简评2026年初开源权重大模型架构
美国初创公司Arcee AI发布4000亿参数开源大模型Trinity Large及其小型变体,采用混合专家架构和滑动窗口注意力技术。中国公司月之暗面同期推出万亿参数开源模型Kimi K2.5,在性能上超越专有模型,并支持多模态处理。StepFun的Step 3.5 Flash以1960亿参数实现高推理速度,采用多token预测技术。阿里Qwen3团队发布的800亿参数编程专用模型Qwen3-Co
Arcee AI 的 Trinity Large:一家分享开源权重模型的美国新创公司
1月27日,Arcee AI(此前我并未关注到这家公司)开始在模型中心发布其开源权重的4000亿参数Trinity Large大语言模型的多个版本,以及两个较小的变体:
其旗舰大模型是一个4000亿参数的混合专家(MoE)模型,拥有130亿激活参数。
两个较小的变体是 Trinity Mini(260亿参数,30亿激活参数)和 Trinity Nano(60亿参数,10亿激活参数)。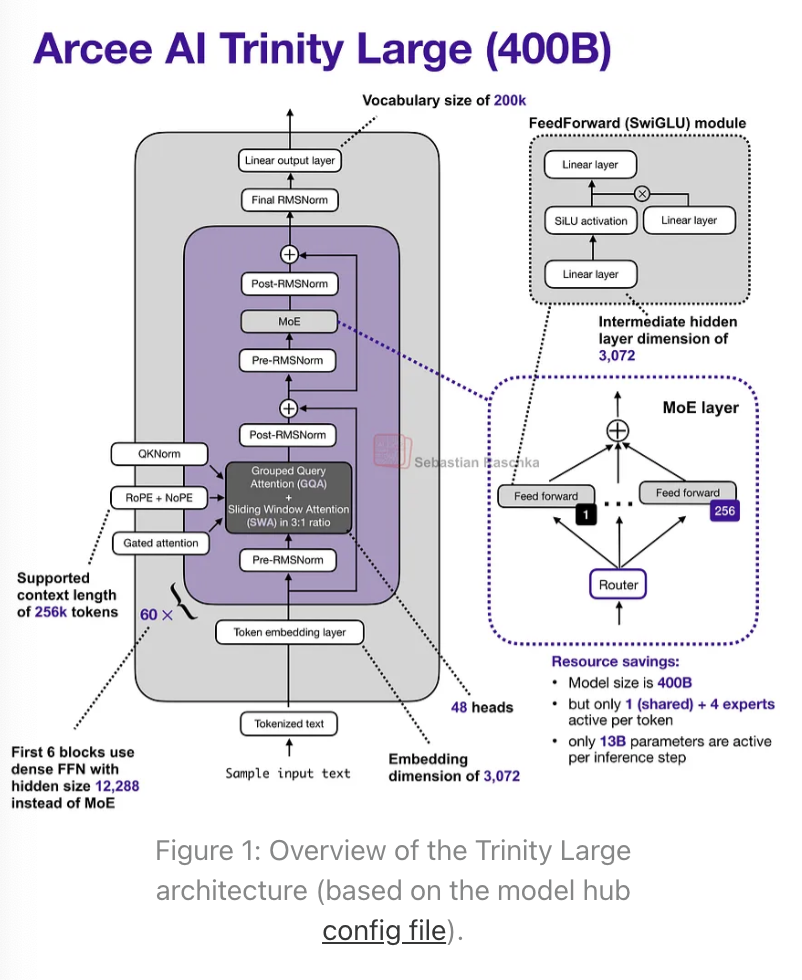
除了模型权重,Arcee AI还在GitHub上发布了一份内容详实的技术报告(截至2月18日,也已上传至arXiv),其中包含大量细节。
现在,让我们仔细看看这个4000亿参数的旗舰模型。下面的图2将其与z.AI的GLM-4.5进行了对比,后者因拥有3550亿参数的规模而成为最相似的模型。
从Trinity和GLM-4.5的对比中可以看出,Trinity模型增加了一些有趣的架构组件。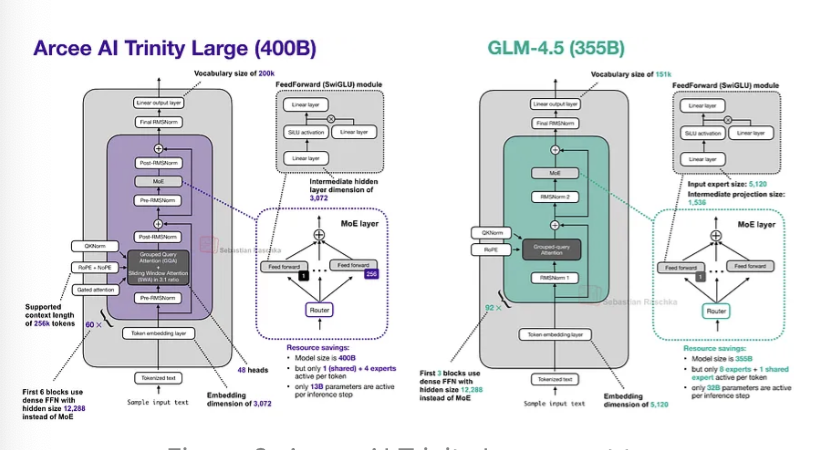
首先,它采用了交替的局部:全局(滑动窗口)注意力层(SWA),类似Gemma 3、Olmo 3、小米MiMo等模型。简而言之,SWA是一种稀疏(局部)注意力模式,其中每个token只关注一个固定大小的、包含最近t个token的窗口(例如4096个),而不是关注整个输入(可能长达n=256,000个token)。对于序列长度n,这将每层常规注意力的成本从O(n²)降低到大约O(n·t),这也是它对长上下文模型具有吸引力的原因。
但是,Arcee团队没有采用Gemma 3和小米使用的常见5:1局部:全局比例,而是选择了类似于Olmo 3的3:1比例,以及相对较大的4096滑动窗口大小(这也与Olmo 3相似)。
该架构还使用了QK-Norm,这是一种对键和查询应用RMSNorm以稳定训练的技术,并且在全局注意力层中没有使用位置嵌入(NoPE),类似于SmolLM3。
Trinity还拥有一种门控注意力形式。它不是一个完全的Gated DeltaNet,但在注意力机制中使用了与Qwen3-Next类似的门控。
也就是说,Trinity团队修改了标准注意力机制,在输出线性投影之前,向缩放点积添加了逐元素门控(如下图所示),这减少了注意力汇聚点(attention sinks)并改善了长序列的泛化能力。此外,这也有助于训练稳定性。
同时,Trinity的技术报告显示,Trinity Large和GLM-4.5基础模型的建模性能几乎相同(我猜测他们没有与更新的基础模型进行比较,因为如今许多公司只分享他们微调后的模型)。
你可能已经注意到,之前的Trinity Large架构图中使用了四个(而不是两个)RMSNorm层,这乍一看类似于Gemma 3。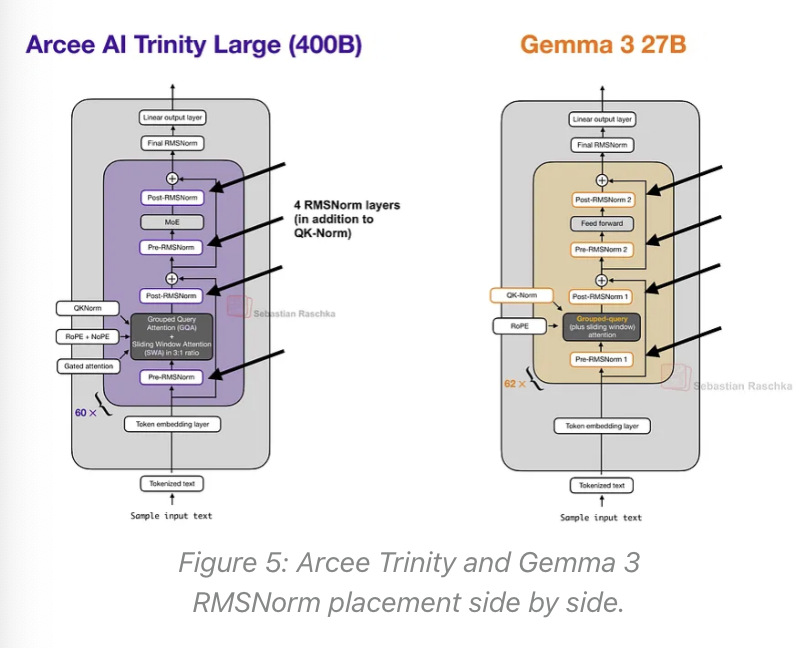
总体而言,RMSNorm的放置位置看起来像Gemma 3的风格,但不同之处在于,第二个RMSNorm(在每个块中)的增益是深度缩放的,这意味着它被初始化为大约1 / sqrt(L)(其中L是总层数)。因此,在训练初期,残差更新幅度很小,并随着模型学习到合适的规模而增长。
MoE部分采用了类似DeepSeek的风格,拥有大量小型专家,但使其更粗粒度,这有助于提高推理吞吐量(我们在Mistral 3 Large采用DeepSeek V3架构时也看到了这一点)。
最后,在训练改进方面还有一些有趣的细节(一种新的MoE负载均衡策略和另一种使用MuOpt优化器的策略),但由于本文主要聚焦于架构(并且还有很多开源权重的大模型要介绍),这些细节将不再展开。
月之暗面的 Kimi K2.5:一个万亿参数级别的类DeepSeek模型
当Arcee Trinity的性能大致与较老的GLM-4.5模型持平时,Kimi K2.5作为一款开源权重模型,在1月27日发布之时便树立了新的开源权重性能标杆。
令人印象深刻的是,根据其详细技术报告中的基准测试,它在发布时与领先的专有模型不相上下。
与之前介绍的Arcee Trinity或GLM-4.5相比,如此出色的建模性能并不令人意外,因为(与其前身K2类似)Kimi K2.5是一个万亿参数级别的模型,规模是Trinity的2.5倍,GLM-4.5的2.8倍。
总体而言,Kimi K2.5的架构与Kimi K2相似,而K2本身又是DeepSeek V3架构的放大版本。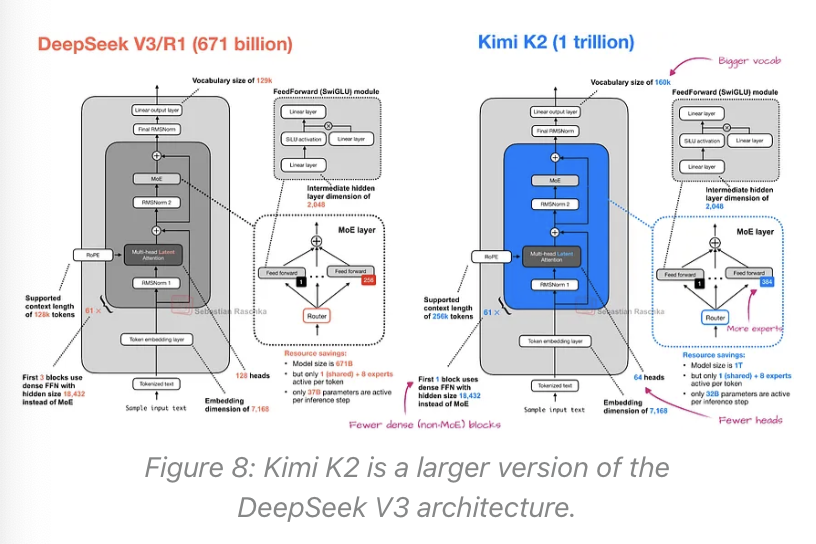
然而,K2是一个纯文本模型,而Kimi K2.5现在是一个支持视觉的多模态模型。引用其技术报告中的描述:
Kimi K2.5是一个原生多模态模型,它基于Kimi K2,通过对大约15万亿混合视觉和文本token进行大规模联合预训练而构建。
在训练过程中,他们采用了早期融合(early fusion)方法,在早期就将视觉token与文本token一起输入,正如我在之前的《理解多模态大语言模型》文章中所讨论的那样。
附注:在多模态论文中,“早期融合”一词不幸地存在多重含义。它可以指:
模型在预训练阶段何时接触到视觉token。即,视觉token是从预训练开始(或很早阶段)就混入,还是在较晚阶段才引入。
图像token在模型中如何组合。即,它们是否作为嵌入token与文本token一起馈入模型。
在这种情况下,虽然报告中使用的“早期融合”一词特指第1点(即视觉token在预训练期间提供的时间点),但第2点在这里也同样适用。
此外,关于第1点,研究人员进行了一项有趣的消融研究,结果表明模型从预训练早期接触视觉token中获益,如下面的注释表所示。
StepFun的Step 3.5 Flash:高吞吐量下的优异性能
我不得不承认,此前我并未关注过Step系列模型。这次它引起了我的注意,是因为其有趣的规模、详细的技术报告以及快速的token/秒性能。
Step 3.5 Flash是一个1960亿参数的模型,规模比最近的DeepSeek V3.2模型(6710亿参数)小了三倍多,但在建模性能基准测试上却略微领先。根据Step团队在其模型中心页面提供的数据,Step 3.5 Flash在128k上下文长度下能达到100 token/秒的吞吐量,而DeepSeek V3.2在Hopper GPU上仅为33 token/秒。
实现更高性能的一个原因是模型规模更小(1960亿参数的MoE,每个token激活110亿参数,相比之下,DeepSeek V3.2是6710亿参数的MoE,每个token激活370亿参数),如下图所示。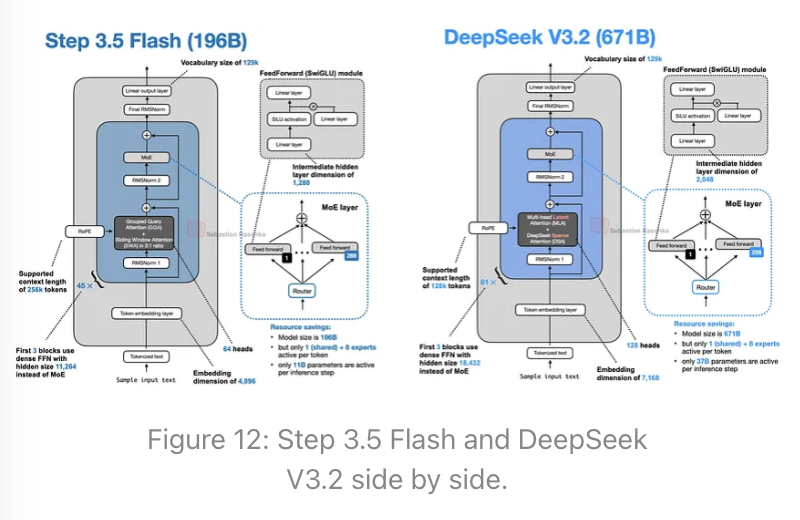
另一个原因,除了我们之前在Trinity中讨论过的门控注意力之外,是多token预测(MTP)。DeepSeek是较早采用多token预测技术的公司,该技术训练LLM在每个步骤预测多个未来token,而不仅仅是一个。具体来说,在每个位置t,额外的小型预测头(线性层)为t+1…t+k输出logits,然后我们对这些偏移位置的交叉熵损失进行求和(在MTP论文中,研究者推荐k=4)。
如下方示意图所示,这种额外的信号加速了训练,而推理时仍可以一次生成一个token。
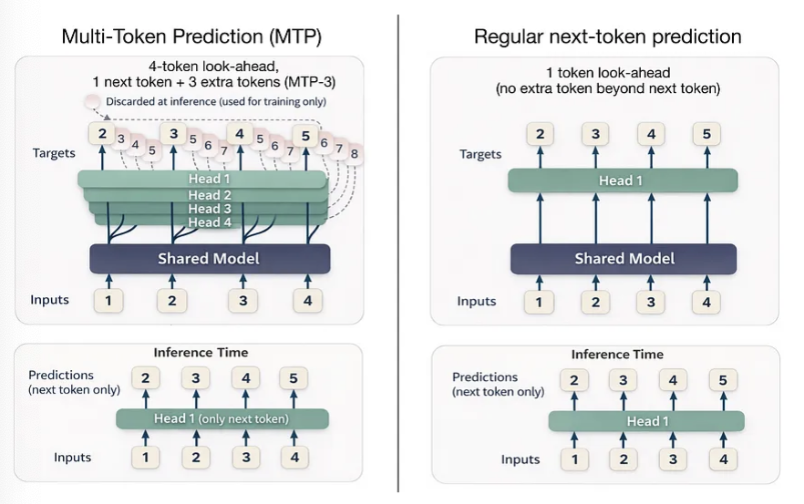
据报道,DeepSeek V3在训练时使用了MTP-1(即,增加预测1个额外token,而不是3个),并在推理时使MTP成为可选。
Step 3.5 Flash则在训练和推理时都使用了带有3个额外token的MTP(MTP-3)(请注意,MTP通常在推理时不使用,这是一个例外)。
需要说明的是,前面讨论的Arcee Trinity和Kimi K2.5没有使用MTP,但其他一些架构,例如GLM-4.7和MiniMax M2.1,已经采用了类似于Step 3.5 Flash的MTP-3设置。
Qwen3-Coder-Next:专为编程设计的混合注意力架构
2026年2月初,Qwen3团队发布了800亿参数的Qwen3-Coder-Next模型(30亿激活参数),该模型在编程任务上超越了许多规模更大的模型,如DeepSeek V3.2(370亿激活参数)、Kimi K2.5和GLM-4.7(均为320亿激活参数),成为头条新闻。
此外,如上图基准测试所示,Qwen3-Coder-Next在SWE-Bench Pro上的性能与Claude Sonnet 4.5大致相当(仅略低于Claude Opus 4.5),对于一个相对较小的开源权重模型来说,这令人印象深刻!
在本地使用ollama版本的Qwen3-Coder-Next,模型大约占用48.2 GB的存储空间和51 GB的内存。
需要注意的是,Qwen3-Coder-Next背后的架构与Qwen3-Next 80B完全相同(实际上,预训练的Qwen3-Next 80B被用作进一步中期和后期训练的基础模型)。下面的图16将Qwen3-Next架构与常规的Qwen3 235B模型进行了对比,以供参考。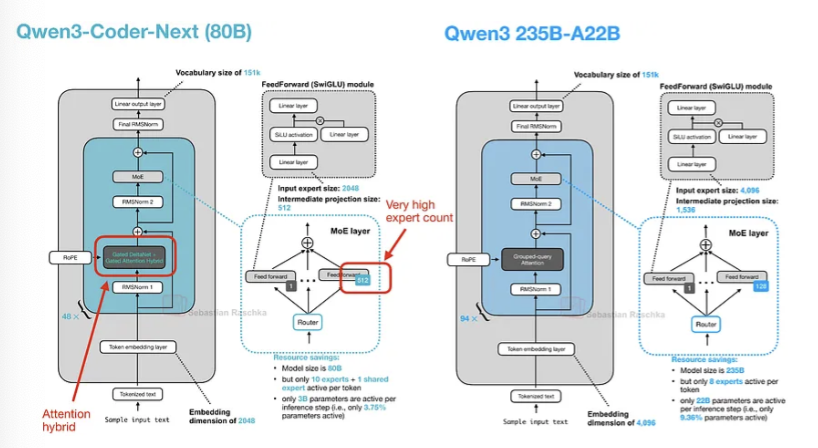
新的Qwen3 Next架构之所以脱颖而出,是因为尽管它比之前的2350亿参数(激活220亿)模型小了三倍,但引入了四倍数量的专家,甚至增加了一个共享专家。这两个设计选择(高专家数量和包含共享专家)是关键。
另一个亮点是,他们用门控DeltaNet + 门控注意力的混合机制取代了常规的注意力机制,这有助于在内存使用方面实现原生262k token的上下文长度(而235B-A22B模型原生支持32k,通过YaRN扩展支持131k)。
那么,这种新的混合注意力是如何工作的呢?与分组查询注意力(GQA)相比,GQA仍然是标准的缩放点积注意力(如之前讨论的,在查询头组之间共享K/V以减少KV缓存大小和内存带宽,但其解码成本和缓存仍随序列长度增长)。而Qwen3的混合机制以3:1的比例混合了门控DeltaNet块和门控注意力块,如图所示。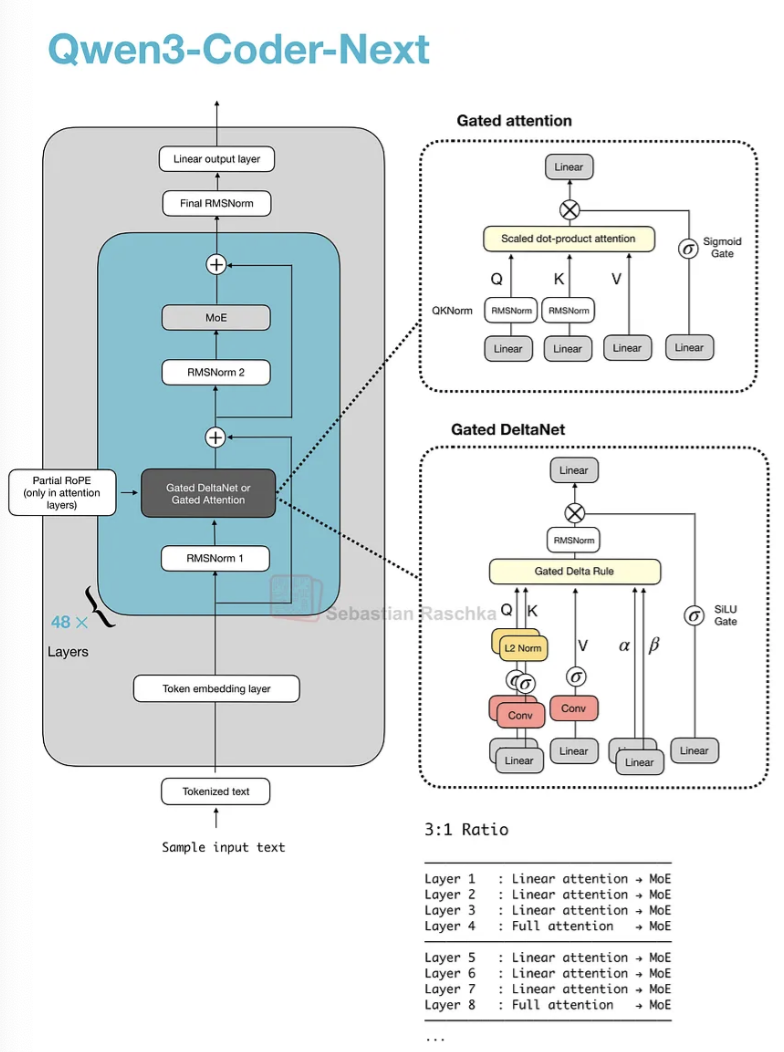
我们可以将门控注意力块视为GQA中使用的标准缩放点积注意力,并进行了一些调整。门控注意力与普通GQA块的主要区别在于:
- 一个输出门(通常按通道,由sigmoid控制),在注意力结果加回残差流之前对其进行缩放;
- 用于QK-Norm的零中心RMSNorm,而不是标准RMSNorm;
- 部分RoPE(仅应用于维度子集)。
请注意,这些本质上只是对GQA的稳定性改进。
门控DeltaNet则是一个更显著的变化。在DeltaNet块中,q、k、v以及两个门(α, β)由线性层和轻量级卷积层(带归一化)生成,该层用一个快速权重的delta规则更新取代了注意力机制。
然而,这样做的代价是,与完全注意力相比,DeltaNet提供的内容检索精度较低,这就是为什么仍然保留了一个门控注意力层。
鉴于注意力机制的计算量呈二次方增长,添加DeltaNet组件是为了提高内存效率。在“线性时间、无缓存”家族中,DeltaNet块本质上是Mamba的一个替代方案。Mamba通过一个学习到的状态空间滤波器(本质上是随时间变化的动态卷积)来维持一个状态。DeltaNet则维护一个由α和β更新的小型快速权重存储器,并用q读取它,仅使用小型卷积来帮助形成q, k, v, α, β。
关于混合注意力和Qwen3-Next架构的更多细节,请参阅我之前的文章《超越标准LLM》。
由于本文主要聚焦于LLM架构,训练细节不在讨论范围内。然而,感兴趣的读者可以在他们GitHub上的详细技术报告中找到更多信息。
z.AI 的 GLM-5:新一代旗舰开源权重模型
2月12日发布的GLM-5意义重大,因为在发布之时,它的性能似乎与主要的旗舰级LLM产品不相上下,包括GPT-5.2 extra-high、Gemini Pro 3和Claude 4.6 Opus。(尽管如此,基准测试的性能并不一定能转化为现实世界的表现。)
不久之前,GLM-4.7(2025年12月)还是最强大的开源权重模型之一。GLM-5显示出显著的建模性能提升。这种跃升可能部分归因于训练流程的改进,但很可能主要归功于其参数数量翻倍——从GLM-4.7的3550亿参数增加到GLM-5的7440亿参数。这一规模的增长使得GLM-5在体量上介于DeepSeek V3.2(6710亿)和Kimi K2.5(1万亿)之间。
将之前讨论过的Kimi K2.5(1万亿)与规模较小的GLM-5(7440亿)的基准测试数字进行比较,如下表所示,GLM-5似乎略微领先。
与GLM-4.7以及迄今为止讨论的所有其他模型一样,GLM-5也是一个混合专家(MoE)模型。每个token的激活参数数量略有增加,从GLM-4.7的320亿增加到GLM-5的400亿。
GLM-5现在采用了DeepSeek的多头潜在注意力以及DeepSeek稀疏注意力。(我在《从DeepSeek V3到V3.2:架构、稀疏注意力与RL更新》一文中更详细地描述了DeepSeek稀疏注意力。)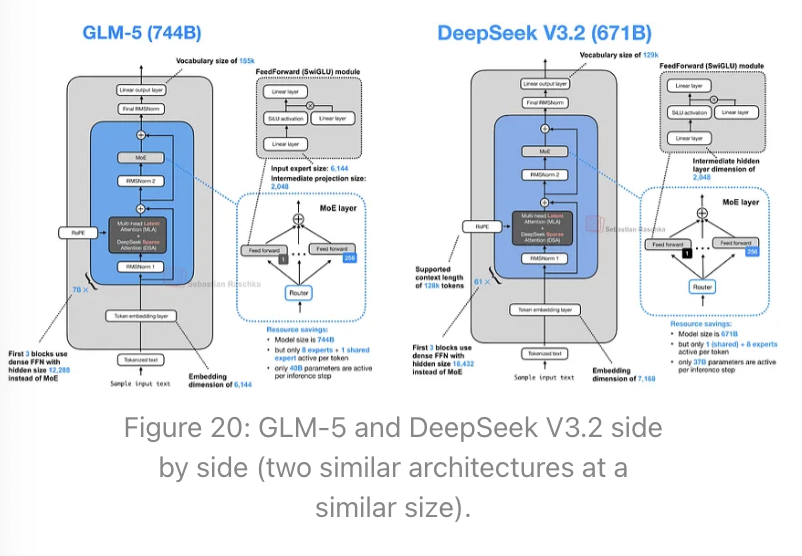
这些修改很可能旨在降低处理长上下文时的推理成本。除此之外,整体架构保持相对相似。
与GLM-4.7相比,总规模的增加主要来自于专家数量的扩充,从160个(GLM-4.7)增加到256个(GLM-5),以及层维度的小幅提升(同时保持每个token的专家数量为8个常规专家 + 1个共享专家不变)。例如,嵌入维度和专家规模从5,120增加到6,144,中间投影尺寸从1,536增加到2,048。
有趣的是,Transformer层数从GLM-4.7的92层减少到了GLM-5的78层。我猜想这一变化也是为了降低推理成本并改善延迟,因为层深度无法像宽度那样进行并行化处理。
此外,我还查看了一个独立基准测试(此处指幻觉排行榜),结果显示GLM-5确实与Opus 4.5和GPT-5.2不相上下(同时使用的token更少)。
更进一步,查看聚合了各种基准测试的最新人工智能指数,GLM-5确实略微领先于Kimi K2.5,仅比GPT-5.2 (xhigh)和最新的Claude Sonnet 4.6落后一分。
MiniMax M2.5:仅凭2300亿参数就成为强大的编程模型
前面提到的GLM-5和Kimi K2.5是热门的开源权重模型,但根据OpenRouter的统计数据,它们与同样在2月12日发布的MiniMax M2.5相比,则相形见绌。
OpenRouter是一个平台和API,允许开发者访问来自不同提供商的众多LLM并路由请求。需要注意的是,虽然其使用统计数据能较好地反映开源权重模型的受欢迎程度,但它严重偏向于开源权重模型(相对于专有模型),因为大多数用户直接通过官方平台使用专有模型。开源权重模型之间也存在使用偏差,因为许多人也会通过官方开发者的API使用开源权重模型。无论如何,它仍然是一个有趣的参考点,可以借此估算那些对大多数用户来说太大而无法在本地运行的开源权重模型的相对流行度。
现在,回到MiniMax M2.5。将SWE-Bench Verified编程基准测试中的GLM-5数据与报告的MiniMax M2.5数据放在一起比较,后者似乎是一个稍强的模型(至少在编程方面)。
附注:有趣的是,Opus 4.5和Opus 4.6在SWE-Bench Verified上的得分几乎相同。这可能表明LLM的进步已经停滞。不过,我并不认为这是真的,因为Opus 4.6的用户可以证实,该模型在实际使用中确实表现更好。因此,更可能的问题是SWE-Bench Verified基准测试已经饱和,它可能不再是一个有意义的基准测试(转而支持例如SWE-Bench Pro等其他基准测试)。所谓饱和,是指由于设计问题,它可能包含了无法解决的问题(正如最近Reddit上一个讨论串和OpenAI新发布的文章《为什么SWE-bench Verified不再衡量前沿编程能力》中讨论的那样)。
无论如何,回到MiniMax M2.5的性能话题。从更广泛的基准测试来看,根据人工智能指数的聚合,GLM-5仍然领先。这或许并不奇怪,因为即使token/秒的吞吐量非常相似,GLM-5仍然是一个比M2.5大四倍的模型。
我认为MiniMax M2.5的受欢迎程度部分归因于它是一个更小、更便宜的模型,同时具有大致相似的建模性能(即,性价比很高)。
从架构上看,MiniMax M2.5是一个拥有2300亿参数的模型,采用了相当经典的设计:仅使用普通的分组查询注意力,没有滑动窗口注意力或其他效率改进。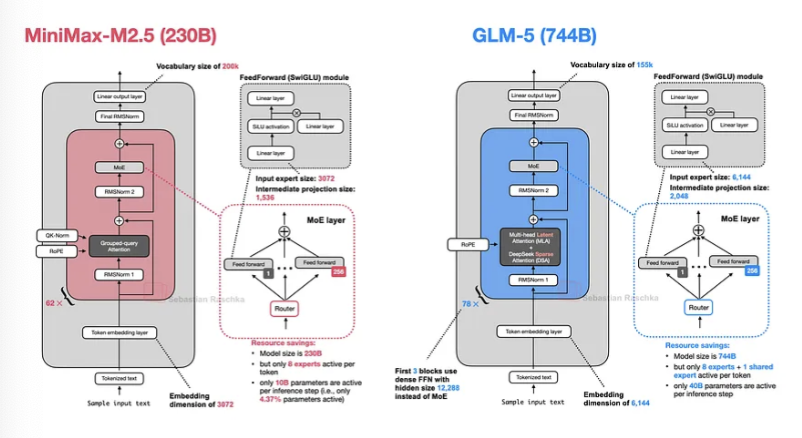
到目前为止,这也是本报告中第一个没有附带详细技术报告的架构,但你可以在模型中心页面上找到更多信息。
Nanbeige 4.1 3B:一个强大的Llama 3继任者
在本节中,我们将转换话题,最终介绍一个可以在笔记本电脑上本地运行的较小模型。但在深入探讨Nanbeige 4.1 3B之前,我们先来了解一些背景信息。
Qwen系列模型一直非常受欢迎。我经常讲一个故事:几年前,我在担任NeurIPS LLM效率挑战赛的顾问时,大多数获奖方案都基于Qwen模型。
如今,Qwen3很可能是使用最广泛的开源权重模型套件之一,因为它们涵盖了从0.6B到235B如此广泛的规模和应用场景。
尤其是较小的模型(800亿参数及以下,比如之前提到的Qwen3-Next),非常适合在消费级硬件上本地使用。
我之所以提到这些,是因为Nanbeige 4.1 3B似乎瞄准了Qwen3广受欢迎的“小型”LLM设备端应用场景。根据Nanbeige 4.1 3B的基准测试,他们的模型远远领先于Qwen3(考虑到Qwen3已发布近一年,这或许并不令人意外)。
从架构上看,Nanbeige 4.1 3B与Qwen3 4B相似,而Qwen3 4B又与Llama 3.2 3B非常相似。下面我将Nanbeige 4.1 3B与Llama 3.2 3B并列展示,因为它们在规模上最为接近。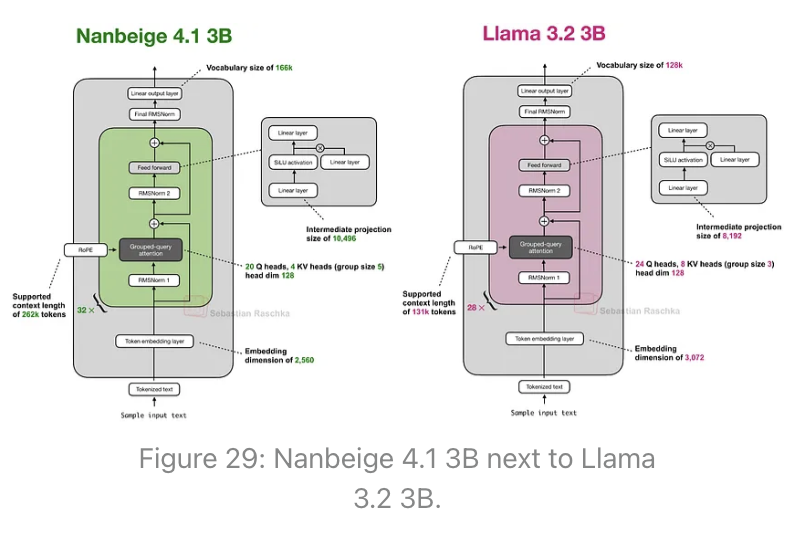
Nanbeige 4.1 3B使用了与Llama 3.2 3B相同的架构组件,只有一些细微的规模差异(例如,稍小的嵌入维度和稍大的中间投影等)。上图中未显示的一个区别是,Nanbeige没有将输入嵌入权重与输出层权重绑定,而Llama 3.2 3B进行了绑定。(根据我的经验,权重绑定是减少总参数数量的一个好方法,但它几乎总是会导致较差的训练性能,这体现在更高的训练和验证损失上。)
如前所述,本文主要关注架构比较。在这种情况下,相较于其前身Nanbeige 4 3B,大部分性能提升来自于额外的监督微调和强化学习后训练,感兴趣的读者可以在详细的技术报告中找到更多信息。
Qwen3.5与混合注意力机制的延续
虽然上一节简要介绍了作为最普遍开源权重模型家族的Qwen3,但考虑到它的发布已近一年(如果不算那些注重效率的Qwen3-Next变体的话),它确实显得有些年头了。不过,Qwen团队刚刚在2月15日发布了新的Qwen3.5模型变体。
Qwen3.5 397B-A17B,一个拥有3970亿参数的混合专家(MoE)模型(每个token激活170亿参数),相较于规模最大的2350亿参数的Qwen3模型(此外还有万亿参数的Qwen3-Max模型,但从未作为开源权重模型发布)是一个巨大的提升。
必要的基准测试概览显示,Qwen3.5全面超越了之前的Qwen3-Max模型,并且更侧重于智能体终端编码应用(这是今年的主要趋势)。在纯粹的智能体编码性能方面(例如,SWE-Bench Verified),Qwen3.5似乎与GLM-5和MiniMax M2.5大致相当。
由于Qwen团队喜欢发布单独的编程模型(例如,我们之前讨论过的Qwen3-Coder-Next),这让我很好奇未来可能的Qwen3.5-Coder将会表现如何。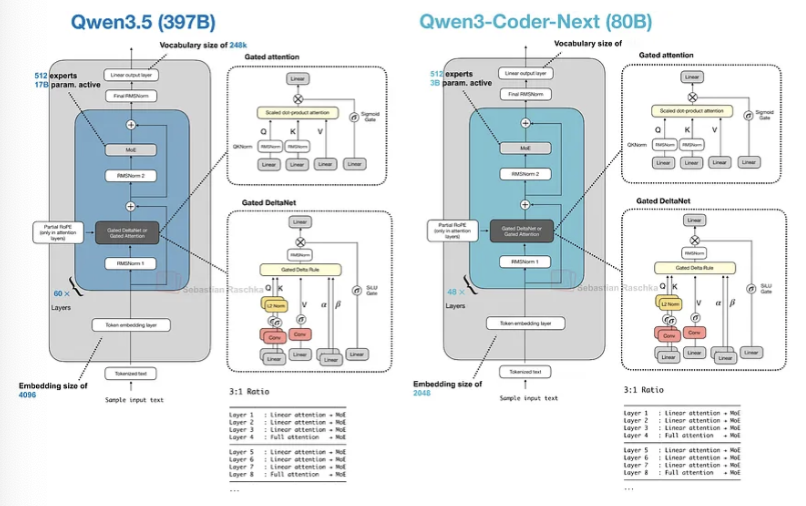
从架构上看,Qwen3.5采用了Qwen3-Next和Qwen3-Coder-Next(第4节)所使用的混合注意力模型(以门控DeltaNet为特色)。这很有趣,因为Qwen3-Next模型最初是作为完整注意力机制Qwen3模型的替代方案,但这表明Qwen团队现在已经将混合注意力机制采纳到其主要模型系列中。
除了扩大模型规模,Qwen3.5现在还包含多模态支持(此前,这仅在单独的Qwen3-VL模型中提供)。
无论如何,Qwen3.5是对Qwen系列的一次很好的更新,我希望未来也能看到更小的Qwen3.5变体!
蚂蚁集团的 Ling 2.5 1T 与闪电注意力机制
Ling 2.5(以及其推理变体 Ring 2.5)是拥有万亿参数的大语言模型,采用了与 Qwen3.5 和 Qwen3-Next 理念相似的混合注意力架构。
不过,它们没有使用门控 DeltaNet,而是采用了一种稍微简单的递归线性注意力变体,称为闪电注意力。此外,Ling 2.5 还采用了 DeepSeek 的多头潜在注意力(MLA)机制。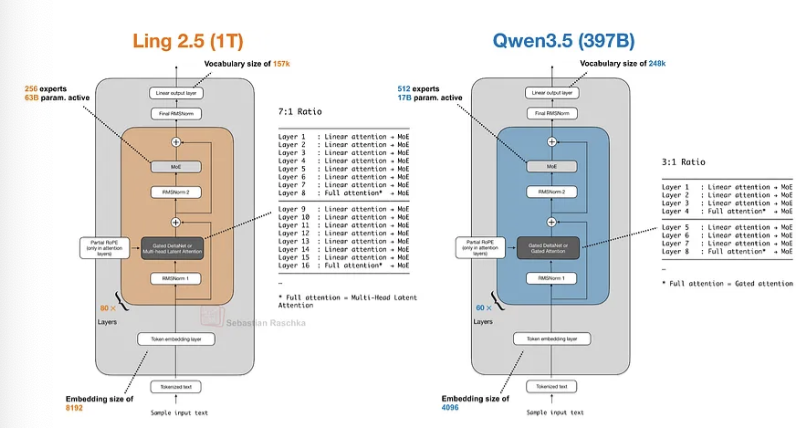
就绝对基准性能而言,Ling 2.5 并非最强的模型,但其卖点在于(得益于混合注意力)在长上下文场景中拥有非常出色的效率。遗憾的是,目前没有与 Qwen3.5 的直接对比,但与 Kimi K2(同样为万亿参数)相比,Ling 2.5 在 32k token 的序列长度下实现了 3.5 倍的吞吐量提升。
Tiny Aya:拥有强大多语言支持的 3.35B 模型
Cohere 于 2 月 17 日发布了 Tiny Aya,这是一个新的“小型”LLM,据称是 30 亿参数级别中“能力最强的多语言开源权重模型”。(根据发布公告,Tiny Aya 的表现优于 Qwen3-4B、Gemma 3 4B 和 Ministral 3 3B)。
这是一个非常适合在本地运行和实验的模型。唯一的注意事项是,尽管它是一个开源权重模型,但其许可条款相对严格,仅允许非商业用途。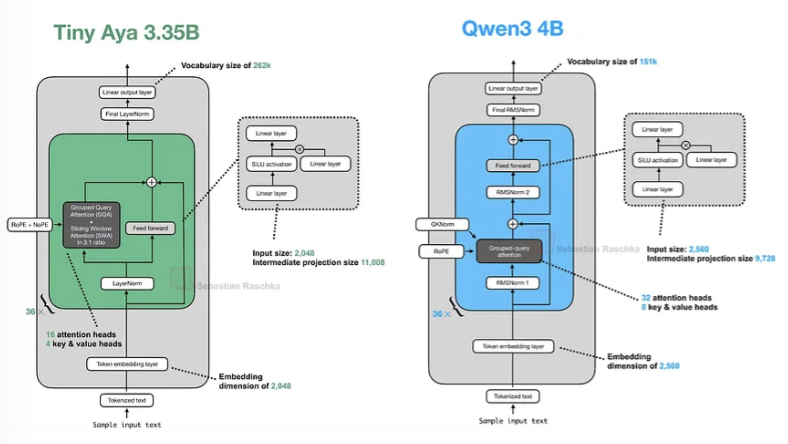
撇开这一点不谈,Aya 是一个拥有 33.5 亿参数的模型,提供了多个适用于个人和(非商业)研究用途的版本:
- tiny-aya-base(基础模型)
- tiny-aya-global(在语言和地区间取得最佳平衡)
- tiny-aya-fire(针对南亚语言优化)
- tiny-aya-water(针对欧洲和亚太地区语言优化)
- tiny-aya-earth(针对西亚和非洲语言优化)
更具体地说,下方列出了这些模型所针对优化的语言。
从架构上看,Tiny Aya 是一个经典的解码器风格 transformer,并带有一些值得注意的修改(除了像 SwiGLU 和分组查询注意力这样显而易见的组件),如下图所示。
总体而言,该架构中最值得关注的亮点是并行的 transformer 块。在这里,并行的 transformer 块从相同的归一化输入计算注意力和 MLP,然后在一个步骤中将两者都添加到残差连接中。我推测这样做是为了减少层内的串行依赖,从而提高计算吞吐量。
对于熟悉 Cohere 的 Command-A 架构的读者来说,Tiny Aya 似乎是它的一个缩小版本。另一个有趣的细节是,Tiny Aya 团队去掉了 QK-Norm(一种应用于注意力机制内部键和查询的 RMSNorm);QK-Norm 在减少损失尖峰、提高训练稳定性方面已经变得相当标准。据 Cohere 团队的一位开发者称,放弃 QK-Norm 是“因为它可能会影响长上下文性能”。
如你所知,我偶尔会从头开始实现一些架构。由于我发现这个并行的 transformer 块非常有趣,而且该模型在低端硬件上运行良好,我便(出于教育目的)从头实现了它,你可以在 GitHub 上找到相关代码。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)