Elastic Streams 中的 Log Processing UX 设计
《Elastic Streams日志处理UX设计:简化复杂数据的可操作性》摘要:Elastic设计团队通过Streams项目重构了日志处理体验,将原本20多个技术步骤简化为2个核心流程。该方案采用AI驱动的智能分区和字段提取,同时强调数据一致性原则,通过"创建-预览-确认"的分屏原型设计确保处理安全性。设计解决了传统日志处理中GROK模式编写、管道管理等复杂性问题,引入嵌套拖放
作者:来自 Elastic Boris Kirov 及 Patri Pascual

探索 Elastic Streams 中的 log processing 以及 Processing UX 背后的设计决策,这些设计使 log 数据更易访问、一致且可操作。
这篇文章从 Elastic Observability 设计团队的视角撰写,面向处理 logs 和 ingest pipelines 的开发者和 SRE,解释了设计决策如何塑造了 Streams 中的 Processing 体验。
日志处理中的设计问题
我们很少谈项目究竟是如何开始的。
如何设计尚未完全存在的功能?
如何将 AI 能力、系统限制、真实用户痛点整合成一个连贯的体验?
Streams 就给了我们这样的挑战。
日志是 observability 中最丰富的信号之一——但也是最混乱的之一。Streams 是一个 agentic AI 驱动的解决方案,重新思考团队如何处理日志,以支持快速的 incident 调查和解决。
Streams 使用 AI 对原始日志进行分区和解析,提取相关字段,减少 schema 管理开销,并突出关键事件,如 critical errors 和 anomalies。
这让日志从一开始就可以直接用于调查,而无需 Site Reliability Engineer 与数据斗争。但为了实现这种体验,我们必须仔细重新思考流程中的核心概念和步骤 —— Processing。
Elastic Streams 中的 Processing UX 设计
日志强大,但前提是它们结构正确。今天,用户通过 Elastic Agent 上线日志,使用自定义 integration,提取像 IP 字段这样简单的信息需要:
-
编写 GROK patterns
-
创建 pipelines
-
管理 mappings
-
测试 transformation
-
反复迭代
听起来简单的步骤实际上需要 20+ 个步骤 —— 而且大多数团队不应该需要如此深厚的专业知识。我们的目标很简单:让这一过程大幅简化。
我们早期的设计问题是:
“我们能否将这个体验从 20 个技术步骤缩减到 2 个有意义的步骤?”
这个问题塑造了我们对 Streams UX 的设计方法。
基础
在我们开始设计 Kibana 中的 UI 之前,我们先定义了一个核心心理模型。
一个 Stream 是一组存储在一起的 documents,它们共享:
-
Retention
-
Configuration
-
Mappings
-
Processing rules
-
Lifecycle behaviour

关键设计原则:
“一个 Stream 应该包含行为一致的数据。”
为什么数据一致性重要?
我们从一个示例开始来测试我们的想法。以 Nginx 的 access 和 error logs 为例。
Access logs 描述请求/响应事件:
192.168.1.10 - - [16/Feb/2026:12:32:10 +0000] "GET /api/orders/123 HTTP/1.1" 200 532 "-" "Mozilla/5.0"
Error logs 描述诊断事件:
2026/02/16 12:32:10 [error] 2719#2719: *342 connect() failed (111: Connection refused) while connecting to upstream…
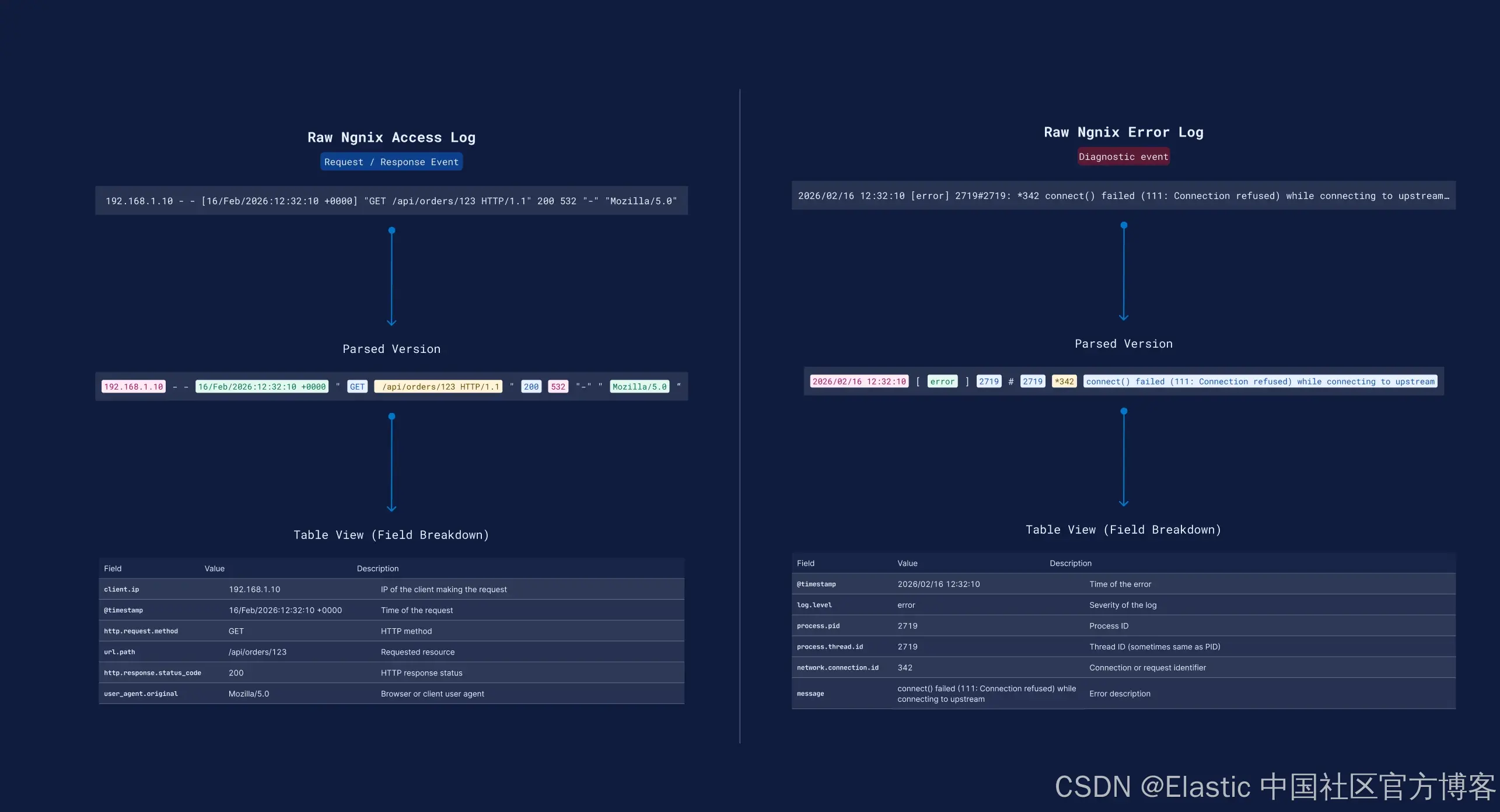
如果两者都存在于同一个 Streams 中,可能导致:
-
Processing logic 冲突
-
Field divergence
-
Mapping 冲突
-
调查工作将变得更困难
这个洞察明确了一点关键:
“Processing 不仅仅是提取字段。它是为了保护一致性。”
让复杂性可管理
Ingest 生态系统并不小、简单或假设性。真实的 pipelines 使用数十种 processors —— 从常见的 rename、set、convert 和 append,到小众类型如 urldecode 和 network_direction。
UI 必须同时支持高频操作和长尾边缘案例,同时保持结构完整。目前 Elasticsearch 支持 40 多种不同的 ingest processors。我们必须确保界面能够处理这些不同类型。

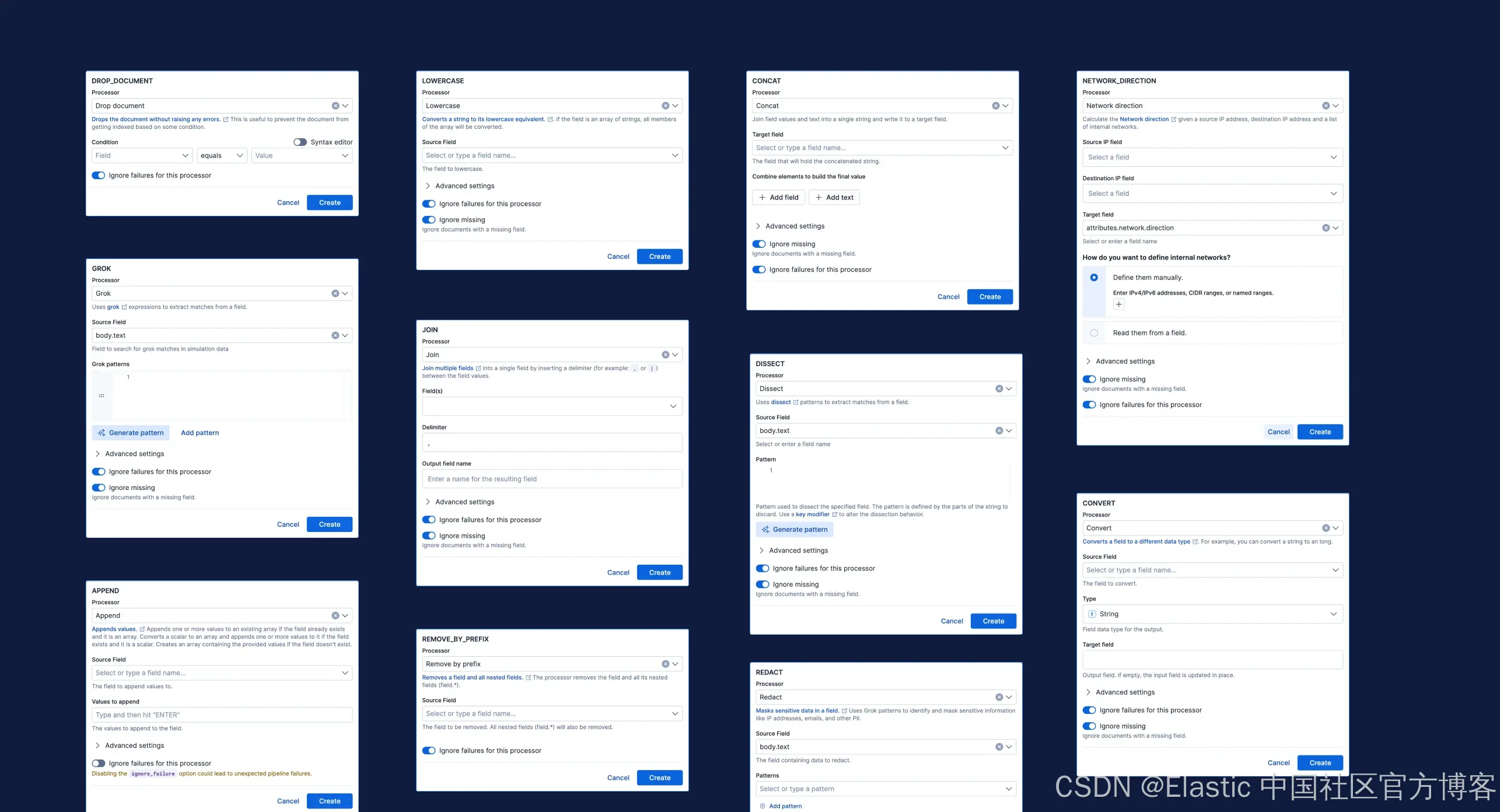
我们引入了清晰的、嵌套的 pipeline 步骤结构。用户可以自信地创建、重新排序、编辑或删除单个步骤或分组步骤。嵌套的拖放功能也作为模式被加入到我们的 EUI 库中。
这为我们提供了上下文和基础,使我们能够将这些概念整合到一个对 Streams 中所有内容都具有决定性的模型中。
页面原型
Processing 功能强大 —— 但也有风险。更改解析条件或步骤可能影响:
- Field 可用性
- Search 行为
- Alerts
- AI Insights
- 调查工作
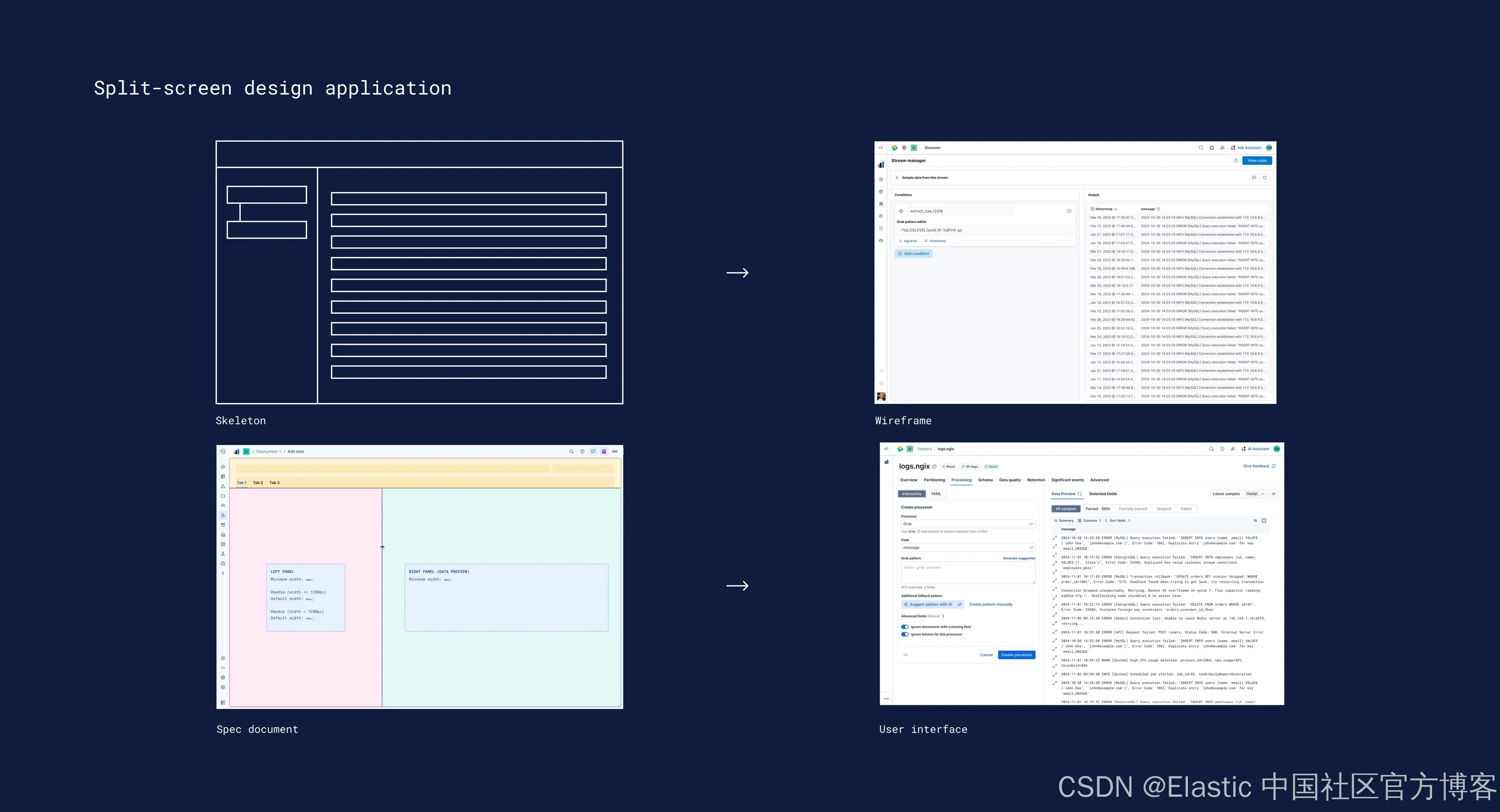
因此我们问自己:如何让这样强大且重要的功能对用户安全?答案引出了一个核心页面原型:
Create > Preview > Confirm
这不是后期添加的 UI 模式。它直接源自我们的概念设计工作,以及对用户需要处理内容的理解。

为了支持这个原型和核心理念,我们还引入了分屏结构。
左侧:Build
这里用户可以:
-
添加 processing 步骤
-
定义条件
-
应用规则
-
利用 AI 建议,无论是整个 pipeline 创建,还是单个步骤如 GROK processor
界面保持专注、有意图且结构化。
右侧:Preview
这里用户可以:
-
查看真实日志样本
-
查看上下文中的提取字段
-
对更改立即反馈,包括文档匹配和未匹配比例的洞察
-
可选的右侧 drilldown 面板

Preview 面板成为了信心的锚点。这不仅仅是为了视觉上的对称,而是为了强化实验、控制错误并减少失误。考虑到用户可能希望在交互与详细 preview 之间切换焦点,我们为两个面板引入了可调整大小功能,从而解锁了更多的灵活性和对使用场景的控制。
AI 自动化
Streams 是智能 agent 驱动的 AI 解决方案。这为设计增加了复杂性,但也提供了从用户日志数据中解锁更多能力和洞察的机会。
AI 引入了新的矛盾:如何加速处理,同时不让它变成一个黑箱?
我们建立了几个 guardrails:
-
清晰、简明的建议
-
通过匹配文档指标可见的影响
-
可检视性
-
与 Create → Preview → Confirm 模型保持一致

Processing UX 成为 automation 与 human in the loop 之间的桥梁。日志数据是最强大的调查信号之一。每一个设计决策都强化了这一信念。
我们学到的
为未来设计并不是从屏幕开始。它从以下内容开始:
-
边缘案例测试
-
清晰的 mental models
-
强有力的指导原则
-
行为一致性
-
可扩展且经过压力测试的 archetypes
我们知道,为了让用户能够从日志中发现有价值的洞察,他们需要有效地处理和管理数据。我们清楚自己在塑造他们整个 observability 基础。
Processing 关乎 trust、control 和可扩展的数据管理。
-
Trust 促进调查速度。
-
调查速度促进韧性。
了解更多
在 cloud.elastic.co 注册 Elastic trial,并试用 Elastic 的 Serverless 服务,这将让你体验 Streams 的全部功能。想了解更多关于 Streams 的信息?查看以下链接:
-
阅读关于 Reimagining streams
-
阅读关于 Retention management
-
浏览 Streams 网站
-
查看 Streams 文档
原文:https://www.elastic.co/observability-labs/blog/designing-log-processing-ux-for-streams

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献170条内容
已为社区贡献170条内容

所有评论(0)