DeepSeek V4:中国AI的“软硬协同”突围战
DeepSeek V4:中国AI的“软硬协同”突围战
DeepSeek V4:中国AI的“软硬协同”突围战
当全球AI竞赛进入2026年,一个静默却深刻的转折正在发生:中国人工智能产业正从“算法突围”迈向“系统重构”。而即将问世的DeepSeek V4,很可能成为这一历史性跃迁的标志性节点。
据英国《金融时报》援引知情人士消息,DeepSeek计划于本周发布其V4大模型。这将是该公司自2025年1月发布R1以来的首次重大模型更新。与以往不同,这次发布的核心看点并非仅仅是参数规模或算法突破,而是一场从底层硬件到上层应用的“全链自主”协同突围。
从“模型震撼”到“硬件冲击”
2025年春节,DeepSeek R1的横空出世曾让硅谷经历了一场“地震”。英伟达股价单日暴跌17%的场景,至今仍被业界视为中国AI算法能力的一次集中展示。美国科技界第一次真切感受到,在模型效率层面,中国已具备颠覆性创新能力。
然而,一年后的今天,焦虑的焦点正在发生微妙而深刻的转移。美国CNBC近期推出的专题报道《China’s next AI shock is hardware》,长达40分钟的分析不再聚焦于参数或训练技巧,而是将目光投向了更底层的基础设施。这种关注点的变化本身,就揭示了一个重要事实:中国AI的竞争维度正在升级——从应用层、算法层,向硬件生态层延伸。

V4的技术伏笔:为国产芯片量身定制
DeepSeek V4的“硬件基因”其实早有端倪。早在DeepSeek V3.1发布时,官方就已透露关键技术细节——UE8M0 FP8格式 。这并非偶然,而是为下一代国产芯片量身定制的设计。
FP8格式的战略意义
相比于传统国产芯片普遍支持的FP16格式,原生FP8支持意味着理论性能翻倍,同时大幅降低对带宽的需求。这直接关系到训练成本的压缩——此前传闻V4的训练成本仅为对手的1/50,原生FP8的支持功不可没。
更值得关注的是,据路透社报道,在发布V4之前,DeepSeek并未按行业惯例向英伟达、AMD等美国芯片厂商提供模型预览,而是提前数周向包括华为在内的中国芯片供应商开放访问权限,以便完成适配和优化工作。这一细微却关键的顺序调整,标志着国产AI产业链协作模式的根本性转变。
华为昇腾Atlas 950:算力底座的重构
在国产AI芯片阵营中,华为昇腾系统无疑是支撑DeepSeek V4冲击硬件行业的基石。2026年3月2日,华为在巴塞罗那MWC 2026上首次在海外展示了最新的Atlas 950 SuperPoD,这款“算力巨兽”的规格令人震撼。
Atlas 950 SuperPoD 关键规格
| 指标 | 规格 | 意义 |
|---|---|---|
| NPU规模 | 8192张Ascend 950DT卡 | 前代Atlas 900的20多倍 |
| FP8算力 | 8E FLOPS | 大规模AI训练核心指标 |
| FP4算力 | 16E FLOPS | 高并发推理能力 |
| 互联带宽 | 16PB/s | 超全球互联网峰值带宽10倍 |
| 物理规模 | 160个机柜,约1000平方米 | 超节点集群的实体体现 |
华为计算产品线总裁Seaway Zhang在MWC上强调,Atlas 950 SuperPoD通过UnifiedBus互联技术,使数千个计算节点能够像单台计算机一样运行 。这种“集群+超节点”的创新架构,正在为从移动互联网到智能体互联网的转型提供弹性的计算基础。
全面领先?国产算力的底气
将Atlas 950与英伟达的旗舰产品对比,更能看清其战略定位。根据观察者网的对比数据:
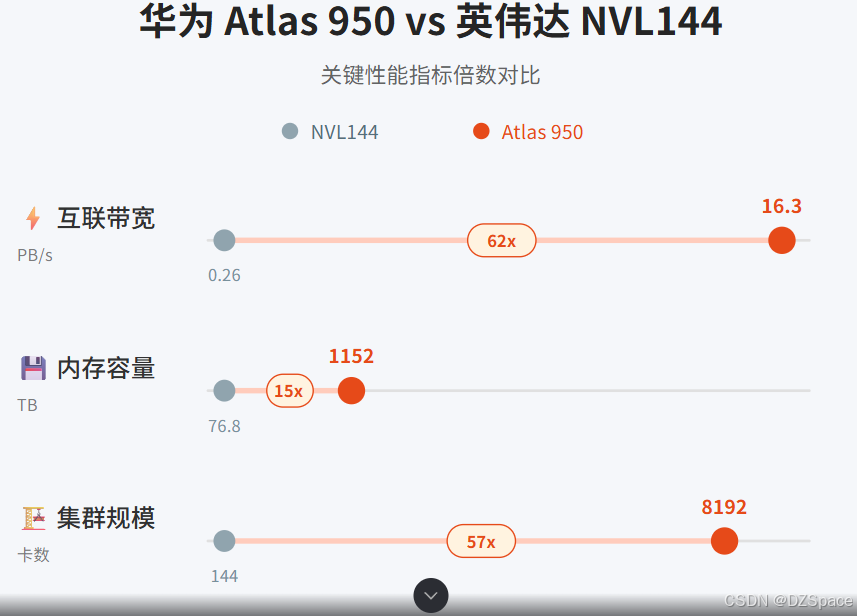
对比英伟达2026年下半年上市的NVL144,Atlas 950超节点卡的规模是其56.8倍,总算力是其6.7倍,内存容量达1152TB(是其15倍),互联带宽更是达到16.3PB/s(是其62倍)。即便是与英伟达计划2027年上市的NVL576相比,Atlas 950在各项关键指标上依然保持领先态势。
华为轮值董事长徐直军曾表示,TaiShan 950加上分布式GaussDB数据库,能帮助金融系统破解核心难题,将成为各类大型机、小型机的终结者。这不仅是硬件性能的超越,更是系统架构层面的重构。
V4的技术亮点:不止于多模态
据《科创板日报》综合消息,正在秘密测试的V4 Lite(精简版)代号为“sealion-lite”,拥有100万(1M)个tokens的上下文窗口,相比V3系列的128K有近8倍提升,理论上可一次处理如《三体》全集体量的长文本。
原生多模态架构
V4为原生多模态架构,意味着模型从预训练阶段就将文本与视觉理解融合,而非后期拼接。泄露的测试示例显示,V4 Lite能用极简代码(如54行)生成高质量的SVG图像,在代码优化和视觉还原度上被认为超越了DeepSeek V3.2、Claude Opus 4.6等模型。
两位知情人士向《金融时报》透露,V4将是一款具备图片、视频和文本生成功能的多模态模型。在硬件适配方面,DeepSeek致力于优化V4模型以适配中国制造的芯片,此举有望提振中国市场对其半导体产品的需求,并加速AI模型“推理”环节靠拢本土芯片。

生态协同:从“单点突破”到“全链自主”
这次DeepSeek V4与华为昇腾的深度绑定,绝非简单的商业合作。知情人士表示,DeepSeek在开发过程中与华为及寒武纪合作,对V4模型进行硬件适配与优化,以匹配其最新AI芯片平台 。
过去很长一段时间,国内大模型厂商的新品首发,无一例外优先适配英伟达GPU。为了抢占首发窗口期,往往仅针对海外芯片做深度优化,国产算力平台只能等到模型正式发布后,再进行漫长的适配调试。这不仅导致国产芯片的性能无法充分发挥,更让整个行业的发展命脉长期受制于海外厂商。
而DeepSeek此次调整适配优先级,核心是两大底层逻辑的转变:其一,华为昇腾算力生态已完成规模化成熟;其二,在芯片出口限制持续收紧的背景下,摆脱对海外算力的单一依赖,实现模型与算力的国产全链协同,是行业长期发展的唯一安全路径。
国产AI软硬件协同时间线
- 2024年5月:DeepSeek V2发布,提出多头潜在注意力(MLA)机制,以极低推理费用出圈
- 2024年12月:DeepSeek V3发布,确立混合专家模型(MoE)技术路线
- 2025年1月:DeepSeek R1发布,引发英伟达股价震荡
- 2025年8月:DeepSeek V3.1发布,首次透露UE8M0 FP8格式
- 2025年:华为公布超节点集群路线图
- 2026年2月:V4 Lite“海狮”内测消息流出
- 2026年3月2日:华为在MWC展示Atlas 950 SuperPoD
- 2026年3月初:DeepSeek V4预计发布
产业意义:重新定义竞争规则
当美国CNBC用40分钟专题讨论“中国下一次AI冲击是硬件”时,他们看到的不仅是单个产品的性能参数,更是一个完整生态系统的崛起。DeepSeek V4与华为昇腾的深度协同,标志着中国AI产业正在完成从“算法突围”到“系统重构”的关键跃迁。
华为在MWC上强调,公司将坚持开源开放,支持领先的开源社区和项目,赋能开发者释放计算潜力,加速AI创新。通过分层解耦,华为已开源CANN——包括算子库、加速库、图引擎和编程语言——使开发者能够高效定制解决方案。
这种“模型+芯片+软件栈+开源生态”的全栈协同,正在构建一个完全自主可控且具备全球竞争力的软硬件生态体系。正如观察者网所指出的,Atlas 950不仅是算力规模和内存容量提升,同时内存访问速度、互联带宽等能力也明显增强。

静待揭晓
截至发稿,DeepSeek官方尚未对V4的任何信息进行正式回应或确认。所有信息均来自媒体爆料,详细信息多集中在正在进行秘密测试的简化版本V4 Lite上 。
但可以确定的是,无论V4最终以何种形式亮相,它都已经不再是一个单纯的大模型发布。这是一场从芯片架构、互联协议、训练框架到应用生态的全方位协同创新,是中国AI产业从跟随到并跑,再到在某些领域领跑的关键一步。
从Hugging Face上超过7500万次的累计下载量来看,DeepSeek依然是全球开源AI领域最受瞩目的存在之一。而这一次,它带来的可能不仅仅是又一个SOTA模型,更是一个全新的产业范式。
当算法与芯片深度耦合,当软件与硬件协同进化,中国AI的“静悄悄革命”正在硬件层悄然展开。这场革命没有喧嚣的发布会,没有炫目的参数比拼,有的只是底层基础设施的系统性重构——而这,或许才是真正意义上的“降维打击”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)