【ComfyUI】HiDream_I1 Dev28基础文生图
本文介绍了一个基于HiDream-I1模型的ComfyUI工作流,实现了从文本到图像的高质量生成。该工作流包含模型加载、提示词编码、采样生成、图像解码与保存的全流程,支持FP8精度以降低显存占用,提供三种采样模式满足不同需求。核心采用HiDream扩散模型、CLIP/T5/LLAMA文本编码器和VAE解码器,通过模块化节点设计实现灵活替换与调整。应用场景涵盖艺术创作、概念设计、视觉研究和高效生成等
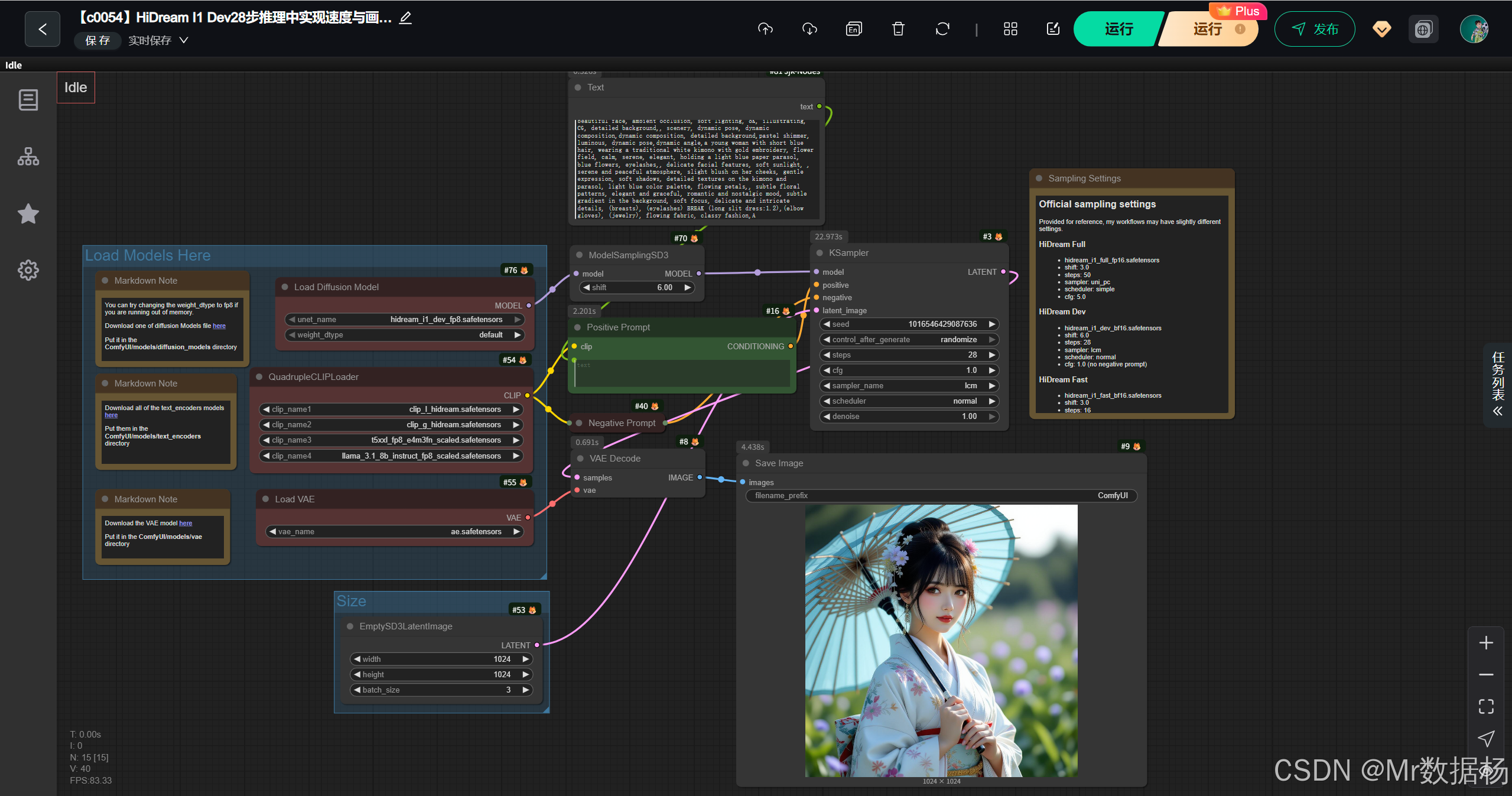
今天展示的案例是一个基于 HiDream-I1 模型的 ComfyUI 工作流。该流程结合了多种模型加载、正负提示词编码、采样生成以及图像解码与保存的完整链路,能够实现从文本到图像的高质量生成。

工作流中还包含详细的采样设置说明,确保生成结果在速度、效果与显存占用之间取得平衡。通过这一案例可以直观理解 ComfyUI 在多模型协同和扩展性方面的强大能力,为后续在艺术创作与应用落地提供参考。
工作流介绍
该工作流通过加载 HiDream 系列扩散模型 与多路文本编码器,结合 VAE 解码与采样策略,完成了从正负提示词到最终图像生成的全流程。设计中强调对显存的灵活适配,例如支持 FP8 精度的 UNet 模型,以便在不同硬件条件下实现优化。同时,工作流集成了多组采样参数设置,用户可以在高质量、快速推理、开发调试三种模式之间自由切换,使其既能满足创作级别的细腻画面,也能快速验证创意。
核心模型
在核心模型部分,工作流集成了 HiDream 系列扩散模型以及多路文本编码器,并通过 VAE 模型完成潜空间与图像空间的映射。扩散模型负责生成潜在图像,文本编码器负责解析提示词语义,VAE 则作为压缩与解码的关键环节。通过组合 hidream_i1_dev_fp8 扩散模型、CLIP 与 T5XXL/LLAMA 编码器,以及 ae.safetensors VAE 文件,工作流在保持图像质量的同时降低了显存占用,提升了运行效率。
| 模型名称 | 说明 |
|---|---|
| hidream_i1_dev_fp8.safetensors | HiDream-I1 系列扩散模型,支持 FP8 精度,降低显存占用的同时保持高质量生成 |
| clip_l_hidream.safetensors / clip_g_hidream.safetensors | CLIP 文本编码器,用于解析正负提示词,强化语义控制 |
| t5xxl_fp8_e4m3fn_scaled.safetensors | 大规模 T5 文本编码器,提升复杂描述的理解能力 |
| llama_3.1_8b_instruct_fp8_scaled.safetensors | LLAMA 指令式语言模型,用于扩展性提示解析 |
| ae.safetensors | VAE 模型,负责潜在空间与像素图像的解码映射 |
Node节点
在节点设计上,工作流覆盖了从模型加载到图像保存的关键环节。UNETLoader、QuadrupleCLIPLoader 与 VAELoader 负责载入核心模型,CLIPTextEncode 节点处理正负提示词,KSampler 与 ModelSamplingSD3 节点完成潜空间的扩散与采样,最后通过 VAEDecode 解码得到图像,并交由 SaveImage 节点输出结果。这种模块化的节点设计便于开发者快速替换模型或调整采样策略,从而实现多样化的创作目标。
| 节点名称 | 说明 |
|---|---|
| UNETLoader | 加载 HiDream 扩散模型,提供潜在空间生成能力 |
| QuadrupleCLIPLoader | 同时加载多路 CLIP、T5 与 LLAMA 文本编码器,提升提示词解析效果 |
| VAELoader | 加载 VAE 模型,作为潜在表示与图像之间的桥梁 |
| CLIPTextEncode (Positive / Negative Prompt) | 分别解析正向与负向提示词,引导生成方向 |
| ModelSamplingSD3 | 调整模型采样策略参数,实现更灵活的扩散过程 |
| KSampler | 核心采样器,结合提示词与潜空间生成潜在图像 |
| VAEDecode | 将潜空间解码为实际图像 |
| SaveImage | 保存最终生成的图像,输出到指定目录 |
工作流程
该工作流的执行路径从模型加载开始,逐步经过文本提示解析、潜空间采样、潜在图像生成、解码与保存,每一步都形成紧密衔接的处理链路。流程先由 UNet、CLIP 与 VAE 模型完成核心加载,再通过正负提示词构建语义引导,KSampler 节点在采样策略作用下结合潜在输入生成潜图,最后经过 VAE 解码与图像保存节点输出结果。通过这种环环相扣的设计,既保证了生成效果的灵活性,又在硬件适配与效率上提供了可调空间。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 载入 UNet 扩散模型、CLIP 编码器和 VAE 模型,准备基础资源 | UNETLoader / QuadrupleCLIPLoader / VAELoader |
| 2 | 提示词解析 | 对正向与负向文本提示进行编码,构建语义条件输入 | CLIPTextEncode (Positive / Negative Prompt) |
| 3 | 采样策略设定 | 配置扩散采样参数,优化潜空间生成过程 | ModelSamplingSD3 |
| 4 | 潜图生成 | 根据提示词与潜空间输入进行扩散与采样,生成潜在图像 | KSampler |
| 5 | 图像解码 | 将潜在图像映射回像素空间,形成完整画面 | VAEDecode |
| 6 | 图像保存 | 输出并保存最终生成结果,供展示与后续处理 | SaveImage |
大模型应用
CLIPTextEncode 文本语义嵌入生成
在 HiDream I1 Dev 工作流中,CLIPTextEncode 节点是文本到潜在空间嵌入的核心节点。它将用户提供的正向 Prompt 转化为条件嵌入,用于指导 UNET 模型在 28 步推理中生成高质量图像,同时兼顾生成速度和画质平衡。Prompt 的描述控制图像的场景、角色、风格和细节,是整个流程中语义控制的关键。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode (Positive Prompt) | A photograph of an albino woman with white skin and dark hair wearing black in the style of old baroque oil paintings, with soft focus, wearing a pearl necklace around her neck, with a dark background, with rosy cheeks, with a long veil covering her face, looking straight ahead | 将正向 Prompt 转化为条件嵌入,用于控制 UNET 模型生成图像的语义、风格和细节,实现速度与画质的平衡。 |
CLIPTextEncode 负向语义控制
该节点生成负向条件嵌入,用于抑制生成图像中不希望出现的元素或质量问题,如噪点、JPEG 压缩痕迹或低质量细节。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode (Negative Prompt) | bad ugly jpeg artifacts | 将负向 Prompt 转化为条件嵌入,用于抑制不希望出现的视觉元素或低质量细节,提升图像生成的清晰度和美观度。 |
使用方法
HiDream I1 Dev 工作流通过结合正向和负向 Prompt 的条件嵌入、潜在空间采样、UNET 模型推理及 VAE 解码,实现 28 步推理下速度与画质的平衡。用户提供正向 Prompt 描述场景、角色及风格,CLIPTextEncode 转化为正向嵌入,负向 Prompt 生成负向嵌入抑制不希望的元素。EmptySD3LatentImage 提供初始潜在图像,UNETLoader 加载 HiDream I1 Dev FP8 模型,ModelSamplingSD3 处理潜变量采样,KSampler 控制采样细节,VAELoader 与 VAEDecode 将潜在图像解码为最终图像,SaveImage 输出。用户可通过修改 Prompt、CFG 值或潜在图像参数调整生成结果,实现高质量、快速生成。
| 注意点 | 说明 |
|---|---|
| Prompt 描述精细 | 确保场景、角色和细节符合预期 |
| 负向 Prompt 使用 | 避免生成不希望的元素或低质量细节 |
| 推理步数合理 | 28 步在速度与画质之间取得平衡 |
| 潜变量尺寸与输出一致 | 保证 VAEDecode 解码后图像比例正确 |
| 模型量化与精度 | HiDream I1 Dev FP8 模型节省显存,同时保持高细节质量 |
应用场景
该工作流的应用覆盖了艺术创作、概念设计、视觉研究与高效生成等多个方向。在艺术领域,可以用来快速生成风格化作品或复古油画风格肖像;在设计环节,可辅助创作者快速迭代视觉原型;在研究场景下,则可用于模型精度对比和显存占用测试。由于其支持不同精度的模型加载与多套采样参数,该工作流能够满足多样化需求,从高质量精细渲染到快速生成预览均可实现。最终的效果既能保证图像的艺术表现力,又能兼顾效率与硬件资源的适配。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 艺术创作 | 生成高质量的风格化图像 | 数字艺术家 / 插画师 | 复古风格人像、绘画效果作品 | 提供细节丰富、质感真实的画面 |
| 概念设计 | 快速构建视觉原型 | 游戏 / 动漫设计师 | 场景草图、人物立绘 | 高效完成创意构思阶段 |
| 视觉研究 | 对比模型效果与参数差异 | 学术研究人员 / 模型开发者 | 不同采样模式、精度下的生成图像 | 验证模型适配性与生成性能 |
| 高效生成 | 提供快速预览结果 | 产品经理 / 内容策划 | 低步数快速采样图像 | 便捷展示概念或演示效果 |
| 多设备适配 | 满足显存限制环境下的运行需求 | 小显存 GPU 用户 | FP8 精度下的生成结果 | 在硬件限制下保持生成稳定性 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)