Context Engineering彻底讲透:为什么它成为2026年构建AI Agent的最重要技能
最干净的解释是:Prompt Engineering = 如何写好单条消息给AIContext Engineering = 如何管理AI在整个任务过程中知道的所有信息想想你和朋友聊天:朋友会记得你五分钟前说过的话,从而理解你现在说的是什么意思。AI也是一样。它靠的是一个叫**Context Window(上下文窗口)**的机制——相当于AI一次能“记住”的信息总量。上下文工程,就是管理这个上下文窗
上下文工程彻底讲透:为什么它成为2026年构建AI Agent的最重要技能
这篇文章在我的草稿箱里躺了整整三周。
不是因为我对这个话题不熟悉,而是我想彻底搞懂它之后,再来好好讲给大家听。
我认真读了两篇深度技术博客,自己动手做了大量实验,还像备考一样做了详细笔记。
今天,我终于可以自信地把它分享出来了。
如果你是第一次来我这里,我平时喜欢写一些长篇技术拆解,专门讲那些大家常用却很少被真正讲清楚的AI概念。
没有废话,不抄概念,只讲我真正花时间吃透的东西。
今天要讲的就是 上下文工程(Context Engineering)。
读完这篇文章,你就会明白,为什么现在很多在认真做AI Agent的人,都把这项技能称为2026年最重要的能力。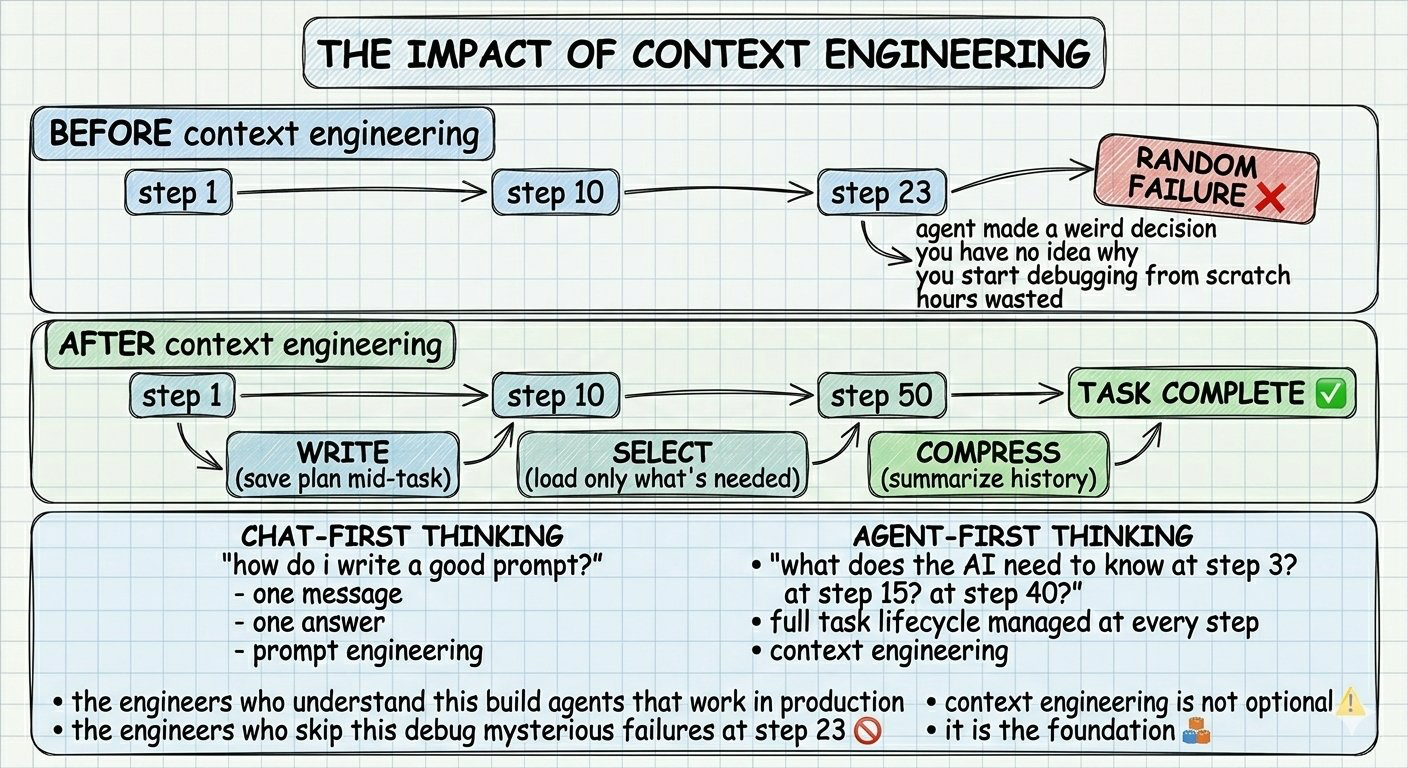
我们开始吧。
先说说大家熟悉的Prompt Engineering
相信你已经听过“提示词工程”(Prompt Engineering)这个词了。
简单来说,它就是写出更好指令来指挥AI的技巧。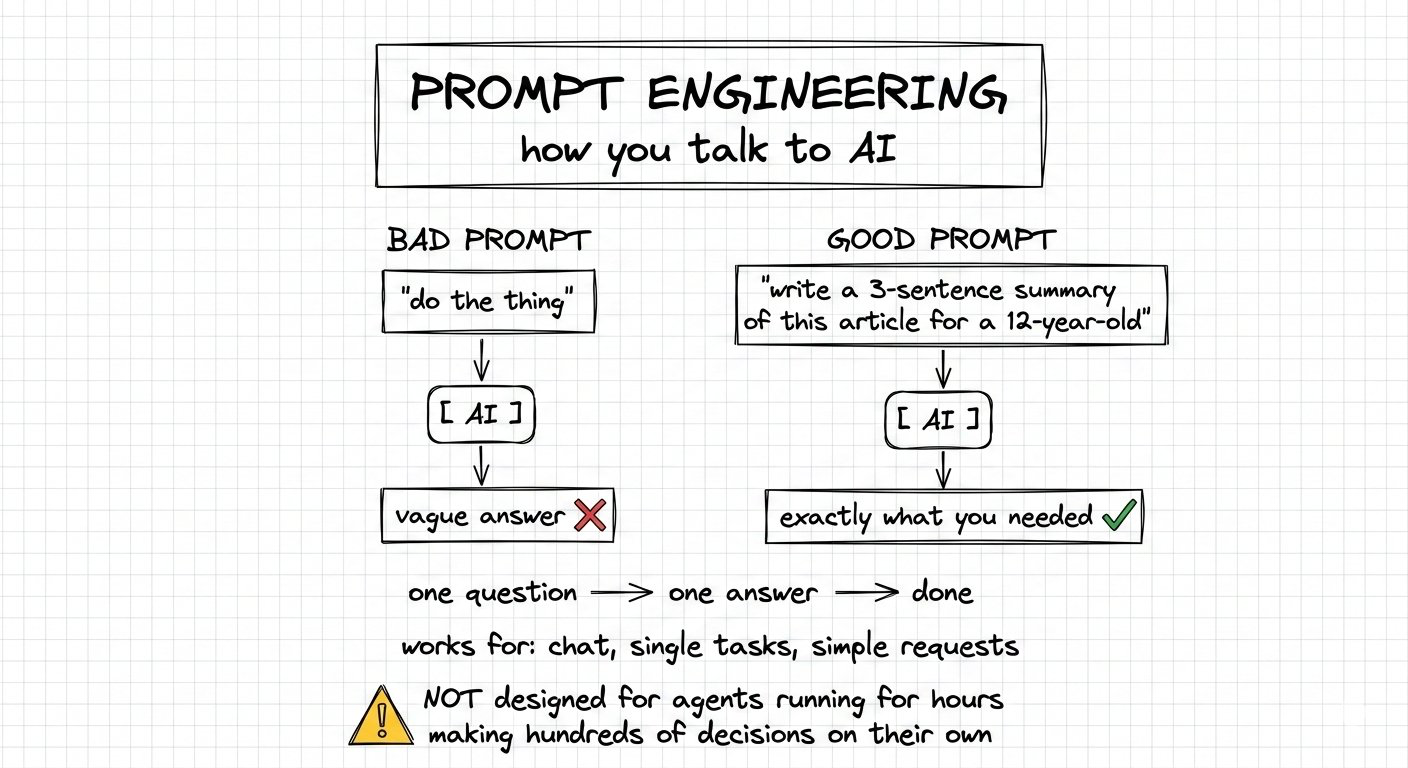
你可以把它想象成给一个超级聪明的助手发消息:
- 如果你说“帮我做件事”,AI很可能给你一个含糊的回答。
- 但如果你说“用三句话给12岁小孩总结这篇文章”,你就能得到非常精准的结果。
Prompt Engineering的核心,就是如何通过措辞来大幅提升AI的输出质量。
ChatGPT刚出来的时候,这个技能特别火。因为大家发现,同一个模型,问法不同,结果可能天差地别。
直到现在,它依然非常有用。
但问题来了:
Prompt Engineering主要适用于单次对话——问一个问题,得到一个答案,任务就结束了。
而当你开始构建那些能自主工作几十分钟甚至几个小时的**AI Agent(智能体)**时,光靠Prompt Engineering就不够了。
这时候,就需要升级到上下文工程。
什么是Context Engineering?
最干净的解释是:
Prompt Engineering = 如何写好单条消息给AI
Context Engineering = 如何管理AI在整个任务过程中知道的所有信息
想想你和朋友聊天:朋友会记得你五分钟前说过的话,从而理解你现在说的是什么意思。
AI也是一样。
它靠的是一个叫**Context Window(上下文窗口)**的机制——相当于AI一次能“记住”的信息总量。
上下文工程,就是管理这个上下文窗口的艺术和科学:决定在每一步里,应该让AI“记住”什么信息。
Andrej Karpathy(前OpenAI著名研究员)曾经专门提到过这个概念,他说:
“人们现在常用‘prompt engineering’这个词,但其实在真正工业级的LLM应用中,更准确的叫法是‘context engineering’。它是一门精细的艺术和科学——如何在每一步都给上下文窗口填入恰到好处的信息。”
另一位创业者Tobi Lutke也表示:“Context Engineering这个词更好,它准确描述了核心技能:给LLM提供足够让任务可解的全部上下文。”
这句话里的每一个词都很关键:
- 精细:给多了AI会混乱,给少了AI又抓不住重点。
- 艺术:没有万能公式,需要判断力。
- 科学:背后有系统性的方法和策略。
- 恰到好处:不是全部信息,而是当前最需要的信息。
- 下一步:不是一次性给全,而是给当前步骤需要的内容。
一个让你瞬间明白的CPU类比
大多数人理解上下文工程的关键,就是这个类比(来自Karpathy):
把AI想象成一台电脑:
- LLM(大模型) = CPU(负责思考的大脑)
- Context Window(上下文窗口) = RAM(正在工作的临时内存)
CPU虽然强大,但它一次只能处理RAM里的内容。RAM空间有限,操作系统要不断决定把什么数据加载进来,什么数据暂时放在硬盘里。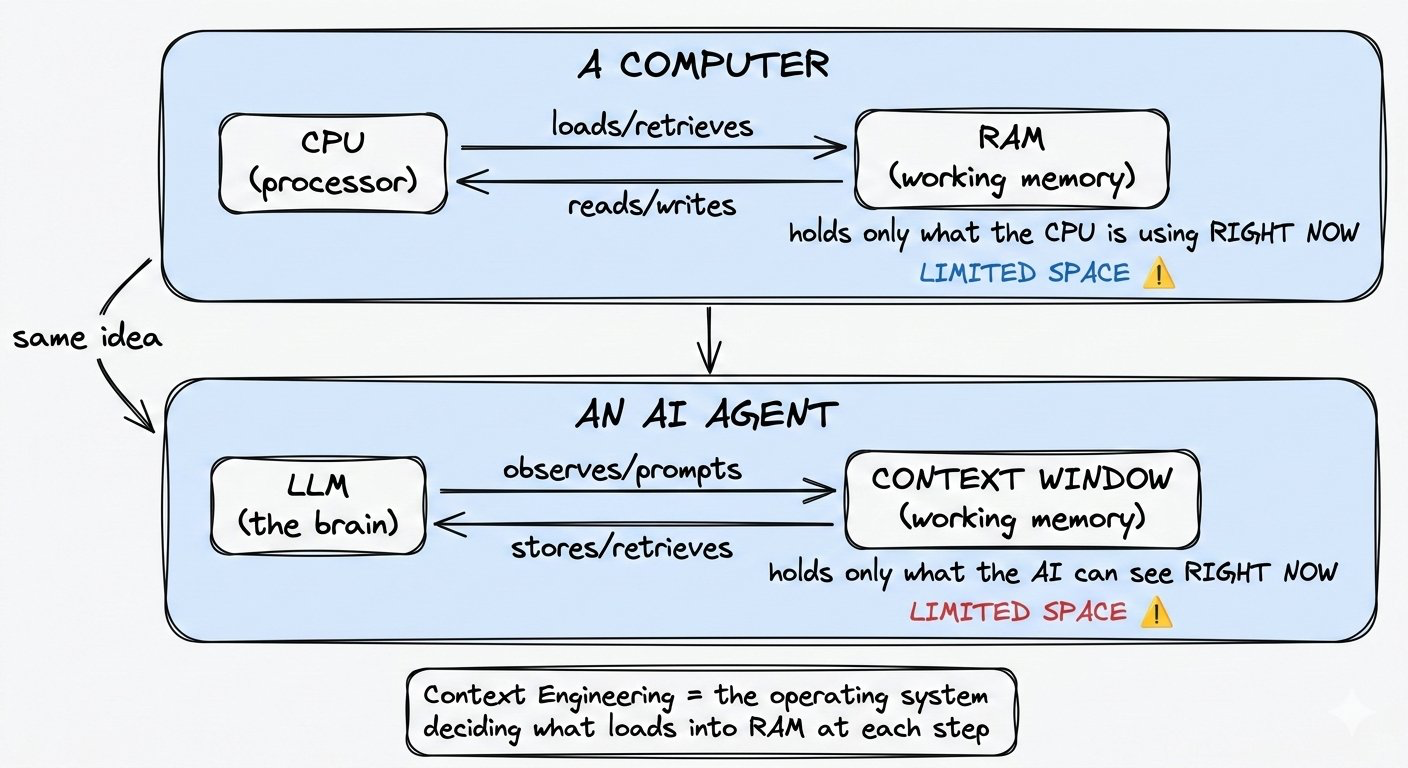
同样,AI也只能思考当前上下文窗口里的内容。窗口之外的所有信息,对它来说等于不存在。
上下文工程的本质,就是成为那个“操作系统”——在任务的每一步,精准决定应该把什么信息放进AI的“RAM”里。
理解了这个类比,后面的所有内容就都通了。
Context Window到底是什么?
简单来说,它就是AI一次能装进脑袋里的信息总量。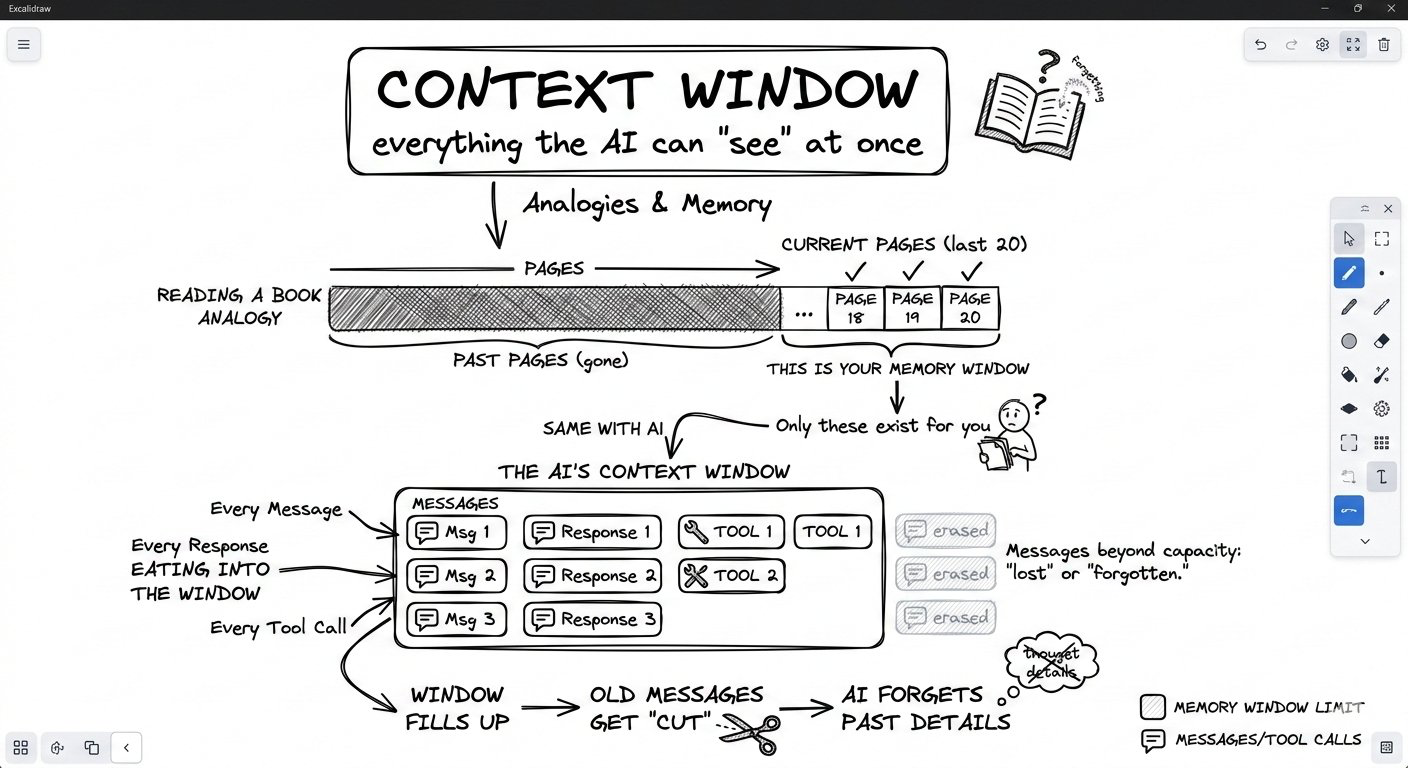
想象你在读一本书,但你只能记住最近20页的内容,20页之前的全都忘了——这就是上下文窗口的限制。
你发的每一条消息、AI的每一次回复、工具返回的每一条结果,都在不断消耗这个窗口的空间。
虽然现在模型的上下文窗口已经越来越大(有的已达几十万甚至百万token),但依然存在上限。更重要的是,即使没达到上限,塞太多无关内容也会严重影响效果。
为什么上下文工程突然成了头号技能?
过去两年,AI的使用方式发生了根本变化:
我们不再只是和AI聊天,而是开始构建能自主工作的AI Agent。
一个真正的Agent不是回答一个问题就结束,它要:
- 搜索网页
- 阅读文件
- 编写代码
- 检查自己的工作
- 自主做决策并执行下一步
这个过程可能持续几十分钟甚至几个小时。
每使用一次工具,结果就会塞回上下文窗口;每走一步,token消耗都在增加。
上下文窗口很快就满了。
而一旦管理得不好,整个Agent就会崩盘。
正因为如此,Cognition团队(Devin AI编程Agent的开发者)公开表示:
“在构建AI Agent的过程中,上下文工程实际上是工程师最重要的工作。”
不是选模型,不是搭基础设施,而是上下文管理。
模型再强,上下文管不好,Agent一样会失败。
Context Window里主要有什么?
要做好上下文工程,首先要知道窗口里通常包含三类内容:
-
Instructions(指令)
系统提示词、行为规则、工具描述、示例等。相当于给员工的第一天工作说明书。 -
Knowledge(知识)
任务所需的事实信息:上传的文档、搜索结果、之前的记忆。相当于员工桌上的研究资料。 -
Tool Feedback(工具反馈)
AI使用工具后返回的结果(搜索结果、代码执行输出等)。相当于员工打电话后记的笔记。
这三类内容在同一个有限的窗口里竞争空间。上下文工程师的工作,就是确保在正确的时间,给到正确的组合。
上下文管理不好的四大杀手
很多人以为“上下文越多越好”,这是个大误区。
实际中,糟糕的上下文管理会导致四大问题:
1. 上下文污染(Context Poisoning)
AI产生一次幻觉(比如编造了一个错误事实),这个错误就会一直留在上下文里。后面每一步都会把这个错误当成真相,越错越离谱。
2. 上下文干扰(Context Distraction)
塞了太多无关信息,AI被淹没,反而忽略了真正重要的内容。就像你让朋友帮你改一个bug,却把整个项目代码和无关日志全甩给他。
3. 上下文混淆(Context Confusion)
无关信息悄悄影响AI的判断,导致输出跑偏。AI可能会把一些本不该用的历史信息带进来。
4. 上下文冲突(Context Clash)
不同信息互相矛盾。比如系统提示要求正式语气,但注入的文档要求活泼风格,AI就会无所适从。
真正有效的四大策略
好消息是,业内已经在实践中总结出了四种核心策略:写入、选择、压缩、隔离。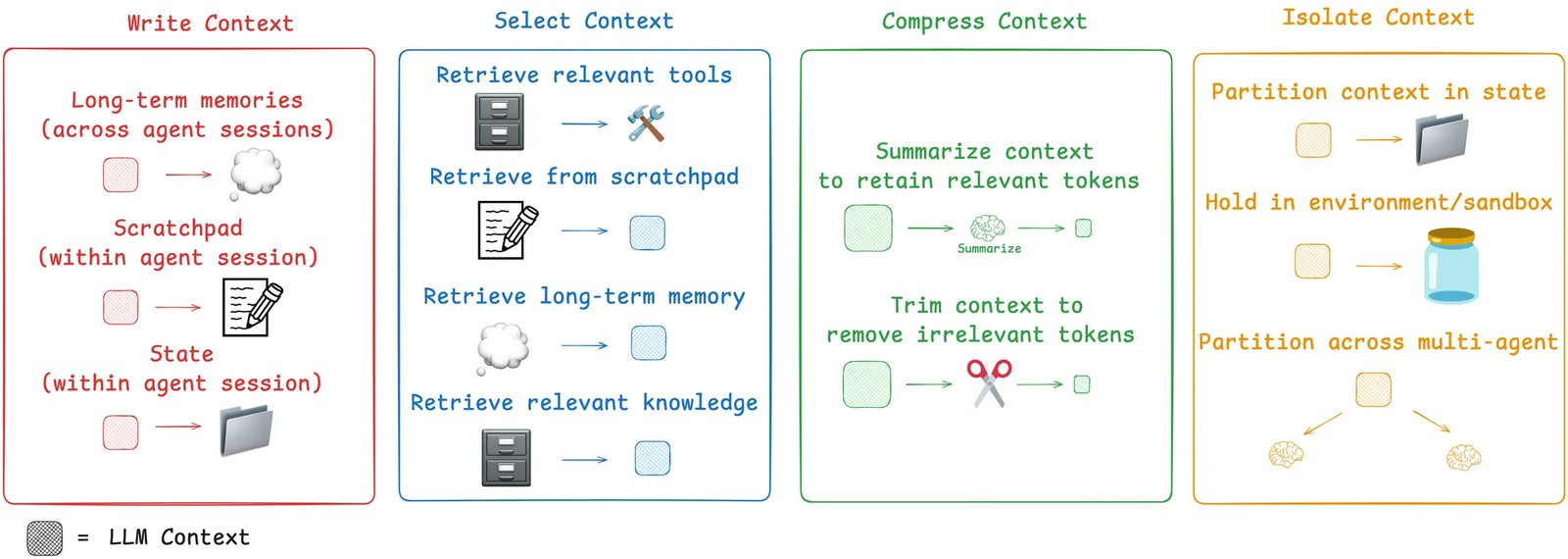
策略一:写入(Write)——把信息存到外部
- Scratchpad(草稿本):让Agent在任务中途把当前计划、关键发现写到外部存储,需要时再拉回来。Anthropic的多Agent系统就用了这个方法。
- Long-term Memory(长期记忆):跨会话记忆,比如记住用户偏好、开发环境等,自动注入新对话。
策略二:选择(Select)——精准拉取需要的内容
- 使用嵌入(embedding)和知识图谱,只把当前任务最相关的记忆或工具拉进上下文。
- 当Agent有很多工具时,用RAG只加载最相关的5个工具,而不是一次性加载50个,能显著提升工具选择准确率。
策略三:压缩(Compress)——减少体积
- Summarization(总结):对话太长时,自动把历史压缩成摘要。Claude Code的auto-compact就是典型。
- Trimming(裁剪):直接删除过期的旧消息或不再相关的搜索结果。
策略四:隔离(Isolate)——拆分上下文
- 多Agent架构:让不同Agent各自负责一部分任务,每个Agent只维护自己的专注上下文。
- Environment Sandbox(沙箱环境):让工具在独立环境中运行,只把最终结果返回给主Agent。特别适合处理大文件、图片、数据集等。
实战对比:好坏Context Engineering的区别
差的版本(纯Prompt):
“你是一个有帮助的助手,帮我做一个网页爬虫。”
好的版本(上下文工程):
角色:你是一位资深Python开发者,正在帮我开发电商价格追踪爬虫。
当前任务:
为amazon.com商品页开发爬虫,需要提取:标题、价格、评分、评论数。
当前已知信息:
- 目标网站使用JavaScript渲染
- BeautifulSoup已失败
- 当前处于项目第3步(共7步)
- 已决定使用Playwright而非Selenium
限制要求:
- 只输出爬虫代码和行内注释
- 不要解释库的作用
- 不要推荐其他方案
- 如果遇到反爬机制,请直接说明并停止
相关文件:(仅粘贴当前步骤需要的2-3个文件)
下一步计划:实现限速逻辑
你看,好的上下文工程不是把所有信息一股脑塞进去,而是在当前步骤,给AI刚好够用的精准信息。
最后想说的话
Prompt Engineering让你更好地和AI对话。
而上下文工程让你更好地用AI构建系统。
当你的Agent要连续工作30分钟、做出上百个决策时,上下文管理的好坏,直接决定它是能稳定落地,还是在第50步突然崩溃。
真正的AI工程师,已经把上下文工程当成构建生产级Agent的基础能力。
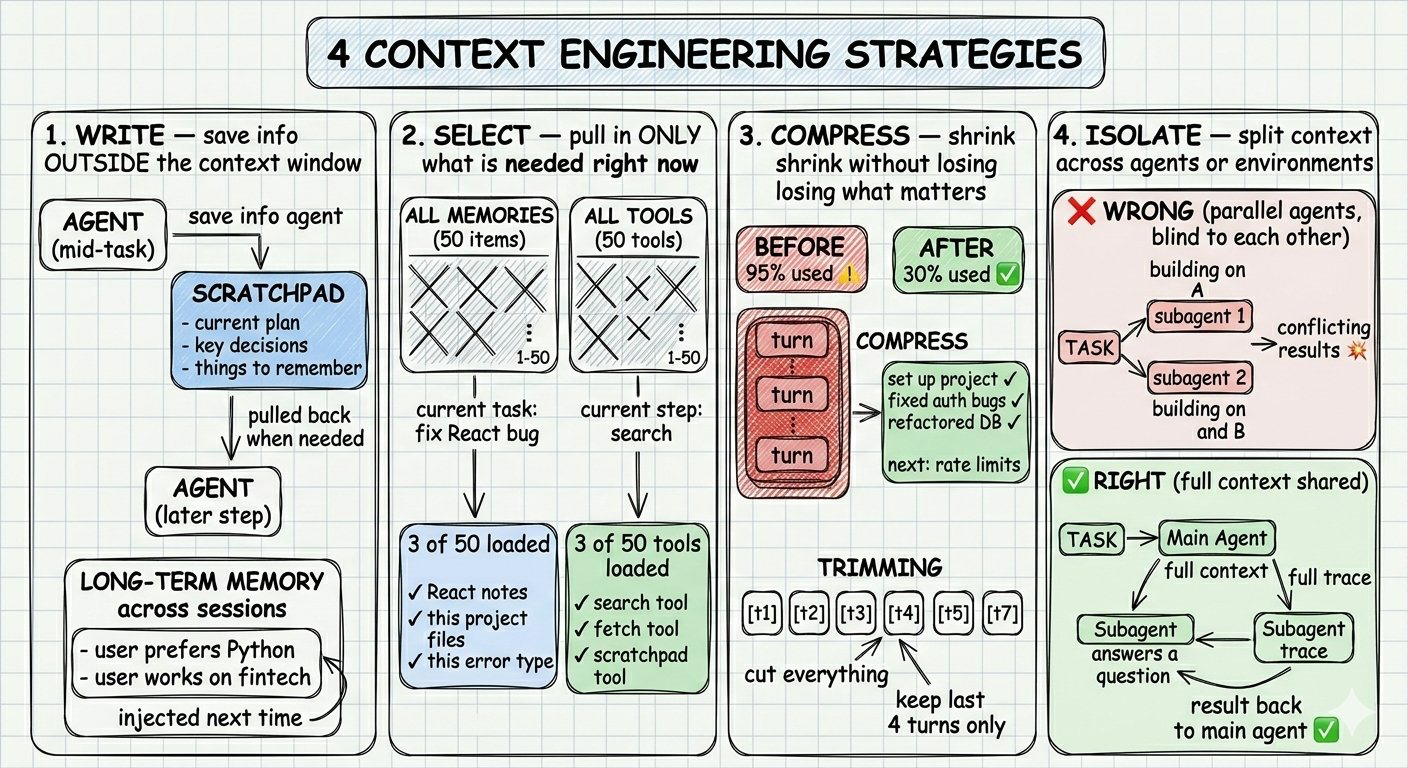
快速回顾:
- Context Window = AI的工作内存(有容量限制)
- Context Engineering = 管理这个内存每一步放什么内容的技能
- 四大问题:污染、干扰、混淆、冲突
- 四大策略:写入、选择、压缩、隔离
- 核心结论:Agent越复杂,上下文工程就越重要
如果你正在做AI Agent,建议把这篇文章转给你的队友。
我花了整整一周时间,结合LangChain和Cognition的最新研究,才把这篇内容整理出来。希望对你有帮助!
(参考资料:LangChain官方博客、Cognition团队相关论文)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)