 提供的演示密钥,这个密钥是免费的,有使用配额限制,且仅限于 gpt-4o-mini 模型。
package com.atguigu.java.ai.langchain4j;
import dev.langchain4j.model.openai.OpenAiChatModel;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class LLMTest {
/**
* gpt-4o-mini语言模型接入测试
*/
@Test
public void testGPTDemo() {
//初始化模型
OpenAiChatModel model = OpenAiChatModel.builder()
//LangChain4j提供的代理服务器,该代理服务器会将演示密钥替换成真实密钥, 再将请求转发给OpenAI API
//.baseUrl("http://langchain4j.dev/demo/openai/v1") //设置模型api地址(如果apiKey="demo",则可省略baseUrl的配置)
.apiKey("demo") //设置模型apiKey
.modelName("gpt-4o-mini") //设置模型名称
.build();
//向模型提问
String answer = model.chat("你好");
//输出结果
System.out.println(answer);
}
}
4、SpringBoot整合
参考文档:https://docs.langchain4j.dev/tutorials/spring-boot-integration
4.1、替换依赖
将 langchain4j-open-ai 替换成 langchain4j-open-ai-spring-boot-starter
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai-spring-boot-starter</artifactId> </dependency>
4.2、配置模型参数
#langchain4j测试模型 langchain4j.open-ai.chat-model.base-url=http://langchain4j.dev/demo/openai/v1 langchain4j.open-ai.chat-model.api-key=demo langchain4j.open-ai.chat-model.model-name=gpt-4o-mini #请求和响应日志 langchain4j.open-ai.chat-model.log-requests=true langchain4j.open-ai.chat-model.log-responses=true #启用日志debug级别 logging.level.root=debug
4.3、创建测试用例
/**
* 整合SpringBoot
*/
@Autowired
private OpenAiChatModel openAiChatModel;
@Test
public void testSpringBoot() {
//向模型提问
String answer = openAiChatModel.chat("你好");
//输出结果
System.out.println(answer);
}
二、接入其他大模型
1、都有哪些大模型
-
大语言模型排行榜:https://superclueai.com/
SuperCLUE 是由国内 CLUE 学术社区于 2023 年 5 月推出的中文通用大模型综合性评测基准。
-
评测目的:全面评估中文大模型在语义理解、逻辑推理、代码生成等 10 项基础能力,以及涵盖数学、物理、社科等 50 多学科的专业能力,旨在回答在通用大模型发展背景下,中文大模型的效果情况,包括不同任务效果、与国际代表性模型的差距、与人类的效果对比等问题。
-
特色优势:针对中文特性任务,如成语、诗歌、字形等设立专项评测,使评测更符合中文语言特点。通过 3700 多道客观题和匿名对战机制,动态追踪国内外主流模型,如 GPT-4、文心一言、通义千问等的表现差异,保证评测的客观性和时效性。
-
行业影响:作为中文领域权威测评社区,其评测结果被学界和产业界广泛引用,例如商汤 “日日新 5.0” 和百度文心大模型均通过 SuperCLUE 验证技术突破,推动了中文 NLP 技术生态的迭代,为中文大模型的发展和优化提供了重要的参考依据,促进了中文大模型技术的不断进步和应用。
-
LangChain4j支持接入的大模型:https://docs.langchain4j.dev/integrations/language-models/
2、接入DeepSeek(DeepSeek需要付费)
1.1、获取开发参数
-
访问官网:https://www.deepseek.com/ 注册账号,获取base_url和api_key,充值
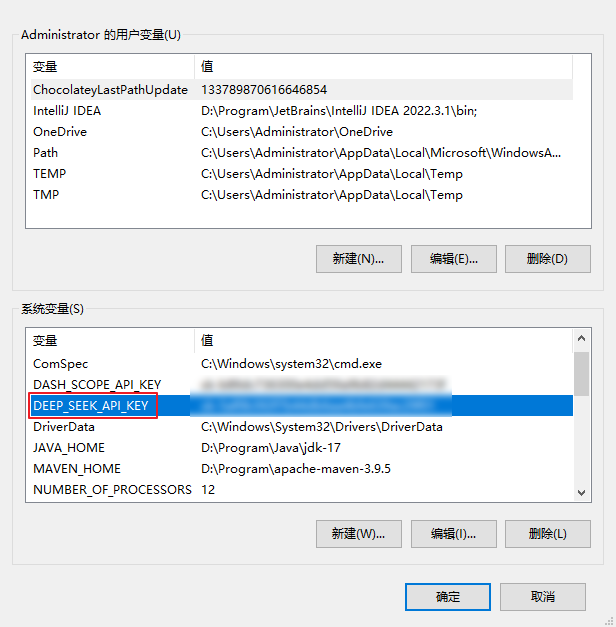
1.2、配置开发参数
为了apikay的安全,建议将其配置在服务器的环境变量中。变量名自定义即可,例如 DEEP_SEEK_API_KEY
1.3、配置模型参数
DeepSeek API文档:https://api-docs.deepseek.com/zh-cn/
在 LangChain4j 中,DeepSeek 和 GPT 一样也使用了 OpenAI 的接口标准,因此也使用OpenAiChatModel进行接入
#DeepSeek
langchain4j.open-ai.chat-model.base-url=https://api.deepseek.com
langchain4j.open-ai.chat-model.api-key=${DEEP_SEEK_API_KEY}
#DeepSeek-V3
langchain4j.open-ai.chat-model.model-name=deepseek-chat
#DeepSeek-R1 推理模型
#langchain4j.open-ai.chat-model.model-name=deepseek-reasoner
1.4、测试
直接使用前面的测试用例即可
3、ollama本地部署
3.1、为什么要本地部署
Ollama 是一个本地部署大模型的工具。使用 Ollama 进行本地部署有以下多方面的原因:
-
数据隐私与安全:对于金融、医疗、法律等涉及大量敏感数据的行业,数据安全至关重要。
-
离线可用性:在网络不稳定或无法联网的环境中,本地部署的 Ollama 模型仍可正常运行。
-
降低成本:云服务通常按使用量收费,长期使用下来费用较高。而 Ollama 本地部署,只需一次性投入硬件成本,对于需要频繁使用大语言模型且对成本敏感的用户或企业来说,能有效节约成本。
-
部署流程简单:只需通过简单的命令 “ollama run < 模型名>”,就可以自动下载并运行所需的模型。
-
灵活扩展与定制:可对模型微调,以适配垂直领域需求。
3.2、在ollama上部署DeepSeek
(1)下载并安装ollama:OllamaSetup.exe
(2)查看模型列表,选择要部署的模型,模型列表: https://ollama.com/search
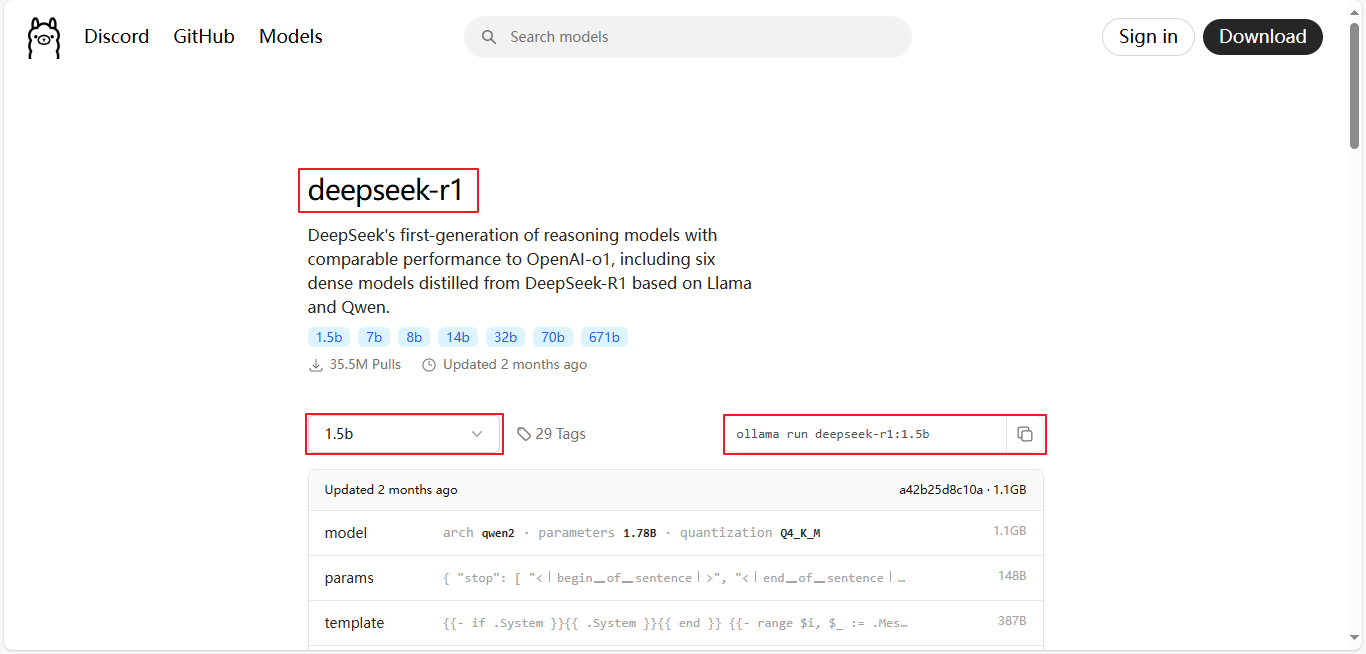
(3)执行命令:ollama run deepseek-r1:1.5运行大模型。如果是第一次运行则会先下载大模型
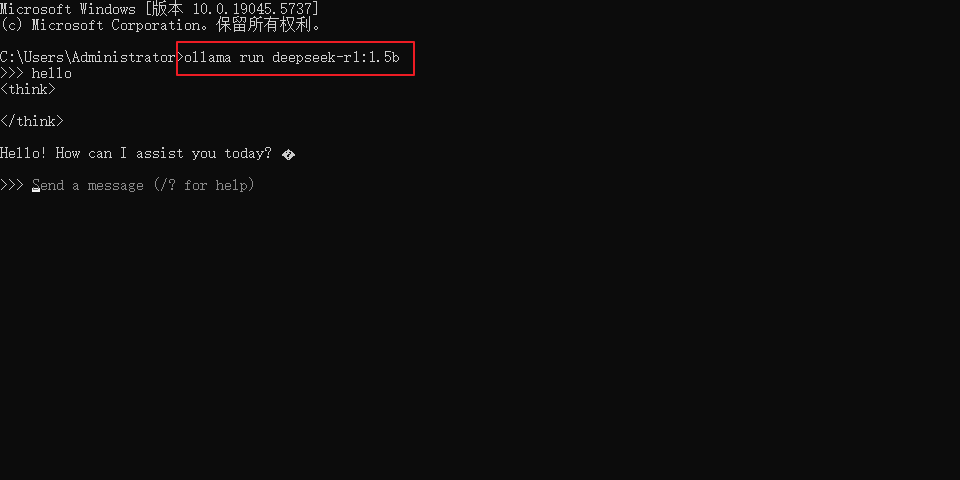
3.3、常用命令
3.4、引入依赖
参考文档:https://docs.langchain4j.dev/integrations/language-models/ollama#get-started
<!-- 接入ollama --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-ollama-spring-boot-starter</artifactId> </dependency>
3.5、配置模型参数
#ollama langchain4j.ollama.chat-model.base-url=http://localhost:11434 langchain4j.ollama.chat-model.model-name=deepseek-r1:1.5b # 创造性控制 # 0.7到1.2•:适用于需要较高创造性的场景,如诗歌生成或头脑风暴 # 0.3到1.0•:适用于需要较高稳定性和多样性的场景,如技术文档或法律文书的生成 langchain4j.ollama.chat-model.temperature=0.8 # 模型进行通信的超时时间为60秒。 langchain4j.ollama.chat-model.timeout=PT60S langchain4j.ollama.chat-model.log-requests=true langchain4j.ollama.chat-model.log-responses=true
3.6、创建测试用例
/**
* ollama接入
*/
@Autowired
private OllamaChatModel ollamaChatModel;
@Test
public void testOllama() {
//向模型提问
String answer = ollamaChatModel.chat("你好");
//输出结果
System.out.println(answer);
}
4、接入阿里百炼平台
4.1、什么是阿里百炼
-
阿里云百炼是 2023 年 10 月推出的。它集成了阿里的通义系列大模型和第三方大模型,涵盖文本、图像、音视频等不同模态。
-
功能优势:集成超百款大模型 API,模型选择丰富;5-10 分钟就能低代码快速构建智能体,应用构建高效;提供全链路模型训练、评估工具及全套应用开发工具,模型服务多元;在线部署可按需扩缩容,新用户有千万 token 免费送,业务落地成本低。
4.2、申请免费体验
(1)点击进入免费体验页面
(2)点击免费体验
(3)点击开通服务
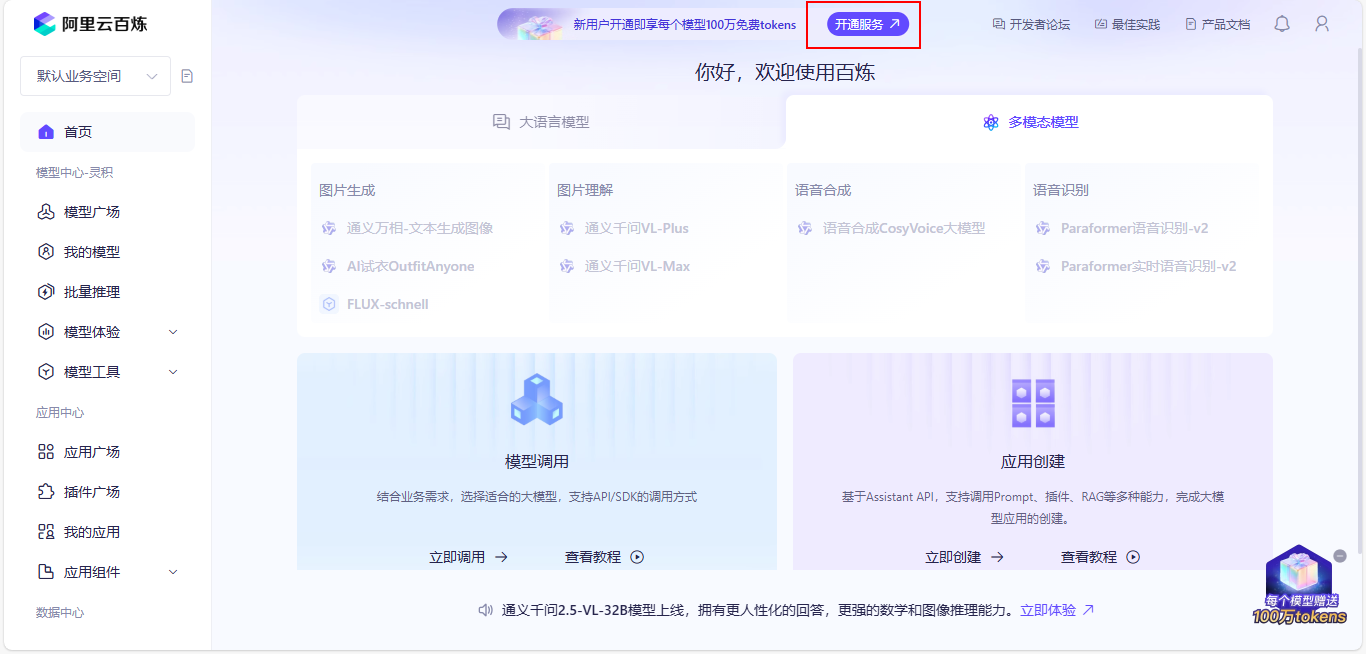
(4)确认开通
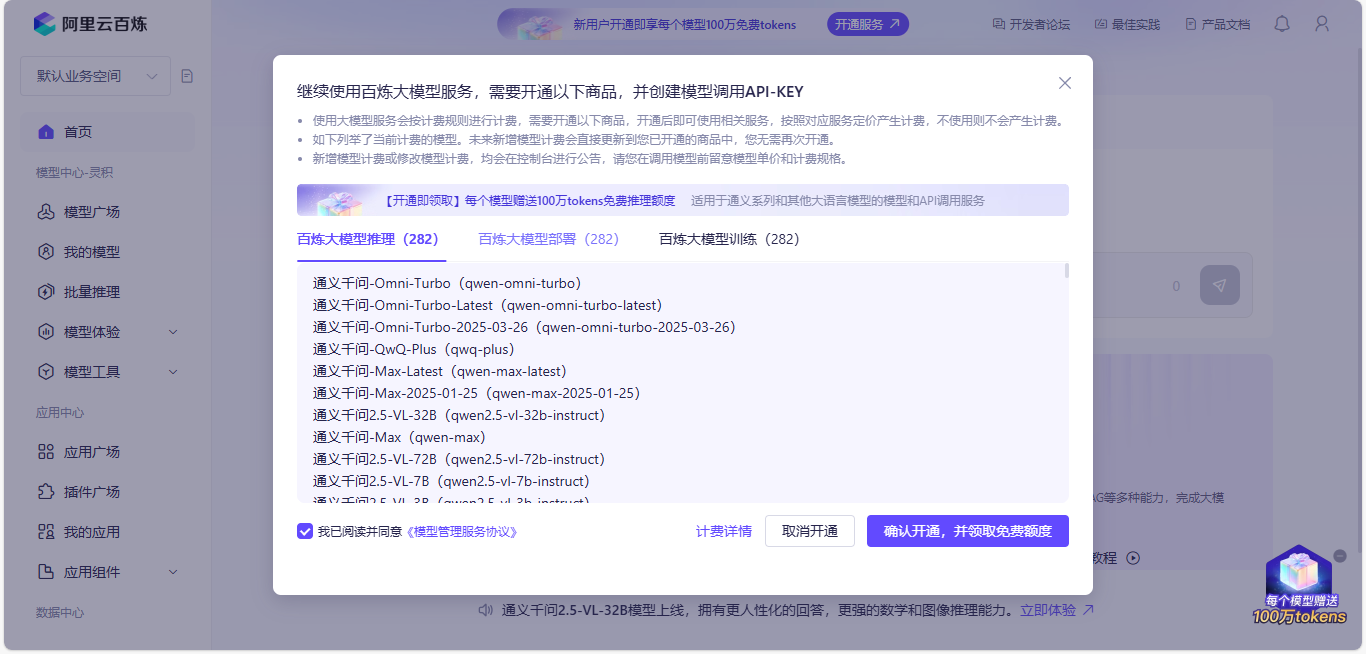
4.3、配置apiKey
申请apiKey:https://bailian.console.aliyun.com/?apiKey=1&productCode=p_efm#/api-key
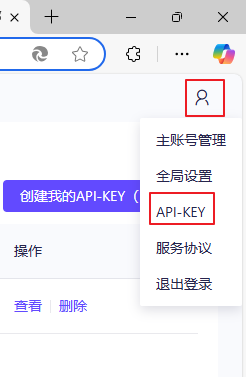
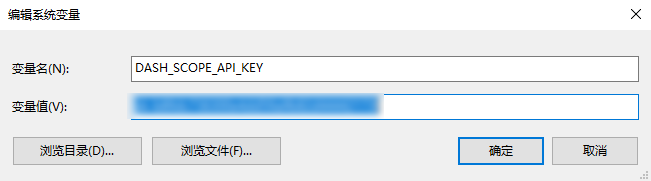
配置apiKey:配置在环境变量DASH_SCOPE_API_KEY中
4.4、添加依赖
LangChain4j参考文档:https://docs.langchain4j.dev/integrations/language-models/dashscope#plain-java
<dependencies>
<!-- 接入阿里云百炼平台 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!--引入百炼依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
4.5、配置模型参数
#阿里百炼平台
langchain4j.community.dashscope.chat-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.community.dashscope.chat-model.model-name=qwen-max
4.6、测试通义千问
/**
* 通义千问大模型
*/
@Autowired
private QwenChatModel qwenChatModel;
@Test
public void testDashScopeQwen() {
//向模型提问
String answer = qwenChatModel.chat("你好");
//输出结果
System.out.println(answer);
}
4.6、测试通义万相
生成图片测试
@Test
public void testDashScopeWanx(){
WanxImageModel wanxImageModel = WanxImageModel.builder()
.modelName("wanx2.1-t2i-plus")
.apiKey(System.getenv("DASH_SCOPE_API_KEY"))
.build();
Response<Image> response = wanxImageModel.generate("奇幻森林精灵:在一片弥漫着轻柔薄雾的古老森林深处,阳光透过茂密枝叶洒下金色光斑。一位身材娇小、长着透明薄翼的精灵少女站在一朵硕大的蘑菇上。她有着海藻般的绿色长发,发间点缀着蓝色的小花,皮肤泛着珍珠般的微光。身上穿着由翠绿树叶和白色藤蔓编织而成的连衣裙,手中捧着一颗散发着柔和光芒的水晶球,周围环绕着五彩斑斓的蝴蝶,脚下是铺满苔藓的地面,蘑菇和蕨类植物丛生,营造出神秘而梦幻的氛围。");
System.out.println(response.content().url());
}
4.7、测试DeepSeek
也可以在阿里百炼上集成第三方大模型,如DeepSeek
将配置参数上的base-url参数指定到百炼平台,使用百炼上的大模型名称和apiKey即可
#集成百炼-deepseek
langchain4j.open-ai.chat-model.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
langchain4j.open-ai.chat-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.open-ai.chat-model.model-name=deepseek-v3
#温度系数:取值范围通常在 0 到 1 之间。值越高,模型的输出越随机、富有创造性;
# 值越低,输出越确定、保守。这里设置为 0.9,意味着模型会有一定的随机性,生成的回复可能会比较多样化。
langchain4j.open-ai.chat-model.temperature=0.9
使用之前的测试用例testSpringBoot测试即可
三、人工智能服务 AIService
1、什么是AIService
AIService使用面向接口和动态代理的方式完成程序的编写,更灵活的实现高级功能。
1.1、链 Chain(旧版)
链的概念源自 Python 中的 LangChain。其理念是针对每个常见的用例都设置一条链,比如聊天机器人、检索增强生成(RAG)等。链将多个底层组件组合起来,并协调它们之间的交互。链存在的主要问题是不灵活,我们不进行深入的研究。
1.2、人工智能服务 AIService
在LangChain4j中我们使用AIService完成复杂操作。底层组件将由AIService进行组装。
AIService可处理最常见的操作:
-
为大语言模型格式化输入内容
-
解析大语言模型的输出结果
它们还支持更高级的功能:
-
聊天记忆 Chat memory
-
工具 Tools
-
检索增强生成 RAG
2、创建AIService
2.1、引入依赖
<!--langchain4j高级功能--> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-spring-boot-starter</artifactId> </dependency>
2.2、创建接口
package com.atguigu.java.ai.langchain4j.assistant;
public interface Assistant {
String chat(String userMessage);
}
2.3、测试用例
@SpringBootTest
public class AIServiceTest {
@Autowired
private QwenChatModel qwenChatModel;
@Test
public void testChat() {
//创建AIService
Assistant assistant = AiServices.create(Assistant.class, qwenChatModel);
//调用service的接口
String answer = assistant.chat("Hello");
System.out.println(answer);
}
}
2.4、@AiService
也可以在Assistant接口上添加@AiService注解
package com.atguigu.java.ai.langchain4j.assistant;
//因为我们在配置文件中同时配置了多个大语言模型,所以需要在这里明确指定(EXPLICIT)模型的beanName(qwenChatModel)
//@AiService(wiringMode = AiServiceWiringMode.EXPLICIT,chatModel = "qwenChatModel")
@AiService(wiringMode = EXPLICIT, chatModel = "qwenChatModel")
public interface Assistant {
String chat(String userMessage);
}
测试用例中,我们可以直接注入Assistant对象
@Autowired
private Assistant assistant;
@Test
public void testAssistant() {
String answer = assistant.chat("Hello");
System.out.println(answer);
}
2.5、工作原理
AiServices会组装Assistant接口以及其他组件,并使用反射机制创建一个实现Assistant接口的代理对象。这个代理对象会处理输入和输出的所有转换工作。在这个例子中,chat方法的输入是一个字符串,但是大模型需要一个UserMessage对象。所以,代理对象将这个字符串转换为UserMessage,并调用聊天语言模型。chat方法的输出类型也是字符串,但是大模型返回的是 AiMessage 对象,代理对象会将其转换为字符串。
简单理解就是:代理对象的作用是输入转换和输出转换
四、聊天记忆 Chat memory
1、测试对话是否有记忆
package com.atguigu.java.ai.langchain4j;
@SpringBootTest
public class ChatMemoryTest {
@Autowired
private Assistant assistant;
@Test
public void testChatMemory() {
String answer1 = assistant.chat("我是华仔");
System.out.println(answer1);
String answer2 = assistant.chat("我是谁");
System.out.println(answer2);
}
}
很显然,目前的接入方式,大模型是没有记忆的。
2、聊天记忆的简单实现
可以使用下面的方式实现对话记忆。
package com.guigu.ai.langchain4j;
import com.guigu.ai.langchain4j.assistant.Assistant;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.response.ChatResponse;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
@SpringBootTest
public class ChatMemoryTest {
@Autowired
private Assistant assistant;
@Autowired
private QwenChatModel qwenChatModel;
@Test
public void testChatMemory2() {
UserMessage userMessage1 = UserMessage.userMessage("我是华仔");
ChatResponse chatResponse1 = qwenChatModel.chat(userMessage1);
AiMessage aiMessage1 = chatResponse1.aiMessage();
System.out.println(aiMessage1.text());
UserMessage userMessage2 = UserMessage.userMessage("我是谁");
ChatResponse chatResponse2= qwenChatModel.chat(Arrays.asList(userMessage1,aiMessage1,userMessage2));
AiMessage aiMessage2 = chatResponse2.aiMessage();
System.out.println(aiMessage2.text());
}
}
3、使用ChatMemory实现聊天记忆
使用AIService可以封装多轮对话的复杂性,使聊天记忆功能的实现变得简单
@Test
public void testChatMemory3() {
//创建chatMemory
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
//创建AIService
Assistant assistant = AiServices
.builder(Assistant.class)
.chatLanguageModel(qwenChatModel)
.chatMemory(chatMemory)
.build();
//调用service的接口
String answer1 = assistant.chat("我是华仔");
System.out.println(answer1);
String answer2 = assistant.chat("我是谁");
System.out.println(answer2);
}
4、使用AIService实现聊天记忆
4.1、创建记忆对话智能体
当AIService由多个组件(大模型,聊天记忆,等)组成的时候,我们就可以称他为智能体了
package com.atguigu.java.ai.langchain4j.assistant;
@AiService(
wiringMode = EXPLICIT,
chatModel = "qwenChatModel",
chatMemory = "chatMemory"
)
public interface MemoryChatAssistant {
String chat(String message);
}
4.2、配置ChatMemory
package com.atguigu.java.ai.langchain4j.config;
@Configuration
public class MemoryChatAssistantConfig {
@Bean
ChatMemory chatMemory() {
//设置聊天记忆记录的message数量
return MessageWindowChatMemory.withMaxMessages(10);
}
}
4.3、测试
@Autowired
private MemoryChatAssistant memoryChatAssistant;
@Test
public void testChatMemory4() {
String answer1 = memoryChatAssistant.chat("我是华仔");
System.out.println(answer1);
String answer2 = memoryChatAssistant.chat("我是谁");
System.out.println(answer2);
}
5、隔离聊天记忆
为每个用户的新聊天或者不同的用户区分聊天记忆
5.1、创建记忆隔离对话智能体
package com.atguigu.java.ai.langchain4j.assistant;
@AiService(
wiringMode = EXPLICIT,
chatModel = "qwenChatModel",
chatMemoryProvider = "chatMemoryProvider"
)
public interface SeparateChatAssistant {
/**
* 分离聊天记录
* @param memoryId 聊天id
* @param userMessage 用户消息
* @return
*/
String chat(@MemoryId int memoryId, @UserMessage String userMessage);
}
5.2、配置ChatMemoryProvider
package com.atguigu.java.ai.langchain4j.config;
@Configuration
public class SeparateChatAssistantConfig {
@Bean
ChatMemoryProvider chatMemoryProvider() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.build();
}
}
5.3、测试对话助手
用两个不同的memoryId测试聊天记忆的隔离效果
@Autowired
private SeparateChatAssistant separateChatAssistant;
@Test
public void testChatMemory5() {
String answer1 = separateChatAssistant.chat(1,"我是华仔");
System.out.println(answer1);
String answer2 = separateChatAssistant.chat(1,"我是谁");
System.out.println(answer2);
String answer3 = separateChatAssistant.chat(2,"我是谁");
System.out.println(answer3);
}
五、持久化聊天记忆 Persistence
默认情况下,聊天记忆存储在内存中。如果需要持久化存储,可以实现一个自定义的聊天记忆存储类,以便将聊天消息存储在你选择的任何持久化存储介质中。
1、存储介质的选择
大模型中聊天记忆的存储选择哪种数据库,需要综合考虑数据特点、应用场景和性能要求等因素,以下是一些常见的选择及其特点:
-
MySQL
-
特点:关系型数据库。支持事务处理,确保数据的一致性和完整性,适用于结构化数据的存储和查询。
-
适用场景:如果聊天记忆数据结构较为规整,例如包含固定的字段如对话 ID、用户 ID、时间戳、消息内容等,且需要进行复杂的查询和统计分析,如按用户统计对话次数、按时间范围查询特定对话等,MySQL 是不错的选择。
-
-
Redis
-
特点:内存数据库,读写速度极高。它适用于存储热点数据,并且支持多种数据结构,如字符串、哈希表、列表等,方便对不同类型的聊天记忆数据进行处理。
-
适用场景:对于实时性要求极高的聊天应用,如在线客服系统或即时通讯工具,Redis 可以快速存储和获取最新的聊天记录,以提供流畅的聊天体验。
-
-
MongoDB
-
特点:文档型数据库,数据以 JSON - like 的文档形式存储,具有高度的灵活性和可扩展性。它不需要预先定义严格的表结构,适合存储半结构化或非结构化的数据。
-
适用场景:当聊天记忆中包含多样化的信息,如文本消息、图片、语音等多媒体数据,或者消息格式可能会频繁变化时,MongoDB 能很好地适应这种灵活性。例如,一些社交应用中用户可能会发送各种格式的消息,使用 MongoDB 可以方便地存储和管理这些不同类型的数据。
-
-
Cassandra
-
特点:是一种分布式的 NoSQL 数据库,具有高可扩展性和高可用性,能够处理大规模的分布式数据存储和读写请求。适合存储海量的、时间序列相关的数据。
-
适用场景:对于大型的聊天应用,尤其是用户量众多、聊天数据量巨大且需要分布式存储和处理的场景,Cassandra 能够有效地应对高并发的读写操作。例如,一些面向全球用户的社交媒体平台,其聊天数据需要在多个节点上进行分布式存储和管理,Cassandra 可以提供强大的支持。
-
2、MongoDB
2.1、简介
MongoDB 是一个基于文档的 NoSQL 数据库,由 MongoDB Inc. 开发。
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
MongoDB 的设计理念是为了应对大数据量、高性能和灵活性需求。
MongoDB使用集合(Collections)来组织文档(Documents),每个文档都是由键值对组成的。
-
数据库(Database):存储数据的容器,类似于关系型数据库中的数据库。
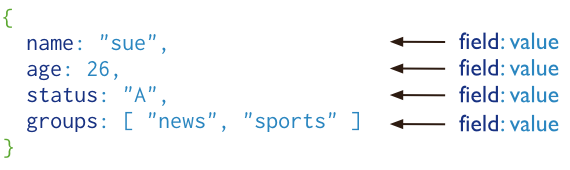
-
集合(Collection):数据库中的一个集合,类似于关系型数据库中的表。
-
文档(Document):集合中的一个数据记录,类似于关系型数据库中的行(row),以 BSON 格式存储。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成,文档类似于 JSON 对象,字段值可以包含其他文档,数组及文档数组:
2.2、安装MongoDB
安装教程(https://cloud.tencent.com/developer/article/2393937)
服务器:mongodb-windows-x86_64-8.0.6-signed.msi https://www.mongodb.com/try/download/community
命令行客户端 :mongosh-2.5.0-win32-x64.zip https://www.mongodb.com/try/download/shell
图形客户端:mongodb-compass-1.39.3-win32-x64.exe https://www.mongodb.com/try/download/compass
2.3、使用mongosh
启动 MongoDB Shell:
在命令行中输入 mongosh 命令,启动 MongoDB Shell,如果 MongoDB 服务器运行在本地默认端口(27017),则可以直接连接。
mongosh
连接到 MongoDB 服务器:
如果 MongoDB 服务器运行在非默认端口或者远程服务器上,可以使用以下命令连接:
mongosh --host <hostname>:<port>
其中 <hostname> 是 MongoDB 服务器的主机名或 IP 地址,<port> 是 MongoDB 服务器的端口号。
执行基本操作:
连接成功后,可以执行各种 MongoDB 数据库操作。例如:
-
查看当前数据库:
db -
显示数据库列表:
show dbs -
切换到指定数据库:
use <database_name> -
执行查询操作:
db.<collection_name>.find() -
插入文档:
db.<collection_name>.insertOne({ ... }) -
更新文档:
db.<collection_name>.updateOne({ ... }) -
删除文档:
db.<collection_name>.deleteOne({ ... }) -
退出 MongoDB Shell:
quit()或者exit
CRUD
# 插入文档
test> db.mycollection.insertOne({ name: "Alice", age: 30 })
# 查询文档
test> db.mycollection.find()
# 更新文档
test> db.mycollection.updateOne({ name: "Alice" }, { $set: { age: 31 } })
# 删除文档
test> db.mycollection.deleteOne({ name: "Alice" })
# 退出 MongoDB Shell
test> quit()
2.4、使用mongodb-compass
2.5、整合SpringBoot
引入MongoDB依赖:
<!-- Spring Boot Starter Data MongoDB --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency>
添加远程连接配置:
#MongoDB连接配置 spring.data.mongodb.uri=mongodb://localhost:27017/chat_memory_db
第一天总结
一、框架核心类
1. LangChain4j
- 角色:Java 生态的「大模型应用开发脚手架」
- 作用:把复杂的大模型调用、对话记忆、数据检索(RAG)等逻辑封装成简单的 Java API,让你不用手写底层 HTTP 请求、不用处理大模型的复杂格式,就能快速开发 AI 应用。
- 类比:就像 Spring Boot 帮你简化 Web 开发一样,LangChain4j 帮你简化 AI 开发。
二、核心组件(你代码里直接用到的)
2. ChatLanguageModel(聊天语言模型)
- 角色:大模型的「Java 翻译官」
- 作用:是 LangChain4j 定义的接口,用来对接具体的大模型(比如你用的通义千问
qwenChatModel、OpenAI 的gpt-4)。它负责把你的 Java 字符串请求传给大模型,再把大模型的回复转成 Java 字符串返回。 - 你的代码对应:
AiServices.builder(...).chatLanguageModel(qwenChatModel)里的qwenChatModel就是它的实现类。
3. ChatMemory(聊天记忆)
- 角色:AI 助手的「短期记忆库」
- 作用:保存你和 AI 的对话历史,让大模型能根据上下文回答问题(比如你先说 “我是华仔”,再问 “我是谁”,它能记得你是华仔)。如果没有它,每次对话都是 “全新的开始”,大模型会忘记之前说过什么。
- 你的代码对应:
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10)里的chatMemory就是它的实例。
4. MessageWindowChatMemory(消息窗口记忆)
- 角色:「滑动窗口式的短期记忆库」(是
ChatMemory的具体实现) - 作用:只保留最近 N 条对话消息(比如你设的 10 条),避免记忆太多导致大模型 “脑子不够用”(处理不过来),同时节省资源。
- 类比:就像你记笔记只记最近 10 页,旧的自动翻过去,只留最新的。
5. AiServices(AI 服务构建器)
- 角色:「AI 助手的组装工厂」
- 作用:LangChain4j 的核心工具类,用来把
ChatLanguageModel(大脑)、ChatMemory(记忆)等组件 “组装” 在一起,动态生成你定义的Assistant接口的实现类(不用你手写一行实现代码)。 - 你的代码对应:
AiServices.builder(Assistant.class).chatLanguageModel(...).chatMemory(...).build()就是在 “组装” AI 助手。
6. Assistant(AI 助手接口)
- 角色:「AI 助手的功能设计图」(是你自己定义的 Java 接口)
- 作用:规定 AI 助手有什么能力(比如你定义的
String chat(String message)方法,就是让 AI 具备 “聊天” 能力)。LangChain4j 会根据这个接口,动态生成具体的实现类(就是你代码里的assistant对象)。 - 你的代码对应:
Assistant assistant = AiServices.builder(...).build()里的Assistant就是你定义的接口,assistant是它的实现类实例。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)