Python后端开发之旅(四)—— AI
Python后端开发之旅(四)—— AI
- 补充知识
- Python进阶——LangChain
-
- ✅ 1. LangChain 0.1.x vs 1.0:版本演进与主要区别
- ✅ 2. 快速入门 LangChain(1.0)
- ✅ 3. [调用方式区别](https://blog.csdn.net/cooldream2009/article/details/153470815)
- ✅ 4. 搜索引擎提供上下文:构建一个智能问答助手
- [与直接调用OpenAI API 区别](https://juejin.cn/post/7473373269888368692)
补充知识
Notebook笔记本(Jupyter/Colab)
在线 Notebook
登录之后:
https://anaconda.com/app/
安装 Jupyter
Vscode的jupyter插件交互没有 浏览器的好,而且也不能安装额外 的插件,更不能进行 演示 slide 的功能- 只能临时作为 不得已的交互方式
- obsidian 的 slide演示功能 画风比较黑暗,而且内容过多的话 容易溢出屏幕,可以通过修改
css进行,但是学习成本有点高 - 所以着手 安装
jupyter啦
UV通过安装依赖
# vscode 的终端bash中操作
## 进入虚拟环境
uv venv --python /e/Lang/Python/Cpython/cpython-3.11.14-windows-x86_64-none
source .venv/Scripts/activate
## 开始安装依赖包
uv init
uv add jupyter --default-index https://pypi.tuna.tsinghua.edu.cn/simple
或者想要快速安装
uv pip install jupyter --default-index https://pypi.tuna.tsinghua.edu.cn/simple
或者没有uv的话
pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple
## 启动后端服务
jupyter --version
jupyter notebook
jupyter notebook /e/Lang # 修改启动目录
jupyter notebook /d/Microsoft/个人简历/教书育人 # 授课路径
# 直接终端中——可能需要NPM(Node Package Manager)?
## 文件夹管理器
win + e -> E:\Lang\LLM\.venv\Scripts
bash
jupyter notebook
## cmd
cd /d E:\Lang\LLM\.venv\Scripts
jupyter notebook
### 或者直接用参数形式启动
jupyter notebook D:\Microsoft\个人简历\教书育人
jupyter notebook . # 当前目录启动
通过 Anaconda——View/Cell Toolbar/Slideshow
一般使用anaconda自带的Anaconda Promp进行操作
Anaconda 安装以及 改变 Jupyter 的启动目录
启动Slide模式:点击这里
“魔法命令”(Magic Commands)
- 是一些以百分号(%)或惊叹号(!)开头的特殊命令,用于执行一些与代码运行环境相关的操作
%开头的魔法命令分为两类:行魔法命令(Line Magic)和单元魔法命令(Cell Magic)。行魔法命令以单%开头,作用于单行代码;单元魔法命令以双%%开头,作用于整个代码单元!开头的命令用于在 Jupyter Notebook 中执行系统命令,类似于在终端中运行命令%lsmagic列出所有可用的魔法命令!调用shell(在新进程中),而%影响与笔记本电脑相关的进程(或笔记本电脑本身;许多%命令没有shell对应项)!cd foo本身没有持久效果,因为更改目录的进程会立即终止。%cd foo更改笔记本电脑进程的当前目录,这是一种持久效果
- 对于
pip命令的区别:%运行shell的环境是当前jupyter运行的虚拟环境比如kernel 是pytorch,输入%pip list,就会显示当前虚拟环境安装的库!运行shell的环境是jupyter的base主环境,输入!pip list,就会显示主环境安装的库
Python库和方法
常见的语法糖
切分词
jieba
- 是一个用于中文文本分词的Python开源库,其名字来源于“结巴”,寓意像结巴一样一个字一个字地分词

import jieba
text = "我来到中南林业科技大学"
# cut 返回一个生成器
result1 = jieba.cut(text)
print("cut结果:", list(result1))
# lcut 返回一个列表
result2 = jieba.lcut(text)
print("lcut结果:", result2)
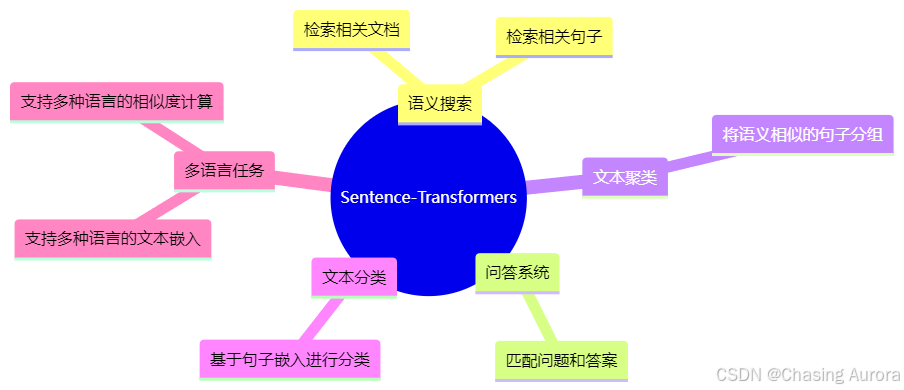
Sentence Transformers(SBERT)
- 基于 PyTorch 的Python库,被自然语言处理(NLP)领域所熟知和使用
- 依托于Hugging Face开发的 Transformers 库,
sentence-transformers专注于将句子或文本映射到高维向量空间,使得语义相近的文本在该空间中的距离也相应接近 - 提供了丰富的预训练模型,涵盖多种语言和任务,即插即用
from sentence_transformers import SentenceTransformer
# 加载预训练模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 生成句子嵌入
sentences = ["我喜欢吃苹果", "今天天气很好"]
embeddings = model.encode(sentences)
print(embeddings.shape) # 输出: (2, 384)
NLTK
- NLTK(Natural Language Toolkit)是Python中功能强大的自然语言处理工具包,支持分词、词性标注、命名实体识别、文本分类、语义分析等多种任务,并内置了丰富的语料库(如Brown、Gutenberg、WordNet等)
- 默认仅支持英文分词,中文需结合
jieba等库 - 停用词(Stopwords) 是指在文本中频繁出现但对分析贡献不大的词,如英文的 the, is, in,中文的“的”“了”等。去除它们可减少噪声、降低计算量并提升模型效果
- NLTK的安装分为库本身和配套数据集两部分,安装完成后,需要下载必要的语料库和模型(首次使用时)
import nltk
# 下载必要的数据包
nltk.download('punkt') # 用于分词
nltk.download('averaged_perceptron_tagger') # 用于词性标注
nltk.download('wordnet') # 用于词形还原
nltk.download('maxent_ne_chunker') # 用于命名实体识别
nltk.download('words') # 用于实体识别的词汇库
nltk.download('vader_lexicon') # 用于情感分析
# 分词
text = "这是一个NLTK的示例代码"
tokens = nltk.word_tokenize(text)
print(tokens)
文档解析
PyMuPDF、pypdfium2、pdfplumber、pdfminer
pdfminer是最早的Python PDF处理库之一pdfplumber专注于PDF文本和表格提取,建立在pdfminer.six的基础上,提供更完整的表格提取功能pypdfium2是PDFium库的Python绑定,PDFium是Google Chrome浏览器使用的PDF引擎PyMuPDF是MuPDF库的Python绑定,基于C++的MuPDF库,性能极高
PDF处理生态系统
├── 底层引擎
│ ├── MuPDF (C++) → PyMuPDF
│ ├── PDFium (C++) → pypdfium2
│ └── pdfminer (Python) → pdfplumber
├── 功能定位
│ ├── 全功能处理:PyMuPDF, pypdfium2
│ ├── 文本提取:pdfplumber, pdfminer
│ └── 表格提取:pdfplumber
└── 性能层次
├── 高性能:PyMuPDF, pypdfium2
└── 中等性能:pdfplumber, pdfminer
- 使用
PyMuPDF(fitz)可以高效地从PDF中提取嵌入图片,还可以将整页渲染为图片,通常还会搭配使用Pillow用于保存图片
tqdm
- 一个快速、可扩展的 Python 进度条库,它可以在循环、迭代器等操作中显示进度条。“tqdm” 这个名字来源于阿拉伯语 “taqaddum”,意为 “进步”
tqdm也常用于深度学习模型训练中,显示训练进度和相关指标:- 使用 tqdm 非常简单,只需要将迭代对象包装在
tqdm()函数中即可
from tqdm import tqdm
import time
my_list = [i for i in range(100)]
for item in tqdm(my_list):
time.sleep(0.1)
json
Json库供用户处理Json格式数据,包括4种方法:
dumps()——将python对象转成json格式的字符串loads()——对字符串进行操作的dump()——将python对象转成json格式存入文件load()——对文件进行操作- 为了方便记忆,可以把loads后面的小尾巴s理解为str
- 不是文件名后缀为
.json的才属于json文件,无论有没有后缀,或者后缀是.txt等,只要文件内容符合下面的格式,都可以使用这些函数- dict:{“姓名”: “张三”, “年龄”: 18}
- list:[“张三”, “李四”]
- 字符串:“张三李四王五” (注意,必须有双引号)
- 纯数字:123
json.dumps()和json.dump()的详细参数ensure_ascii参数- 使用ensure_ascii=False输出原始Unicode字符
- 默认情况下,ensure_ascii=True,非ASCII字符会被转义
indent参数- 使用indent参数进行美化输出
- 默认为 None,用于指定每个层级的缩进空格数,此时输出的JSON数据将尽可能紧凑
json.loads()和json.load()的详细参数
文件操作
tempfile
- 标准库中的一个模块,用于创建临时文件和目录
- 适用于需要临时存储数据的场景。临时文件和目录在使用后可以自动清理,避免手动管理的麻烦
- 自动清理:
TemporaryFile、NamedTemporaryFile、TemporaryDirectory和SpooledTemporaryFile是带有自动清理功能的高级接口,可用作上下文管理器 - 手动清理: 使用 mkstemp 和 mkdtemp 创建的文件或目录需要手动删除
- 比如
shutil.rmtree(temp_dir)可以用于清理 文件夹
shutil(shell utility)
- 标准库中的一个高级文件操作模块,主要用于文件和目录的复制、移动、删除、压缩和解压等操作。它是对
os模块的补充,提供了更高层次的文件操作功能 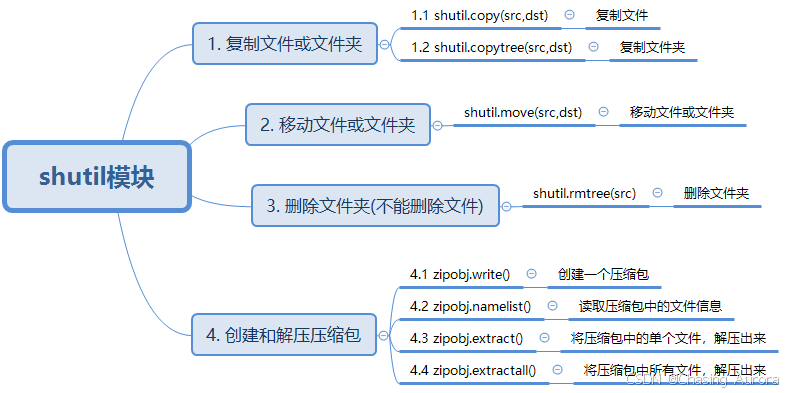
- 保持了 Python “batteries included” 的理念
python-dotenv
python-dotenv是一个用于从 .env 文件读取键值对并加载为环境变量的库,常用于管理敏感信息和配置,符合 12-factor 应用原则- 可以把所有用到的环境变量写到.env文件里,然后以k,v的方式读取作为环境变量
- 从当前目录或其父目录中的.env文件或指定的路径加载环境变量
pip install python-dotenv
# 自动搜索 .env 文件
load_dotenv()
# 或指定路径
# load_dotenv(dotenv_path="config/.env", override=True)
# 获取变量
db_url = os.getenv("DATABASE_URL")
secret = os.getenv("SECRET_KEY")
print(db_url, secret)
# 对于多环境配置,可按优先级加载
for env_file in (".env", ".env.local"):
load_dotenv(env_file)
pandoc
- Pandoc 是由 John MacFarlane 开发的免费开源文档格式转换工具,被称为文档转换界的“瑞士军刀”。它支持在 Markdown、HTML、LaTeX、Word DOCX、EPUB、PDF 等数十种格式之间进行双向或单向转换,并可通过模板、过滤器和自定义样式实现高度定制化
- 除了使用命令行方式之外,很多开发工具和软件都集成了 Pandoc,从而实现文件格式的转换。例如 Markdown 编辑器 PanWriter、Typora,文本编辑器 Atom、Sublime Text、Emacs、Vim,R Markdown,PanConvert、Manubot 等等
# Markdown 转 HTML
pandoc test.md -f markdown -t html -s -o test.html
# Markdown 转 PDF(使用 xelatex 引擎)
pandoc test.md -o test.pdf --pdf-engine=xelatex -V CJKmainfont="思源宋体"
# HTML 转 Markdown
pandoc -f html -t markdown input.html -o output.md
- 常用参数:
- -f/–from:指定输入格式
- -t/–to:指定输出格式
- -s/–standalone:生成独立文件(带完整结构)
- –toc:生成目录
- –css:HTML 输出时附加样式表
网页解析
WARCIO
- 一个高效的Python库,专为读取和写入WARC(Web ARChive)格式设计,广泛应用于网络存档领域
from warcio.capture_http import capture_http
from warcio.warcwriter import WARCWriter
import requests
with open('example.warc.gz', 'wb') as fh:
warc_writer = WARCWriter(fh)
with capture_http(warc_writer):
requests.get('https://example.com/')
lxml
lxml是Python中一个高性能的XML和HTML处理库,它基于C语言编写的libxml2和libxslt库,因此速度飞快,而且API设计得相当友好,特别适合各种结构化数据的处理工作
from lxml import etree
html_content = '''
<html>
<body>
<a href="http://example.com">Example</a>
<a href="http://test.com">Test</a>
</body>
</html>
'''
# 创建解析对象
html_tree = etree.HTML(html_content)
# 使用 XPath 提取所有链接
links = html_tree.xpath('//a/@href')
print(links) # 输出: ['http://example.com', 'http://test.com']
trafilatura
- Trafilatura 把「网页 → 干净正文」这件事做到了「一键可用」的程度,既能当 Python 库嵌入代码,也能当命令行工具批量跑
trafilatura是 依赖于lxml的
import trafilatura
url = 'https://zhuanfou.com/article/79345768_063'
downloaded = trafilatura.fetch_url(url)
# 默认输出纯文本
text = trafilatura.extract(downloaded)
print(text)
# 想要结构化字段
obj = trafilatura.extract(downloaded, output_format='json', with_metadata=True)
print(obj) # 含 title、author、date、text、tags 等
BeautifulSoup
- 是一个用于解析 HTML 和 XML 文档的 Python 库,主要用于从网页中提取数据。它通过提供简单的 API,帮助开发者快速定位和操作 HTML 元素,非常适合用于 网页抓取 和 数据挖掘
- 它支持多种解析器,如
lxml和html.parser,其中 lxml 通常速度更快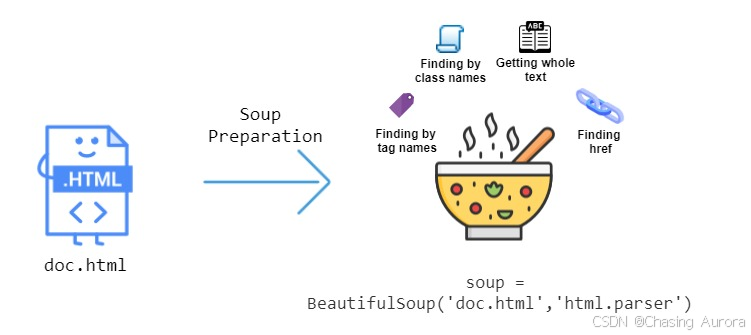
from bs4 import BeautifulSoup
import requests
# 获取网页内容
url = 'https://www.example.com'
response = requests.get(url)
response.encoding = 'utf-8' # 处理中文编码问题
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(response.text, 'lxml')
# 查找 <title> 标签并提取文本
title_tag = soup.find('title')
if title_tag:
print("网页标题:", title_tag.get_text())
else:
print("未找到标题")
- 查找标签:使用 find() 查找第一个匹配的标签,或使用 find_all() 查找所有匹配的标签
- 提取属性:通过 tag.get(‘属性名’) 获取标签的属性值
- 提取文本:使用 tag.get_text() 提取标签内的纯文本内容
LM
Transformers
- Transformers 是 Hugging Face 提供的最先进机器学习模型定义框架,支持文本、计算机视觉、音频、视频及多模态任务,既可用于推理,也可用于训练。它统一了模型定义,使其可跨
PyTorch、JAX、TensorFlow等框架使用 - 不是
torchvision.transforms哦,这个是用于图像预处理和数据增强的核心模块,提供了丰富的图像变换操作,import torchvision.transforms as transforms
| 目标 | 用法 | 适合场景 |
|---|---|---|
| 直接推理 | pipeline() | 快速 demo、验证 |
| 精细控制 | AutoTokenizer + AutoModel | 批处理、自定义输出 |
| 训练微调 | Trainer | 训练/微调自己的模型 |
from transformers import pipeline
# 创建文本生成Pipeline
generator = pipeline(task="text-generation", model="Qwen/Qwen2.5-1.5B")
# 输入提示词
result = generator("人工智能的未来是")
print(result[0]['generated_text'])
TRL(Transformer Reinforcement Learning)
- 一个专为后训练(
Post-Training)Transformer语言模型设计的全栈库。它集成了多种先进的训练方法,如监督微调(SFT)、群体相对策略优化(GRPO)、直接偏好优化(DPO) 和奖励建模
from trl import SFTTrainer
from datasets import load_dataset
# 加载数据集
dataset = load_dataset("trl-lib/Capybara", split="train")
# 初始化训练器
trainer = SFTTrainer(
model="Qwen/Qwen2.5-0.5B",
train_dataset=dataset,
)
# 开始训练
trainer.train()
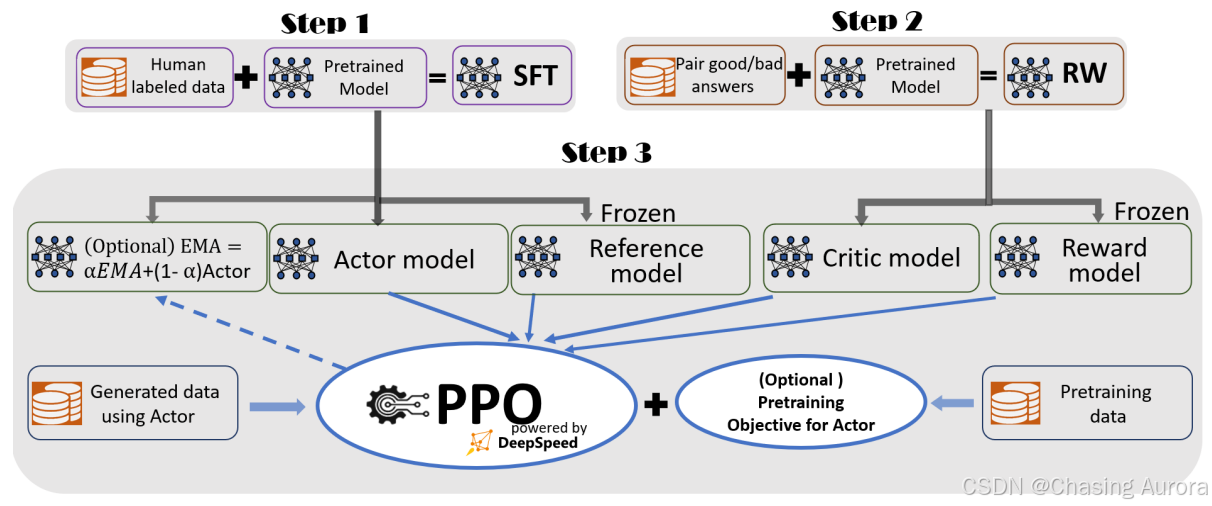
DeepSpeed-Chat
DeepSpeed-Chat是微软Deep Speed团队的开源项目,其完整的提供了Supervised Fine-tuning、Reward Model Training、RLHF PPO Traing三阶段的代码,逻辑简单,模块划分清晰- 旨在通过强化学习与人类反馈(
RLHF)技术,快速训练类似 ChatGPT 的模型。它支持从预训练的大型语言模型(LLM)出发,完成三阶段训练流程,生成高质量的对话模型 - DeepSpeed-Chat中完整的 RLHF 训练流水线,严格遵循 InstructGPT 的三阶段训练逻辑,SFT、RW和PPO
其他
re
- Python 的
re模块是用于处理正则表达式的标准库模块。 - 正则表达式(Regular Expression,简称 regex 或 regexp)是一种强大的工具,用于匹配、搜索和操作文本
re.match()函数用于从字符串的起始位置匹配正则表达式。如果匹配成功,返回一个匹配对象;否则返回Nonere.search()函数用于在字符串中搜索正则表达式的第一个匹配项。与re.match()不同,re.search()不要求匹配从字符串的起始位置开始re.findall()函数用于查找字符串中所有与正则表达式匹配的子串,并返回一个列表re.sub()函数用于替换字符串中与正则表达式匹配的部分match.group()是 Match对象 提取匹配结果的核心方法。当使用re.match()或re.search()成功匹配后group()或group(0):返回完整匹配结果group(n):返回第 n 个捕获组的内容(从 1 开始编号)group(name):返回命名捕获组的内容groups()方法返回一个元组,其中包含所有分组的匹配结果
# 将多个空白字符(包括换行符和制表符)替换为单个空格
text = re.sub(r'\s+', ' ', text)
# 修复常见的OCR问题,将制表符和换行符替换为空格
text = text.replace('\\t', ' ')
text = text.replace('\\n', ' ')
# OCR 常把换行、段落、表格中的间隔当成不同的控制字符,这会造成后续 chunk_text 切片、BM25 分词等逻辑看到不连贯或多余的空白
# 再用 text.split() 去重空格,可以恢复句子连续性
# 去除首尾空白字符,并确保单词之间只有一个空格
# 让单词之间只有一个空格,有助于后续分块和BM25分词的准确性
text = ' '.join(text.split())
nest-asyncio
- nest_asyncio 是一个轻量级 Python 库,用于修补解决
Python asyncio事件循环在嵌套场景下的限制。它允许在已经运行的事件循环中再次运行事件循环- 允许嵌套运行异步代码
- 在
Jupyter Notebook中运行异步代码
- 特别适合在 Jupyter Notebook、交互式 shell 或需要嵌套异步操作的场景中
- 嵌套事件循环:允许在现有 asyncio 事件循环中运行新的异步代码,解决
RuntimeError: This event loop is already running
- 嵌套事件循环:允许在现有 asyncio 事件循环中运行新的异步代码,解决
pip install nest-asyncio
# 修补 asyncio
nest_asyncio.apply()
async def inner_task():
await asyncio.sleep(1)
print("Inner task completed")
async def outer_task():
print("Outer task started")
await inner_task()
print("Outer task completed")
# 在已有事件循环中运行
loop = asyncio.get_event_loop()
loop.run_until_complete(outer_task())
NetworkX
- 用于创建、操作和研究复杂网络的结构、动态和功能的 Python 软件包
- NetworkX 不是专门用于可视化的工具,但它提供了基本的绘图功能,通常与 Matplotlib 库一起使用来显示图形
import networkx as nx
import matplotlib.pyplot as plt
G = nx.Graph()
G.add_edge('A','B',weight=0.5)
G.add_edge('B','C',weight=5)
print(G.adj)
nx.draw(G,with_labels=True)
plt.show()
#结果:{'B': {'C': {'weight': 5}, 'A': {'weight': 0.5}}, 'C': {'B': {'weight': 5}}, 'A': {'B': {'weight': 0.5}}}
监测
Wandb
- Wandb(Weights & Biases,简称就是W&B) 是一个开源且提供免费版本的机器学习实验跟踪与可视化平台,支持在线与离线模式。免费版已包含核心功能,适合个人与小团队使用,可记录超参数、指标、模型版本,并支持团队协作
- 免费版优势
- 无限制实验记录:个人项目可无限保存运行数据
- 可视化仪表盘:实时曲线、图片、混淆矩阵等
- 团队协作:可邀请成员共享项目,支持参数筛选与结果对比
- 离线支持:无网络环境下先记录,后续同步
- 自动调参
传统做法是:
人手动改参数 → 运行训练 → 看结果 → 再调参数。
而 W&B Sweeps 做的事就是自动化这个过程:
它自动生成参数组合 → 启动训练 → 收集结果 → 再决定下一个参数组合
import wandb
import random
# 🐝 1️⃣ Start a new run to track this script
wandb.init(
# Set the project where this run will be logged
project="basic-intro",
# We pass a run name (otherwise it’ll be randomly assigned, like sunshine-lollypop-10)
name=f"experiment",
# Track hyperparameters and run metadata
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
})
# This simple block simulates a training loop logging metrics
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# 🐝 2️⃣ Log metrics from your script to W&B
wandb.log({"acc": acc, "loss": loss})
# Mark the run as finished
wandb.finish()
方法
np.linalg.norm()
- linalg=linear(线性)+algebra(代数),norm则表示范数。
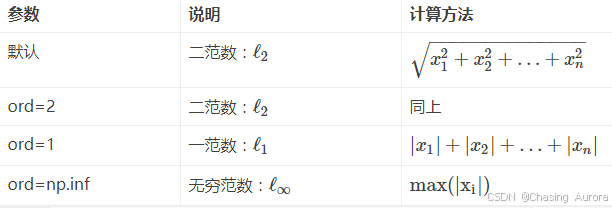
- 函数参数
x_norm=np.linalg.norm(x, ord=None, axis=None, keepdims=False)
- ①x: 表示矩阵(也可以是一维)
- ②ord :范数类型
- ③axis:处理类型
- axis=1表示按行向量处理,求多个行向量的范数
- axis=0表示按列向量处理,求多个列向量的范数
- axis=None表示矩阵范数。
- ④keepding:是否保持矩阵的二维特性
- 默认参数ord=None,axis=None,keepdims=False’
def cosine_similarity(vec1, vec2):
"""
计算两个向量之间的余弦相似度。
参数:
vec1 (np.ndarray): 第一个向量。
vec2 (np.ndarray): 第二个向量。
返回:
float: 两个向量之间的余弦相似度。
"""
# 计算两个向量的点积,并除以它们范数的乘积
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
assert()
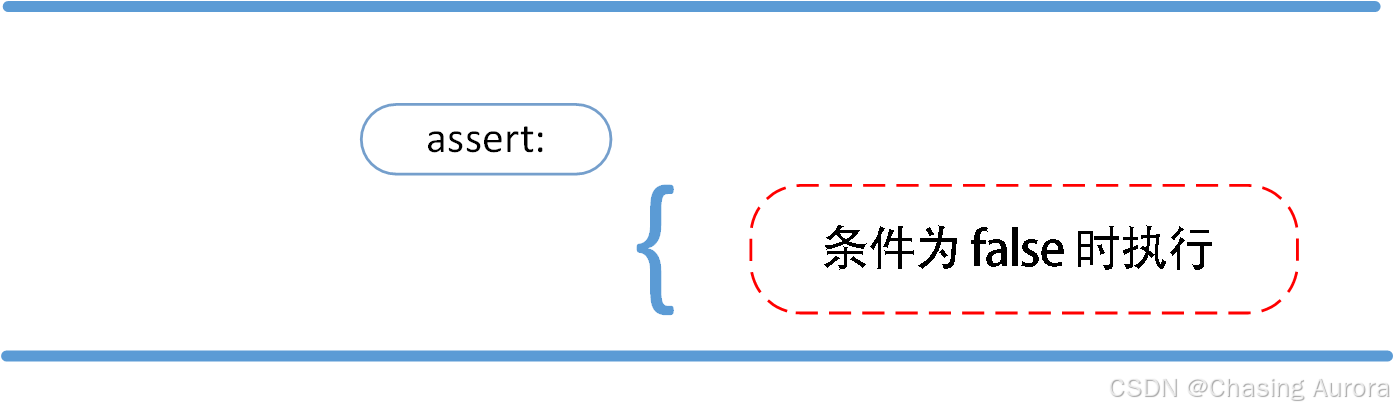
语法格式如下:
assert expression
等价于:
if not expression:
raise AssertionError
assert 后面也可以紧跟参数:
assert expression [, arguments]
等价于:
if not expression:
raise AssertionError(arguments)
Python进阶——LangChain

✅ 1. LangChain 0.1.x vs 1.0:版本演进与主要区别
LangChain 的第一个稳定版本,即 LangChain 0.1.0,于 2024 年 1 月 8 日正式发布,这是一个值得庆祝的里程碑,也是 LangChain 项目的一个新的起点
LangChain 的版本号由三个部分组成,即主版本号、次版本号和修订号,分别表示 LangChain 的大的、中等的和小的更新。例如,LangChain 0.1.0 表示 LangChain 的第 0 个主版本,第 1 个次版本,第 0 个修订版本
| 特性 | LangChain 0.1.x(旧版) | LangChain 1.0(新版) |
|---|---|---|
| 发布时间 | 2024 年 1 月 8 日 | 2025年10月23日 |
| 核心理念 | 模块松散,流程不统一 | 统一、可组合、强类型 |
🔍 关键总结:
- 0.1.x → 多个独立类(如
LLMChain,AgentExecutor)- 1.0 → 统一
Runnable接口,所有组件都是Runnable,模块重组,代码也得改变
✅ 2. 快速入门 LangChain(1.0)
📦 1. 安装
pip install langchain langchain-openai # 以 OpenAI 为例
💡 你也可以用其他 LLM 提供商,如 Anthropic、Cohere、Claude、Google Vertex AI ,DeepSeek等
🧩 2. 核心概念图谱(类比 Java)
| LangChain 概念 | 类比 Java 开发 | 说明 |
|---|---|---|
LLM |
RestTemplate / FeignClient |
调用大模型 API |
PromptTemplate |
String.format() + @Value |
动态生成提示词 |
Runnable |
Function<T, R> / Supplier<T> |
所有组件都实现此接口 |
Chain |
Service + Controller |
逻辑处理 链 |
Tool |
@Component + @Autowired |
工具函数,用于 Agent |
Memory |
Session / Cache |
记忆历史对话 |
LCEL |
Spring Expression Language | 链式表达式语法 (` |
Callback |
Interceptor / AOP |
日志、监控、追踪 |
chain = {“context”: 本地Rag或者工具搜索 , “input”: RunnablePassthrough()} |prompt | llm | JsonOutputParser()
- Conversational(Agent):用于与用户进行自然对话,并接收用户提出的问题,根据提问内容选择具体使用的处理工具
- RetrievalQA(Retriever):用于从自定义资料集中检索相关内容。
DuckDuckGoSearchRun(tool): 用于访问DuckDuckGoSearch搜索API- Prompts & Structured output parser(ModelIO):用于定义接收对话的模板以及结构化搜索引擎查询到的结果并生成一个简洁和准确的回答。
SequentialChain(Chain):用于按照顺序执行以上组件,并将每个组件的输出作为下一个组件的输入- ConversationBufferMemory(Memory):用于在对话中记住以前的交互置,以便在后续的对话中使用。
StdOutCallbackHandler:标准输出用于进行日志记录。
🧱 3. 基础组件详解
- 大部分都是通过
lanchain_core进行导入的 - 通过
from langchain_community.tools import DuckDuckGoSearchRun会导入 社区的工具包 - 还有一部分通过
lanchain导入的是 比较顶层的 工具了,比如from langchain.callbacks import StdOutCallbackHandler进行调式跟踪
✅ 3.1 LLM(大语言模型)
使用 OpenAI(最常见)
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0.7)
📝 你可以通过
os.getenv("OPENAI_API_KEY")读取密钥
自定义 LLM 类(高级用法)——invoke()
from langchain_core.runnables import Runnable
class CustomLLM(Runnable):
def invoke(self, input: str, config: dict = None):
# 实现自己的大模型调用逻辑
return f"Custom response to: {input}"
# 使用
custom_llm = CustomLLM()
result = custom_llm.invoke("Hello")
print(result)
✅ 这样就可以把你的私有模型或本地模型接入 LangChain!
✅ 3.2 提示模板(PromptTemplate)
使用format()进行填入
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"You are a helpful assistant. Answer the question: {question}"
)
# 生成最终提示
formatted_prompt = prompt.format(question="What is Python?")
print(formatted_prompt)
# 输出: You are a helpful assistant. Answer the question: What is Python?
✅ 支持变量替换,可用于动态生成提示
✅ 3.3 工具(Tools)和工具包(Toolkits)
自定义工具(类似 Java 的 Service)
from langchain_core.tools import tool
import requests
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气"""
url = f"https://api.weather.com/forecast?city={city}"
response = requests.get(url)
return response.json()["temperature"] if response.ok else "Error"
工具包(Toolkit)
from langchain_community.tools import DuckDuckGoSearchRun
search_tool = DuckDuckGoSearchRun()
✅ 工具可以被 Agent 调用,实现“查询互联网”功能
✅ 3.4 消息(Messages)与历史记录(Memory)
消息格式(类似聊天上下文)
-
消息是LangChain中对话交互的基本单元,分为两类:
- HumanMessage:表示用户输入(如提问或指令)
- AIMessage:表示AI模型的响应
from langchain_core.messages import HumanMessage, AIMessage
messages = [
HumanMessage(content="Hello"),
AIMessage(content="Hi! How can I help?")
]
记忆机制(Memory)
-
记忆模块用于持久化存储和管理对话历史,常见类型包括:
- ConversationBufferMemory:完整保存所有对话记录
- ConversationBufferWindowMemory:仅保留最近N轮对话
- ConversationSummaryMemory:用LLM摘要压缩长对话
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello")
memory.chat_memory.add_ai_message("Hi! How can I help?")
- 保存对话历史供后续调用(如多轮对话上下文)
- 支持通过
memory.load_memory_variables()读取历史
✅ 类似 Session,但持久化更灵活
✅ 3.5 输出解析(Output Parsing)
目标:让模型返回结构化数据(如 JSON 使用 JsonOutputParser())
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
parser = JsonOutputParser()
prompt = PromptTemplate(
template="Answer only in JSON format: {question}",
input_variables=["question"]
)
chain = prompt | llm | parser
result = chain.invoke({"question": "Who is the CEO of Tesla?"})
print(result)
# 输出: {"name": "Elon Musk"}
✅ 避免模型返回自由文本,提升结构化能力
✅ 3.6 回调处理(Callbacks)
用于日志、追踪、调试
from langchain.callbacks import StdOutCallbackHandler
callbacks = [StdOutCallbackHandler()]
llm.invoke("Hello", callbacks=callbacks)
✅ 可扩展为:
LangChainTracer、LangSmithCallbackHandler(企业级追踪)
LangChain 借助
LangSmith提供了更好的日志、可视化、播放和跟踪功能,以便监控和调试 LLM 应用。LangSmith 是一个基于 Web 的工具,用于可视化和控制 LangChain 的链和代理,能够查看和分析 细化到class的输入和输出
✅ 3.7 LCEL(LangChain Expression Language)
用
|链接模块,像流水线一样执行
就像unix的管道机制
示例:一个简单的 LCEL 流程
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnableSequence
# 1. 提示模板
prompt = PromptTemplate.from_template("Translate this to English: {text}")
# 2. Lambda 函数:转成大写
uppercase = RunnableLambda(lambda x: {"text": x["text"].upper()})
# 3. 链接:先转大写,再翻译
chain = uppercase | prompt | llm
# 执行
result = chain.invoke({"text": "你好世界"})
print(result.content)
- RunnableLambda:将普通 Python 函数包装为 LangChain 可执行的组件
- RunnableBranch 是 LangChain 中用于根据条件选择不同执行路径的组件
- RunnableBranch 接受多个条件判断对
(condition, component)以及一个默认的 fallback 函数 - 每个条件判断对的结构是:
(condition, component),其中:- condition 是一个函数,用于判断输入是否满足某个条件。
- component 是一个可执行的组件(如 RunnableLambda),如果条件满足,则会执行该组件。
- 如果所有条件都不满足,则执行最后一个 fallback 函数
- RunnableBranch 接受多个条件判断对
更复杂的例子:带条件判断
from langchain_core.runnables import RunnableBranch
branch = RunnableBranch(
(lambda x: x["text"].startswith("hello"), lambda x: "Hello!"),
(lambda x: x["text"].startswith("hi"), lambda x: "Hi!"),
lambda x: "Unknown greeting"
)
result = branch.invoke({"text": "hello world"})
✅ 3. 调用方式区别
- invoke():一次性同步调用,等待完整输出后返回。
- stream():流式异步调用,边生成边返回。就是流式响应!!!
- LangChain会将这些结果作为生成器逐步返回,开发者可在接收到每个分片(chunk)时进行实时处理或显示

- LangChain会将这些结果作为生成器逐步返回,开发者可在接收到每个分片(chunk)时进行实时处理或显示
- 有时我们既想实时输出,又想保存完整结果:
chunks = []
for chunk in llm.stream("请解释RAG的原理。"):
print(chunk.content, end="", flush=True)
chunks.append(chunk.content)
full_output = "".join(chunks)
✅ 4. 搜索引擎提供上下文:构建一个智能问答助手
🎯 功能:
- 接收用户问题
- 使用 LLM 生成回答
- 支持简单工具(如搜索)
- 保留聊天历史
🛠️ 代码结构
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableSequence
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.output_parsers import StrOutputParser
# 1. 初始化 LLM
llm = ChatOpenAI(model="gpt-4-turbo")
# 2. 定义工具
search_tool = DuckDuckGoSearchRun()
wikipedia = WikipediaAPIWrapper()
# 3. 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant.请根据以下上下文回答问题:{context}"),
("human", "{question}")
])
# 4. 构建 LCEL 流程
chain = (
{
"question": RunnablePassthrough(),
"context": RunnableLambda(lambda x: search_tool.invoke(x["question"]))
}
| prompt
| llm
| StrOutputParser()
)
# 5. 运行
result = chain.invoke({"question": "Who is Elon Musk?"})
print(result)
- 使用 LangChain 表达式语言(LCEL)构建处理流程:
- 接收输入问题并原样传递(
RunnablePassthrough) - 使用搜索工具获取问题相关上下文
- 将问题和上下文传递给提示模板
- 将模板输出传递给LLM
- 最后使用字符串输出解析器
- 接收输入问题并原样传递(
- 使用
LangChain构建一个结合外部搜索的问答系统。 - 检索到的信息会作为上下文提供给LLM,帮助生成更准确的回答
与直接调用OpenAI API 区别
| 维度 | LangChain集成 | 直接OpenAI API调用 |
|---|---|---|
| 架构设计 | 模块化框架,支持链式操作和Agent决策 | 单点API请求,需手动处理上下文 |
| 数据处理 | 内置文档加载/向量检索/记忆管理 | 需自行实现数据预处理和存储逻辑 |
| 开发效率 | 通过预置组件快速搭建复杂流程(如RAG) | 适合简单问答场景,复杂逻辑需重复造轮子 |
| 多模型支持 | 可混合调用不同模型(如DeepSeek+Stable Diffusion) | 单一模型交互,跨模型协同需额外开发 |
| 适用场景 | 知识库问答/自动化办公/复杂决策系统 | 简单文本生成/翻译/基础对话 |
| 可维护性 | 标准化组件,便于团队协作和代码维护 | 需要自定义实现,可维护性依赖于代码质量 |
| 扩展性 | 易于添加新功能和集成新模型 | 扩展需要修改核心代码 |
在需要精细控制部分环节时,可组合使用两者(如用LangChain处理数据流,关键节点直接调API)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)