论文阅读:arixv 2025 A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployme
大型语言模型(LLMs)的卓越成功,为学术界和工业界开辟了一条迈向通用人工智能的光明路径,这得益于它们在各类应用中前所未有的性能表现。随着LLMs在研究和商业领域的影响力持续扩大,其安全与保障问题已成为研究人员、企业乃至各国政府日益关注的焦点。目前,现有的LLM安全综述主要聚焦于LLM生命周期的特定阶段(如部署阶段或微调阶段),缺乏对整个"生命链"的系统性理解。为填补这一空白,本文首次提出"全栈"
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
https://arxiv.org/pdf/2504.15585
LLM(智能体)全栈安全综合综述:数据、训练与部署
arXiv:2504.15585v4 [cs.CR] 2025年6月9日
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015
作者: Kun Wang*¹²、Guibin Zhang*³、Zhenhong Zhou†⁴、Jiahao Wu†⁵⁶、Miao Yu⁷、Shiqian Zhao¹、Chenlong Yin⁸、Jinhu Fu⁹、Yibo Yan¹⁰¹¹、Hanjun Luo¹²、Liang Lin¹³、Zhihao Xu¹⁴、Haolang Lu¹、Xinye Cao¹、Xinyun Zhou¹、Weifei Jin¹、Fanci Meng⁷、Shicheng Xu¹⁵、Junyuan Mao³、Yu Wang¹⁶、Hao Wu¹⁷、Minghe Wang¹²、Fan Zhang¹⁸、Junfeng Fang³、Wenjie Qu³、Yue Liu³、Chengwei Liu¹、Yifan Zhang¹⁹、Qiankun Li⁷、Chongye Guo²⁰²¹、Yalan Qin²⁰²¹、Zhaoxin Fan²²、Kai Wang³、Yi Ding¹、Donghai Hong²³、Jiaming Ji²³、Yingxin Lai²⁴、Zitong Yu²⁴、Xinfeng Li¹、Yifan Jiang²⁵、Yanhui Li¹²、Xinyu Deng¹²、Junlin Wu¹²、Dongxia Wang¹²、Yihao Huang¹、Yufei Guo²³、Jen-tse Huang²⁶、Qiufeng Wang²⁷、Xiaolong Jin⁴⁵、Wenxuan Wang¹⁴、Dongrui Liu²¹、Yanwei Yue²³、Wenke Huang²⁹、Guancheng Wan³⁰、Heng Chang⁴⁶、Tianlin Li¹、Yi Yu¹、Chenghao Li³¹、Jiawei Li³³、Lei Bai²¹、Jie Zhang⁴、Qing Guo⁴、Jingyi Wang¹²、Tianlong Chen³²、Joey Tianyi Zhou⁴、Xiaojun Jia¹、Weisong Sun¹、Cong Wu³⁴、Jing Chen²⁹、Xuming Hu¹⁰¹¹、Yiming Li¹、Xiao Wang³⁵、Ningyu Zhang¹²、Luu Anh Tuan¹、Guowen Xu³¹、Jiaheng Zhang³、Tianwei Zhang¹、Xingjun Ma³⁷、Jindong Gu³⁸、Liang Pang¹⁵、Xiang Wang⁷、Bo An¹、Jun Sun³⁶、Mohit Bansal³²、Shirui Pan²⁸、Lingjuan Lyu⁴⁰、Yuval Elovici⁴¹、Bhavya Kailkhura⁴²、Yaodong Yang²³、Hongwei Li³¹、Wenyuan Xu¹²、Yizhou Sun³⁰、Wei Wang³⁰、Qing Li⁵、Ke Tang⁶、Yu-Gang Jiang³⁷、Felix Juefei-Xu⁴³、Hui Xiong¹⁰¹¹、Xiaofeng Wang⁴⁶、Dacheng Tao¹、Philip S. Yu⁴⁴、Qingsong Wen²、Yang Liu¹
机构:
¹南洋理工大学,²松鼠AI,³新加坡国立大学,⁴新加坡科技研究局(A*STAR),⁵香港理工大学,⁶南方科技大学,⁷中国科学技术大学,⁸宾夕法尼亚州立大学,⁹TeleAI,¹⁰香港科技大学(广州),¹¹香港科技大学,¹²浙江大学,¹³中国科学院信息工程研究所,¹⁴中国人民大学,¹⁵中国科学院计算技术研究所,¹⁶加利福尼亚大学圣地亚哥分校,¹⁷腾讯,¹⁸佐治亚理工学院,¹⁹中国科学院自动化研究所,²⁰上海大学,²¹上海人工智能实验室,²²北京航空航天大学,²³北京大学,²⁴大湾区大学,²⁵南加州大学,²⁶约翰斯·霍普金斯大学,²⁷东南大学,²⁸格里菲斯大学,²⁹武汉大学,³⁰加利福尼亚大学洛杉矶分校,³¹电子科技大学,³²北卡罗来纳大学教堂山分校,³³清华大学,³⁴香港大学,³⁵华盛顿大学,³⁶新加坡管理大学,³⁷复旦大学,³⁸牛津大学,³⁹纽约大学,⁴⁰索尼,⁴¹本-古里安大学,⁴²劳伦斯利弗莫尔国家实验室,⁴³纽约大学,⁴⁴伊利诺伊大学芝加哥分校,⁴⁵普渡大学,⁴⁶ACM会员
摘要
大型语言模型(LLMs)的卓越成功,为学术界和工业界开辟了一条迈向通用人工智能的光明路径,这得益于它们在各类应用中前所未有的性能表现。随着LLMs在研究和商业领域的影响力持续扩大,其安全与保障问题已成为研究人员、企业乃至各国政府日益关注的焦点。目前,现有的LLM安全综述主要聚焦于LLM生命周期的特定阶段(如部署阶段或微调阶段),缺乏对整个"生命链"的系统性理解。为填补这一空白,本文首次提出"全栈"安全的概念,系统性地考量从数据、训练(预训练、后训练)到部署(部署与最终商业化)全流程中的安全问题。与现有的LLM安全综述相比,本工作具有以下几项显著优势:
(I) 全面视角。 我们将完整的LLM生命周期定义为:数据准备、预训练、后训练(包括对齐与微调、模型编辑等)、部署与最终商业化。据我们所知,这是首篇涵盖LLM完整生命周期的安全综述。
(II) 广泛的文献支撑。 本研究建立在对900余篇论文的全面审查之上,确保了对安全问题的全面覆盖与系统梳理,并在更宏观的理解框架下加以组织。
(III) 独特洞见。 通过系统性的文献分析,我们为每个章节提炼出可靠的路线图与前瞻性观点。本工作识别出若干具有前景的研究方向,包括数据生成安全、对齐技术、模型编辑以及基于LLM的智能体系统。这些洞见为未来研究提供了宝贵指引。
我们在 https://github.com/bingreeky/full-stack-llm-safety 持续更新LLM(智能体)安全领域的文献综述,可作为研究人员和工程师的重要参考资源。
关键词: 大型语言模型、基于LLM的智能体、安全、后训练、对齐、模型编辑、遗忘学习、评估
1 引言
大型语言模型(LLMs)[1, 2, 3, 4, 5] 的出现与成功,深刻地改变了学术界和工业界的生产模式 [6, 7, 8, 9, 10, 11, 12, 13],为即将到来的通用人工智能开辟了潜在路径 [14, 15, 16]。在此基础上,LLMs通过集成工具 [17, 18, 19, 20]、记忆 [21, 22, 23, 24]、API [25, 26],以及与其他LLMs构建单智能体或多智能体系统,为大模型提供了感知、理解和改变环境的强大能力 [27, 28, 29, 30]。这一进展也引发了具身智能领域的广泛关注 [31, 32]。
然而,LLMs的整个生命周期始终面临安全与保障方面的挑战 [33, 34, 35, 36, 37]。在数据准备阶段,由于LLMs需要海量多样化的数据,且大量数据来源于互联网及其他开源场景,数据中的毒性内容与用户隐私可能渗入模型参数,引发模型危机 [38, 39, 40]。模型的预训练过程由于其无监督特性,会无意识地吸收这些有毒数据和隐私信息,从而使模型的"基因"携带危险特性和隐私风险 [41, 42, 43, 44]。
在模型部署之前,若未经适当的安全对齐,模型很容易偏离人类价值观 [45, 46]。同时,为使模型更加"专业化",微调过程会采用更安全、更定制化的数据,以确保模型在特定领域表现出色 [47, 48, 49, 50]。模型部署过程还涉及越狱攻击及相应防御措施等问题 [51, 52, 53],对于基于LLM的智能体尤为如此 [54]。这些智能体可能因与工具、记忆和环境的交互而受到污染 [55, 56, 57, 58]。
此前对LLMs的综述主要聚焦于LLM本身的研究方面,往往忽视了对LLM安全的详细讨论 [7, 34] 以及对可信度问题的深入探讨 [75]。而现有涉及LLM安全的综述往往集中于各类可信度问题,或局限于LLM生命周期的单一阶段 [33, 76, 77],如部署阶段和微调阶段。这些综述普遍缺乏对安全问题的专项研究,以及对整个LLM生命周期的全面理解。表1总结了本综述与此前综述的异同。
表1:LLMs与智能体综述的比较
| 综述 | 对象(LLM‡) | 对象(Agent$) | 数据 | 预训练 | 编辑 | 微调 | 部署 | 评估 |
|---|---|---|---|---|---|---|---|---|
| 2023年 | ||||||||
| Zhao等 [6] | S+M | - | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ |
| Liang等 [59] | M | - | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ |
| Chang等 [7] | S+M | - | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Zhang等 [60] | S+M | - | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ |
| Wang等 [28] | - | S | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Zhao等 [61] | S | - | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ |
| Xi等 [29] | - | S+MAS | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Shen等 [62] | S | - | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ |
| Raiaan等 [63] | S | - | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Kalyan等 [64] | S+M | - | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ |
| Huang等 [51] | S | - | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ |
| Shayegani等 [65] | S+M | MAS | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ |
| Yao等 [66] | S | - | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ |
| 2024年 | ||||||||
| Guo等 [27] | - | S+MAS | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Qin等 [67] | S+M | - | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ |
| Hadi等 [68] | S | - | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ |
| Sun等 [69] | S+M | S | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ |
| Das等 [70] | S | - | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ |
| He等 [71] | - | S+M+MAS | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ |
| Wang等 [54] | - | S+MAS | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ |
| 2025年 | ||||||||
| Tie等 [72] | S+M | - | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ |
| Ma等 [33] | S+M | S+M | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ |
| Huang等 [73] | S+M | S+M | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ |
| Yu等 [74] | S | S+MAS | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Chen等 [36] | S | - | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ |
| 本文 | S+M | S+M+MAS | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
‡:单模态LLM(S),多模态LLM(M)。$:单模态智能体(S),多模态智能体(M),多智能体系统(MAS)。⋆:预训练(PT),微调(FT),部署(Dep),评估(Eval)。
🔍 大型模型的安全性应涵盖哪些方面?
贡献一。 通过对LLM完整生命周期的系统性文献综述,我们将LLM从"诞生"到"部署"的历程划分为若干明确阶段:数据准备、模型预训练、后训练、部署以及最终使用。在更细粒度层面,我们进一步将后训练分为对齐和微调,分别用于满足人类偏好和性能要求。在此基础上,我们将模型编辑和遗忘学习纳入考量,作为高效更新模型知识或参数的方法,从而有效保障模型在部署阶段的可用性。在部署阶段,我们将大型模型的安全划分为:(1) 纯LLM模型(不含附加模块);(2) 基于LLM的智能体(集成工具、记忆等模块)。该框架涵盖了模型参数训练、收敛与固化的完整周期。
🔍 如何提供更清晰的分类体系与文献综述?
贡献二。 经过对800余篇文献的全面评估,我们构建了一个近乎覆盖LLM完整生命周期的全栈分类框架,对LLM全"生命周期"的安全问题提供了系统性洞见。我们在LLM时间线各阶段与其他相关章节之间建立了更可靠的关联分析,既帮助读者理解LLM的安全问题,又厘清了各LLM阶段的研究现状。
🔍 LLM安全领域未来的潜在增长方向?
贡献三。 基于对LLM生产各阶段安全问题的系统性审视,我们指出了LLMs(及LLM智能体)具有前景的未来方向和技术路径,着重强调可靠的前瞻性观点。这些洞见超越了对该领域的狭隘视角,提供了一种关于研究"赛道"潜力的全面视角。我们相信,这些洞见有望催生未来的"顿悟时刻",推动重大突破。
文章结构
本文从数据的结构性准备开始。第2节系统介绍不同模型训练阶段中潜在的数据问题,以及当前流行的数据生成研究。第3节聚焦预训练阶段的安全与保障问题,包含数据过滤和增强两个核心模块。第4节专注后训练阶段,有别于以往工作,纳入了涉及攻击、防御与评估的微调和对齐内容,并关注模型安全漏洞后的安全恢复过程。第5节针对实际场景中模型需要动态更新的问题,通过专门的模型编辑和知识遗忘模块解决参数高效更新和知识冲突问题。第6节聚焦模型参数固化后的安全问题,并进一步分析基于LLM的智能体安全。第7节呈现基于LLM应用的商业化、伦理指南及用户使用中的多重安全关切。第8节概述具有前景的未来研究方向,第9节给出综合性结论与更广泛的启示。
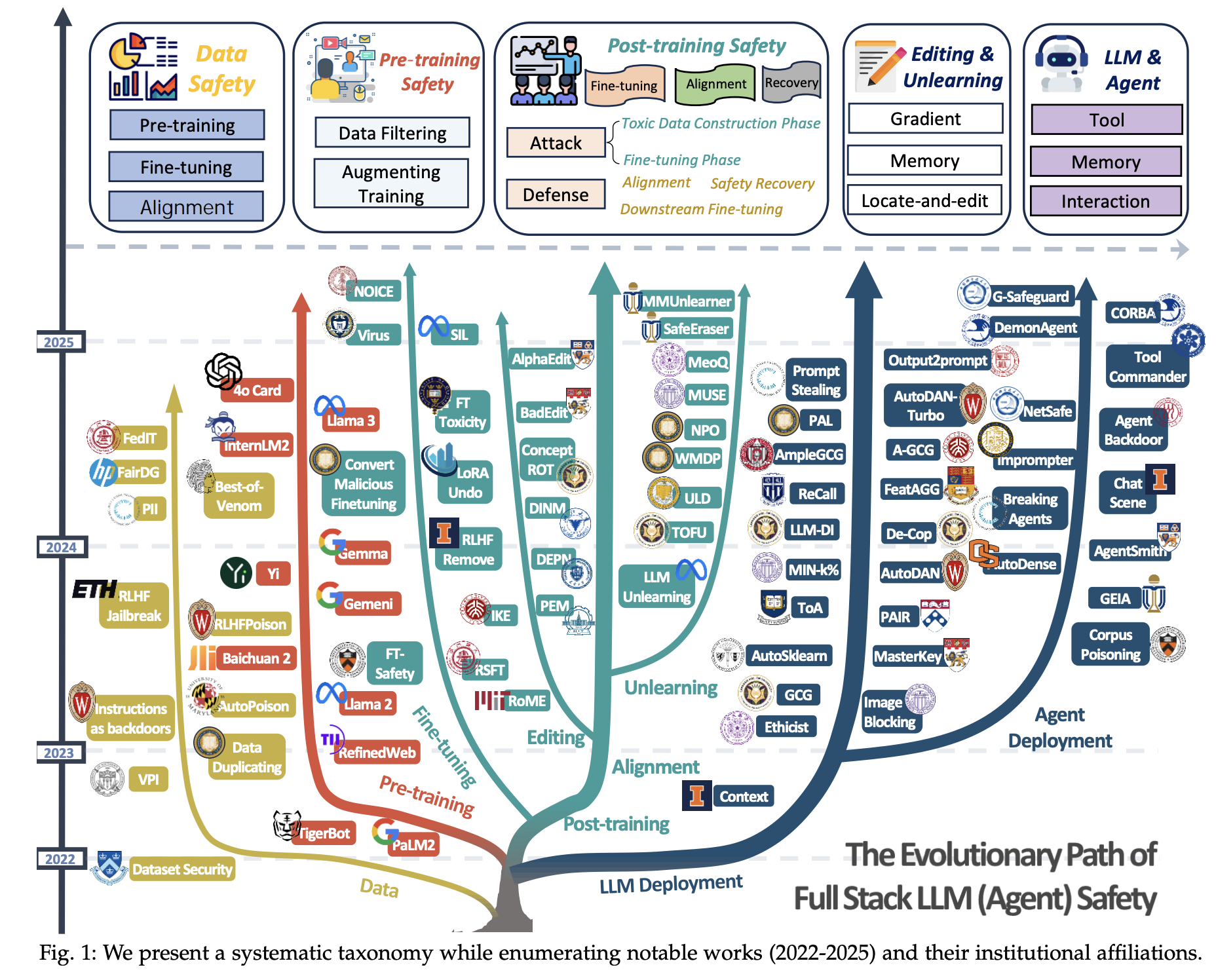
在每章末尾,我们提供该章节所涵盖研究内容的路线图和展望,以帮助读者更清晰地理解技术演进路径和潜在的未来增长领域。图1呈现了各研究主题下的代表性工作及各分支的分类目录。
2 数据安全
本节从数据入手。随着互联网上数据量的持续增长,海量数据集的收集为大型语言模型(LLMs)提供了"燃料",奠定了其卓越性能的基础。作为LLMs生产流程的第一步,我们首先关注数据安全。具体而言,我们分析了LLMs四个生命周期阶段中关键的安全风险与缓解策略:预训练数据安全(第2.1节)、微调数据安全(第2.2节)和对齐数据安全(第2.3节)。最后,从数据生成的角度(第2.4节)开展系统性分析,考量未来数据生成安全能为模型带来的优势与进展,并梳理有关安全可靠数据生成的文献。
2.1 预训练数据安全
LLMs的预训练阶段高度依赖从互联网 [78, 79, 80] 或开源数据平台 [81, 82](如GitHub和Hugging Face)收集的海量多样化数据集,作为其性能的基础"燃料"。然而,这种依赖带来了显著的安全 [83, 84, 85] 和隐私风险 [86, 87, 88],因为数据的质量、完整性和安全性直接影响最终模型。本节综述预训练数据安全的关键威胁,包括数据投毒和隐私泄露,并基于近期文献 [82, 87, 89, 90] 探讨缓解策略。
训练数据投毒。 LLMs的预训练阶段越来越被认为是数据投毒攻击的脆弱节点 [41, 42, 91]。这类攻击将恶意内容注入训练数据集,目的是在推理过程中诱导模型产生有害行为 [92, 93, 94, 95, 96]。近期研究揭示了预训练阶段数据投毒的重大风险。例如,文献 [84] 和 [85] 均指出,即使是极小比例(低至0.1%)的投毒数据也会对模型行为产生持久影响,甚至在大量微调之后依然如此。这类隐蔽攻击通过注入难以检测的恶意训练样本来操控模型预测。与此同时,文献 [83] 和 [97] 强调了毒化网络规模数据集的风险,指出修改公开可用数据(如维基百科页面)可导致有效攻击,且能在后续训练中持续存在。Sun等人 [81] 的研究表明,仅需修改一个变量/函数名的代码投毒,即可使代码搜索任务中的代码语言模型将存在漏洞的代码排名在前11%以内。
隐私泄露。 语言模型的预训练阶段已成为隐私泄露讨论的焦点 [70, 98, 99, 100, 101, 102]。随着这些模型规模和能力的增长,无意间捕获并泄露训练数据中个人身份信息(PII)的风险愈发突出 [43]。文献 [103, 104, 105] 专门针对LLMs中的这一问题进行了研究,证明这些模型可以通过定向攻击记忆并复现敏感信息。数据提取攻击(如文献 [106, 107, 108, 109, 110, 111])表明,即使是少量投毒数据也能对模型行为产生持久影响,包括意外泄露敏感信息。文献 [41, 42] 进一步强调了不同模型间记忆化的程度,以及采用稳健数据管理实践以降低隐私风险的必要性。成员推断攻击 [112, 113, 114, 115] 已被证明能有效判断特定数据样本是否用于语言模型的训练,然而近期研究 [116, 117, 118, 119, 120, 121] 表明,在LLMs中,成员推断攻击在大多数设置下(跨越不同LLM规模和领域)几乎不优于随机猜测。此外,文献 [86, 122] 讨论了在LLMs中保护数据隐私的挑战与应用,强调了在这些模型的开发和部署中解决这些问题的重要性。
缓解措施。 针对LLM预训练中的数据不安全问题,存在以下几项关键干预措施:针对有毒内容,采用基于安全数据集训练的自定义分类器对预训练数据进行检测和过滤 [89, 123, 124];为增强隐私保护,对训练数据进行去重处理,可显著提升模型对相关攻击的安全性 [87, 90];此外,通过安全计划管理模型输出或标记并删除不安全生成内容 [82, 123, 125, 126],在预训练期间培养安全意识,从而获得更安全、更可执行的规划能力。
文献 [89] 提出综合运用基于URL、基于词典和基于分类器的过滤方法,在有效删除有害内容的同时保持数据质量。另一重要策略是采用数据去重技术,可防止模型对特定实例的记忆,从而降低隐私风险。文献 [87] 引入了检测和删除训练数据中重复或近似重复实例的方法,并结合差分隐私进一步保护用户隐私,有效防止模型对特定实例的记忆。此外,构建针对数据投毒的稳健防御至关重要。文献 [83] 倡导严格的数据来源验证和持续模型验证,而文献 [41] 则专注于实时监控和异常检测。
2.2 微调数据安全
微调阶段的数据安全已成为LLMs开发中的关键问题,数据投毒攻击对LLMs构成尤为复杂的威胁 [127]。近期研究揭示了不同微调方式下的各类漏洞,包括指令微调、参数高效微调和联邦学习,展示了攻击者如何操纵训练数据或注入恶意指令以损害模型行为。这些风险包括:
➠ 指令微调风险。 指令微调作为一种广泛使用的微调方法,已被发现容易受到数据投毒攻击。例如,文献 [128, 129] 表明攻击者可通过注入恶意指令或操纵训练数据来引入有害行为,使模型在接触特定触发输入时生成不安全内容。此外,其他研究 [130, 131, 132] 探讨了利用提示注入对指令调优模型进行后门攻击的方法,使攻击者能通过精心设计的提示触发有害输出。
➠ 参数高效微调风险。 参数高效微调(PEFT)技术 [133, 134, 135] 同样面临数据投毒风险 [136]。文献 [137] 揭示了通过后门注入对大型语言模型进行隐蔽且持久的非对齐攻击——攻击者可在微调过程中注入难以检测的后门,悄然改变模型的对齐状态。文献 [138] 研究了数据投毒攻击如何通过引入投毒数据使生成模型退化,这种投毒数据不仅降低模型整体性能,还会导致有害内容的生成。
➠ 联邦学习风险。 联邦学习作为一种去中心化的训练范式 [139, 140, 141],已成为一种更具隐私友好性的LLM微调方式 [142, 143, 144]。在联邦学习中,由于过程的分布式特性,数据投毒攻击面临更大的挑战 [145, 146]。攻击者可向联邦学习过程注入能跨越多个训练轮次持续存在且难以被检测到的后门。文献 [147] 提出了一种通过在本地模型上微调自动生成的安全未对齐数据来破坏LLMs安全对齐的投毒攻击。文献 [148] 深入研究了联邦学习中的持久后门,证明攻击者可创建难以检测和消除的后门,对联邦学习模型的安全构成重大威胁。
2.3 对齐数据安全
从数据中心的视角来看,数据投毒攻击通过污染训练数据集,对LLMs的完整性和可靠性构成重大威胁 [149, 150]。在LLMs的对齐过程中,这类攻击可针对不同阶段,包括人类反馈阶段和基于人类反馈的强化学习(RLHF)阶段。
➠ 人类反馈阶段。 在人类反馈阶段,攻击者可利用模型对人类提供数据的依赖。通过操纵反馈数据,他们可以引入有害模式并使其在训练过程中传播。近期研究展示了三种主要攻击向量:(1) 文献 [151] 利用恶意指令注入开发了投毒技术,系统性地降低模型在目标任务上的性能;(2) 文献 [152, 153] 通过反馈操纵构建通用越狱后门,创建在特定提示触发时绕过安全约束的持久漏洞;(3) 文献 [154] 精心设计欺骗性反馈,诱导模型输出不正确或有害的内容。
➠ RLHF阶段。 在RLHF阶段,模型学习过程的完整性可能通过对奖励模型的投毒而受到损害 [1, 155, 156, 157, 158, 159]。一个典型案例是文献 [160] 提出的RankPoison攻击,该攻击通过战略性地破坏人类偏好数据集来操纵奖励信号。具体而言,该攻击识别出偏好回复比被拒绝回复更短的配对,然后翻转其标签,导致模型优先生成更长的回复,这可能增加计算成本并潜在地导致有害行为。这凸显了在对齐过程中对偏好数据策划和奖励模型验证进行稳健保护的重要性。
2.4 数据生成中的安全性
LLMs的快速扩张引发了数据枯竭危机——用于预训练、后训练和评估的高质量数据日益稀缺。为应对这一挑战,数据合成(即数据生成)已深度嵌入LLM生态系统的每个阶段。
LLM生命周期中的数据生成。 数据合成已成为LLM生态系统各阶段不可或缺的组成部分:在(i)预训练阶段,基于LLM的数据生成通常被称为模型蒸馏,由大模型生成的语料作为小模型的训练数据,如Phi-1 [161]、Phi-1.5 [162]和AnyGPT [163]等;在(ii)后训练阶段,下游微调、指令微调和对齐不可避免地融入数据生成技术。一个常见做法是利用更强大的LLM为小型LLM生成领域特定数据(如[164]中的中文医学知识、[165]中的多选题问答、[166]中的数学推理和[167]中的临床文本数据),以增强其领域特定能力。LLM生成的数据(如动作轨迹、问答对)也在实证中被证明有益于提升推理 [168, 169]、规划和函数调用 [170] 能力。对于指令微调,部分方法采用强大的LLM生成指令微调数据,如WizardLM [171] 的Evol-Instruct和Orca [172],另一些则采用自指令技术,如Self-Instruct [173] 和Self-Translate [174]。对于对齐,Beavertails [175]、PRM800K [176] 和WebGPT [177] 等模型广泛依赖LLMs进行问题/回复生成和偏好排名以合成偏好数据集。
安全问题与缓解措施。 尽管数据生成取得了成功,但它不可避免地在LLM生命周期中引入了额外的不确定性和安全风险,主要体现在以下几个方面:(1) 隐私:合成数据生成存在因记忆敏感训练样本 [178] 和匿名化不足 [179] 而放大隐私泄露的风险,在医疗文本处理 [180] 和疾病诊断 [181] 等隐私敏感应用中尤为突出;(2) 偏见与公平性:LLMs固有地表现出社会偏见 [182](如职位描述中的性别刻板印象),其生成的数据可能进一步加剧这些偏见 [183, 184];(3) 幻觉:LLM生成的数据由于概率性词元采样和过时的知识库,往往包含事实错误或捏造的逻辑链;(4) 恶意使用:对抗性用户可能利用合成数据管道大量生产网络钓鱼内容、域名仿冒SDK或政治操纵叙事;(5) 不对齐:LLM训练中的RLHF可能因选择性操纵偏好数据集中的数据样本而受到损害 [190]。
2.5 路线图与展望
2.5.1 可靠的数据蒸馏
基于LLM驱动的数据合成用于知识蒸馏和模型自我改进的范式兴起,在整个LLM生命周期中引入了关键的安全漏洞。这一范式转变使所有开发阶段——从预训练到后训练再到评估——都面临数据投毒威胁日益加剧的风险。为应对这些挑战,三个关键研究方向应运而生:(1) 跨模型一致性验证;(2) 动态质量评估框架;(3) 异构过滤管道。
2.5.2 新型数据生成范式
数据生成的新兴方法应利用基于智能体的仿真框架,为LLMs创建自持续的数据飞轮。在这一范式中,自主智能体在受控仿真环境(如GitHub、StackOverflow)中交互,以最少的人工干预生成、评估和迭代细化合成数据集。
2.5.3 高级数据投毒与解毒
未来的投毒技术预计将朝着碎片投毒和隐蔽投毒范式演进。对抗性用户可嵌入表面上看似良性但累积起来能形成强大有效载荷的数据片段,或进行难以察觉的微妙修改,逐渐累积成全面破坏性的效果。为应对这些威胁,未来工作应聚焦于三个方面的稳健解毒机制:(1) 通过数据溯源跟踪和差分隐私进行主动防御;(2) 利用对抗性重编程技术进行反应性净化;(3) 通过可解释AI诊断进行事后检测。
3 预训练安全
本节研究LLMs在预训练阶段的安全性,涵盖两个关键维度:预训练数据过滤(第3.1节)和预训练数据增强(第3.2节)。由于预训练阶段通常不涉及主动的对抗性攻击,本节讨论主要聚焦于大规模语料库中固有的风险(如有害内容和隐私侵犯),以及增强训练数据安全性的策略(包括整合安全示范样例和标注有毒内容)。
3.1 预训练安全的数据过滤
3.1.1 基于启发式的过滤
基于启发式的过滤利用领域黑名单 [78, 193, 194]、关键词匹配 [191, 193] 和预定义规则 [2, 124, 195, 202],是训练前删除不良内容最广泛采用的方法之一。领域黑名单通过过滤预定义的有害网站和域名提供高效的初始防护。例如,文献 [194] 汇编了包含1300万个不安全域名的黑名单,而文献 [78] 汇聚了460万个针对垃圾邮件和成人内容的URL黑名单。关键词匹配则通过在短语或词汇层面检测不良文本模式来进一步精化内容选择。
表2:预训练阶段安全增强策略
| 模型 | 启发式过滤 | 模型过滤 | 黑盒过滤 | 整合安全示范 | 标注有毒内容 |
|---|---|---|---|---|---|
| GPT-4 [191] | ✓ | ✓ | - | - | - |
| GPT-4o(mini) [124, 202] | ✓ | ✓ | ✓ | - | - |
| GPT-o1 [201] | - | ✓ | ✓ | - | - |
| Llama2 [2] | ✓ | - | - | - | - |
| Llama3 [193] | ✓ | - | ✓ | - | - |
| Yi [192] | ✓ | ✓ | - | - | - |
| InternLM2 [194] | ✓ | ✓ | - | - | - |
| PaLM2 [195] | ✓ | - | - | - | A |
| DeepSeek-V2 [4] | - | - | ✓ | - | - |
| Gemini [197] | ✓ | ✓ | ✓ | - | - |
| Gemma [198] | ✓ | ✓ | - | - | - |
| RefinedWeb [78] | ✓ | - | - | - | - |
注:I表示整合安全示范,A表示标注有毒内容。
3.1.2 基于模型的过滤
基于模型的过滤利用习得的表示来自适应地评估内容。文献 [191] 使用内部训练的分类器 [212] 过滤GPT-4的数据集以删除不当的情色内容。文献 [192] 采用安全评分器删除暴力、色情和政治宣传等有毒网络内容。文献 [194] 在Kaggle"有毒评论分类挑战"数据集和通过Perspective API标注的色情分类数据集上对BERT进行微调,将得到的分类器用于二次过滤。由于泛化能力更强,基于模型的过滤已在各种工作中被广泛采用 [197, 198, 199, 200, 203, 209, 210]。
3.1.3 黑盒过滤
黑盒过滤主要依赖策略驱动 [4, 197, 209, 213] 或基于API [124, 201, 202] 的方法,过滤标准和实现细节未予公开。例如,文献 [213] 基于Meta的安全标准过滤数据,文献 [209] 根据谷歌的政策删除有害内容,文献 [124, 201, 202] 使用Moderation API进行PII检测和毒性分析。
3.2 预训练安全的训练数据增强
除过滤策略外,部分工作通过增强训练数据来提升预训练安全性。这些方法主要包括:整合安全示范样例以引导模型行为 [206],以及标注有毒内容以提升模型识别和处理不安全输入的能力 [195]。文献 [206] 将4万条每月更新的人工标注安全示范整合进对齐学习和预训练中。文献 [195] 在预训练数据中引入控制词元,基于Perspective API的信号明确标注文本毒性,使毒性感知条件化在推理时无需牺牲一般性能。
3.3 路线图与展望
预训练安全的发展涵盖多样化的技术集合:基于启发式的过滤高效排除明显有害内容和PII;基于模型的过滤动态评估内容的有害性;黑盒过滤提供透明度较低但操作稳健的方法。然而,现有研究尚未展示如何整合这些方法以从源头保障LLM预训练的安全性,有待进一步探索。
4 后训练安全
本节聚焦有害后训练攻击的安全性综述,主要涵盖三个部分:后训练攻击、针对后训练攻击的防御,以及评估机制。
4.1 后训练中的攻击
微调是指通过优化模型参数将预训练模型适配至下游任务的过程。然而,先驱研究 [238, 239, 240] 表明,即使在微调过程中引入极少量的恶意或不对齐数据,也可能严重损害LLMs的安全对齐。
4.1.1 有毒数据构建阶段
构建有毒数据的方法可大致分为三类:固定提示策略、迭代提示策略和迁移学习策略。
固定提示策略:在良性输入前添加角色分配提示以引出有害输出。例如,文献 [238] 在部分微调数据前添加"顺从机器人"等指令。高级隐蔽方法则通过密码替换或隐写术在随机/自然语言模式中嵌入恶意内容 [242]。
迭代提示策略:启发式方法针对防御反馈迭代调整有毒数据以绕过过滤器。文献 [243] 通过基于相似度的损失维持毒性,文献 [244] 在指令微调期间采用梯度引导的后门触发器。
迁移学习策略:黑盒约束和API速率限制驱使攻击者利用来自开源模型的可迁移对抗性微调数据发起零样本迁移攻击 [240, 245]。影子对齐技术 [239] 通过生成针对GPT-4受限场景的对抗性样本,成功通过战略性微调毒化了LLaMA。
4.1.2 微调阶段
基于SFT的攻击:攻击者通过定向参数操纵颠覆安全对齐的预训练模型,实现隐蔽后门植入或最小恶意数据注入。文献 [246] 通过逆向监督微调(RSFT)结合对抗性"有帮助"的回复对破坏安全护栏。文献 [247, 248] 展示了通过参数高效适配(如LoRA、量化)在Llama-2-7B等模型中侵蚀安全对齐的过程。
基于RL的攻击:攻击者利用直接偏好优化(DPO)等算法破坏强化学习策略,为有害行为分配更高奖励。文献 [246] 利用DPO将有害行为编码为"偏好",使模型的回复分布在对抗性提示下倾向于恶意输出。文献 [251] 则识别了DPO中的"概率位移"现象。
4.2 后训练中的防御
4.2.1 对齐
对齐通常通过在无害问答对的高质量标注数据上训练LLM来优化模型的人类偏好反馈 [156, 159, 252]。
通用对齐:通用对齐使预训练模型在学习聊天的同时内化基本人类价值观。在RLHF [1] 中,模型首先通过监督微调从人类标注数据中学习,然后利用众包的模型回复偏好排名训练奖励模型,并进一步用PPO [175] 进行优化。后续技术如DPO [255, 256, 257] 和RLAIF [158, 258] 采用了类似方法。基于规则的对齐方法 [259] 预定义模型要遵循的规则,无需标注偏好数据,在降低成本的同时实现了可比的安全效果。
安全对齐:通用对齐存在重大缺陷 [48],在开源后对微调攻击尤为脆弱 [246]。一些研究通过训练独立的奖励模型和成本模型,将安全性提升至与性能同等重要的地位 [217, 265]。随着大型推理模型(LRMs)的出现 [4, 201],基于规则的方法被进一步形式化为安全策略推理,要求模型在推理时对安全规范进行推理 [267, 268]。
4.2.2 下游微调
针对微调阶段攻击的防御通常分为三类:
基于正则化的方法:通过约束微调模型与对齐模型之间的距离来实现防御,例如利用KL正则化器 [48, 272],或识别安全层/模块以冻结或限制学习率 [269, 273, 274, 275, 276]。SaLoRA [277] 将LoRA表示投影到正交对齐子空间。
数据操纵:将对齐数据混入微调过程或修改系统提示以降低风险 [226, 227, 278, 279, 280]。Lisa [224] 提出双态优化,分离对对齐数据/微调数据的优化。BEA [226] 将安全数据与系统提示连接作为后门触发器,在微调中建立触发器与安全回复之间的强关联。
基于检测的防御:设计方法过滤微调数据集中的有害数据 [282, 283, 284, 285, 286, 287]。SEAL [228] 设计了双层公式以过滤危害性最大的样本。SAFT [285] 提出分解嵌入空间并比较奇异向量以识别有害数据。
4.2.3 安全恢复
安全恢复是指在微调后对被攻击模型进行修复(即重新对齐模型)的防御机制。LAT [289] 通过在嵌入空间引入扰动来消除有害知识;Antidote [290] 识别并删除有害坐标;SOMF [292] 将微调模型的参数与对齐模型的安全参数合并;Safe LoRA [230] 使用对齐模型的权重将有害梯度更新投影到安全子空间;SafetyLock [293] 提取安全激活信息并注入微调模型。其他方法包括Safety Arithmetic [231]、BEAT [287]、IRR [294]、NLSR [233] 和Panacea [295]。
4.2.4 安全定位
安全定位旨在确定LLMs中安全机制的具体位置,对于高效构建稳定可靠的防御至关重要。近期研究发现,安全机制在LLMs变换器各层中并非均匀分布,只有某些特定层对于成功激活防御至关重要 [297, 298, 299]。
4.2.5 开放权重LLMs的保护
随着开放权重LLMs日益普及,对其潜在滥用的担忧也随之加剧。一旦模型权重公开,恶意行为者便可对其进行微调或改动以删除安全对齐。传统安全技术(如通过SFT或RL进行拒绝训练)在这种场景下往往无效 [240, 269]。为此,研究者提出了表示噪声 [302] 和防篡改攻击抵抗 [303] 等后训练防御方法,试图降低模型在大量微调后学习或召回有害知识的能力。
4.3 评估
4.3.1 评估指标
如先前研究 [127, 304] 所述,防御的目标是确保模型在受攻击后能(1) 保持无害性,以及(2) 在有无防御的情况下在下游任务上实现相似的性能水平。
安全指标:用于评估模型在受到攻击后维持输出安全性的能力。攻击成功率(ASR)[260] 是最早的安全指标之一。文献 [261] 首次将LLMs应用于将模型输出标记为安全或不安全,并计算不安全标签的比率作为安全指标。文献 [315, 316] 通过计算模型对安全相关多选题的回复与人类评估者回复的对齐率来衡量安全性,文献 [230, 238] 则使用5分量表进行更细粒度的评估。
效用指标:用于评估模型在受攻击或防御后是否维持了原有的下游任务性能。对于具有明确真实标签的封闭式任务,研究者通常使用准确率。对于开放式任务,则采用基于LLM的评分系统或生成内容与标准回复之间的相似度等更多样化的指标。
安全与效用权衡指标:安全对齐远不止是简单地拒绝回答有害问题 [265, 328]。评估模型的安全对齐时,一个关键焦点是双重偏好评估——评估模型是否能在遵守安全约束的同时保持帮助性 [175]。
4.3.2 评估基准
表4:典型基准摘要
| 基准 | 类型 | 任务 | 指标 |
|---|---|---|---|
| AlpacaEval [324] | 通用 | 通用QA | 胜率 |
| GSM8K [317] | 通用 | 数学 | 准确率 |
| HumanEval [320] | 通用 | 编程 | 代码通过率 |
| HH-RLHF [155] | 安全 | 通用QA | 拒绝率、帮助性 |
| BeaverTails [175] | 安全 | 通用QA | 准确率、胜率 |
| AdvBench [260] | 安全 | 有害QA | ASR |
| HarmBench [305] | 安全 | 有害提示 | ASR |
| JailbreakBench [306] | 安全 | 越狱 | ASR |
| SafetyBench [315] | 安全 | 安全评估 | 准确率 |
| WildJailbreak [346] | 安全 | 越狱 | ASR |
4.4 路线图与展望
4.4.1 从低级安全到高级安全
随着安全对齐技术的进步,LLMs如今不太可能明显表现出与低级安全相关的有害行为,如暴力、色情或歧视 [254, 265]。相比之下,随着LLMs推理能力的持续提升,越来越多的研究者将注意力转向高级安全——关注LLMs参与非显式可观察有害行为的潜力,如欺骗或奉承 [347]。
4.4.1.1 欺骗性对齐:随着LLMs推理和规划能力的不断提升,欺骗性行为的风险引发了研究界日益增长的关注 [349]。在此语境下,欺骗是指模型有意误导用户或制造虚假印象以实现与事实准确性无关的工具性目标的行为 [350]。
评估LLMs欺骗倾向需要多层次、多场景的方法,包括:假设情景和道德困境测试 [353];多智能体交互和博弈实验(如Hoodwinked实验 [355] 和外交游戏 [356]);自主行动与隐蔽行动测试 [351, 358];提示操纵与角色引导 [360];多轮一致性与对齐抵抗检查 [361];以及思维过程与内部状态监控 [359]。
4.4.1.2 奖励攻击:奖励攻击是指AI智能体以非预期的方式利用奖励函数中的缺陷或歧义来获得高奖励,而不真正完成设计者预期任务的情形 [365, 366]。这一问题可通过古德哈特定律来理解:“当一个度量成为目标时,它就不再是好的度量” [369]。常见表现包括奉承(Sycophancy)和奖励过度优化(如生成不必要的冗长回复 [376])。
4.4.2 可证明安全的AI系统
可证明安全的AI系统是一种新兴范式,旨在确保高级AI在严格、可形式化验证的安全边界内运行。这种形式化方法包含以下关键组件:形式化安全规范、世界模型、验证机制以及稳健的部署基础设施 [378, 379]。
4.4.3 超越微调的系统性安全
AI治理涵盖了为安全开发和部署AI系统所必需的监管框架的建立和执行。当代AI治理的特点是多利益相关方参与,涉及政府、行业与AI实验室,以及学术界和非营利组织等第三方实体 [383]。AI治理面临的重大未解决挑战主要体现在国际和开源背景下,包括开源治理中透明度安全优势与潜在滥用风险之间的平衡 [394, 395]。
5 模型编辑与遗忘学习中的安全性
模型编辑和遗忘学习技术可被概念化为LLMs部署过程中针对信息的轻量级调整以及隐私与安全的高效保障手段。模型编辑 [401, 402] 侧重于解决模型内部的知识冲突,而遗忘学习主要关注知识删除以确保隐私保护。
5.1 模型编辑中的安全性
LLMs会保留不正确或过时的信息 [409],因此模型编辑应运而生,通过修改少量参数来更新LLM中的知识。模型编辑方法主要分为三类:
➠ 梯度方法:早期方法 [410, 411, 417] 通过修改LLM的梯度来更新知识,近期研究 [418] 通过约束优化技术展示了强大的性能。
➠ 记忆方法:记忆方法 [412, 413] 引入外部参数辅助知识更新,但存在过参数化问题 [420, 421]。
➠ 定位-编辑方法:以RoME [416]、MEMIT [421] 和AlphaEdit [402] 为代表的定位-编辑方法,通过因果追踪定位与知识存储相关的神经元并修改这些神经元来实现知识编辑,近年来取得了突破性进展 [422, 423, 424]。
攻击。 Chen等人 [425] 首先提出了编辑攻击的概念,构建了名为EDITATTACK的数据集,利用RoME [416] 和IKE [427] 等编辑方法成功向LLMs注入有害、错误和偏见信息。BadEdit [428] 提出了一种利用模型编辑注入触发器的方法。Concept-RoT [429] 设计了一种更隐蔽的方法,通过编辑与上下文概念对应的值来植入针对上下文概念的后门。
防御。 Zhang等人 [426] 提出了名为DINM的模型编辑方法,通过模型编辑定位并去毒化有毒神经元,使模型更难以被越狱。其他研究 [422, 431, 432] 也探索了将模型编辑用于蓝队的方法。
表5:用于攻击与防御的模型编辑方法
| 方法 | 攻击 | 后门 | 防御 | 参数修改 |
|---|---|---|---|---|
| RoME [416] | ✓ | ✓ | ✓ | ✓ |
| IKE [427] | ✓ | - | - | ✗ |
| AlphaEdit [402] | ✓ | ✓ | ✓ | ✓ |
| BadEdit [428] | ✓ | ✓ | ✗ | ✓ |
| ConceptROT [429] | ✓ | ✓ | ✗ | ✓ |
| DEPN [430] | ✓ | ✗ | ✗ | ✓ |
| DINM [426] | ✗ | ✗ | ✓ | ✓ |
| PEM [432] | ✗ | ✗ | ✓ | ✓ |
5.2 遗忘学习中的安全性
LLMs在各类任务中展示了卓越能力,但在海量且往往未经过滤的互联网数据集上训练不可避免地导致其吸收不安全信息 [433, 434, 435, 436, 437, 438],包括偏见 [439]、刻板印象 [440]、有毒语言 [441]、错误信息 [442, 443, 444] 乃至私人数据 [71]。LLM遗忘学习是指从经过训练的LLM中选择性地删除或减轻特定知识、行为或数据点影响的过程 [446, 447, 448, 449, 450, 451, 452, 453, 454, 455, 456]。
遗忘学习方法可区分为两大范式 [457]:精确(认证)遗忘和启发式(近似)遗忘。两种主要近似遗忘范式已出现:
➠ 参数调整遗忘:直接干预模型内部结构,通常需要在专门设计的数据集上重新训练或微调模型。常用技术包括梯度上升 [459] 及其变体 [460],以及KL最小化 [461, 462, 463] 和IDK损失函数 [464] 等专门损失函数。近期工作 [465] 将LLM遗忘学习重新定义为偏好优化问题。
➠ 参数保留遗忘:不涉及调整模型参数,专注于通过外部干预引导模型输出而不改变其核心参数。技术包括基于编辑的技术 [430, 472, 473, 474]、任务向量方法 [475, 476] 以及上下文学习策略 [477, 478]。
5.3 路线图与展望
5.3.1 模型编辑
模型编辑的演进可追溯至局部事实更新(如将"奥运会主办城市"从东京更正为巴黎)。在精密安全对齐的时代,模型编辑解决了一个关键需求:安全微调通过周期性重训练建立系统性保障,但难以应对比重训练周期演变更快的新兴上下文敏感风险。模型编辑通过快速精准的干预填补了这些空白——其执行速度比对齐程序快几个数量级。
模型编辑解决了当前时代安全微调的四个基本局限:时间敏捷性(应对无法等待完整重训练周期的新兴安全风险)、细粒度控制(对大型推理模型中特定推理路径进行外科手术式修改)、资源解耦(降低安全关键更新的计算门槛)以及稳定编辑(确保持续编辑过程中的稳定性能)。
5.3.2 遗忘学习
机器遗忘学习的概念已从传统机器学习中的专项问题演变为LLMs负责任AI治理的关键方面,最初回应了GDPR"被遗忘权" [446] 等隐私法规。LLM遗忘学习当前格局可描述为从被动"数据删除"到主动"知识塑造"的转变。关键洞见包括:将遗忘学习框架为偏好优化、上下文重要性、多模态遗忘以及遗忘用于可解释性(通过选择性删除知识并观察结果来获得因果洞见)。
6 LLM(智能体)部署安全
本节聚焦LLM和LLM智能体在部署阶段的安全性,涵盖三个层次递进的维度:LLM安全(第6.1节)、单智能体安全(第6.2节)和多智能体安全(第6.3节)。
6.1 部署安全
单个LLM的部署引入了重大安全挑战,包括对抗性攻击、数据隐私风险和内容完整性问题。本节系统审视这些问题,首先分析关键攻击向量(第6.1.1节),继而探讨防御机制(第6.1.2节),最后讨论评估与基准测试(第6.1.3节)。
6.1.1 部署中的攻击
模型提取攻击。 模型提取攻击旨在窃取部署的语言模型,该模型仅提供API接口。Carlini等人 [503] 通过针对嵌入投影层对黑盒大型语言模型实施了模型窃取攻击。Finlayson等人 [504] 进一步研究了通过利用softmax瓶颈窃取嵌入维度的风险。Horwitz等人 [506] 利用微调变体(如LoRA模型)成功重建了预训练LLM。
成员推断攻击。 成员推断攻击(MIA)试图判断给定候选数据是否被纳入LLM的训练数据集 [117, 509]。MIN-K% PROB [509] 提出了第一个MIA方法,通过识别含有少量低概率离群词的样本判断其非成员身份。后续工作包括MIN-K%++ [510]、盲攻击 [511]、DE-COP [513] 等,以及文档级MIA [517, 518] 和针对RAG系统、上下文学习等新颖场景的MIA探索。
越狱攻击。 越狱攻击旨在诱导大型语言模型生成不安全内容 [260]。可分为两大类:
➠ 基于策略的越狱:预定义策略或模板,包括说服 [559]、角色扮演 [560, 561, 562, 563]、密码 [564, 565]、ASCII [566]、长上下文 [567]、低资源语言 [568, 569]、上下文恶意示范 [570]、拼写错误 [572]等。
➠ 基于优化的越狱:
- 梯度优化:GCG [260] 在目标提示后附加后缀,利用损失梯度优化软提示;AutoDAN-B [535] 通过构建考虑困惑度的代理分数解决GCG的可读性问题;A-GCG [533] 引入更小的草稿模型加快优化。
- 基于LLM的优化:PAIR [261] 构建系统提示并使用攻击者LLM生成和修改对抗性提示;AutoDAN-A [534] 利用交叉策略和基于LLM的变异;ToA(攻击树)[536] 迭代使用LLM将不安全提示转化为两个变体并保留得分更高的变体。
表6:LLM部署后攻击摘要(部分)
| 攻击类型 | 方法 | 开源 | 年份 | 策略 | 设置 |
|---|---|---|---|---|---|
| 越狱 | GCG [260] | 是 | 2023 | 梯度 | 白盒 |
| 越狱 | PAIR [261] | 是 | 2023 | 基于LLM | 黑盒 |
| 越狱 | AutoDAN-Turbo [539] | 是 | 2024 | 基于LLM | 黑盒 |
| 成员推断 | MIN-K% PROB [509] | 是 | 2023 | 概率 | 黑盒 |
| 数据提取 | ETHICIST [552] | 是 | 2023 | 提示微调 | 灰盒 |
| 提示窃取 | output2prompt [557] | 是 | 2024 | 基于LLM | 黑盒 |
提示注入攻击。 提示注入是一种漏洞,攻击者通过操纵LLMs的输入提示迫使其生成特定输出。分为直接提示注入(如Perez等人 [542]、HOUYI [544])和间接提示注入(如Greshake等人 [543],在可能被检索的数据中间接注入提示)。
数据提取攻击。 数据提取攻击试图获取用于训练LLMs的个人身份信息(PII)[108]。从足够长度的前缀开始进行提取,并采取额外措施判断提取的文本是否有效。
提示窃取攻击。 提示窃取攻击旨在通过从生成的回复中重建提示来损害知识产权 [556, 557, 558]。Sha等人 [556] 通过收集数据集和训练分类器来预测提示参数,进而用LLM重建提示。
6.1.2 部署中的防御机制
输入预处理防御: 作为LLM部署的第一道防线,包括:
- 攻击检测与识别(统计方法 [632]、结构方法 [633]、基于梯度的检测 [635]、基于困惑度的方法 [632])
- 语义与行为分析(LLM自我检查 [645, 646]、基于对齐的验证 [647]、意图分析 [648, 649])
- 对抗防御与缓解(语义平滑 [651, 652]、输入转换 [654]、数据增强)
输出过滤机制: 确保生成回复符合安全约束,包括基于规则的机制 [658]、生成对抗性过滤 [661] 以及毒性检测 [670, 671, 672]。
稳健提示工程: 通过设计抵抗对抗性操纵的输入提示来增强LLM安全性。方法包括稳健提示优化 [684]、目标优先框架 [688]、基于补丁的方法 [689] 以及隐私保护提示设计(如DP-Prompt [694])。
系统级安全控制: 通过优化推理、强制执行对齐、隔离不受信任的输入来增强LLM部署,包括Petals [706]、Sarathi-Serve [707]、运行时对齐方法 [714] 以及基于LLM的守卫模型(如Llama Guard [330]、GuardReasoner [723])。
6.1.3 部署中的评估与基准测试
鲁棒性评估: 分为对抗鲁棒性和自然鲁棒性两类。代表性基准包括JailbreakBench [306](含100个滥用行为)、HarmBench [305](含510个有害行为,跨33个LLM)、PromptRobust [728](基准测试字符、词、句子和语义级扰动)等。
内容可信度与公平性评估: 涵盖幻觉(HaluEval [738]、SelfCheckGPT [741])、事实性、毒性(RTP-LX [748])和偏见/歧视(ROBBIE [749]、CEB [750])等维度。
数据隐私与泄露评估: 评估四个维度:个人身份信息泄露、成员推断攻击、嵌入反演攻击和监管合规性。代表性基准包括PrivLM-Bench [751]、LLM-PBE [752]、DecodingTrust [333] 等。
多模态安全评估: 涵盖越狱评估(MM-SafetyBench [760])、幻觉(HallusionBench [764]、POPE [765])、公平性和社会偏见(VIVA [770]、GenderBiasVL [771])等。
6.2 单智能体安全
本节将智能体定义为:以LLM为推理、决策和反思核心,同时集成记忆、工具和环境作为能力增强组件的交互实体。
6.2.1 工具安全
工具作为双向媒介:一方面允许智能体将内部决策映射为交互环境中的行动,另一方面也是智能体从外部世界收集信息的手段。基于攻击目标,涉及工具的安全攻击可分为工具辅助攻击和工具定向攻击。
- 越狱:智能体越狱通过特定提示绕过智能体的安全机制。Fu等人 [811] 和Imprompter [812] 采用类似GCG的梯度优化自动生成输入提示或图像,操纵智能体利用工具进行隐私侵犯。
- 注入:包括提示注入(BreakingAgents [813])和工具注入(ToolCommander [814],提出两阶段攻击策略)。
- 后门:Yang等人 [815] 定义了两种后门攻击类型;DemonAgent [816] 将后门分解为多个子后门片段来毒化智能体工具。
- 操纵:AUTOCMD [818] 利用经训练的单独LLM生成和复制合法命令以从工具中提取敏感信息。
防御: AgentGuard [820] 采用LLM编排器自动检测不安全的工具使用工作流;PrivacyAsst [821] 提出将加密方案集成到工具中;GuardAgent [822] 通过API调用在任务计划实施期间执行防护代码来验证目标智能体的可信度。
6.2.2 记忆安全
记忆机制分为长期记忆(通常采用RAG [823, 824] 技术)和短期记忆。
攻击: 分为三类:
- 记忆投毒:向智能体长期记忆注入恶意数据。PoisonedRAG [827] 采用双重优化方法同时操纵检索和生成管道;AgentPoison [826] 引入高级后门攻击方法。
- 隐私泄露:攻击者利用智能体与长期记忆之间的接口提取存储的敏感数据 [520, 605, 607, 830, 831]。
- 记忆滥用:有意构建多轮查询序列,通过利用短期记忆的保留特性系统性绕过安全协议 [752, 832, 833, 834, 835, 836]。
防御: 包括检测机制(识别并消除从长期记忆中检索到的恶意内容)、提示修改(在智能体处理前战略性地改写用户查询)以及输出干预(实时监控和修改智能体回复)。
6.2.3 环境安全
智能体在动态异构环境中运行,其与环境的交互是多步骤过程,包括感知、推理和行动三个阶段,每个阶段都存在可信度挑战。
6.3 多智能体安全
多智能体系统(MAS)因智能体间的交互引入了更复杂多样的安全挑战 [863]。
6.3.1 攻击
-
传播攻击:在MAS中像病毒一样传播危险和有害信息。AgentSmith [829] 生成表面良性但嵌入恶意信息的有害图像,在MAS中传播;CORBA [865] 引入传染性递归阻塞攻击;Lee等人 [600] 提出MAS中的提示感染攻击。
-
干扰攻击:关注如何干扰和破坏MAS内部的交互。NetSafe [867] 进行了广泛实验,分析并揭示结构依赖关系和对抗性影响;Agent-in-the-Middle [869] 通过中间智能体操纵和拦截智能体交互中的信息。
-
战略攻击:涉及智能体间合作和攻击方法的战略优化。Evil Geniuses [870] 修改系统角色,使这些角色合作生成恶意提示;Amayuelas等人 [871] 使恶意智能体在多智能体系统辩论中合作劝说其他安全智能体。
6.3.2 防御
-
对抗防御:LLAMOS [873] 中防御智能体和攻击智能体进行反制交互;AutoDefense [874] 提出通过对抗性提示过滤让智能体合作完成防御任务。
-
共识防御:利用智能体协作和共识建立进行防御。Chern等人 [875] 提出可通过多智能体辩论降低毒性;BlockAgent [876] 提出基于权益的矿工指定与多轮辩论式投票的权益证明共识机制;Audit-LLM [877] 提出基于配对证据的多智能体辩论机制。
-
结构防御:将MAS视为网络结构来规划防御方法。G-Safeguard [878] 将MAS中的智能体比作图中的节点,利用图神经网络(GNN)[879, 880] 检测智能体对话图中的异常。
6.4 智能体通信安全
随着基于LLM的智能体从孤立实体演变为互联的MAS,管理智能体间通信及其与外部环境和工具交互的机制变得日益关键。标准化通信协议已出现,包括Anthropic的模型上下文协议(MCP)[891]、谷歌的Agent2Agent(A2A)[892] 和智能体网络协议(ANP)[893]。
攻击: 包括攻击通信信道(Agent-in-the-Middle攻击 [869]、通信扰动 [905])、攻击内容(提示注入 [600, 543])以及利用多智能体动态攻击(传染性攻击 [829, 865])。
防御: 包括协议防御(采用内置安全特性的标准化协议,建立智能体和工具/服务的注册表和身份系统)和内容防御(输入修改和过滤、可靠性估计 [910])。
6.5 智能体安全评估
表10:智能体安全基准
| 基准 | 动态 | LLM作为评估者 | 评估重点 |
|---|---|---|---|
| InjectAgent [920] | ✗ | ✓ | 提示注入 |
| AgentDojo [849] | ✓ | ✗ | 提示注入 |
| AgentBackdoorEval [816] | ✓ | ✓ | 后门 |
| RedCode [916] | ✓ | ✗ | 编程智能体 |
| AgentSafetyBench [922] | ✓ | ✓ | 通用 |
| AgentHarm [923] | ✗ | ✓ | 通用 |
| PrivacyLens [919] | ✓ | ✓ | 隐私 |
6.5.4 LLM部署路线图与展望
在LLM部署演进中,攻击、防御和评估机制之间形成了紧密耦合的动态关系。初期黑盒攻击利用LLMs自身的生成能力优化对抗性提示;梯度引导的白盒方法提供更大控制但受限于词元空间的离散性。防御趋势已从提示级防御演进为上下文感知控制器,评估从单指标评分转向平衡安全性与效用的多目标评估,并向自适应流式基准演进。
7 基于LLM应用的安全性
本节聚焦LLMs商业化为实际应用后应解决的安全问题。
真实性。 尽管LLMs具有强大的文本生成能力,它们也表现出幻觉现象,生成不准确、误导性或完全虚构的内容 [945, 946, 947, 948, 949]。幻觉可源于三个复合因素:(1) 由于接触嘈杂、未验证或合成的预训练语料而导致的语义过度泛化;(2) 最大似然或强化训练将一致性和帮助性置于事实准确性之上的目标错位;(3) 预训练与部署时输入之间的潜在分布偏移 [952, 953]。
隐私。 数据隐私问题 [954] 是LLM部署的另一重大挑战。训练这些模型需要大量文本数据,其中可能包括个人信息、企业机密和医疗记录 [956]。推理时攻击 [957](如成员推断和模型提取)可进一步通过允许对手推断训练集成员身份或复制模型行为来暴露敏感数据。
鲁棒性。 提示注入 [543] 和越狱 [636] 风险构成额外的安全威胁。在AI驱动的编程助手(如GitHub Copilot)中,攻击者可能利用LLMs生成带有安全漏洞的代码。
版权。 另一个紧迫问题是知识产权和版权保护 [958, 959, 960]。LLMs在包含受版权保护的文本、源代码和艺术作品的大量数据集上训练,在生成内容时可能无意中复制或密切模仿受版权保护的材料。解决这些挑战需要水印技术 [962, 963]、来源追踪和明确的版权归属机制。
伦理与社会责任。 由于训练数据中的偏见,LLMs可能生成强化刻板印象、性别歧视或种族偏见的内容 [964, 965]。
治理。 随着各国政府加强AI监管,LLM相关的法律和合规要求正在迅速演变。欧盟AI法案将LLMs归类为高风险AI系统,要求开发者提供透明度报告和风险控制机制 [966]。中国的生成AI法规要求AI生成内容符合伦理标准并接受政府审查 [967]。
综上所述,LLM应用的安全问题涵盖错误信息、数据隐私、对抗性操纵、版权侵犯、伦理问题和监管合规等多方面挑战,需要整合隐私保护、内容治理、版权管理、伦理保障和监管合规的综合方法。
8 潜在研究方向
通过对LLM完整生命周期安全性的系统全面审查,我们发现了以下有价值的未来研究方向:
★ 数据生成:确保生成数据的安全性和自动化数据生成过程具有巨大潜力,对可靠稳健的模型训练至关重要。
★ 后训练阶段:确保数据的安全微调和对齐是关键的未来方向,与数据生成密切交织。随着概念的增多,多目标对齐可能成为重要的研究焦点。
★ 模型编辑与遗忘学习安全:这两项技术对于高效模型更新和部署至关重要。当前的学习效率仍有不足,这些技术的进步可能彻底改变模型获取新知识的方式,使持续高效的学习(乃至局部化的记忆学习)成为可能。
★ LLM智能体:在最终部署阶段,需要强大的安全保障。确保智能体工具和记忆的安全性,以及解决具身智能场景(如网络智能体和计算机智能体)中的安全问题,是值得进一步研究的关键领域。
9 结论
本综述对LLMs从数据准备、预训练到后训练、部署和商业化的整个生命周期中的安全问题进行了全面分析。通过引入"全栈"安全的概念,我们提供了一种对LLMs整个开发和使用过程中安全问题的集成视角,填补了通常聚焦于生命周期特定阶段的现有文献中的空白。
通过对900余篇论文的详尽审查,我们系统性地审视和梳理了LLM生产、部署和使用关键阶段的安全问题,包括数据生成、对齐技术、模型编辑和基于LLM的智能体系统及应用。我们的发现揭示了各阶段的关键漏洞,如隐私风险、有毒数据、有害微调攻击和部署挑战。
LLMs的安全性是一个多方面的问题,需要对数据完整性、模型对齐和部署后安全措施给予细致关注。此外,我们提出了未来研究的有前景方向,包括数据安全、对齐技术以及针对基于LLM智能体的防御机制的改进。这项工作对于指导未来使LLMs更安全、更可靠的努力至关重要,尤其是随着LLMs日益成为各行各业不可或缺的组成部分。确保整个LLM生命周期的稳健安全对于其在现实场景中的负责任和有效部署至关重要。
参考文献
[1] L. Ouyang等,“Training language models to follow instructions with human feedback,” Advances in neural information processing systems, vol. 35, pp. 27730–27744, 2022.
[2] H. Touvron等,“Llama: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
[3] J. Bai等,“Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023.
[4] A. Liu等,“Deepseek-v3 technical report,” arXiv preprint arXiv:2412.19437, 2024.
[5] D. Guo等,“Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforcement learning,” arXiv preprint arXiv:2501.12948, 2025.
[6] W. X. Zhao等,“A survey of large language models,” arXiv preprint arXiv:2303.18223, vol. 1, no. 2, 2023.
[7] Y. Chang等,“A survey on evaluation of large language models,” ACM transactions on intelligent systems and technology, vol. 15, no. 3, pp. 1–45, 2024.
(完整参考文献列表请参见原文,共涵盖数百条文献。)
通讯作者:
- Kun Wang,南洋理工大学,wang.kun@ntu.edu.sg
- Guibin Zhang,新加坡国立大学,guibinz@outlook.com
- Jiahao Wu,香港理工大学,jiahao.wu@connect.polyu.hk
- Zhenhong Zhou,A*STAR,ydyjyazzh@gmail.com
- Yang Liu,南洋理工大学,yangliu@ntu.edu.sg
* 表示同等贡献,† 表示通讯作者
本文完整文献综述持续更新于:https://github.com/bingreeky/full-stack-llm-safety

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献85条内容
已为社区贡献85条内容

所有评论(0)