为什么数据标准平台必须对接大模型?
摘要: 数据标准平台与大模型的对接实现了数据治理的智能化跃迁。业务层面,大模型将数据标准制定、元数据管理等人工流程效率提升60%以上,并通过动态适配和智能应用释放数据价值,典型场景包括自动生成标准草案、语义化元数据填充等。技术架构上,通过“数据层-接口层-应用层”协同,确保数据安全与流程可控,关键技术涉及标准化数据供给、统一接口网关及提示词工程。落地挑战包括模型幻觉风险与数据合规,需通过多层校验和
在 AI 大模型规模化落地的今天,企业普遍陷入 “模型强、数据弱” 的困境:大模型如同高性能发动机,但分散、异构、低质量的数据却无法提供合格燃料。数据标准平台作为企业数据治理的核心枢纽,其核心价值在于建立统一的数据规范与质量体系;而大模型则具备强大的语义理解、自动化处理与动态适配能力。两者的对接,本质是标准化数据资产与智能化处理能力的深度融合,实现从 “数据治理” 到 “数据智理” 的跃迁 —— 既解决大模型 “喂料难” 问题,又让数据标准平台突破传统人工治理的效率瓶颈。
一、业务视角:对接的核心价值与应用场景
1. 三大核心业务价值
- 降本增效:将数据标准制定、元数据维护等人工流程的效率提升 60% 以上,某金融机构通过大模型自动生成指标口径,合规检查时间从月级缩短至小时级;
- 动态适配:应对业务快速变化,自动更新数据标准(如电商新品类字段自动匹配已有规范),解决传统静态治理的滞后性;
- 价值放大:让标准化数据资产通过大模型转化为直接业务成果(如智能问数、自动生成分析报告),实现 “数据 - 模型 - 应用” 的闭环价值。
2. 四大典型业务场景
|
场景 |
传统做法痛点 |
对接大模型后的解决方案 |
|
数据标准制定 |
人工梳理业务术语,跨部门口径难统一 |
大模型基于行业规范(如 DCMM、DAMA)+ 企业历史数据,自动生成标准草案,推荐字段匹配策略 |
|
元数据管理 |
手动录入字段含义、敏感等级,工作量大 |
语义分析自动填充元数据(如 “cust_id” 识别为 “客户唯一标识”,敏感等级标注 “高”) |
|
数据质量管控 |
规则引擎依赖人工配置,异常识别滞后 |
大模型实时检测异常(如价格波动 ±30%),自动生成修复建议,甚至一键修复简单问题 |
|
数据服务化 |
业务人员需通过 IT 获取数据,响应慢 |
自然语言交互(如 “统计近 30 天华东地区销售额”),大模型自动生成 SQL 并调用标准数据接口返回结果 |
3. 行业落地案例
- 交通基建行业:中交集团通过数据标准平台整合 400 亿 Token 行业数据,对接 “交融大模型”,实现施工方案智能生成、设备故障诊断等 100 余项场景应用,行业问答准确度达 85%;
- 政务领域:某省应急厅通过数据标准平台统一预案数据,对接大模型构建 “智能问数” 应用,跨部门数据获取效率提升 3 倍;
- 烟草行业:面对跨境物流等新兴场景样本不足,通过大模型扩充训练数据,数据标准覆盖率从 39.4% 提升至 63%。
二、技术视角:对接的架构设计与关键实现
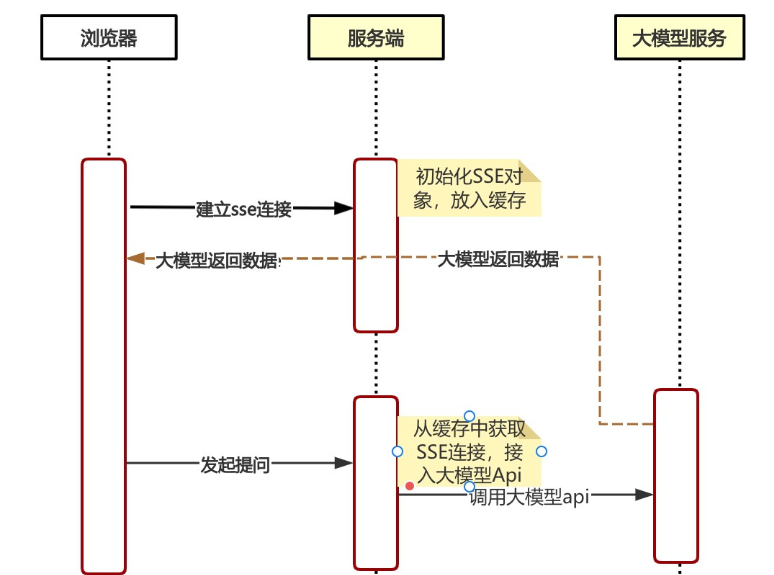
1. 整体对接架构:三层协同模型
数据标准平台与大模型的对接需构建 “数据层 - 接口层 - 应用层” 的协同架构,确保数据安全、流程可控、结果可信:
plaintext取消自动换行复制
2. 关键技术环节拆解
(1)数据层:标准化数据供给
- 数据治理适配:通过数据标准平台的 MDM 模块(主数据管理),统一客户、产品等核心数据的编码规则与属性定义,消除 “同物异码” 问题,为大模型提供一致性输入;
- 数据质量管控:执行 “清洗 - 脱敏 - 校验” 流程,剔除重复数据、修正格式错误,同时通过脱敏算法保护敏感信息(如身份证号掩码处理),避免大模型训练 / 推理时泄露隐私;
- 数据分级供给:针对大模型训练场景,输出批量历史标准化数据;针对推理场景,通过实时同步机制提供最新数据(如交易系统实时数据同步至标准平台后供模型调用)。
(2)接口层:标准化通信桥梁
- 统一接口网关:采用 OneAPI 等工具,将不同大模型(OpenAI、通义千问、本地模型)的异构接口标准化,数据标准平台只需对接一套 OpenAI 兼容接口,即可调用任意模型,降低适配成本;
- 接口能力封装:
- 批量接口:供大模型训练时调用,支持高并发批量数据传输(如一次性同步 1000 万条标准化订单数据);
- 实时接口:供模型推理时调用,基于 ESB 服务总线实现毫秒级响应(如实时查询客户信用等级);
- 接口安全管控:通过 Token 认证、IP 白名单、HTTPS 加密等机制,管控大模型的接口访问权限;同时记录全量调用日志,实现 “谁调用、调用什么数据、用于什么场景” 的全链路审计。
(3)应用层:智能化协同逻辑
- 提示词工程(Prompt Engineering):将数据标准规则(如字段定义、质量阈值)嵌入提示词,引导大模型生成符合规范的结果(如 “按企业客户数据标准,分析近一年复购率”);
- 人机协同反馈:大模型生成的标准草案、元数据标注等结果,需经数据专家审核确认后,再同步至数据标准平台,同时将审核意见反馈给模型进行迭代优化(如标注 “此字段定义错误” 后,模型下次自动修正);
- 模型幻觉防御:建立 “数据标准校验机制”,大模型生成的结果需与数据标准平台的规范进行比对,如发现冲突(如虚构字段含义)则触发告警,避免错误扩散。
3. 技术选型建议
|
技术需求 |
推荐方案 |
优势说明 |
|
多模型适配 |
OneAPI/APISIX |
支持 27 + 主流大模型,自动抹平请求格式、认证方式差异,开箱即用 |
|
数据实时同步 |
Flink/Debezium |
实现业务系统与数据标准平台的实时数据同步,延迟低至秒级 |
|
语义分析与元数据生成 |
通义千问 / 文心一言 + 行业微调 |
通用大模型经行业数据微调后,元数据识别准确率提升至 90% 以上 |
|
本地部署与安全合规 |
百度文心一言企业版 / 百分点百思大模型 |
全栈信创适配,支持私有化部署,满足政务、金融等行业的数据不出域要求 |
三、落地挑战与应对策略
1. 三大核心挑战
- 模型幻觉风险:大模型可能生成不符合实际的数据标准或元数据(如虚构数据血缘关系);
- 数据安全合规:对接过程中需确保标准化数据不泄露,同时满足《数据安全法》《生成式 AI 服务管理暂行办法》等监管要求;
- 业务适配难度:不同行业、企业的业务场景差异大,通用大模型难以直接匹配个性化数据标准。
2. 应对策略
- 幻觉防御:建立 “三道防线”—— 业务部门自查→IT 部门审核→管理层监督,同时将数据标准规则嵌入模型推理流程,强制校验结果合规性;
- 安全合规:采用 “数据不出域” 部署模式(大模型部署在企业内网,不与公网连通);对输出结果进行敏感信息检测,避免标准化数据中的核心资产泄露;
- 个性化适配:基于企业数据标准体系构建行业知识图谱,通过 RAG 技术(检索增强生成)让大模型在回答时优先引用企业自有标准,提升适配度。
四、总结:从 “对接” 到 “融合” 的演进方向
数据标准平台与大模型的对接,不是简单的技术叠加,而是数据治理模式的根本性变革 —— 从 “人工主导的静态治理” 转向 “模型赋能的动态自治”。其核心逻辑是:数据标准平台提供 “可信数据燃料”,大模型提供 “高效处理引擎”,两者协同实现数据资产的价值最大化。
未来的演进方向将聚焦三个维度:
- 全流程自动化:通过 AI Agent 技术,实现 “数据标准制定→质量管控→服务化应用” 的全自动闭环,无需人工干预;
- 行业化深化:构建垂直行业的 “数据标准 + 大模型” 解决方案(如金融数据治理大模型、政务数据治理大模型),提升场景适配度;
- 生态化协同:建立跨企业的数据标准知识共创网络,让大模型学习行业共性标准,同时适配企业个性化需求,推动数据资产跨域流通。
对于企业而言,落地的关键不是追求 “一步到位”,而是先从元数据自动标注、数据标准草案生成等高频场景切入,积累实践经验后再逐步扩展至全流程智能化 —— 毕竟,让数据标准平台与大模型真正发挥价值的核心,永远是 “业务驱动、实用为先”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)