官宣|FlagOS 登陆腾讯云,快速在国产AI芯片部署OpenClaw+大模型,实现“养虾”自由
还在为云端大模型的隐私风险和高昂 Token 成本发愁?众智 FlagOS 联合腾讯云 HAI,正式将 Qwen3-4B-hygon-flagos 模型镜像上线!本文手把手教你在国产 AI 芯片上快速部署 FlagOS + OpenClaw,以小模型驱动智能体执行任务,并无缝接入 QQ 机器人 。带你零门槛体验本地 7×24 小时待命的“数字员工”,轻松实现“养虾”自由!
目录
过去,大家习惯通过公有云 API 获取 AI 能力;但随着 OpenClaw 爆火,个人和企业都需要本地 7×24 小时待命的 “数字员工”。奈何云端方案的隐私风险和高额 Token 成本,让工业级智能体很难大规模落地,自建本地大模型服务已成刚需。
近日,众智 FlagOS 联合腾讯云 HAI,将 Qwen3‑4B‑hygon‑flagos 模型镜像正式上线至 HAI 社区,开发者可直接拉取使用。基于该镜像,用户能够在加速卡上快速运行 FlagOS + OpenClaw,以小模型驱动智能体执行任务,轻松完成从公有云到本地 AI 服务的无缝切换,同时深度参与到国产 AI 芯片标准化生态的建设中。
众智 FlagOS 是由智源研究院打造的开源 AI 系统软件栈,致力于构建统一、开放、安全的全栈平台,面向多元计算架构构建统一开源技术栈,实现一次开发、多芯复用、全域部署,推动国产 AI 芯片生态实现标准化适配与规模化落地。该平台支持多款异构 AI 芯片,可帮助用户快速部署模型与智能体。
安装及测试过程
基于 FlagOS 系统软件栈的跨芯能力,众智 FlagOS 社区把 Qwen3-4B 适配至多款GPU硬件。以下内容重点介绍如何部署与配置 FlagOS 版 Qwen3-4B的过程,仅用于复现实验结果,不影响对 Agent 能力的判断。
1.安装Qwen3-4B-hygon-flagos
a.首先,从HAI 社区平台找到 Qwen3-4B-hygon-FlagOS,根据README.md拉取模型并启动服务。
以 ModelScope为例,下载模型权重
pip install modelscope
modelscope download --model Qwen/Qwen3-4B --local_dir /share/Qwen3-4Bb.点击【部署当前镜像】获取镜像拉取命令,从 HAI 社区拉取镜像
docker pull haihub.cn/baai/flagrelease_hygon_qwen3:v1.0.0
c.通过下面的代码,启动容器。
这段代码可直接复制使用,也可以根据需要修改容器名,即在第4行--name=flagos对 name 进行修改。
#Container Startup
docker run -it \
--name=flagos \
--network=host \
--privileged \
--ipc=host \
--shm-size=16G \
--memory="512g" \
--ulimit stack=-1:-1 \
--ulimit memlock=-1:-1 \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device=/dev/kfd \
--device=/dev/dri \
--group-add video \
-u root \
-v /opt/hyhal:/opt/hyhal \
-v /share:/share \
haihub.cn/baai/flagrelease_hygon_qwen3:v1.0.0 \
/bin/bash
d.进入容器(如果上一步修改了容器名,这里要将flagos对 name 进行修改。
docker exec -it flagos bashe. 启动服务
flagscale serve qwen3
2.安装配置OpenClaw
安装过程: https://github.com/openclaw/openclaw?spm=5176.28103460.0.0.696675514ZMILC见详情, 通过源码方式,安装 OpenClaw。
git clone https://github.com/openclaw/openclaw.git
cd openclaw
pnpm install
pnpm ui:build # auto-installs UI deps on first run
pnpm build
pnpm openclaw onboard --install-daemon
# Dev loop (auto-reload on TS changes)
pnpm gateway:watch配置过程:
a. 访问链接以下链接:https://cloud.tencent.com/developer/article/2625144,文中有给出通用的"模型配置"文件格式,可以直接套用,套用后命令如下。需要注意的是,配置本地模型时,厂商一定是加速推理工具如vllm。
pnpm openclaw config set 'models.providers.vllm_local' --json '{
"baseUrl": "http://1.15.51.106:9033/v1",
"apiKey": "anykey", #key不可为空,如果原来模型没有配置key,任意填写即可
"api": "openai-completions",
"models": [
{ "id": "Qwen3-4B-hygon-flagos", "name": "远程模型" }
]
}'执行之后出现如下信息提示:
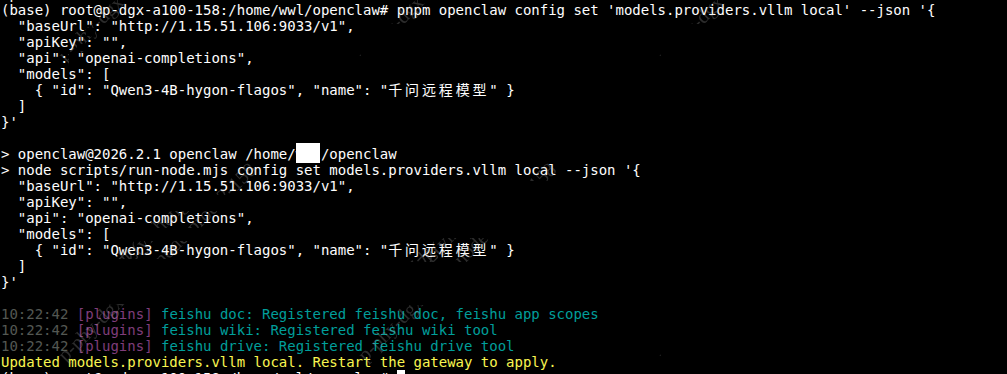
启用并设置为默认模型
pnpm openclaw config set models.mode mergepnpm openclaw models set vllm_local/Qwen3-4B-hygon-flagos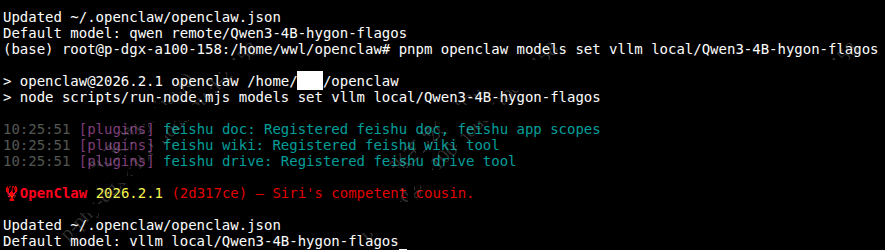
可以看到当前默认模型已经切换为 Qwen3-4B-hygon-flagos。
执行下面代码,可以看到模型已经切换完成。
pnpm openclaw configure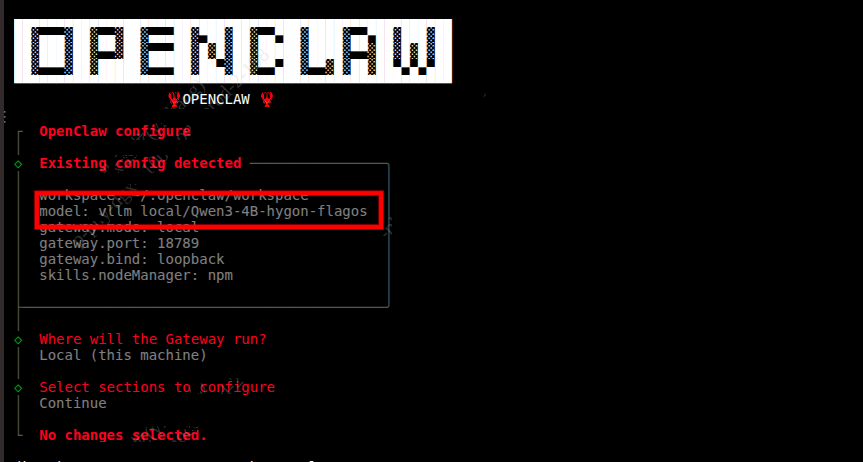
可以看到模型已经切换完成。
3. 配置 channel 为QQ
参考文档: https://cloud.tencent.com/developer/article/2626045,这部分需要替换为自己的ID和secret。配置完成后,进行以下操作:
a.启动openclaw网关, 命令如下:
pnpm openclaw gateway b.启动成功后,您可以在QQ软件中尝试和已经打通OpenClaw的QQ机器人进行单独聊天,或者在群里与QQ机器人进行对话。如果QQ机器人能够以AI的方式对话,则说明您已经成功完成OpenClaw应用接入QQ机器人。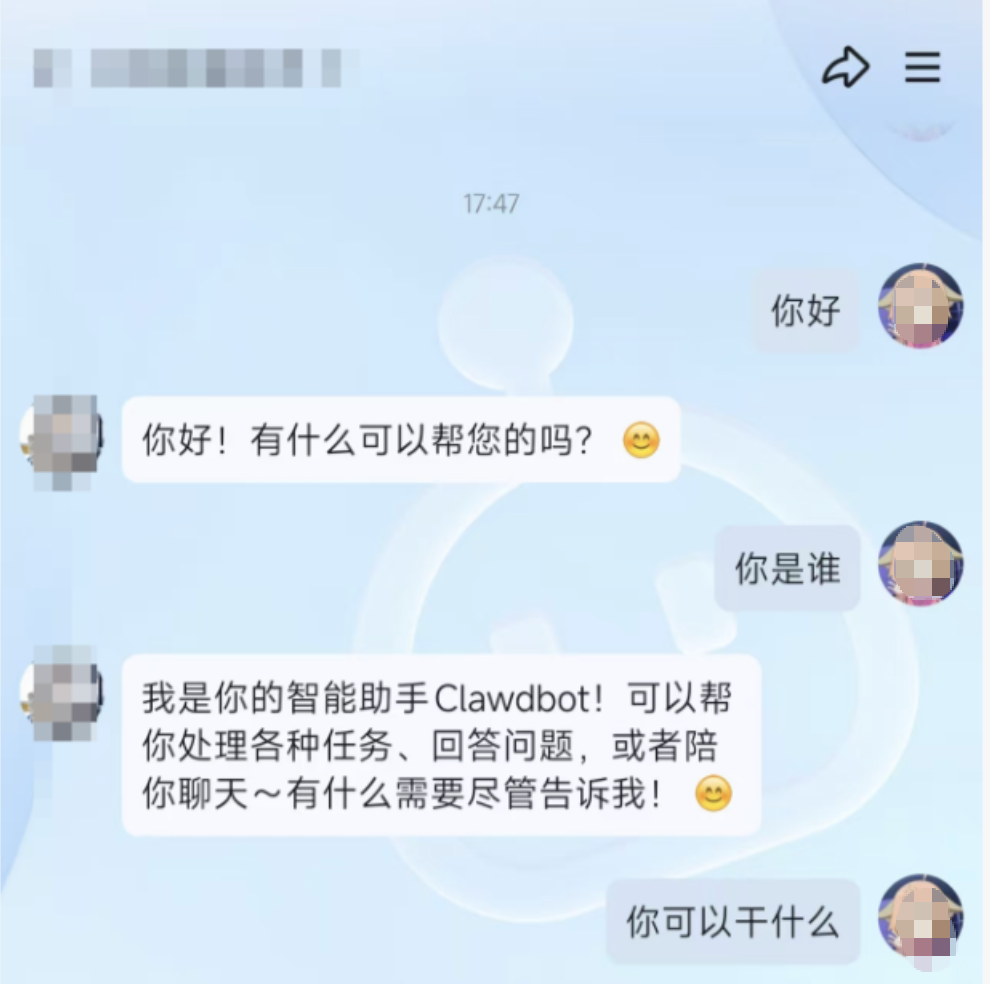
接下来您就可以开始进一步探索OpenClaw接入QQ机器人之后的更多使用场景。
趋势展望
这次在 OpenClaw 连接QQ的场景中对 Qwen3-4B-hygon-flagos 进行了测试,发现Agent 的能力边界正在发生转移。
关键信号
-
小模型开始进入 Agent 执行层 Qwen3-4B-hygon-flagos 已经可以在 OpenClaw 中稳定承担指令理解、工具调用、本地文件操作和协作入口控制等任务。这意味着,小模型第一次从“对话组件”走进了 Agent 的执行中枢。
-
真正的瓶颈不在模型,而在系统 无论 4B 还是更大的模型,在文档写入等能力上同样受限,说明 Agent 的上限越来越多地由平台权限、接口设计和工程抽象决定,而不是模型本身。
如果你要的是一个能在本地跑、能调工具、能接企业系统的 Agent 内核, 4B 级模型,已经开始成为一个现实且合理的默认选项。
Less is More, FlagOS is the Key!
关于众智 FlagOS 社区
众智FlagOS是一款专为异构AI芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。
社区官网:https://flagos.io
GitHub地址:https://github.com/flagos-ai
GitCode地址:https://gitcode.com/flagos-ai
关于HAI
高性能应用服务(Hyper Application Inventor,HAI)是一款面向 AI 、科学计算的 GPU 应用服务产品,提供即插即用的澎湃算力与常见环境,助力中小企业及开发者快速部署 LLM。
而HAI社区是一款面向AI和科学计算等GPU环境的容器镜像中心,提供丰富的官方与社区维护的开发资源。助力企业和开发者快速部署AIGC大模型、计算机视觉、自然语言处理、数据科学等容器,原生集成开发工具与组件。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)