Agent 总失忆?这套记忆架构让它过目不忘!
摘要:本文深入探讨了AI在多轮对话中"失忆"问题的根源与解决方案。指出模型无状态性、Token限制和注意力分散是三大核心问题,并提出分层记忆系统架构:短期记忆(对话缓冲区)、长期记忆(向量检索)、摘要记忆(定期压缩)和结构化记忆(键值存储)。文章详细介绍了三种技术实现方案(滑动窗口+摘要、向量检索、多Agent共享状态)及主流工具生态(LangChain/LlamaIndex等
做过 Agent 开发的同学可能都遇到过类似的情况:单轮问答表现完美,一旦进入多轮对话,AI 就开始“犯糊涂”。明明刚才设定的规则,聊着聊着就忘了;上下文稍微长一点,逻辑就断档。有时候你甚至会觉得,这模型是不是“金鱼脑”,只有七秒记忆?
其实,这并非模型不够聪明,而是我们在架构设计上忽略了记忆模块的重要性。在构建多轮对话 Agent 时,如何让模型保持连贯的上下文记忆,是决定体验上限的关键。这不仅仅是把聊天记录传给模型那么简单,而是需要设计一套完整的记忆架构(Memory Architecture)。下面我们将深入拆解如何让多轮 Agent 对话真正实现“不失忆”,并从原理、策略到落地实现进行全方位解析。
一、为什么 Agent 会“失忆”?三大根源剖析
要实现多轮 Agent 对话“不失忆”(即保持上下文连贯性和长期记忆),核心在于解决大模型本身的无状态性(Stateless)与有限上下文窗口(Context Window)之间的矛盾。
很多初学者误以为只要把历史消息塞进 Prompt 就能解决问题,但实际上,Agent 失忆有着更深层次的技术根源。
Agent 失忆的三大根源:
- 无状态性:LLM 每次推理都是独立的,它不知道上一次发生了什么,除非你把历史记录作为输入传给它。模型本身并不具备持久化存储的能力。
- Token 限制:上下文窗口有限(如 8k、32k、128k)。对话越长,早期的信息越容易被截断(Truncation)。一旦超出窗口限制,旧信息就会物理消失。
- 注意力分散:即使 Token 没超,过多的无关信息也会稀释模型对关键信息的注意力(Lost in the Middle 现象)。模型可能会忽略埋在长文本中间的重要指令。
二、分层记忆系统:模仿人类大脑的智慧
要解决失忆,通常采用分层记忆系统,模仿人类的大脑机制。这套架构包含四个核心层级,每一层负责不同的记忆任务。
1. 短期记忆(Short-Term Memory)
- 机制:对话缓冲区(Conversation Buffer)
- 做法:保留最近的 N 轮对话(例如最近 10 轮)完整放入 Prompt
- 优点:保证当前对话的流畅性和即时上下文
- 缺点:超出 N 轮的信息会丢失
- 适用:当前任务的即时逻辑推理
2. 长期记忆(Long-Term Memory)
- 机制:外部存储 + 检索(RAG for Memory)
- 做法:
-
- 将历史对话切片,转化为向量(Embedding),存入向量数据库(如 Chroma、Milvus、Pinecone)
- 当用户发起新请求时,先检索与当前问题最相关的历史片段,注入到 Prompt 中
- 优点:理论上可以记住无限长的历史,且只消耗少量 Token
-
- 例子:用户第一句说“我叫 Alice",第 100 句问“我叫什么”,通过向量检索能找回第一句的信息
- 适用:事实性信息、用户偏好、很久之前的约定
3. 摘要记忆(Summary Memory)
- 机制:定期压缩(Summarization)
- 做法:每隔 N 轮,调用一次 LLM 将过去的对话总结成一段精简的文本(例如:“用户喜欢蓝色,正在开发一个 Python 项目,遇到了报错 X")
- 优点:用极少的 Token 保留核心语义
- 适用:宏观任务进度、用户画像
4. 实体/结构化记忆(Entity/Structured Memory)
- 机制:键值对存储(Key-Value Store)
- 做法:从对话中提取关键实体(姓名、时间、地点、偏好),存入 Redis 或 SQL 数据库
- 优点:查询精准,不会发生幻觉
- 适用:用户 Profile、配置项、明确的任务状态
三、记忆架构全景图:四层协同工作
为了更直观地理解这套系统是如何运作的,我们可以通过下面的架构图来观察数据流向。这是一个典型的多层记忆协同处理流程,确保每一次用户请求都能得到最全面的上下文支持。
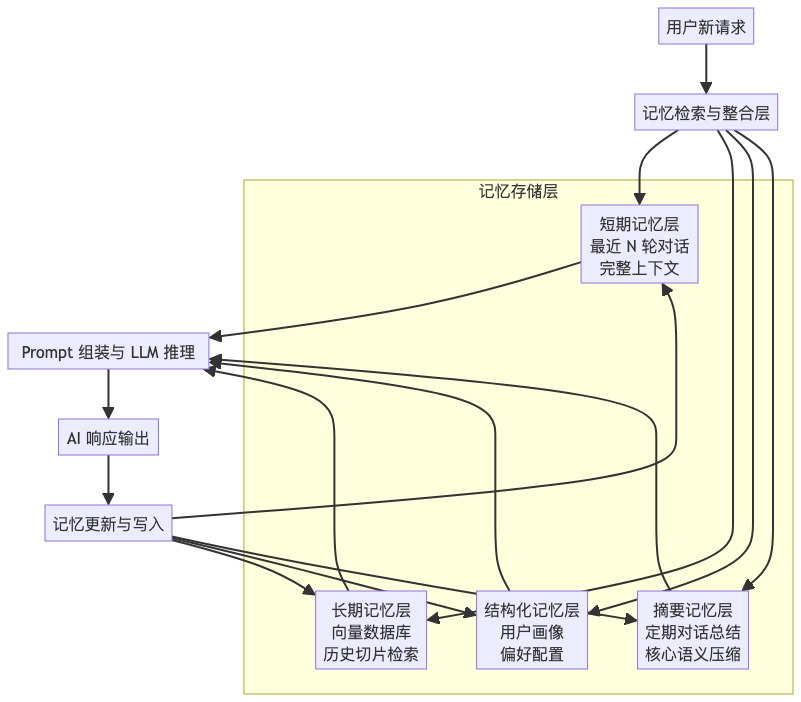
从图中可以看出,记忆不仅仅是存储,更是一个动态的检索 - 组装 - 更新闭环。每一次交互都在强化系统的记忆能力。
四、三大技术实现方案详解
在实际落地过程中,根据业务场景的不同,可以选择不同的技术实现方案。
方案 A:滑动窗口 + 摘要(适合大多数场景)
这是 LangChain 等框架的经典做法,实现成本较低。
- 维护一个
messages列表 - 当列表长度超过阈值,触发摘要操作
- 将旧消息替换为一条
System Message,内容是“历史对话摘要” - 保留最近几轮原始消息
方案 B:向量检索记忆(适合长周期、信息量大)
如果你的应用需要记住用户很久之前的细节,这套方案必不可少。
- 写入:每一轮对话结束后,异步将内容 Embedding 并存入 Vector DB
- 读取:用户输入新 Query → Embedding → 在 Vector DB 搜索 Top-K 相似历史 → 拼接到 Prompt
- 工具:LangChain 的
VectorStoreRetrieverMemory或 Zep、Mem0 等专用记忆层
方案 C:多 Agent 共享状态(Multi-Agent Shared State)
如果是多个 Agent 协作(如一个负责规划,一个负责执行),记忆需要共享。
- 黑板模式(Blackboard):建立一个共享的全局状态对象(Global State)
- 所有 Agent 读写这个对象,而不是只依赖各自的对话历史
- 状态对象包含:
current_task、completed_steps、user_preferences、conversation_history
五、主流框架与工具生态
不要重复造轮子,利用现有生态可以大幅降低开发成本。
1. LangChain / LangGraph
- 提供
ConversationBufferMemory、ConversationSummaryMemory、VectorStoreRetrieverMemory - LangGraph 特别适合管理多 Agent 的状态流转,原生支持持久化检查点
2. LlamaIndex
- 擅长处理知识库和记忆检索,其
ChatMemoryBuffer配合VectorIndex效果很好 - 对于需要结合私有知识库的场景,LlamaIndex 是首选
3. AutoGen(Microsoft)
- 原生支持多 Agent 对话,通过
GroupChat管理消息历史,可自定义记忆存储 - 适合复杂的多角色协作场景
4. 专用记忆层(Memory Layers)
- Zep:专门用于生产环境的 AI 记忆层,自动总结、提取实体、向量检索
- Mem0:新兴的记忆管理库,旨在让 Agent 拥有个性化记忆
- Redis:用于存储快速访问的 Session 状态和用户配置,性能极高
六、最佳实践与避坑指南
在调研和实测过程中,我总结了一些关键的最佳实践,能有效避免常见问题。
1. Prompt 显式指令
- 在 System Prompt 中明确告诉 Agent:“请查阅历史记忆”、“如果用户提到过偏好,请优先遵循”
- 例如:"在回答之前,先检索用户的历史偏好。如果用户之前说过不喜欢长文本,请保持回答简短。"
2. 记忆清洗(Garbage Collection)
- 不要把所有日志都存下来。过滤掉无意义的寒暄(如“你好”、“谢谢”),只存储包含信息量的内容,节省向量库空间和 Token
3. 时间衰减(Time Decay)
- 给记忆加上时间戳。检索时,不仅看语义相似度,还要看时间权重。最近的信息通常比一年前的信息更重要
4. 混合检索(Hybrid Search)
- 结合关键词搜索(BM25)和向量搜索(Dense Vector)。有些专有名词(如订单号、特定产品名)向量检索效果不好,需要关键词匹配
5. 成本与延迟平衡
- 向量检索和摘要都会增加延迟和 Token 成本
- 策略:简单任务只用滑动窗口;复杂任务或检测到用户意图涉及历史时,再触发向量检索
七、落地检查清单
如果你想构建一个不失忆的 Agent,请检查是否完成了以下步骤。这份清单是我在项目复盘时整理的,每一项都对应着一个潜在的失忆风险点。
- 短期:是否保留了最近 N 轮完整对话?
- 长期:是否接入了向量数据库存储历史?
- 摘要:是否有机制定期总结对话大意?
- 结构化:是否提取了用户关键信息(名字、偏好)存入 KV 数据库?
- 检索:每次回答前,是否根据当前问题检索了相关历史?
- 多 Agent:如果是多 Agent,是否有共享的 State/Blackboard?
通过组合滑动窗口(保流畅) + 向量检索(保细节) + 摘要总结(保宏观) + 结构化存储(保配置),可以最大程度实现 Agent 的“长记性”。
记住,记忆架构不是一成不变的,需要根据你的具体业务场景、成本预算和性能要求灵活调整。从简单的滑动窗口开始,逐步引入向量检索和摘要机制,才是稳健的演进路径。
现在,你的 Agent 终于可以告别“金鱼脑”,真正成为用户的智能伙伴了!希望这套架构能为你的项目带来实质性的帮助。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)