[论文阅读] AI +软件工程 | 无需执行代码,LLM也能精准分析代码语义?Meta提出半形式化推理新方法
本文研究了LLM智能体的**Agentic Code Reasoning(智能体代码推理)** 能力——即无需执行代码,通过迭代探索代码库、追踪依赖完成深度语义分析的能力,并提出**半形式化推理**这一结构化提示方法。该方法通过任务定制化模板,强制智能体明确陈述前提、追踪执行路径、推导形式化结论,避免无依据断言。在补丁等价验证、故障定位、代码问答三大任务中的评估表明,半形式化推理实现了全面的精度提
无需执行代码,LLM也能精准分析代码语义?Meta提出半形式化推理新方法
论文信息
- 论文原标题:Agentic Code Reasoning
- 主要作者及研究机构:Shubham Ugare, Satish Chandra(Meta, USA)
- 发表信息:arXiv:2603.01896v1 [cs.SE], 2026
- GB/T 7714引文格式:UGARE S, CHANDRA S. Agentic Code Reasoning[EB/OL]. [2026-03-02]. https://arxiv.org/abs/2603.01896v1.
研究背景:代码分析的「两难困境」,LLM也踩坑
在AI赋能软件工程的时代,让大语言模型(LLM)成为「智能代码分析师」是行业刚需——不管是验证代码补丁是否有效、定位程序中的bug,还是解答复杂的代码语义问题,都需要LLM能精准理解代码逻辑。但**「不执行代码就无法准确分析」** 成了横亘在面前的核心难题,而现有解决方案又陷入了「两难困境」:
困境1:非结构化推理靠「猜」,结论缺乏依据
现有LLM代码分析方法多采用无约束的自然语言推理(比如思维链),模型常常凭表面特征下结论,跳过关键的代码路径追踪和证据验证。比如在Django的一个年份格式化补丁验证中,模型想当然认为format()是Python内置函数,却忽略了项目中自定义的同名函数会导致代码报错,最终错误判定两个补丁等价。这种「想当然」的推理,让代码分析的准确性大打折扣。
困境2:纯形式化验证太「繁」,实操性极低
另一种思路是纯形式化验证,将代码和推理转化为Lean、Coq等形式化语言,实现自动化的严谨证明。但这种方法需要为不同编程语言、不同框架定义复杂的语义规则,对于真实项目中跨文件、跨框架的代码,几乎无法落地——就像让普通人用专业数学公式描述日常购物流程,繁琐且不切实际。
行业刚需:无执行的代码语义分析
在实际的软件工程中,执行代码进行验证往往需要搭建专属沙箱、配置依赖环境,耗时耗力;而在RL训练、自动化代码审查等场景中,更需要**「无需执行代码,快速完成精准分析」** 的能力。如何在「推理严谨性」和「实操便捷性」之间找到平衡,成了LLM代码分析领域的关键问题。
一段话总结
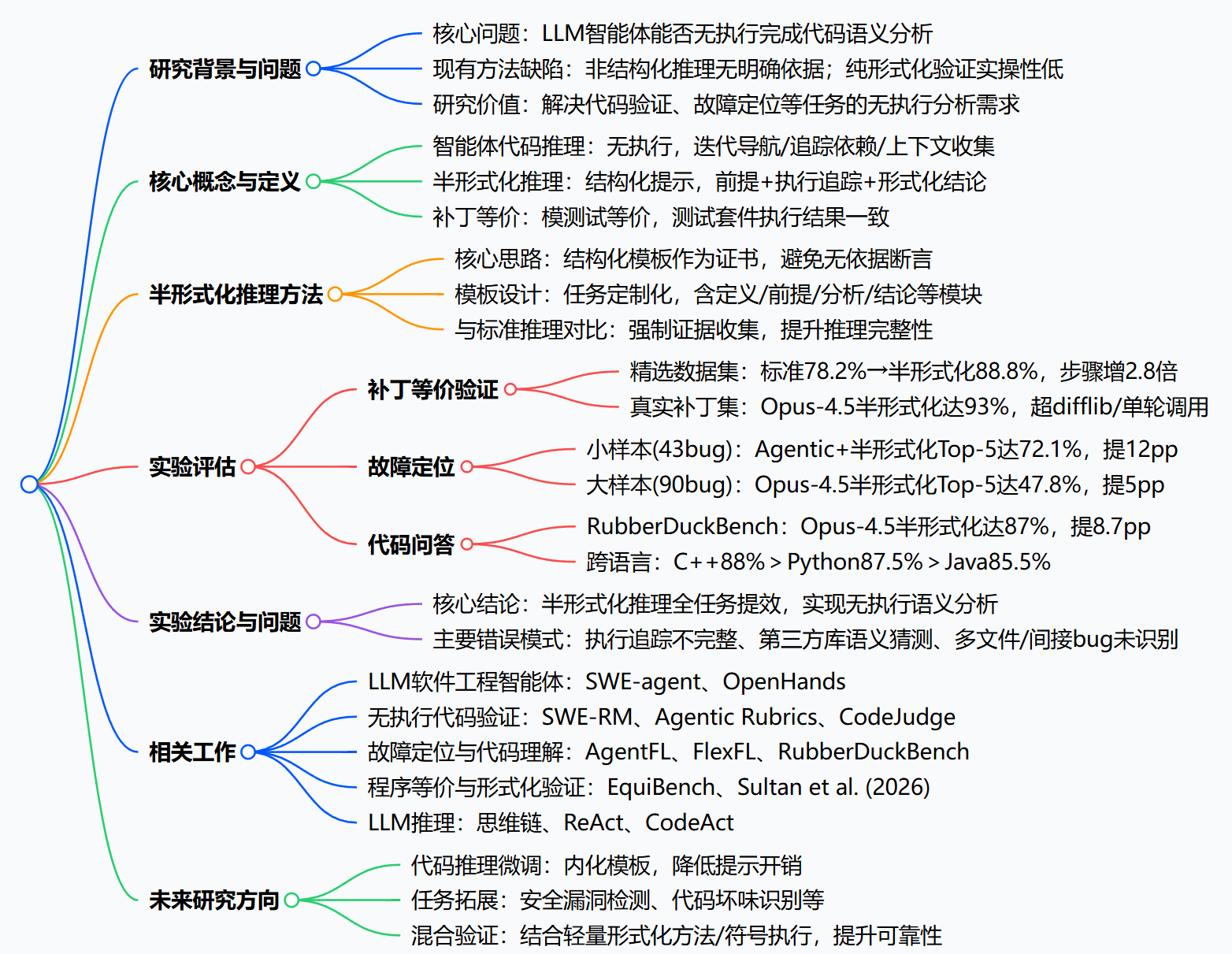
Meta的研究者提出智能体代码推理(agentic code reasoning) 能力,探索LLM智能体无需执行代码即可完成代码库语义分析的可能性,并设计了半形式化推理(semi-formal reasoning) 这一结构化提示方法,要求智能体明确陈述前提、追踪执行路径并推导形式化结论,解决了非结构化推理缺乏依据、纯形式化验证实操性低的问题。该方法在补丁等价验证、故障定位、代码问答三大任务中均实现精度提升,补丁等价验证在人工精选案例上精度从78%提升至88%,真实智能体生成补丁上达93%,RubberDuckBench代码问答精度达87%,Defects4J故障定位Top-5精度最高提升12个百分点,证明了结构化推理能实现无执行的有效语义代码分析,为RL训练、代码审查、静态程序分析提供了实用方案,同时也指出了模型仍存在执行追踪不完整、第三方库语义猜测等问题,并提出了微调、拓展任务、混合验证等未来研究方向。
思维导图
详细总结
本文由Meta的研究者完成,聚焦LLM智能体的智能体代码推理能力,提出半形式化推理结构化提示方法,通过三大代码分析任务验证其有效性,证明了无执行代码语义分析的可行性,为软件工程领域的LLM应用提供了新方案。
一、研究背景与核心问题
- 研究核心:探索LLM智能体无需执行代码即可导航代码库、追踪依赖、完成深度语义分析的智能体代码推理能力,该能力是bug检测、代码审查、补丁验证的关键。
- 现有方法的两大痛点:
- 非结构化推理(如SWE-RM、Agentic Rubrics):模型可做出无明确依据的代码行为断言,推理不严谨;
- 纯形式化验证(如Lean、Coq):需将代码转化为形式化语言,对多框架/多语言的任意仓库代码实操性极低。
- 研究缺口:LLM能预测程序属性但难以提供有效证明,且现有方法多为任务专用,需单独设计架构。
二、核心概念与方法设计
- 关键定义
- 智能体代码推理:LLM智能体在不执行代码的前提下,迭代导航文件、追踪依赖、收集上下文,完成代码深度语义分析的能力;
- 补丁等价(模测试):两个补丁在仓库测试套件(F2P+P2P)中执行的通过/失败结果完全一致,为补丁验证提供可落地的评判标准;
- F2P/P2P测试:F2P(Fail-to-Pass)是补丁修复后从失败变通过的测试,P2P(Pass-to-Pass)是补丁修复后需保持通过的回归测试。
- 半形式化推理:作为连接非结构化与纯形式化推理的通用方法,核心是任务定制化的结构化提示模板,要求智能体必须明确陈述前提、追踪代码执行路径、推导形式化结论,模板充当「证书」避免模型跳过案例或做出无依据断言。
- 与标准推理的对比:标准推理仅要求模型给出自然语言推理和二元结论,易出现猜测;半形式化推理强制证据收集,推动跨过程推理,需追踪函数调用而非猜测行为。
- 核心模板结构:所有任务模板均包含定义、前提、分析、结论核心模块,补丁等价验证还需增加测试行为分析、反例/无反例说明,故障定位需增加测试语义分析、代码路径追踪、分歧分析,代码问答需增加函数追踪表、数据流分析。
三、实验设置
- 评估任务:选取三大典型代码语义分析任务,覆盖验证、故障查找、语义理解:补丁等价验证、故障定位(Defects4J)、代码问答(RubberDuckBench);
- 实验模型:主要使用Opus-4.5,辅以Sonnet-4.5做对比;
- 智能体设置:基于SWE-agent,支持bash工具探索代码库,最大步骤100,禁止执行仓库代码/测试套件、禁止使用Git命令,仅可运行独立Python脚本探索语言通用行为;
- 评估指标:补丁等价验证用整体精度,故障定位用Top-N精度(所有真实bug行出现在前N个预测中的比例),代码问答用LLM评分精度(Gemini-3-Pro+GPT-5.2按专家评分标准加权评估)。
四、三大任务实验结果
所有实验均显示半形式化推理相比标准推理实现精度提升,部分场景结合Agentic探索(迭代代码库探索) 后效果更佳,核心结果如下表:
| 评估任务 | 数据集/规模 | 模型 | 推理模式 | 核心指标 | 对比提升 |
|---|---|---|---|---|---|
| 补丁等价验证 | 人工精选170例 | Opus-4.5 | 标准推理 | 78.2%整体精度 | - |
| 补丁等价验证 | 人工精选170例 | Opus-4.5 | 半形式化推理 | 88.8%整体精度 | 10.6pp,非等价82.9%/等价93.0% |
| 补丁等价验证 | 真实智能体生成200例 | Opus-4.5 | Agentic+半形式化 | 93.0%整体精度 | 超difflib(73%)20pp,超单轮调用(86%)7pp |
| 故障定位 | Defects4J小样本43例 | Opus-4.5 | Agentic+标准 | 60.5% Top-5精度 | - |
| 故障定位 | Defects4J小样本43例 | Opus-4.5 | Agentic+半形式化 | 72.1% Top-5精度 | 12pp |
| 故障定位 | Defects4J大样本90例 | Opus-4.5 | Agentic+标准 | 43.3% Top-5精度 | - |
| 故障定位 | Defects4J大样本90例 | Opus-4.5 | Agentic+半形式化 | 47.8% Top-5精度 | 5pp |
| 代码问答 | RubberDuckBench15题 | Opus-4.5 | Agentic+标准 | 78.3%精度 | - |
| 代码问答 | RubberDuckBench15题 | Opus-4.5 | Agentic+半形式化 | 87.0%精度 | 8.7pp |
| 代码问答 | RubberDuckBench跨语言 | Opus-4.5 | 半形式化 | C++88.0%/Python87.5%/Java85.5% | Java因框架语义最具挑战性 |
- 实验附加发现:
- 半形式化推理提升精度的代价是步骤增加,如精选补丁集平均步骤从10.08增至28.17(2.8倍);
- Sonnet-4.5在代码问答中基础精度已较高(84.2%),半形式化推理无明显提升,说明结构化推理的收益随模型基础能力提升可能趋于饱和。
五、错误模式分析
三大任务中,Opus-4.5采用半形式化推理仍存在典型错误,核心分为以下类别:
- 补丁等价验证:执行追踪不完整、第三方库语义猜测、忽视细微语义差异对测试结果的影响;
- 故障定位:间接bug(测试未直接调用的类中存在bug)、多文件bug(跨文件bug未识别全部位置)、领域专用bug(如数值分析问题超出模型专业知识)、真实bug行超5个导致指标统计失败;
- 代码问答:推理链详尽但遗漏下游代码路径、对函数名的惯性猜测(未验证实际实现)。
六、相关工作
本文研究关联软件工程与LLM推理两大领域的前沿工作,核心分类包括:
- LLM软件工程智能体:SWE-agent、OpenHands、Agentless;
- 无执行代码验证:SWE-RM、Agentic Rubrics、CodeJudge;
- 故障定位与代码理解:AgentFL、FlexFL、RubberDuckBench;
- 程序等价与形式化验证:EquiBench、Sultan et al. (2026)、Sistla et al. (2025);
- LLM推理方法:思维链(CoT)、ReAct、CodeAct;
- SWE智能体训练:SWE-Gym、R2E-Gym、SWE-RL。
七、研究结论与未来方向
- 核心结论
- 半形式化推理在补丁等价验证、故障定位、代码问答三大任务中均实现5-12个百分点的精度提升,是提升智能体代码推理能力的通用方法;
- LLM智能体可通过结构化推理实现无执行的有效语义代码分析,能为RL训练管道提供无执行反馈,降低沙箱执行的计算成本;
- 半形式化推理是经典静态程序分析的灵活替代方案,无需为不同任务编码专用算法,可通过定制模板跨语言/框架推广。
- 未来研究方向
- 代码推理专用微调:对LLM进行微调,使其内化半形式化模板结构,提升精度并降低提示开销;
- 任务拓展:将半形式化推理应用于安全漏洞检测、代码坏味识别、API误用检测等其他静态分析任务;
- 混合验证:结合LLM推理与轻量形式化方法/符号执行,在保持灵活性的同时提升验证的可靠性。
关键问题
问题1:半形式化推理相比传统的非结构化推理和纯形式化验证,核心优势是什么?
答案:半形式化推理弥补了非结构化推理和纯形式化验证的双重缺陷,核心优势有三:1. 相比非结构化推理,通过任务定制化的结构化模板强制智能体明确陈述前提、追踪执行路径、提供形式化结论,避免无依据断言和跳过案例,提升推理的严谨性和完整性;2. 相比纯形式化验证,无需将任意仓库代码转化为Lean/Coq等形式化语言,无需形式化语言语义,降低了实操门槛,适用于多框架、多语言的真实代码库;3. 具备通用性,无需为不同代码分析任务设计单独的架构或训练专用模型,仅需定制模板即可适配补丁验证、故障定位、代码问答等不同任务。
问题2:半形式化推理在补丁等价验证任务中达到93%的高精度,该结果的实验条件和实际价值是什么?
答案:实验条件:1. 数据集为200例真实智能体生成的补丁,均衡分布正确/错误补丁(各100例);2. 模型为Opus-4.5,采用Agentic+半形式化推理模式,可探索完整代码库,且能访问F2P测试补丁、参考黄金补丁、全量P2P测试;3. 以实际测试执行结果为真实标签,验证补丁是否与参考黄金补丁模测试等价。实际价值:93%的高精度证明该方法可实现无执行的补丁等价验证,能为RL训练管道提供低成本的执行无关反馈,避免了为每个仓库搭建沙箱、运行CI系统的高昂计算和环境配置开销,是实现自动化补丁验证的关键突破。
问题3:Agentic探索(迭代代码库探索)与半形式化推理结合,为何能在故障定位任务中实现更显著的精度提升?
答案:原因主要有两点:1. 故障定位的核心难点是在大代码库中定位bug根因,而非仅识别崩溃位点,Agentic探索允许智能体迭代导航、读取相关文件、追踪函数调用依赖,突破了单轮推理的上下文限制,能获取崩溃位点之外的根因代码信息;2. 半形式化推理的结构化模板强制智能体完成测试语义分析、代码路径全追踪、分歧分析、假设验证的完整流程,避免了标准推理中仅根据测试代码或崩溃位点做表面猜测的问题,而Agentic探索为这一流程提供了足够的代码上下文和证据,二者形成互补;3. 半形式化推理的模板要求智能体基于证据形成假设并更新,Agentic探索的迭代特性恰好支持这一过程,能逐步排除错误假设、定位真实bug根因,因此在小样本Defects4J实验中实现了12个百分点的Top-5精度提升,远高于单轮推理的提升幅度。
创新点:三大核心突破,填补推理与形式化的空白
Meta的这项研究首次提出Agentic Code Reasoning(智能体代码推理) 概念,并设计了半形式化推理(Semi-formal Reasoning) 方法,一举解决了上述难题,核心创新点有三:
- 定义全新能力维度:明确智能体代码推理是LLM在不执行代码的前提下,迭代导航代码库、追踪依赖、收集上下文,完成深度语义分析的能力,为该领域的研究划定了清晰的边界。
- 桥接两大推理极端:半形式化推理既摒弃了非结构化推理的「无约束猜测」,又避开了纯形式化验证的「高语义成本」,用自然语言+结构化模板的方式,让模型在保持推理灵活性的同时,必须提供可验证的证据。
- 通用化任务适配:设计任务定制化的结构化证书模板,无需为不同代码分析任务训练专用模型,仅通过调整模板即可适配补丁等价验证、故障定位、代码问答等多种场景,实现了「一套方法,多任务通用」。
研究方法:从模板到实验,拆解半形式化推理的完整流程
整个研究围绕「设计半形式化推理模板→搭建实验环境→在三大核心任务中验证效果」展开,把复杂的代码分析方法论拆解为可落地的步骤,核心分为方法设计和实验验证两部分。
第一步:核心方法——半形式化推理的「结构化证书模板」
半形式化推理的核心是给LLM设定「推理规则」:通过结构化模板,强制模型必须完成「定义→前提→分析→结论」的完整推理流程,且每一步都需要提供从代码库中获取的明确证据,模板如同「推理证书」,不允许模型跳过案例、做出无依据的断言。
模板设计原则
- 「任务定制化」:为补丁等价验证、故障定位、代码问答设计不同的模板模块,但核心逻辑一致;
- 「证据可验证」:所有结论必须追溯到具体的代码行、函数调用或执行路径;
- 「自然语言友好」:全程使用自然语言,无需掌握形式化语言,降低实操门槛。
三大核心任务的模板核心模块
| 任务类型 | 核心模板模块 |
|---|---|
| 补丁等价验证 | 定义(模测试等价)→前提(补丁修改内容)→测试行为分析(逐用例追踪执行)→反例/无反例→形式化结论 |
| 故障定位 | 测试语义分析(明确测试预期)→代码路径追踪(函数调用链)→分歧分析(代码与预期的矛盾)→排名预测 |
| 代码问答 | 函数追踪表(文件+行号+行为)→数据流分析(变量生命周期)→语义属性→反假设验证→最终答案 |
第二步:实验基础——统一的智能体与任务设置
为了公平验证半形式化推理的效果,研究搭建了标准化的实验环境,确保所有对比实验在同一基准下进行:
- 智能体设置:基于SWE-agent搭建无执行代码分析智能体,支持bash工具探索代码库(导航、搜索、读取文件),但禁止执行仓库代码/测试套件、禁止使用Git命令,仅可运行独立脚本探索语言通用行为;
- 实验模型:以Opus-4.5为主,Sonnet-4.5为辅,对比不同模型在半形式化推理下的表现;
- 三大评估任务:选取覆盖「验证、排错、理解」的核心代码分析任务,均采用行业公认的基准数据集:
- 补丁等价验证:SWE-bench-Verified(精选170例+真实200例);
- 故障定位:Defects4J(Java真实bug,小样本43例+大样本90例);
- 代码问答:RubberDuckBench(Python/Java/C++,15个语义问题);
- 对比基线:每个任务均对比「标准推理(无结构约束)」和「半形式化推理」,同时加入单轮调用、difflib(纯文本相似度)等传统方法作为参考。
第三步:实验执行——逐任务精准评估,聚焦「准确性」与「推理过程」
研究对每个任务的评估重点各有不同:补丁等价验证关注整体精度,故障定位关注Top-N精度(bug根因是否出现在前N个预测中),代码问答则通过双LLM(Gemini-3-Pro+GPT-5.2)按专家评分标准评估答案精准度,同时分析模型的推理步骤,定位错误原因。
主要成果和贡献:全任务精度提升,实现无执行代码分析的实用化
这项研究的核心成果可以用一句话概括:半形式化推理让LLM在不执行代码的情况下,实现了高精度的代码语义分析,且在三大核心任务中均实现显著精度提升,部分场景达到工业级实用水平。具体成果和领域贡献如下:
一、核心实验成果:三大任务精度全面跃升(核心数据汇总)
| 评估任务 | 数据集/规模 | 模型 | 推理模式 | 核心指标 | 相比标准推理提升 |
|---|---|---|---|---|---|
| 补丁等价验证 | 精选170例 | Opus-4.5 | 半形式化推理 | 88.8%整体精度 | 10.6个百分点 |
| 补丁等价验证 | 真实智能体生成200例 | Opus-4.5 | 智能体+半形式化 | 93.0%整体精度 | 6.0个百分点(超智能体标准推理),20个百分点(超difflib) |
| 故障定位 | Defects4J小样本43例 | Opus-4.5 | 智能体+半形式化 | 72.1% Top-5精度 | 12.0个百分点 |
| 故障定位 | Defects4J大样本90例 | Opus-4.5 | 智能体+半形式化 | 47.8% Top-5精度 | 5.0个百分点 |
| 代码问答 | RubberDuckBench15题 | Opus-4.5 | 智能体+半形式化 | 87.0%精度 | 8.7个百分点 |
| 代码问答 | 跨语言对比 | Opus-4.5 | 半形式化推理 | C++88%/Python87.5%/Java85.5% | - |
关键发现:
- 半形式化推理的精度提升具有普适性,在所有任务中均实现5-12个百分点的提升,且在真实场景的补丁验证中达到93%的高精度,满足工业级使用需求;
- 智能体探索+半形式化推理是最优组合:迭代的代码库探索为推理提供完整上下文,结构化模板保证推理严谨性,二者结合实现1+1>2的效果;
- 模型能力与结构化推理的收益成反比:基础能力较强的Sonnet-4.5在代码问答中已达到84.2%精度,半形式化推理的收益趋于饱和,而Opus-4.5的收益更显著。
二、错误模式分析:明确改进方向,为后续研究铺路
研究并非只关注精度,还深入分析了半形式化推理下模型的错误类型,为该领域的后续研究指明了方向:
- 补丁等价验证:主要错误为执行追踪不完整、猜测第三方库语义、忽视细微语义差异对测试的影响;
- 故障定位:主要错误为漏检间接bug(测试未直接调用的类)、跨文件bug、领域专用算法bug(如数值分析);
- 代码问答:主要错误为推理链详尽但遗漏下游代码路径,导致「自信的错误答案」。
三、对软件工程与LLM领域的核心贡献
- 实现无执行代码分析的实用化:93%的真实补丁验证精度,让LLM可以作为RL训练的无执行奖励信号,避免了搭建沙箱、执行代码的高昂成本,大幅提升自动化代码训练的效率;
- 提供静态程序分析的新范式:相比传统静态分析工具需要为不同任务编码专用算法,半形式化推理通过任务定制化模板实现跨语言、跨框架的通用分析,灵活性远超传统工具;
- 提升LLM代码推理的可解释性:结构化模板让LLM的代码分析过程从「黑箱」变为「白箱」,每一步结论都有明确的代码证据支撑,便于人类审查和验证;
- 定义并验证了智能体代码推理能力:首次为「LLM无执行代码分析」划定了能力边界和评估标准,为该领域的后续研究提供了统一的基准和思路。
总结
Meta的这项《Agentic Code Reasoning》研究,核心解决了**「LLM如何在不执行代码的情况下,实现严谨、高效的代码语义分析」** 这一行业关键问题。研究首次提出智能体代码推理概念,并设计了半形式化推理方法,通过自然语言+结构化证书模板,桥接了非结构化推理的「不严谨」和纯形式化验证的「低实用」两大问题。
实验结果表明,半形式化推理在补丁等价验证、故障定位、代码问答三大核心代码分析任务中均实现5-12个百分点的精度提升,在真实智能体生成补丁的验证中达到93%的高精度,实现了无执行代码分析的工业级实用化。该方法不仅为RL训练、自动化代码审查提供了低成本的解决方案,还为LLM代码分析领域提供了「结构化推理」的新范式,同时为传统静态程序分析工具提供了灵活的替代方案。
当然,研究也发现模型仍存在执行追踪不完整、漏检跨文件bug等问题,后续可通过模型微调、结合轻量形式化方法、拓展任务场景等方向进一步优化。整体而言,这项研究让LLM向「真正的智能代码分析师」迈出了关键一步,为AI赋能软件工程的未来发展奠定了重要基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献116条内容
已为社区贡献116条内容

所有评论(0)