为什么程序员越来越离不开 Claude?三点就解释清楚
AI 模型越来越强,但真正能让程序员“离不开”的模型并不多。
很多人第一次深度用 Claude 时,都会有类似的感受:
“这不是一个聊天模型,而是一个能真正理解代码体系结构的工程同事。”
这并不是错觉,而是源自它背后清晰且高度聚焦的产品定位。
与其说它强,不如说它从第一天起就“只为程序员设计”。
要理解为什么越来越多开发者选择它,我们只需要看清三件事。
一、从一开始就不是“通用模型”,而是“工程模型”
OpenAI 和 Google 的路径是做“十亿人都能用的模型”,因此强调的是通用理解与大众化体验。
而 Anthropic 的路线从第一天起就更明确:
“要让让一百万专业开发者离不开我。”
这直接决定了 Claude 的能力结构:
它会优先强化代码能力、增强结构化推理、投入资源做长上下文,并针对工程体系做专项训练。
因此很多工程师第一次用 Claude 时会觉得无比顺畅
这种体验不是偶然,而是产品定位导致的必然结果。
二、超大上下文让Claude更能“理解一个系统”
很多人把 Claude 的百万级上下文理解成“更大的记忆”。
但对工程师来说,这是第一次能让模型处理真实工程规模。
企业级系统的单模块代码量就能轻松破十万 token,过去我们必须:
- 手工拆文件、裁剪逻辑
- 分几十段让模型“自己拼凑全局”
而现在可以直接把:
- 项目 repo
- 配置文件、技术文档
- 数据库 schema、API 文档
- Git log 和变更说明
一次性全部投入上下文。
而Claude模型能够真正能理解整个系统的结构与意图。
这也是为什么工程师会说:
“GPT 擅长写局部功能,Claude 擅长读大型系统。”
本质是模型设计路线不同。
三、工具链是 Claude 的真正优势
很多人只看到模型本体,却忽略了 Claude 的工程工具链成熟度是行业第一。
Claude Code 爆火的原因不是辅助写代码,而是它能:
- 理解工程规范与依赖体系
- 把项目当成整体推理
- 按团队结构生成完整文件
- 针对工程任务进行系统级分析
它可以“重建一个工程上下文并给出方案”。
这对专业开发者是质变。
相比之下,GPT 偏向通用创作与思维辅助,DeepSeek 更擅长逻辑与推理,而 Claude 则在工程体系中做到最极致。
三者并非谁更强,而是各自做到最擅长的方向。
那么问题来了:既然Claude这么好用,为什么不是所有的创作者都在用呢?
很现实的三点:
直连海外 API 不稳定
时快时慢,甚至无法访问,对代码生成这种高交互任务极不友好。
需要翻墙才能访问
稳定性差,企业合规性也不允许。
官方价格偏高,多客户端管理麻烦
Claude、GPT、Gemini、DeepSeek 都要单独付费、单独对账、单独接入。
尤其是对于工程师来说:
“我想专注写代码,而不是专注折腾 API。”
这就是为什么越来越多团队选择一站式模型平台。
国内开发者更适合用什么方式调用 Claude?
答案是:一站式 API 聚合平台。
例如好易智算
![]()
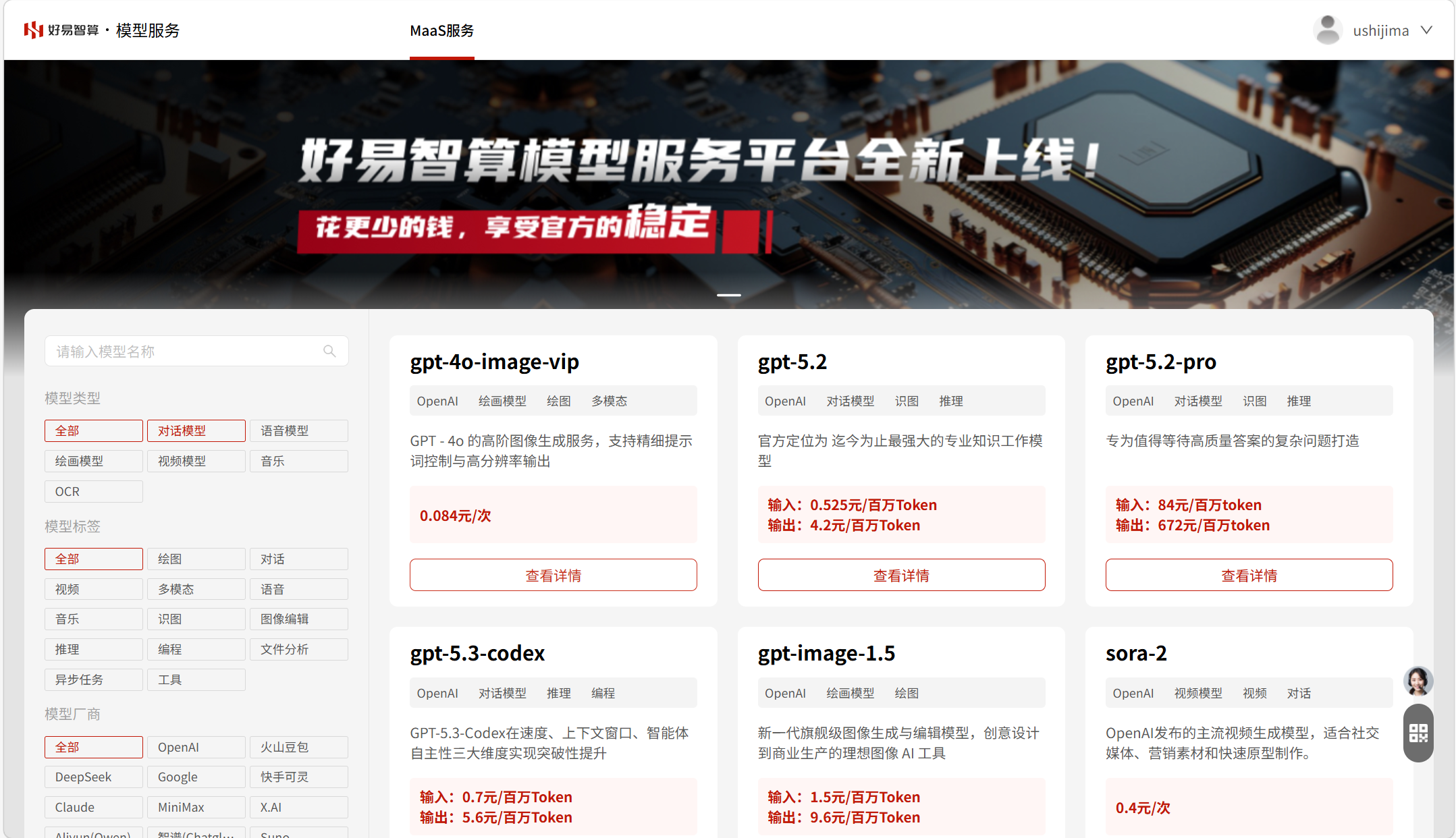
已上线Claude Opus 4.6系列等主流模型。
对于国内用户,有几项非常核心的优势:
1)稳定,不用翻墙,不用自己注册账号,延迟更低
平台做了海外节点优化和加速,对工程师这种高频调用太重要了。
2)官方同源 API,但价格更低
同等模型能力,但成本比官方更友好,非常适合长时间调用与大 token 任务。
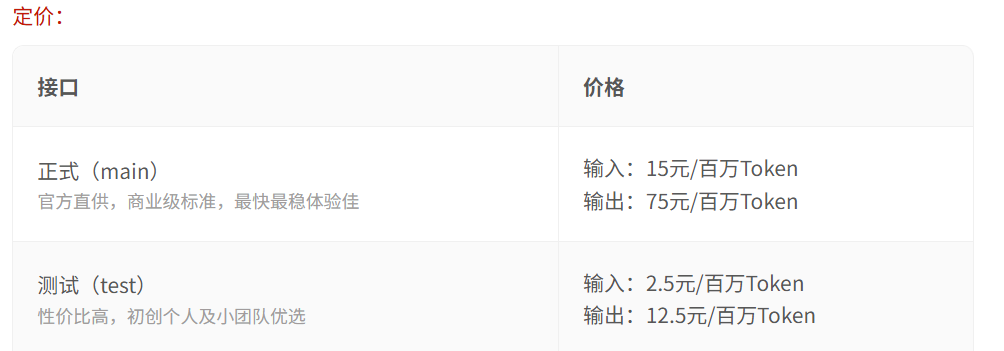
官方价格(美元):
好易智算价格(人民币):
3)多模型统一管理,一站式调用
你可以像切换“模型版本”一样切换:
GPT-5.2-Pro
Claude Opus 4.6
DeepSeek V3.2
Gemini 3.1等 大热模型
对于工程团队来说,这意味着:
“模型更新速度再快,但不用重复改代码。”
“我可以随时换模型评估效果,而不需要任何额外成本。”
“我可以随意调用各平台API但不再需要去各个网站单独充值”
这才是企业级使用的核心价值。
最后:如果你是一名开发者,现在是 Claude 最值得使用的时间点
而如果你是在国内开发,又想长期使用它,
通过我们的一站式 API 平台调用 Claude Opus 4.6 与全系列海外模型,
不用翻墙、速度快、价格低、接入轻松。
模型更新越快,越需要这样的平台。
你只需要开发,剩下的交给我们。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)