SSA - KELM回归预测:MATLAB实现与代码解读
SSA麻雀搜索算法优化KELM核极限学习机(SSA-KELM)回归预测MATLAB代码代码注释清楚。main为主程序,可以读取EXCEL数据。很方便,容易上手。(电厂运行数据为例)温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。在电厂运行数据分析领域,精准的回归预测对于优化电厂运行、提高能源效率至关重要。今天我们要探讨的是基于SSA麻雀搜索算法优化KELM核极限学习机(SSA -
SSA麻雀搜索算法优化KELM核极限学习机(SSA-KELM)回归预测MATLAB代码 代码注释清楚。 main为主程序,可以读取EXCEL数据。 很方便,容易上手。 (电厂运行数据为例) 温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。
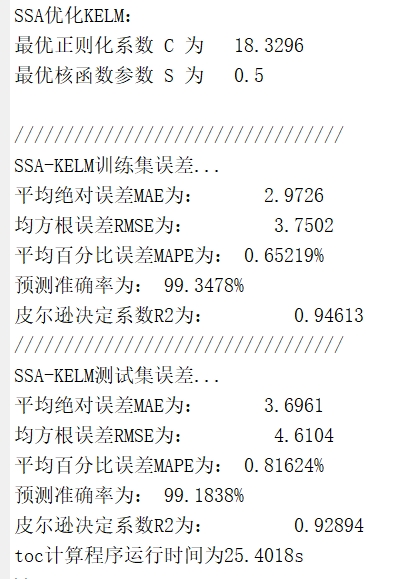
在电厂运行数据分析领域,精准的回归预测对于优化电厂运行、提高能源效率至关重要。今天我们要探讨的是基于SSA麻雀搜索算法优化KELM核极限学习机(SSA - KELM)的回归预测,并用MATLAB代码来实现这一过程。代码注释详细,方便大家上手。
一、主程序(main)读取EXCEL数据
MATLAB读取EXCEL数据非常方便,这是主程序中读取数据部分的代码:
% 读取EXCEL数据
data = readtable('power_plant_data.xlsx');
% 将表格数据转换为数值矩阵
data = table2array(data);
% 假设前n - 1列是特征,最后一列是目标值
X = data(:, 1:end - 1);
Y = data(:, end);在这段代码中,首先使用readtable函数读取名为powerplantdata.xlsx的EXCEL文件。这个文件存放着我们电厂运行的数据。然后通过table2array函数将表格形式的数据转换为数值矩阵,方便后续的计算。接着,将矩阵中的前end - 1列数据作为特征值赋给X,最后一列作为目标值赋给Y,这样数据预处理就初步完成了。
二、SSA - KELM核心代码与分析
麻雀搜索算法(SSA)是一种启发式优化算法,用于寻找最优解。这里它被用来优化KELM的参数,以提升预测性能。
% 定义SSA参数
pop = 30; % 种群数量
dim = 2; % 维度,假设KELM需要优化的参数有2个
Max_iteration = 100; % 最大迭代次数
lb = [0.1, 0.1]; % 参数下限
ub = [100, 100]; % 参数上限
% 初始化麻雀位置
X = initial_position(pop, dim, lb, ub);上述代码初始化了SSA算法的一些关键参数。pop设定了种群中麻雀的数量,dim表示需要优化的参数维度,因为KELM有需要优化的参数,这里假设为2个,所以dim为2。Maxiteration定义了算法的最大迭代次数,这决定了算法寻找最优解的努力程度。lb和ub分别设定了参数的下限和上限,限制了搜索空间。initialposition函数则是自定义的初始化麻雀位置的函数,在这个函数里会随机生成在lb和ub范围内的初始位置,为后续搜索做准备。
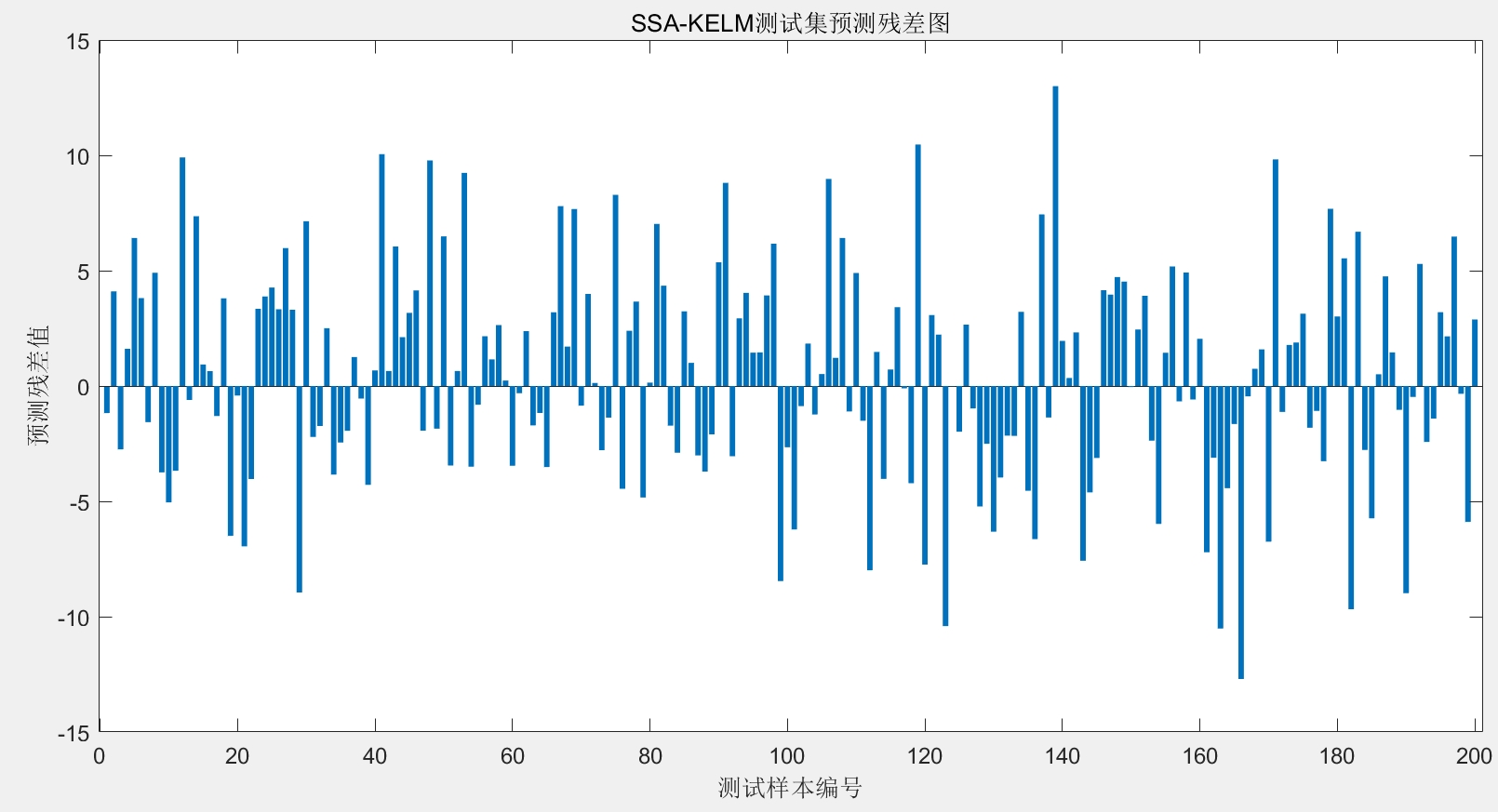
SSA麻雀搜索算法优化KELM核极限学习机(SSA-KELM)回归预测MATLAB代码 代码注释清楚。 main为主程序,可以读取EXCEL数据。 很方便,容易上手。 (电厂运行数据为例) 温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。
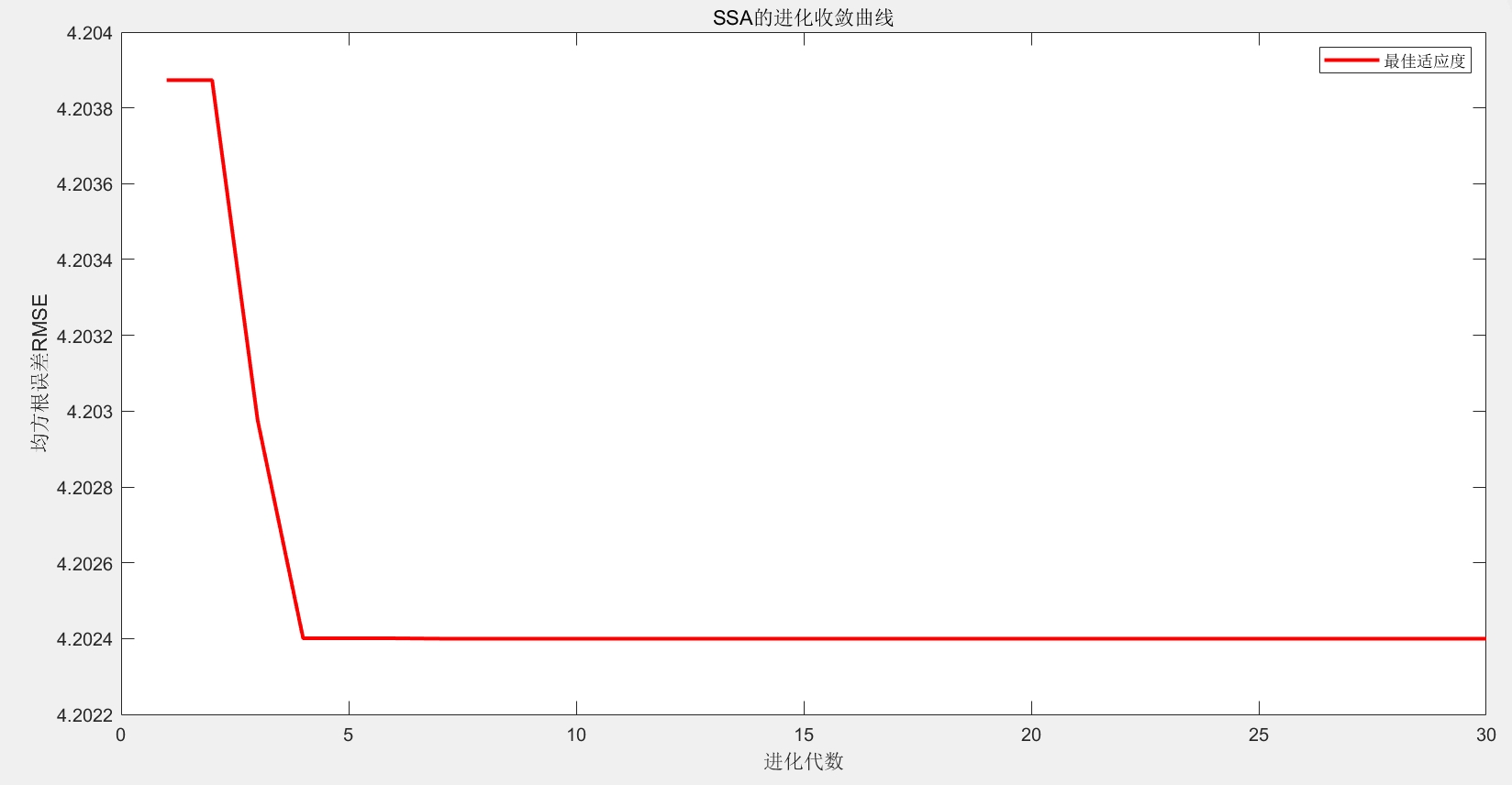
接下来看看KELM部分的核心代码:
function [output] = KELM(X, Y, inputWeight, bias, kernelFunction, kernelPara)
% 计算隐含层输出
H = feval(kernelFunction, X, inputWeight, bias, kernelPara);
% 计算输出权重
outputWeight = pinv(H) * Y;
% 预测输出
output = H * outputWeight;
end在这个KELM函数中,首先根据传入的核函数kernelFunction、输入权重inputWeight、偏差bias以及核参数kernelPara,通过feval函数计算隐含层输出H。这里的核函数可以是高斯核函数等不同类型,根据实际需求选择。然后利用伪逆矩阵pinv计算输出权重outputWeight,最后通过隐含层输出与输出权重相乘得到预测输出output。
三、完整的SSA - KELM流程
结合上述部分,完整的SSA - KELM流程代码大致如下:
% 主程序
data = readtable('power_plant_data.xlsx');
data = table2array(data);
X = data(:, 1:end - 1);
Y = data(:, end);
% 定义SSA参数
pop = 30;
dim = 2;
Max_iteration = 100;
lb = [0.1, 0.1];
ub = [100, 100];
% 初始化麻雀位置
X = initial_position(pop, dim, lb, ub);
for t = 1:Max_iteration
% 计算适应度值
fitness = zeros(pop, 1);
for i = 1:pop
inputWeight = X(i, 1);
kernelPara = X(i, 2);
% 调用KELM进行预测
pred = KELM(X, Y, inputWeight, 1, @gaussian_kernel, kernelPara);
% 计算适应度,这里以均方误差为例
fitness(i) = mean((pred - Y).^2);
end
% 更新麻雀位置,这里省略具体的SSA更新位置代码逻辑
[X, fitness] = update_position(X, fitness, pop, dim, lb, ub, t, Max_iteration);
end
% 找到最优参数
[bestFitness, bestIndex] = min(fitness);
bestInputWeight = X(bestIndex, 1);
bestKernelPara = X(bestIndex, 2);
% 用最优参数进行最终预测
finalPred = KELM(X, Y, bestInputWeight, 1, @gaussian_kernel, bestKernelPara);在这个完整流程中,首先进行数据读取和SSA参数初始化。在迭代过程中,每次计算每个麻雀位置对应的KELM预测结果,并以均方误差作为适应度值进行评估。然后通过update_position函数(这里省略具体实现,因为SSA更新位置逻辑较为复杂且篇幅有限)更新麻雀位置,寻找更优解。最后找到适应度最优的参数,并用这些参数进行最终的预测。
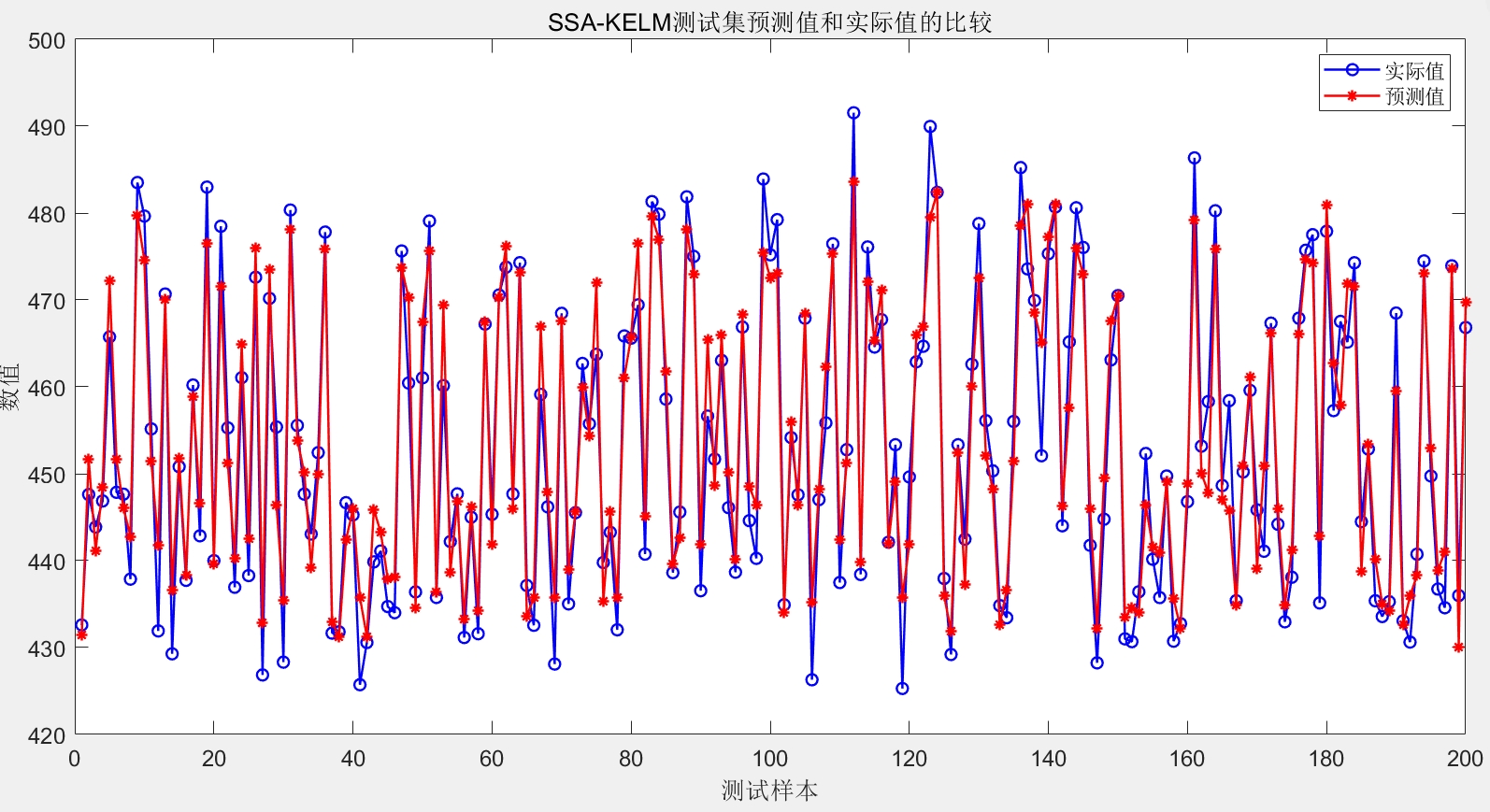
温馨提示:如果此程序代码作为商品出售,一经售出,概不退换哦。希望通过这些代码和分析,大家对基于SSA - KELM的电厂运行数据回归预测有更清晰的认识,能在实际项目中灵活运用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)