服务器上部署ollama、LLM
本文详细介绍了Ollama本地部署及Qwen2-32B模型安装过程。首先指导用户下载并解压Ollama 0.17.5版本,通过环境变量配置监听地址和端口,解决服务启动参数不兼容问题。随后介绍Windows环境下安装Ollama客户端,下载Qwen2.5-32B模型的方法。最后讲解如何通过Docker部署OpenWebUI界面,包括端口映射调试和常见错误排查。整个流程涵盖Linux/Windows双
首先在本地下载好Ollama
https://github.com/ollama/ollama/releases/tag/v0.17.5
下载好压缩包以后,放到home/ubuntu/
进入文件所在目录
cd /home/ubuntu/解压
tar -I zstd -xvf ollama-linux-amd64.tar.zst移动可执行文件到系统目录
# 把 bin/ollama 移动到 /usr/local/bin/,让系统能识别 ollama 命令
sudo mv bin/ollama /usr/local/bin/移动依赖库到系统目录
# 先创建系统依赖目录(如果不存在)
sudo mkdir -p /usr/local/lib/
# 把解压出的 lib/ollama/ 整个目录移动过去
sudo mv lib/ollama /usr/local/lib/刷新系统库缓存
sudo ldconfig验证安装是否成功
ollama --version安装成功

启动 Ollama 服务
绑定 GPU 0
export CUDA_VISIBLE_DEVICES=0后台启动 Ollama 服务(端口 11434,允许外部访问)
nohup ollama serve --host 0.0.0.0 --port 11434 > ollama.log 2>&1 &等待服务初始化(5 秒),测试服务是否正常
sleep 5
curl http://localhost:11434/v1/models此处报错

查看服务启动日志
cat ollama.log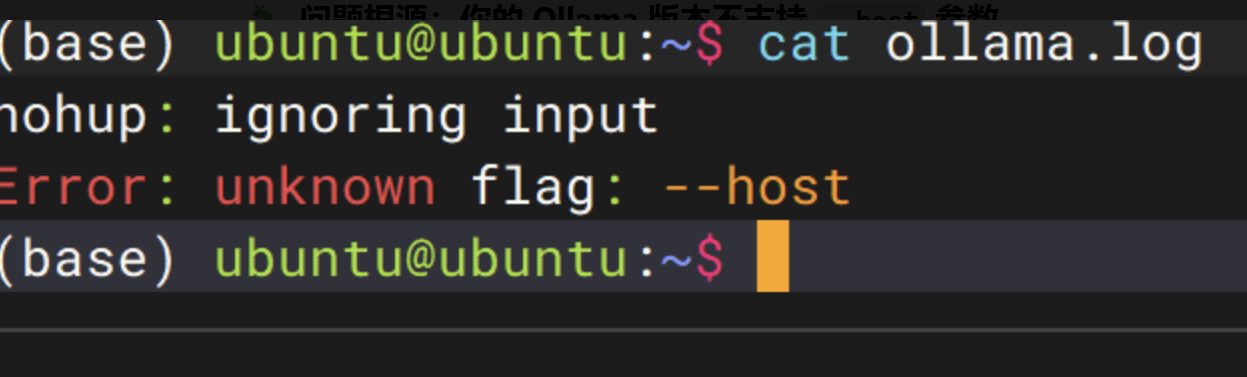
原因是:安装的 Ollama 0.17.5 版本中,ollama serve 命令不支持 --host 参数
先杀死残留的无效进程
kill -9 $(pgrep -f "ollama serve") 2>/dev/null用环境变量指定监听地址(0.0.0.0)+ 后台启动
# 1. 绑定 GPU 0(隔离现有服务)
export CUDA_VISIBLE_DEVICES=0
# 2. 指定 Ollama 监听所有地址(0.0.0.0),端口 11434(核心修复:用环境变量替代 --host)
OLLAMA_HOST=0.0.0.0 nohup ollama serve --port 11434 > ollama.log 2>&1 &
# 3. 等待 10 秒让服务完全初始化(比 5 秒更稳,避免连接超时)
sleep 10测试服务是否启动成功
curl http://localhost:11434/v1/models还是会报错:

查看错误日志
cat ollama.log
Ollama 0.17.5 版本既不支持 --host,也不支持 --port 参数,必须通过环境变量 OLLAMA_HOST 和 OLLAMA_PORT 来配置,命令中不能带任何参数。
先杀死残留的无效进程
kill -9 $(pgrep -f "ollama serve") 2>/dev/null用环境变量指定地址和端口,启动服务
# 1. 绑定 GPU 0(隔离现有服务)
export CUDA_VISIBLE_DEVICES=0
# 2. 用环境变量指定监听地址(0.0.0.0)和端口(11434),启动服务(核心修复:ollama serve 后不带任何参数)
OLLAMA_HOST=0.0.0.0 OLLAMA_PORT=11434 nohup ollama serve > ollama.log 2>&1 &
# 3. 等待 10 秒让服务完全初始化
sleep 10测试服务是否启动成功
curl http://localhost:11434/v1/modelsollama服务启动成功

二、部署LLM
本地安装ollama
https://ollama.com/download/windows
点击下一步安装完成
执行 ollama --version,输出版本号即成功。
本地下载 Qwen2-32B 模型
在本地终端 / CMD 执行以下命令
# 推荐:拉取 Qwen2.5-32B 默认 Q4_K_M 量化版(约14GB,显存需求<20GB)
ollama pull qwen2.5:32b-instruct
执行 ollama list,终端会显示 qwen2.5:32b-instruct

这里推荐一款配合ollama做的服务,比较方便
Open WebUI
首先确保本地有docker
以管理员身份打开 CMD,执行一键启动命令:
docker run -d -p 3000:3000 -v open-webui:/app/backend/data -v C:\Users\本地地址\.ollama:/root/.ollama --add-host=host.docker.internal:host-gateway ghcr.io/open-webui/open-webui:main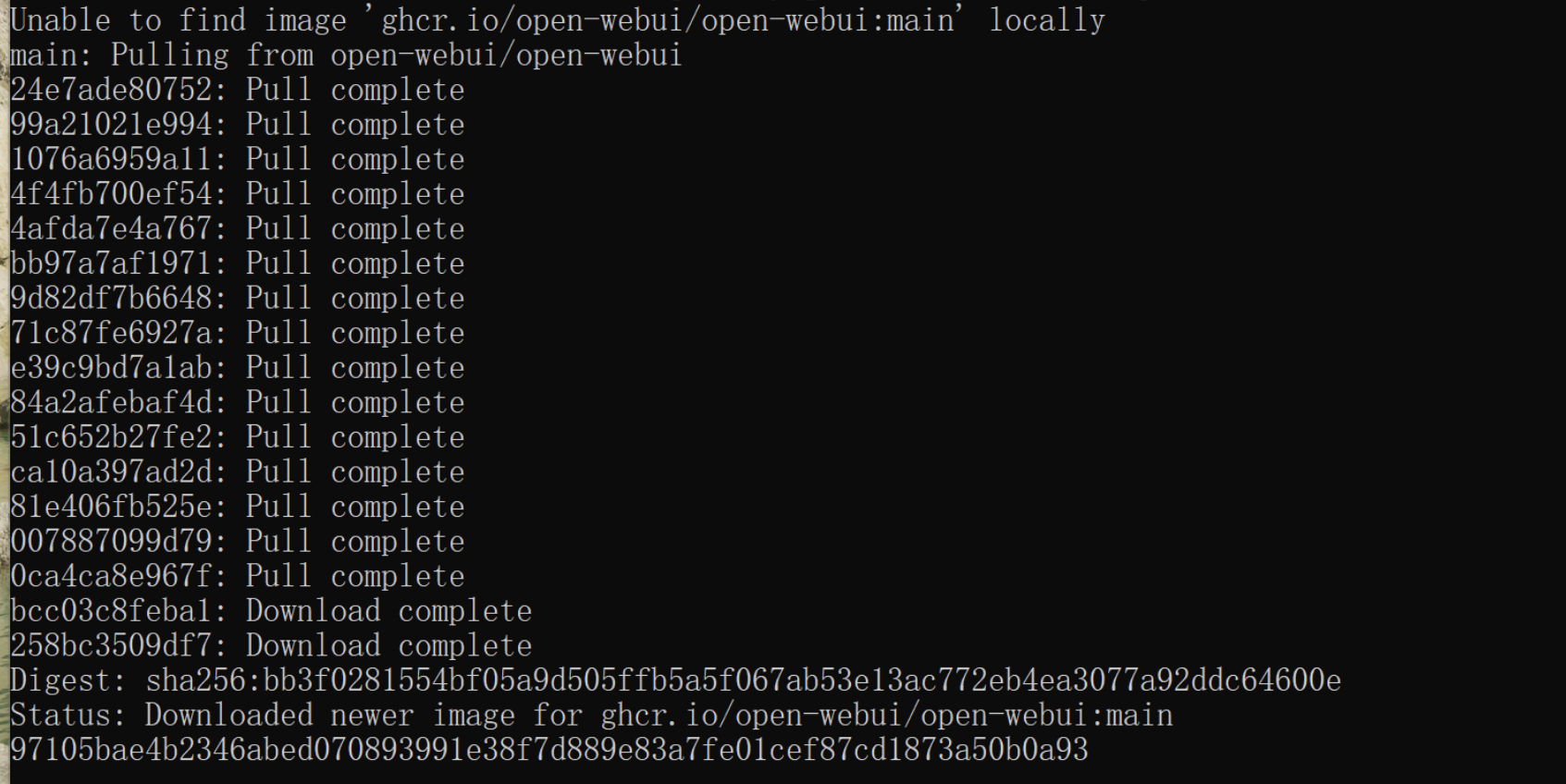
Open WebUI 必须依赖本地运行的 Ollama 服务,先在新的 CMD 窗口执行
ollama serve打开浏览器访问 http://localhost:3000,首次注册账号后即可使用;
- 若提示
Error: listen tcp 127.0.0.1:11434: bind: address already in use,说明 Ollama 已在后台运行,无需重复启动; - 若正常启动,终端会显示
Ollama is running,保持该窗口不要关闭。

Only one usage of each socket address is normally permitted,说明 Ollama 核心服务已在 Windows 后台自动启动,无需手动执行 ollama serve,这是 Windows 版 Ollama 的默认行为,直接进行模型下载即可。
在 CMD 中执行
docker ps -aIMAGE 列为 ghcr.io/open-webui/open-webui:main 的那一行,复制它的 CONTAINER ID(通常是一串 16 位的字符,如 97105bae4b23)。
停止并删除旧容器
在 CMD 中执行以下两条命令,将 <容器ID> 替换为你刚才复制的容器 ID:
docker stop <容器ID>
docker rm <容器ID>重新启动 Open WebUI 容器
务必将 192.168.1.100 替换为你在步骤 1 中找到的本地 IPv4 地址
docker run -d -p 3000:3000 ^
-v open-webui:/app/backend/data ^
-v C:\Users\千睿智汇\.ollama:/root/.ollama ^
-e OLLAMA_API_BASE_URL=http://192.168.1.100:11434 ^
--add-host=host.docker.internal:host-gateway ^
ghcr.io/open-webui/open-webui:main然后访问:
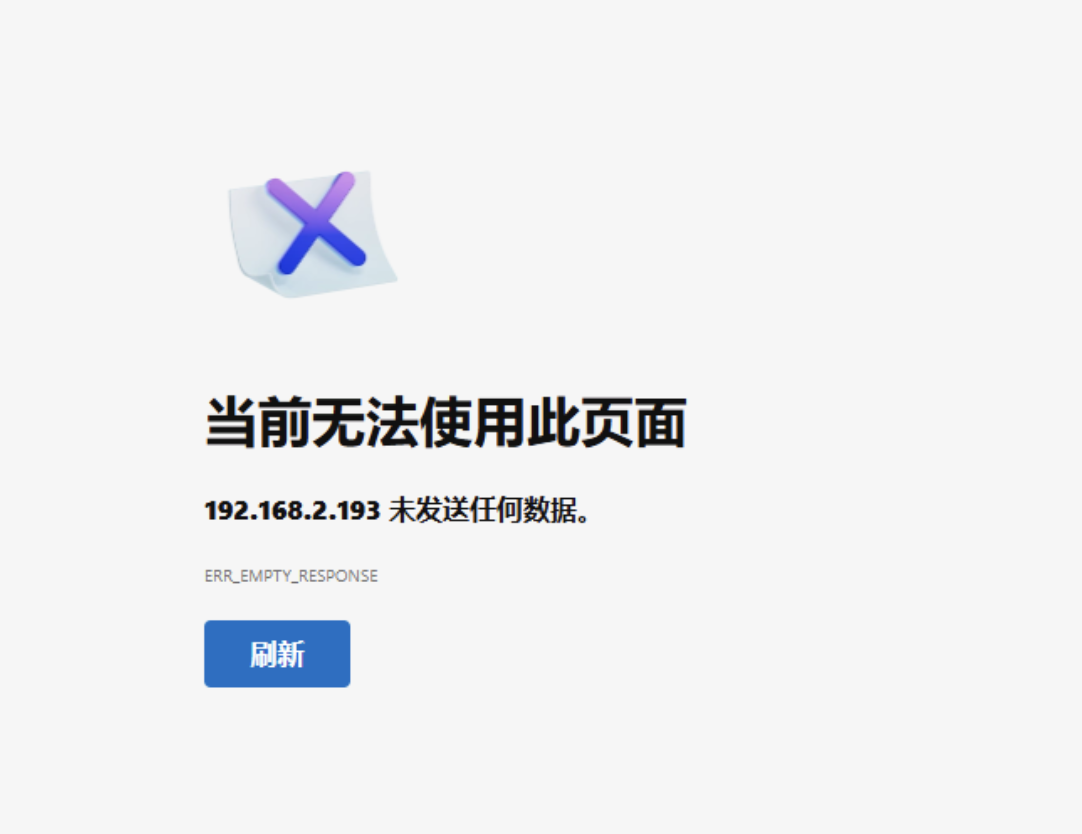
这时候还是没有办法跑起来
容器虽然启动了,但内部服务可能没跑起来。先执行以下命令,查看容器的详细日志
docker logs <新容器ID>显示日志里面是启动陈工了
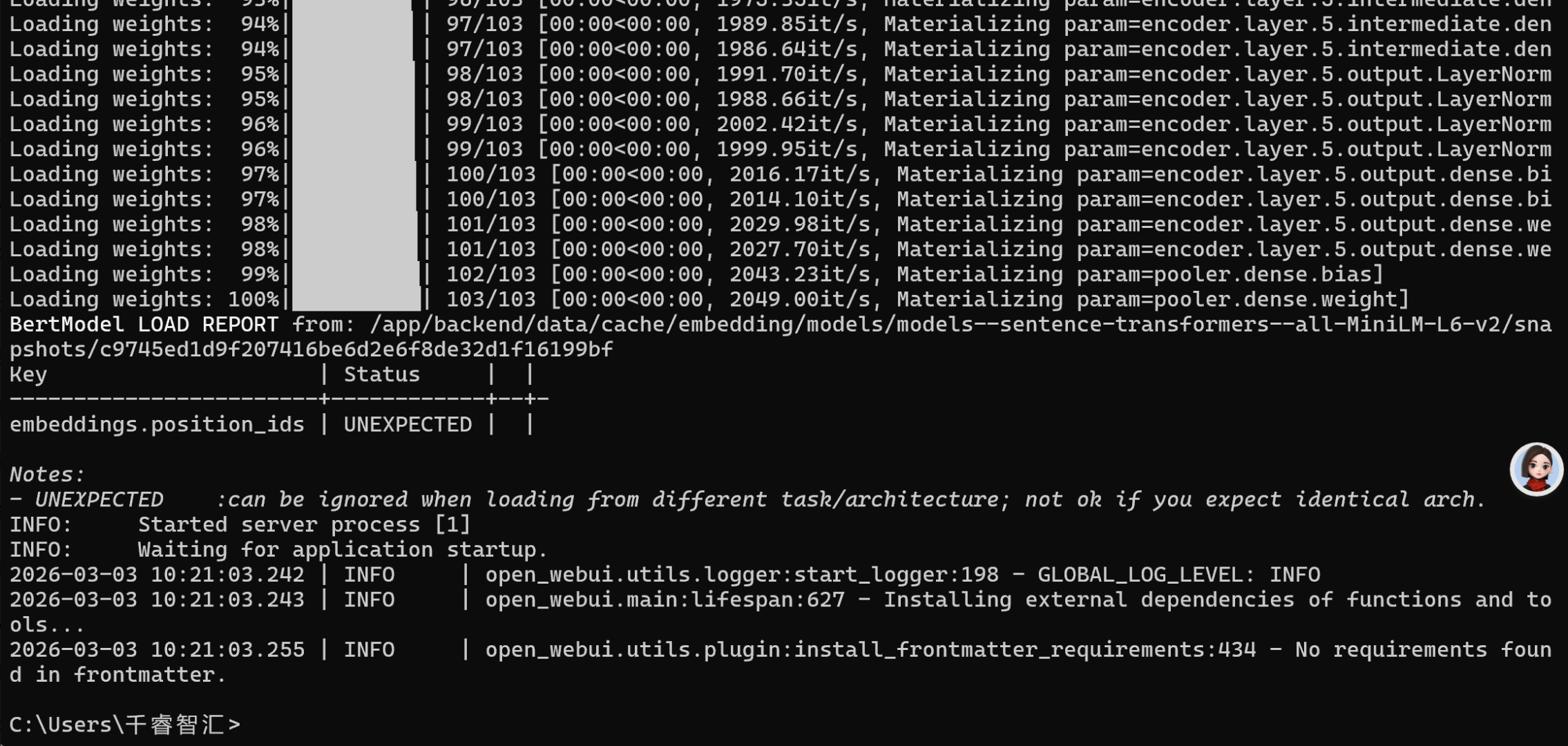
日志里明确显示:
Started server process [1]→ Web 服务已启动Waiting for application startup→ 服务正在等待请求- 没有出现连接 Ollama 的错误 → 容器已能正常连接 Ollama
页面打不开,大概率是访问地址或防火墙的问题,按以下步骤排查:
确认端口映射是否正确
docker ps看 PORTS 列,应该显示:
0.0.0.0:3000->3000/tcp如果是这样,说明容器的 3000 端口已经正确映射到宿主机的 3000 端口。
用 localhost 访问
打开浏览器,访问:
http://localhost:3000打开新的 CMD 窗口,执行:
curl http://localhost:3000
核心问题:端口映射搞反了!
先停止并删除旧容器(替换 <容器ID> 为当前运行的容器 ID):
docker stop <容器ID>
docker rm <容器ID>用正确的端口映射重新启动容器
docker run -d -p 3000:8080 ^
-v open-webui:/app/backend/data ^
-v C:\Users\本地地址\.ollama:/root/.ollama ^
-e OLLAMA_API_BASE_URL=http://192.168.2.193:11434 ^
--add-host=host.docker.internal:host-gateway ^
ghcr.io/open-webui/open-webui:main等待 10 秒,再用 curl 测试:
curl http://localhost:3000修复后,打开浏览器访问:
http://localhost:3000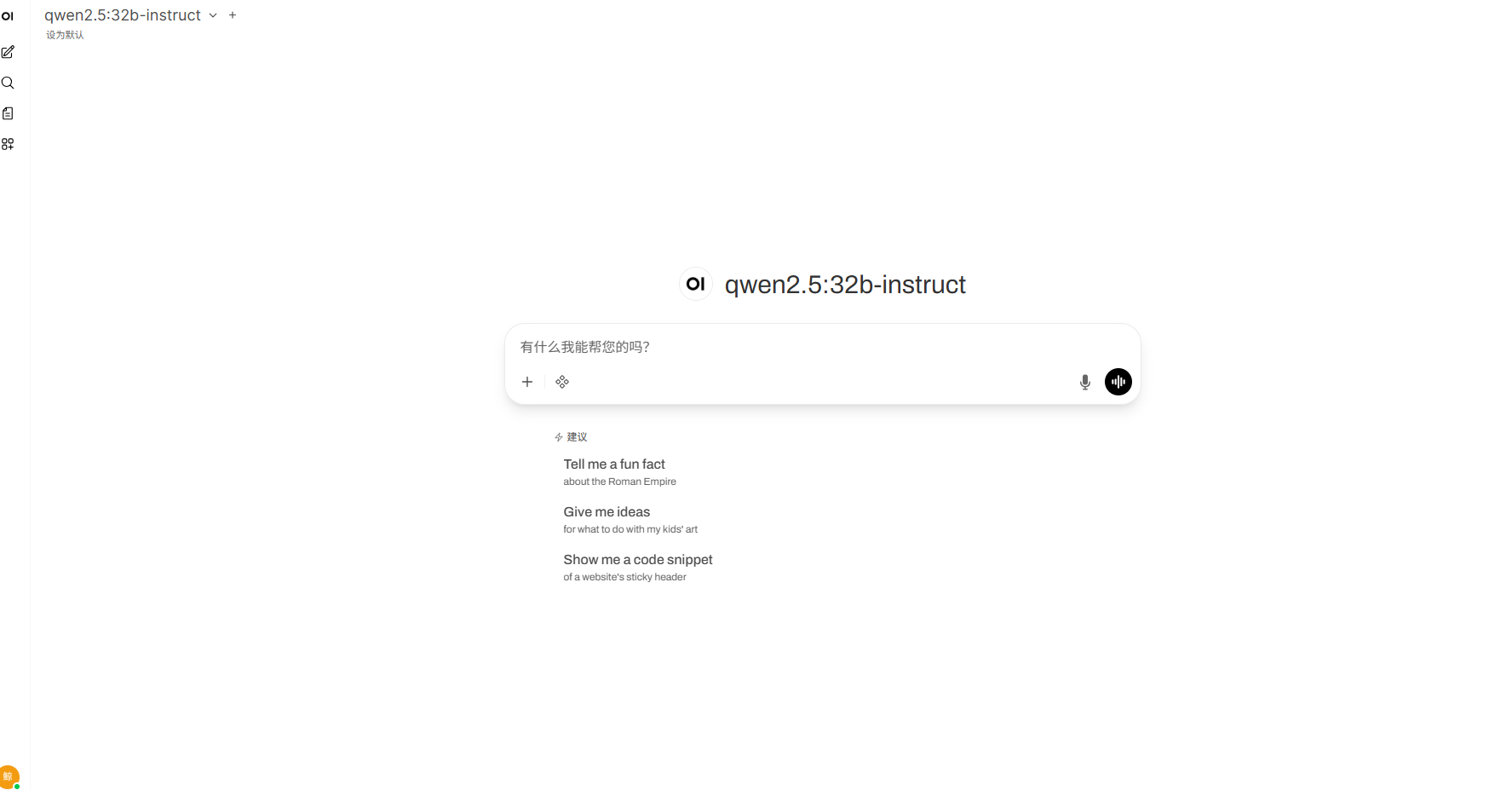
最后把压缩包上传LLM到服务器上执行下面的命令
# 1. 进入用户目录
cd /home/ubuntu/
# 2. 确保 Ollama 目录存在
mkdir -p ~/.ollama/
# 3. 解压模型文件到 Ollama 目录
# 如果是 rar 格式,需要先安装 unrar
sudo apt update && sudo apt install -y unrar
unrar x models.rar ~/.ollama/
# 如果是 zip 格式,使用 unzip
# unzip models.zip -d ~/.ollama/启动 Ollama 服务
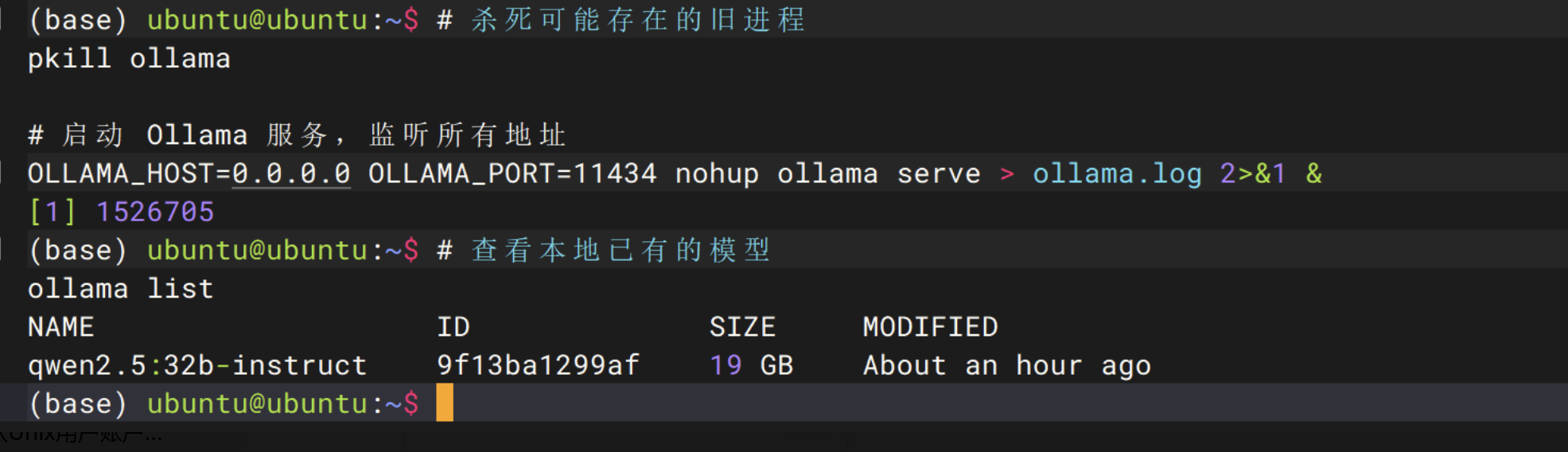
# 杀死可能存在的旧进程
pkill ollama
# 启动 Ollama 服务,监听所有地址
OLLAMA_HOST=0.0.0.0 OLLAMA_PORT=11434 nohup ollama serve > ollama.log 2>&1 &验证模型加载成功
# 查看本地已有的模型
ollama list模型部署成功

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)