Gemini 3.0从零到精通:超详细教程+实战指南,收藏这篇就够了!
本文全面介绍了Google Gemini3.0大模型的使用指南,涵盖基础入门到高级应用。Gemini3.0具备200万tokens上下文窗口和原生多模态能力,支持文本、图像、视频等处理。文章详细讲解了三种使用方式:网页聊天、Google AI Studio和API调用,并分享了提示词优化、思考深度控制等进阶技巧。特别针对科研场景提供了文献分析、视频解读等实用解决方案。推荐国内用户通过RskAi平台
无论你是刚接触AI的新手,还是想深度挖掘模型潜力的开发者,Gemini 3.0都值得投入时间掌握。本文将从基础入门、进阶技巧到真实科研与开发场景,为你呈现一份完整的从零到精通指南。如果你希望在国内网络环境下直接体验Gemini 3.0,可访问聚合平台RskAi(ai.rsk.cn),一站使用Gemini、GPT-4o和Claude 3.5,每日免费。
一、Gemini 3.0核心特性速览
Gemini 3.0是Google DeepMind推出的多模态大模型系列,包含三个主要版本:
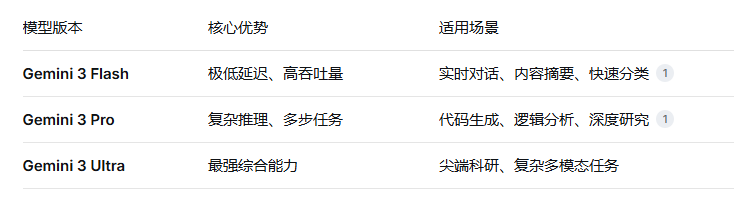
全系列支持200万tokens上下文窗口,可一次性处理数百页文档或长视频;原生多模态能力可直接“看懂”图像、视频、PDF和音频文件,无需预处理 。
二、基础入门:三种使用方式
方式一:网页聊天(零代码)
最简单的方式是直接访问官方聊天界面或国内镜像站。通过RskAi,你可以在对话框中:
-
选择“Gemini 3 Pro”模型
-
输入问题获取回答
-
上传文件让模型分析
-
开启联网搜索获取实时信息
方式二:Google AI Studio(提示词工程)
适合需要反复调试提示词的用户。访问Gemini谷歌官网,你可以:
-
选择最新Gemini 3模型
-
设置系统指令(System Instruction)固定助手风格
-
测试不同参数组合
-
将调好的提示词导出为代码
方式三:API调用(开发者)
开发者可通过API将Gemini集成到应用中。以下以Python为例:
python
import google.generativeai as genai
import os
genai.configure(api_key=os.environ["GEMINI_API_KEY"])
model = genai.GenerativeModel("gemini-3-pro-latest")
response = model.generate_content("用一句话解释量子纠缠")
print(response.text)
API密钥获取:在Google AI Studio中创建API Key,建议设置为环境变量而非硬编码 。
三、进阶技巧:从会用到精通
3.1 提示词五步模板
一位资深用户分享了高效提示词结构 :
| 要素 | 说明 | 示例 |
|---|---|---|
| 角色 | 定义AI身份 | "你是一位资深产品经理" |
| 目标 | 明确要完成的任务 | "为新产品撰写定位说明" |
| 输入 | 提供上下文数据 | "[粘贴产品资料]" |
| 约束 | 设定限制条件 | "不超过200字,避免技术术语" |
| 输出格式 | 指定返回形式 | "用三个要点呈现" |
3.2 控制思考深度
Gemini 3引入了thinking_level参数,让你能精确控制模型的推理深度 :
| 思考级别 | 适用场景 | 特点 |
|---|---|---|
| minimal | 简单查询、高吞吐量 | 极低延迟,几乎无内部思考 |
| low | 简单指令遵循 | 最小化延迟和成本 |
| medium | 大多数日常任务 | 平衡速度与推理质量 |
| high | 复杂推理、逻辑分析 | 最大化推理深度,输出更严谨 |
代码示例(Python):
python
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents="分析这段代码的性能瓶颈",
config={
"thinking_config": {"thinking_level": "high"}
}
)
3.3 多模态输入处理
Gemini 3支持直接分析图片、PDF、视频。通过media_resolution参数,你可以控制图像处理的精细程度 :
python
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents=[
"这张图表反映了什么趋势?",
{"file_data": {"mime_type": "image/png", "file_uri": "path/to/chart.png"}}
],
config={
"media_resolution": {"level": "media_resolution_high"}
}
)
对于需要读取图片中细小文字的场景,建议使用高分辨率;对于文档理解,中等分辨率通常足够 。
3.4 结构化输出与工具调用
当你需要模型返回JSON格式数据时,可以指定输出格式 :
python
class MatchResult(BaseModel):
winner: str
final_match_score: str
scorers: List[str]
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents="搜索最近一场欧冠决赛结果,以指定格式输出",
config={
"tools": [{"google_search": {}}],
"response_mime_type": "application/json",
"response_json_schema": MatchResult.model_json_schema()
}
)
3.5 专业技巧汇总
-
Few-shot示例:在提问前粘贴1-2个"黄金标准"示例,能大幅提升输出质量
-
温度控制:低温度(0.2-0.4)适合精准任务,高温度(0.7-0.9)适合创意生成
-
分阶段处理:将复杂任务拆解为"研究→提纲→草稿→润色"多步,避免一次过载
-
设置质量基准:告诉模型"如果置信度低,先问两个澄清问题",能减少返工
四、实战指南:科研场景深度应用
场景一:海量文献并行分析
痛点:做元分析或综述时,面对几百篇PDF,整理归类耗时数周。
解决方案:利用Gemini 3的200万tokens上下文窗口,分批上传文献全文,执行跨文档分析 。
实测案例:某研究团队收集327篇关于"ESG评级与企业财务绩效"的英文论文,分三十多批上传后,指令模型:
"你已经阅读了所有文献。请:1. 归纳5个最常用财务绩效指标及使用频率 2. 找出结论存在分歧的子领域 3. 绘制关键理论演进时间线"
约10分钟后,模型输出结构化报告,精准捕捉到"欧美市场vs新兴市场"的核心分歧点,并指出研究空白区 。
实用提示词模板 :
text
我已上传了[N]篇关于[研究领域]的文献。请阅读所有文档,并执行: 1. 总结主流3-5种研究方法或理论框架 2. 找出核心结论、数据解读上的矛盾点,指明是哪几篇文献冲突 3. 生成包含“研究背景-主流方法-关键争议-未来展望”的综述报告草稿
场景二:视频与图像数据解读
痛点:定性研究中,数小时的访谈录像整理编码极其耗时。
解决方案:直接上传视频,让模型识别语言内容、语气、面部表情和肢体动作 。
实测案例:上传30分钟消费者小组讨论视频,指令:
"请以定性研究员身份分析:1. 参与者表达明确喜欢/不喜欢的产品特征及时间点 2. 出现明显非语言信号的时刻 3. 意见领袖的出现及影响"
模型返回带时间戳的行为日志,识别出"口头接受但肢体语言防御"等细微信号,相当于完成第一轮粗编码 。
实用提示词 :
text
请观看这段[时长]的[实验对象]录像,充当行为学研究员: 1. 记录[特定行为A]的所有起始时间戳和持续时间 2. 统计对象在前半段和后半段进入[特定区域]的次数和总时长 3. 描述整体活动水平随时间的变化趋势
场景三:科学图表深度解读
痛点:论文中的复杂图表(光谱图、K线图等)需要专业知识解读。
解决方案:Gemini 3能结合图表类型和学科常识进行"解读",而非简单OCR 。
实测案例:输入包含股价K线、均线和MACD指标的技术分析图,指令:
"请作为金融分析师解读这张技术分析图,描述图表形态,结合指标给出趋势判断"
模型回复指出"量价背离"现象、MACD即将形成"死叉",并给出"短期回调风险增加"的专业判断,达到入门级分析师水平 。
实用提示词 :
text
附件是一张[图表类型,如:X射线衍射图谱]。请作为[学科]专家: 1. 识别图中主要的特征峰位置和强度 2. 与标准图谱对比,判断可能的物相组成 3. 指出任何异常特征及其可能原因
五、常见问题解答
Q1:Gemini 3免费吗?国内怎么用?
Google官方提供免费额度,但国内直接访问可能不稳定。推荐使用国内镜像聚合站RskAi(ai.rsk.cn),国内网络可直接访问,每日免费使用Gemini 3 Pro、GPT-4o和Claude 3.5三大模型,支持文件上传和联网搜索,实测响应速度约1.2秒。
Q2:Flash和Pro怎么选?
-
Flash:适合高频调用、实时应用,如聊天机器人、快速分类
-
Pro:适合复杂推理、代码生成、深度研究,质量更高但延迟稍长
-
建议在应用中保留配置开关,可随时切换
Q3:如何处理API调用报错?
-
401:API Key错误或未设置,检查环境变量
-
429:请求超限,添加指数退避重试,控制并发
-
400安全拦截:提示词触发了安全过滤,重新表述或缩小任务范围
-
长文本超限:将大文件分块处理,采用"分块摘要→最终合成"的map-reduce模式
Q4:如何控制成本?
-
优先使用Flash模型处理日常任务
-
设置
maxOutputTokens限制输出长度 -
缓存常用提示词和回复,避免重复调用
-
记录每次请求的token消耗,量化优化
Q5:Gemini 3的中文能力如何?
实测显示,Gemini 3在中文内容创作、技术文档翻译、跨文化商业沟通等方面表现出色,语言流畅自然,对中文修辞和商业文化有深度理解 。
六、总结:从入门到精通的成长路径
-
第一阶段(新手):从网页聊天开始,熟悉基础对话和文件上传功能
-
第二阶段(进阶):学习提示词工程,掌握角色设定、输出格式控制
-
第三阶段(专家):深入API调用,掌握思考级别控制、多模态处理、工具调用
-
第四阶段(实战):将Gemini应用到具体工作流,如文献分析、视频研究、图表解读
Gemini 3.0的价值不在于单个功能有多强,而在于你能否将它无缝融入自己的工作流。希望这份指南能帮你少走弯路,更快地从"会用"走向"精通"。如果你希望在国内网络环境下直接体验,RskAi(ai.rsk.cn) 是一个不错的起点。现在就打开一个对话窗口,开始你的第一个实战任务吧!
【本文完】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)