不需要5090,英伟达喊你免费白嫖 GLM-4.7 和 Minimax
英伟达NIM平台免费开放GLM-4.7和Minimax-M2.1模型调用,无需高性能显卡或复杂部署。用户只需3分钟完成注册、手机验证并获取API Key,即可通过标准OpenAI接口使用。每分钟40次请求的额度适合个人开发需求,中文处理能力优异。建议开发者尽快申请,抢占这波免费资源红利。
不需要5090,英伟达喊你免费白嫖 GLM-4.7 和 Minimax!
最近英伟达悄悄发了一波大福利。
我发现他们的 NIM平台上,竟然可以直接免费调用 GLM-4.7 和 Minimax-M2.1 这两个重磅模型!
重点是:
对于我们这种想在编辑器里快速集成 AI,或者做一些轻量级开发测试的朋友来说,这简直就是降维打击。今天就手把手带大家薅这把“显卡皇”的羊毛。
保姆级教程:3分钟搞定 API Key
整个过程非常丝滑,我实测下来大概只需要 3 分钟。
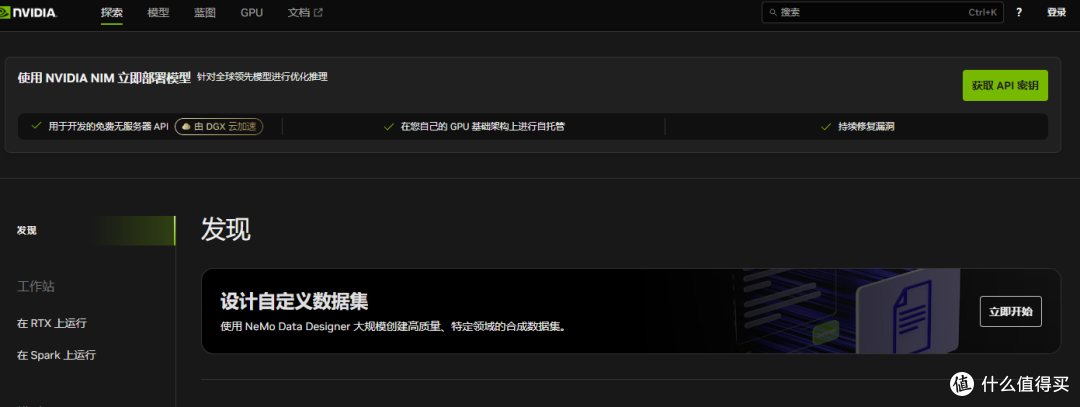
第一步:注册与登录
直接访问 NVIDIA NIM 的集成主页: 🔗 build.nvidia.com/explore/discover
如果你还没有英伟达账号,直接注册一个。建议优先使用邮箱注册,方便后续管理。
第二步:手机号验证
这是很多人担心卡住的地方。注册成功后,为了防止接口被滥用,英伟达会要求验证手机号。
不要因为看到是国外平台就劝退!中国大陆的 +86 手机号是完美支持的。
在验证页面直接选择 “China”,输入你的手机号,接收验证码即可。整个过程非常流畅,没有任何阻碍。验证通过后,你就正式拥有了免费调用 API 的权限。
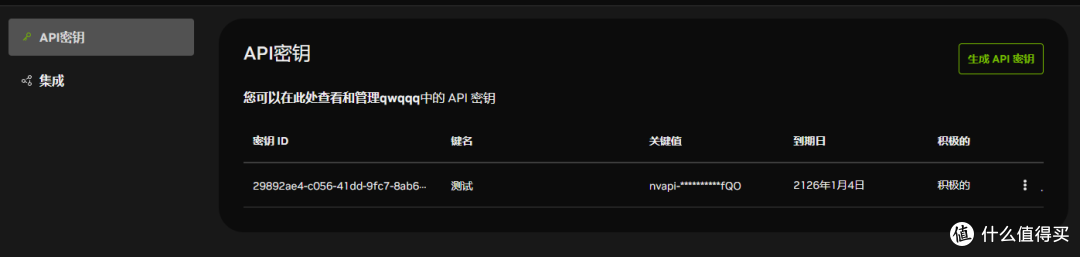
第三步:获取 API Key
登录成功后,在模型列表中随便点开一个模型(虽然我们要用 GLM 或 Minimax,但 Key 是通用的,你点 DeepSeek-R1 或 Llama-3 进去也行)。
-
点击页面右上角的 “Get API Key”。
-
生成后,一定要点击 “View Code” 并没有立即复制,系统会为你生成一个以
nvapi-开头的长密钥。 -
请务必第一时间保存好这个 Key,页面刷新后可能就看不到了。
实战配置:VSCode / Cursor 接入指南
拿到 Key 怎么用?最直接的场景当然是放在代码编辑器里辅助编程。以下是标准配置参数,适用于所有支持 OpenAI Compatible 协议的软件(如 VSCode 的各种 AI 插件、Cursor、沉浸式翻译等)。
配置参数抄作业:
-
API Provider: OpenAI Compatible
-
Base URL:
https://integrate.api.nvidia.com/v1 -
API Key: 填入你刚才申请的
nvapi-xxxx... -
Model ID (模型名称):
-
如果你想用智谱:
z-ai/glm4.7 -
如果你想用 Minimax:
minimaxai/minimax-m2.1
-
为什么推荐这一波?
1. 额度真香: 大家最关心的限制问题,我也看了一下。目前的限制是 Your API Rate Limit Up to 40 rpm(每分钟 40 次请求)。
说实话,对于个人开发者、写代码辅助、或者日常润色文章来说,每分钟 40 次几乎等于无限畅用。除非你是想拿去跑批量数据清洗,否则根本触不到这个天花板。
2. 模型硬核: GLM-4.7 和 Minimax-M2.1 都是目前国产模型里的第一梯队。特别是在处理中文语境、长文本理解上,效果往往比原生的 Llama 系列更好。现在能通过英伟达的服务器免费跑,稳定性和速度都有保障。
建议大家趁着现在限制还没收紧,赶紧去申请一个 Key 备用。 这种大厂的羊毛,手慢无!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)