当大语言模型学会诊断:基于ChatGLM2-6B提示微调的机械故障智能诊断
本文提出了一种基于大语言模型(LLM)的机械故障诊断新方法。通过将传统振动信号特征(24维时频域特征)转换为自然语言描述,并微调ChatGLM2-6B模型进行故障分类,实现了诊断过程的可解释性。该方法采用LoRA技术高效微调,仅需训练约600万参数,在保持模型原有语言理解能力的同时,将数值分类问题转化为文本分类任务。实验结果表明,该方法既能利用大模型的语义推理能力,又解决了传统方法特征提取依赖人工
以前工程师靠听诊器听异响,现在可以用加速度传感器采集振动信号,再通过信号处理提取出各种特征——比如振动的均值、峰值、频谱形状等等。这些特征就像病人的各项生理指标,然后我们训练一个分类器来根据这些指标判断机械是正常还是哪坏了。但传统方法的问题是:特征提取靠人工设计,分类器又像个黑盒子,很难利用到领域专家的先验知识。
最近大语言模型LLM火了,像ChatGLM这种模型,你给它一段描述,它能理解并回答。那如果把每个样本的特征用自然语言写成一段话,比如该振动信号时域均值是0.02,标准差是0.15,频谱重心是120Hz……,然后让LLM去做分类,岂不是既能用上预训练模型里蕴含的语义知识,又能让诊断过程变得可解释?这就是算法的核心思路:把特征向量翻译成自然语言提示,然后用LoRA高效微调ChatGLM2-6B,让大模型学会根据这些特征描述来分类故障类型。
这个算法的核心就是用自然语言把传统特征包装成提示,然后微调一个大语言模型来做分类。它绕过了复杂的特征工程和模型设计,直接让大模型理解特征描述与故障类型之间的关联。好处是:1)利用了大模型预训练时学到的语言知识和推理能力,相当于注入了领域经验;2)LoRA微调高效省显存,普通GPU也能跑;3)整个过程可解释性强——你让大模型看一段描述,它给出诊断结果,就像问一个专家一样。本质上,这是将数值分类问题转换为了文本分类问题。
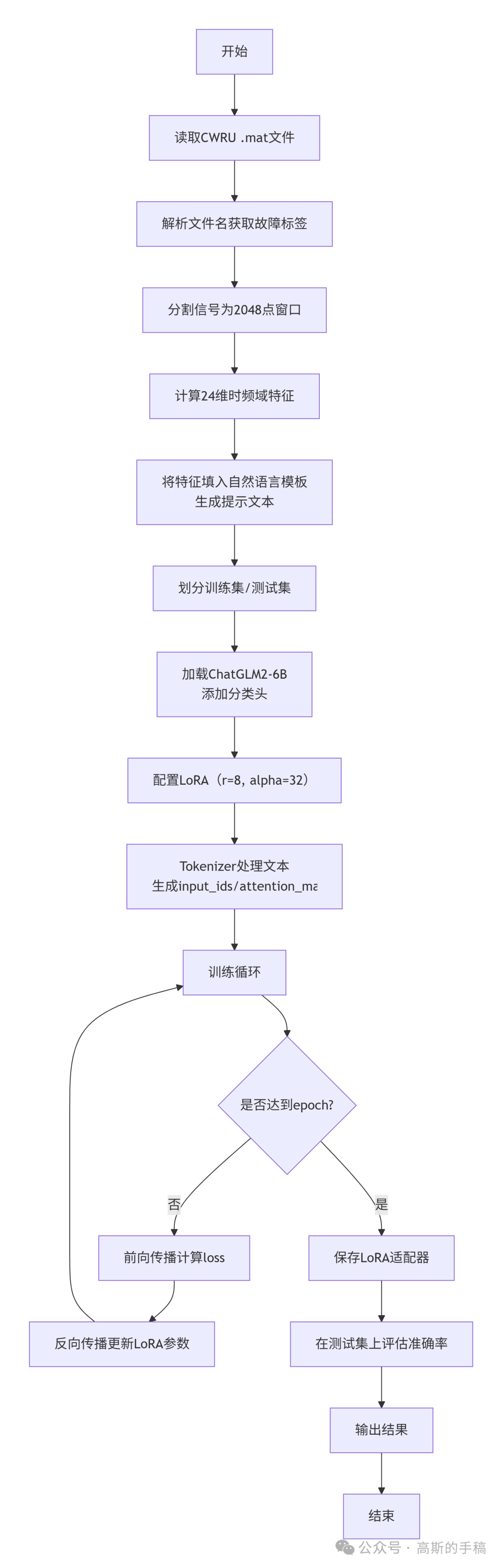
算法步骤
数据准备与预处理
从CWRU数据集读取.mat文件,提取驱动端(DE)、风扇端(FE)的振动信号,以及正常数据。
根据文件名中的字母确定故障类型(Ball、Inner race、Outer race、Normal)。
将每个信号分割成固定长度(2048点)的窗口,步长512点,得到大量样本。
特征提取(24维特征)
对每个窗口分别计算12个时域特征(均值、标准差、峰值、峭度、波形指标等)和12个频域特征(频谱均值、重心频率、谱峭度、谱偏度等)。
这24个特征从不同角度描述了振动信号的统计特性,是传统故障诊断的经典特征集。
构建自然语言提示
将每个样本的24个特征值按照固定句式填入模板,形成一段描述性文字。例如:“你是轴承故障诊断专家……时域均值为x,标准差为y……频域重心频率为z……”
这样每个样本就变成了一个包含丰富语义信息的文本,既保留了数值信息,又赋予了自然语言的可解释性。
数据集划分与编码
用LabelEncoder将故障类型转换为数值标签(0-3)。
按照8:2的比例划分训练集和测试集,并保证各类别比例一致(分层抽样)。
模型加载与LoRA微调配置
加载预训练的ChatGLM2-6B模型(支持中文和英文),并在其基础上添加分类头(4分类)。
使用LoRA技术,冻结原模型大部分参数,只在注意力层的query_key_value矩阵上添加低秩适配器,大幅减少可训练参数量(从6B降到约6M),节省显存和训练时间。
训练与评估
使用HuggingFace的Trainer API,设置训练参数(batch size=1,梯度累积8步,学习率5e-6,epoch=1)。
将文本提示通过tokenizer转换为input_ids和attention_mask,输入模型进行前向传播,计算交叉熵损失,反向传播更新LoRA参数。
在每个epoch结束后在测试集上计算准确率,保存最优模型。
结果输出
训练完成后,保存LoRA适配器权重,方便后续部署。
在测试集上评估最终模型,输出分类准确率。
# ---------- 1. 加载预训练模型和Tokenizer ----------
model_name = "hatglm2-6b"
num_classes = 4
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=num_classes,
trust_remote_code=True
)
# ---------- 2. 配置LoRA(只训练少量参数) ----------
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
task_type="SEQ_CLS",
r=8, # LoRA秩,控制参数量
lora_alpha=32, # 缩放因子
target_modules=["query_key_value"], # 在注意力层的QKV矩阵上加适配器
lora_dropout=0.1,
)
peft_model = get_peft_model(model, lora_config)
peft_model.print_trainable_parameters() # 输出可训练参数量
# ---------- 3. 构建自定义数据集,将文本转换为模型输入 ----------
class CustomDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_length=2048):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_length = max_length
def __getitem__(self, idx):
# 将文本tokenize,填充/截断到固定长度
encoding = self.tokenizer(
self.texts[idx],
truncation=True,
padding='max_length',
max_length=self.max_length,
return_tensors=None
)
return {
'input_ids': torch.tensor(encoding['input_ids'], dtype=torch.long),
'attention_mask': torch.tensor(encoding['attention_mask'], dtype=torch.long),
'labels': torch.tensor(self.labels[idx], dtype=torch.long)
}
# 创建训练集和测试集
train_dataset = CustomDataset(train_texts, y_train, tokenizer)
test_dataset = CustomDataset(test_texts, y_test, tokenizer)
# ---------- 4. 设置训练参数并启动Trainer ----------
from transformers import TrainingArguments, Trainer, DataCollatorWithPadding
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=1, # 显存有限,batch size设小
gradient_accumulation_steps=8, # 梯度累积等效于batch_size=8
num_train_epochs=1,
learning_rate=5e-6,
fp16=True, # 混合精度加速
remove_unused_columns=False, # 保留自定义列
logging_steps=10,
save_steps=50,
)
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorWithPadding(tokenizer), # 动态padding
compute_metrics=lambda p: {"accuracy": (p.predictions.argmax(-1) == p.label_ids).mean()} # 计算准确率
)
# 开始训练(如果中断过,可恢复)
trainer.train(resume_from_checkpoint=True)
# 保存LoRA权重
peft_model.save_pretrained("lora-adapters")
# 评估
eval_result = trainer.evaluate()
print(eval_result)如果你对信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测有疑问,或者需要论文思路上的建议,欢迎交流
担任《MSSP》《中国电机工程学报》《宇航学报》《控制与决策》等期刊审稿专家,擅长领域:信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)