AI编程适配|Supabase全解析(云服务+本地部署)+PostgreSQL高级特性实战
Supabase作为25年后端热门开源BaaS框架,GitHub星标98000+,基于PostgreSQL封装全套后端基础设施,支持用户认证、文件存储等核心功能,可云服务快速上手或Docker本地部署。本文实操演示Supabase云服务使用、Navicat远程连接、前端SDK接入及RLS行级安全策略配置,同步详解PostgreSQL核心特性,包括自定义类型、表继承、JSONB支持、全文检索及高级索
文章目录
supabase
Supabase作为25年后端最火的开源项目,它在 GitHub 上拥有 98000+ Star,是整个平台最顶级的开源项目之一。作为一个开源的后端即服务框架(BaaS),它基于强大的 PostgreSQL 数据库,封装了用户认证、文件存储、可视化运维面板等功能,为开发者提供了一整套开箱即用的后端基础设施。
Supabase 为开发者提供了三大部分核心能力:
- 后端基础设施:PostgreSQL 数据库、文件存储、边缘函数、用户认证等。
- 前端 SDK:支持 React、Vue、移动端 App 等,几行代码即可接入后端。
- 免费云服务:无需自建,注册即可获得免费实例;也可通过 Docker 本地 / 私有部署。
它与 AI 编程是绝配,能让你以极快速度搭建一套包含用户认证 + 数据库的前后端完整应用。
从云服务版本快速上手
supabase的基础是一个完整的PostgreSQL数据库,具备PostgreSQL一切能力。在官网中可以使用github登录,创建一个数据库实例。
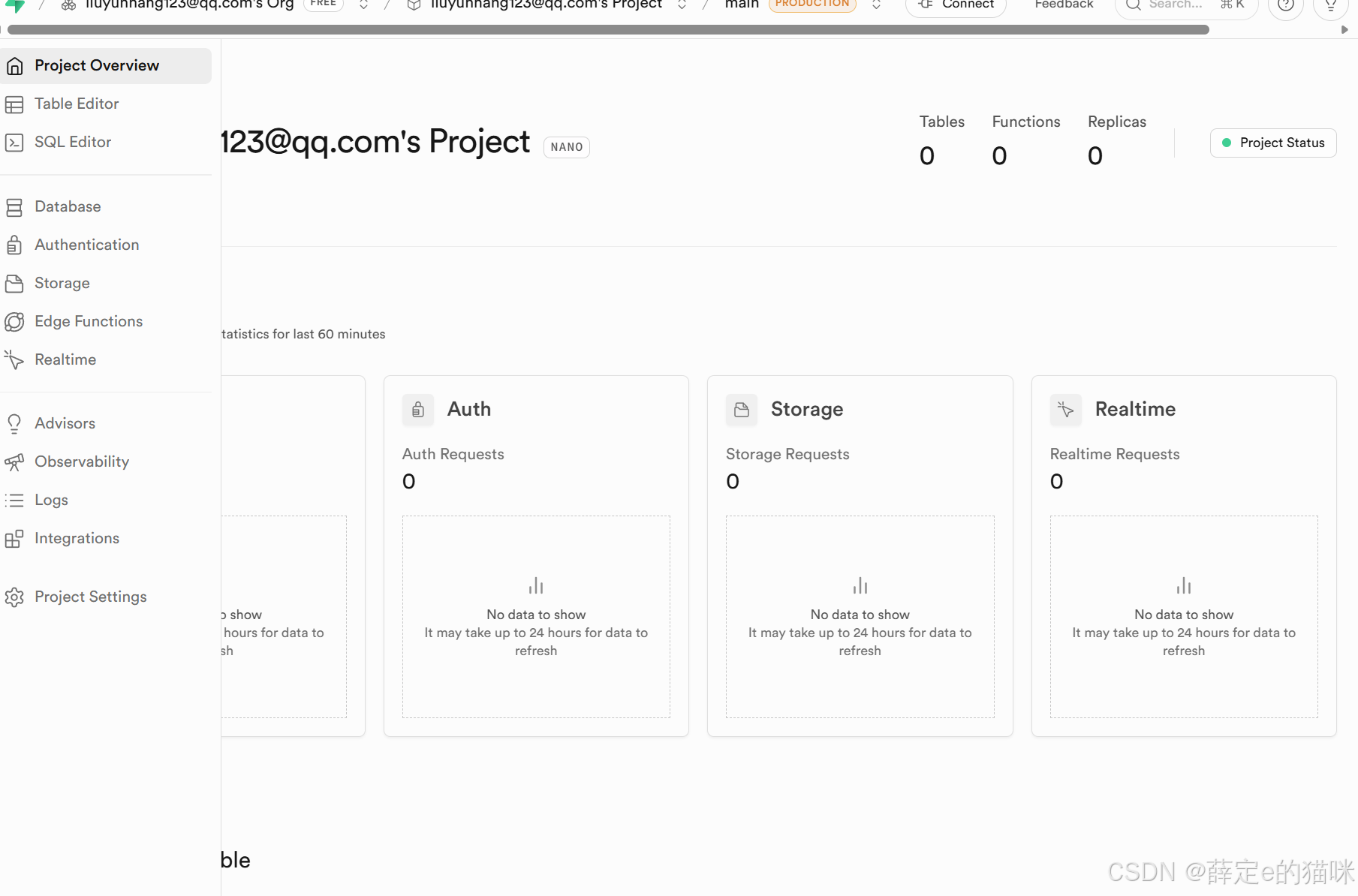
| 模块名称 | 核心功能 | 适用场景 |
|---|---|---|
| Project Overview | 项目仪表盘,展示数据库、认证、存储、实时服务的核心指标与运行状态 | 快速监控项目健康度,作为进入项目后的默认入口 |
| Table Editor | 可视化 PostgreSQL 表管理,支持图形化创建 / 修改表结构、字段、约束等 | 快速搭建数据模型,无需手动编写 DDL 语句 |
| SQL Editor | 在线 SQL 工作台,支持编写、执行、保存任意 PostgreSQL SQL 脚本 | 调试复杂查询、批量数据操作、自定义业务逻辑 |
| Database PostgreSQL | 包含Postgres的所有基础功能:Schema,表(Tables),函数(Function),触发器(Triggers),枚举(Enumerated Types),插件(Extensions),索引(Indexes),实时监控(Publications) — 把表的修改信息以Websocket的形式推送出去 | 精细化数据库运维、架构选型、性能调优 |
| Authentication | 一站式用户认证,支持邮箱 / 手机号 / 第三方登录及权限控制 | 快速实现 Web 应用的登录注册、用户体系 |
| Storage | 对象存储服务,支持文件上传 / 下载及权限管理 | 管理图片、视频、文档等非结构化资源 |
| Edge Functions | 边缘无服务器函数,基于 Deno 运行时,低延迟执行服务端逻辑 | 轻量级 API、第三方集成、定时任务等微服务场景 |
| Realtime | 基于 PostgreSQL 复制槽的实时数据推送(WebSocket) | 聊天、实时榜单、协同编辑等需要数据即时同步的场景 |
| Advisors | AI 助手,自动检测数据库缺陷、性能问题并给出优化建议 | 辅助开发、排查性能瓶颈、提升代码质量 |
| Observability | 可观测性总览,整合性能指标、错误链路、资源使用等可视化数据 | 运维监控、问题定位、性能瓶颈分析 |
| Logs | 分类存储的详细操作与错误日志,支持多维度筛选 | 问题复盘、错误排查、审计追踪 |
| Integrations | 第三方服务集成,如 Slack、GitHub Actions 等 | 自动化通知、CI/CD 流水线、外部系统数据同步 |
| Project Settings | 全局配置,包括 API 密钥、区域、安全策略、成员权限等 | 项目部署、生产环境安全配置、团队权限管理 |
Extensions的postgis插件实例:
Database -> Extensions -> postgis(选择public)
安装postgis插件后,postgres就有了存储地理位置信息的能力,可以把postgres变成一个性能顶尖的企业级地理信息系统数据库。

创建一个表用来存储城市里面的地理位置信息
CREATE TABLE city_map (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
-- 4326 是 WGS84 GPS坐标系的 EPSG 代号
geom GEOMETRY(Geometry, 4326)
);

插入地理位置相关的测试数据
INSERT INTO city_map (name, geom) VALUES
(
'人民公园',
-- 一个四边形的公园
ST_GeomFromText('POLYGON((0 0, 10 0, 10 10, 0 10, 0 0))', 4326)
),
(
'护城河',
-- 一条直线形的河流
ST_GeomFromText('LINESTRING(-5 5, 15 5)', 4326)
),
(
'电话亭',
-- 一个点坐标
ST_GeomFromText('POINT(12 8)', 4326)
);
使用插件提供的函数来计算人民公园的面积
SELECT name, ST_Area(geom)
FROM city_map
WHERE name = '人民公园';

使用插件提供的操作符来计算两个地理位置之间的距离(查找三个距离电话亭最近的地理元素)
SELECT name
FROM city_map
ORDER BY geom <-> (SELECT geom FROM city_map WHERE name = '电话亭')
LIMIT 3;

远程连接操作数据库(navicat)
supabase还提供了远程连接的方式操作数据库,点击connect,supabase提供了一个远程连接的地址,可以接入到任意一个数据库的客户端,或者后端代码中。

使用直连模式direct connection是不支持IPv4的,如果网络只能使用IPv4的话请选择Session pooler
在navicat中的配置信息如下:密码填写创建supabase项目时候的密码

数据库连接成功:

Supabase SDK:前端直连后端
supabase可以将任何一个前端框架(React,Vue,app)用一行代码接入后端。 ---- supabase一般配合鉴权功能(Authentication)使用。
创建一个vue前端工程体验一下supabase的SDK模式“:
npm create vue@latest
cd vue-project
npm install
npm run dev
接下来把supabase的SDK接入到这个前端工程,安装 Supabase SDK:
npm install @supabase/supabase-js
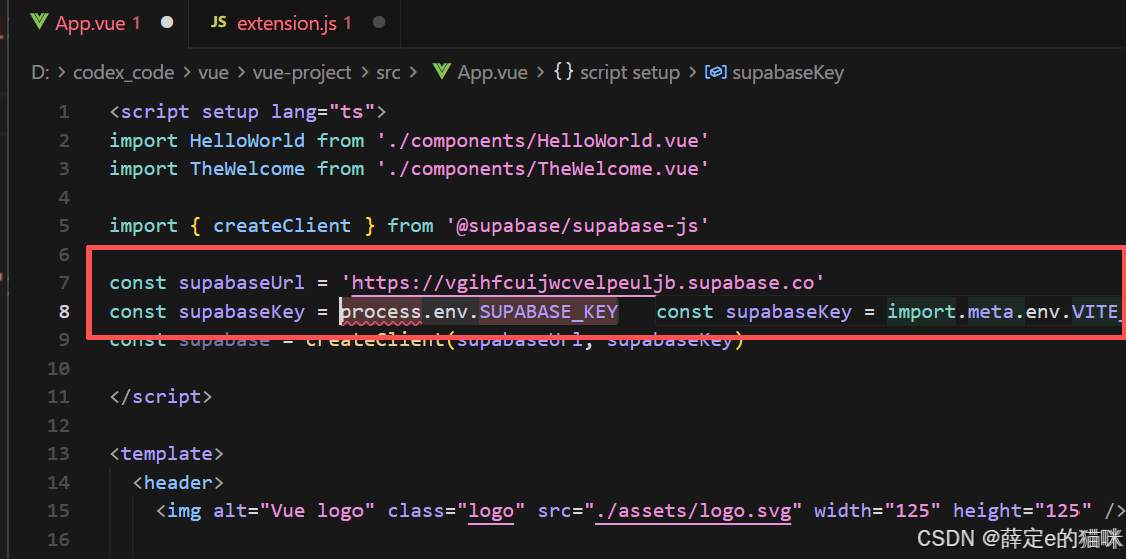
测试SDK,在APP.vue文件中添加如下内容,正确填写自己的Url和Key:
import { createClient } from '@supabase/supabase-js'
const supabaseUrl = 'https://vgihfcuijwcvelpeuljb.supabase.co'
const supabaseKey = process.env.SUPABASE_KEY
const supabase = createClient(supabaseUrl, supabaseKey)
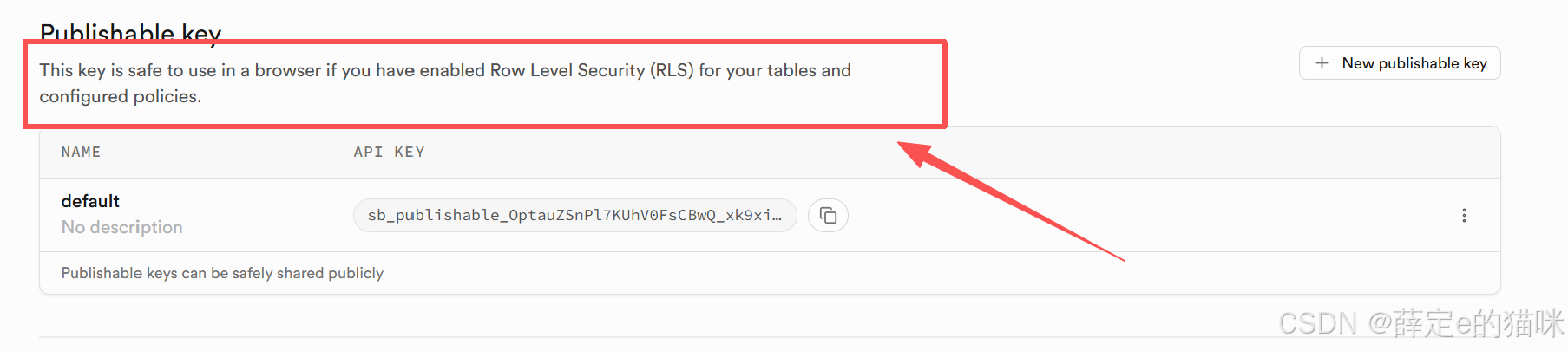
把API key直接写道前端代码里,不是直接泄露违反安全规范了么?
在supabase官网中说明了这个key在游览器中使用是安全的,RLS保证了我们即时在前端跟数据库交互也能确保数据的安全。
在const supabase = createClient(supabaseUrl, supabaseKey)下面写如下面的代码(输入自己的邮箱和密码):
await supabase.auth.signUp({
email: 'test@test.com',
password: 'test',
})
重新启动程序 :npm run dev
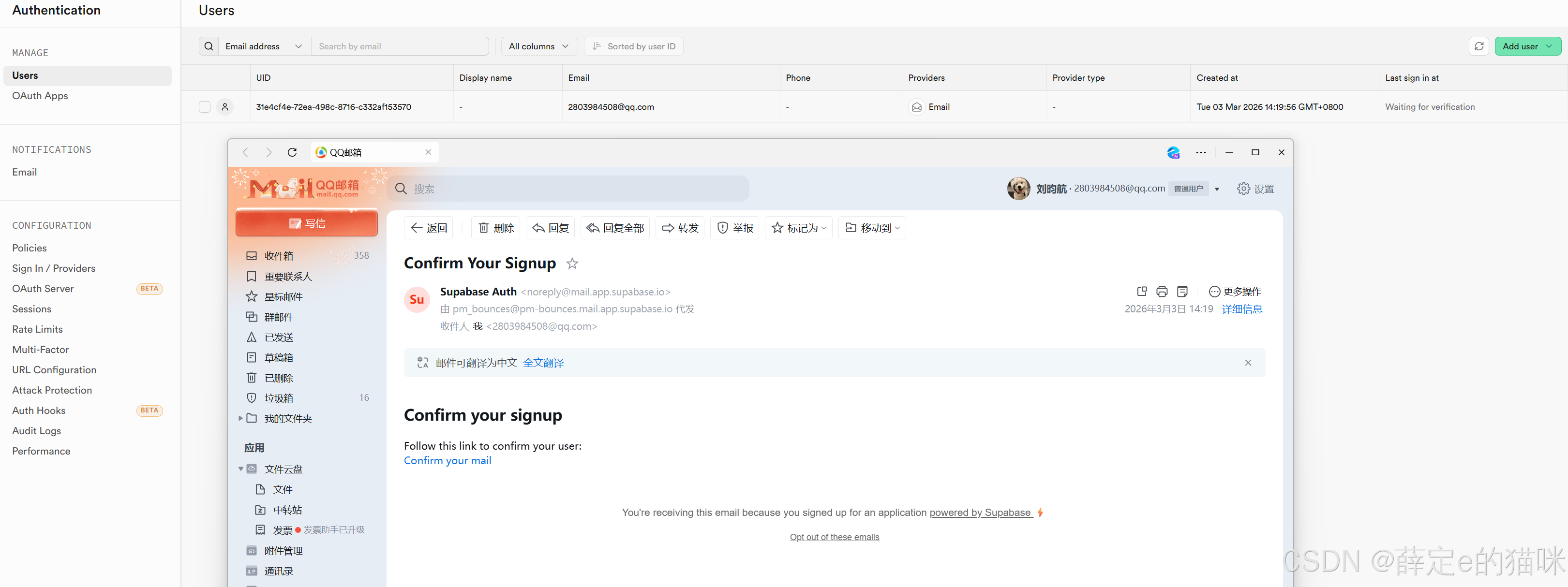
用户登录只需要把注册的代码改成如下形式:
const{data:signInData,error:signInError} = await supabase.auth.signInWithPassword({
email: '2803984508@qq.com',
password: '781206lyh',
})
console.log(signInData)
在控制台可以看到打印出来的用户信息:
RLS 行级安全策略

RLS行级安全策略 是postgres的原生功能(约束哪些数据可以被哪些用户修改或读取)
RLS实践如下:
Table Editor -> New tables
首先创建一个用户信息表 user_info,添加需要的字段:
需要将用户信息表和系统表关联起来,添加一个字段user_id,类型选择uuid

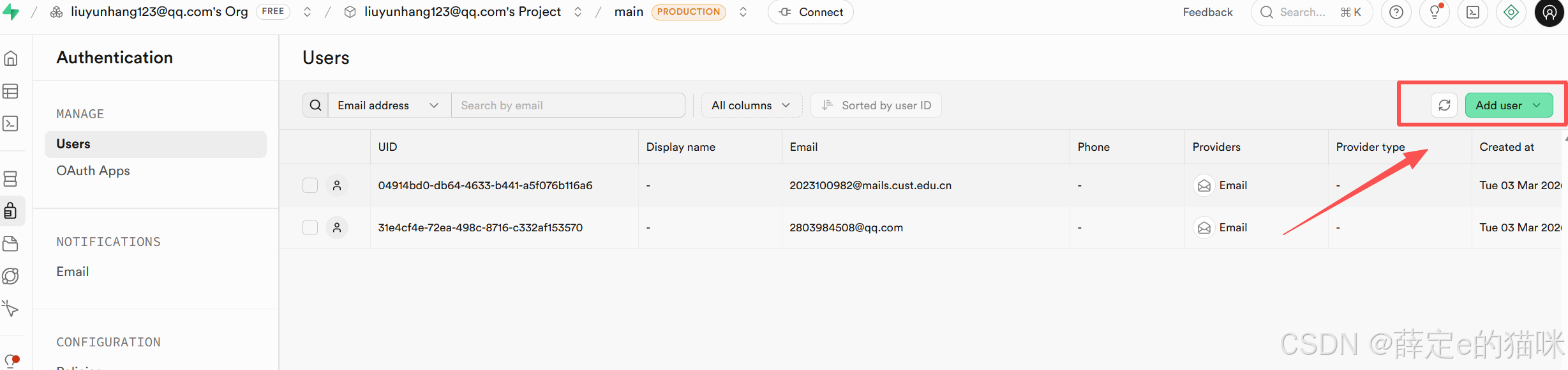
添加外键:将user_id与auth(系统表 — Authentication)里边的users(用户表)关联起来,

在Authentication中新建一个用户(Add user),这样系统里边就用有两个用户了:
回到业务表 Table Editor 填写用户的基础信息 Insert :
填写 age ,first_name , last_name信息,其中user_id选择 select record 在选择不同用户的字段:

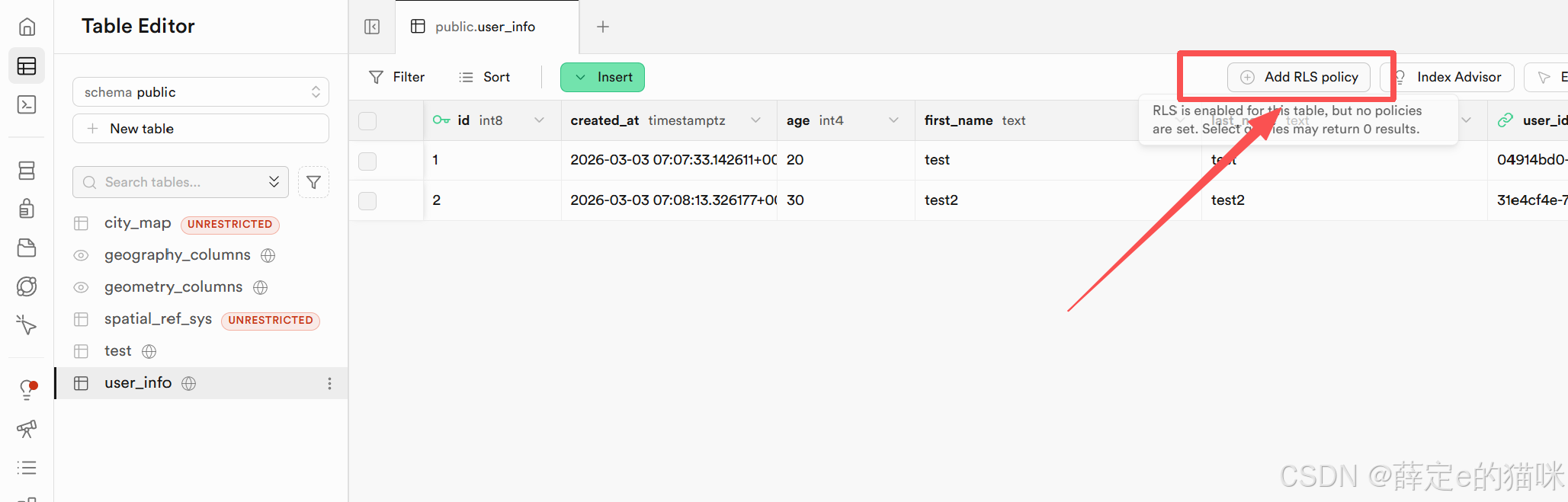
这样在Authentication的系统表里有两个用户,在业务表(Table Editor)里存储了两个用户的年龄。 现在希望只让某个用户查看并且修改属于自己的记录,而不能去查看或者修改别人的记录。 ---- 因此需要给业务表配置行级安全策略:
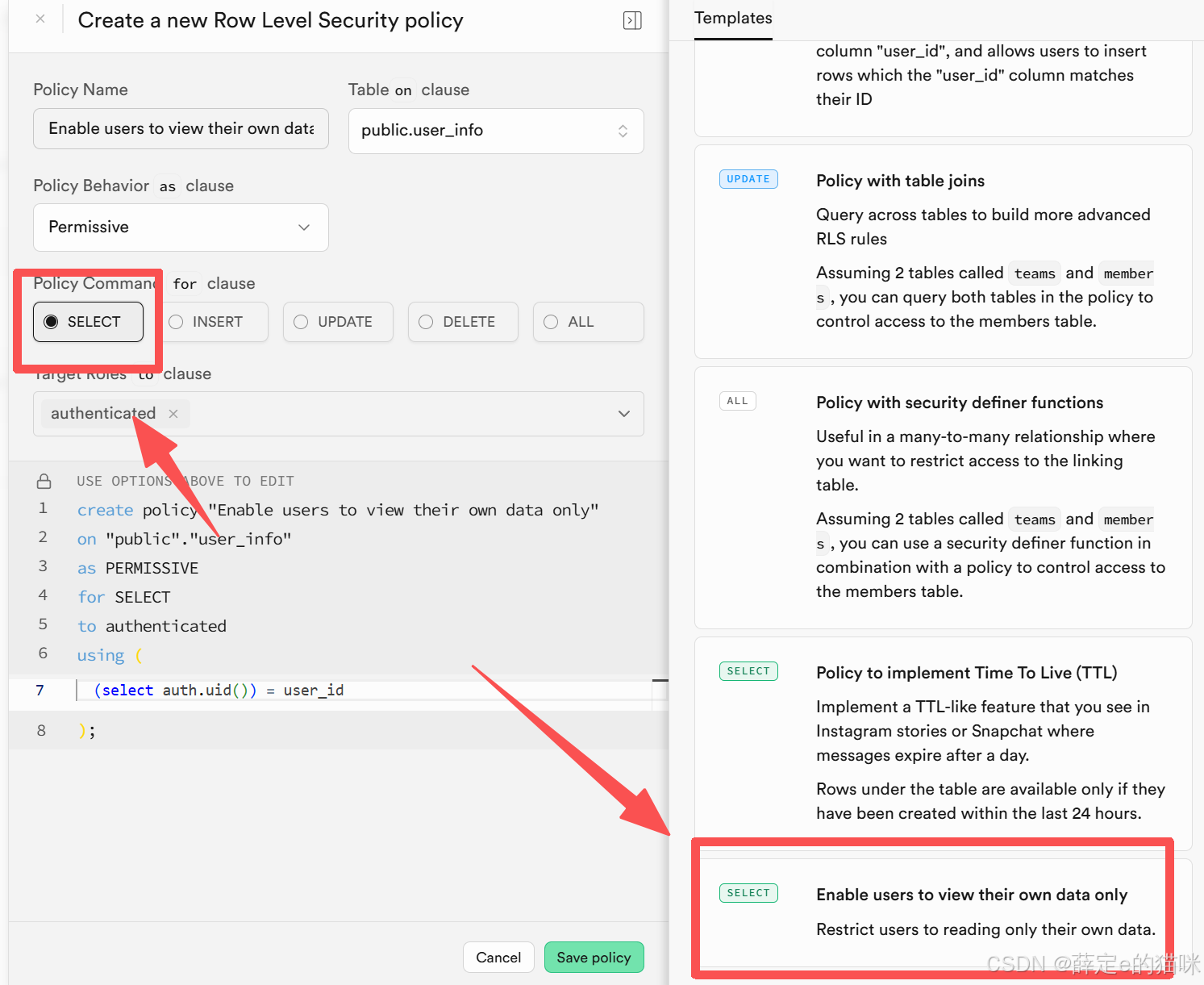
Add RLS policy -> Create policy -> select -> Enable users to view their own data only(登录用户只能读取属于自己的数据)
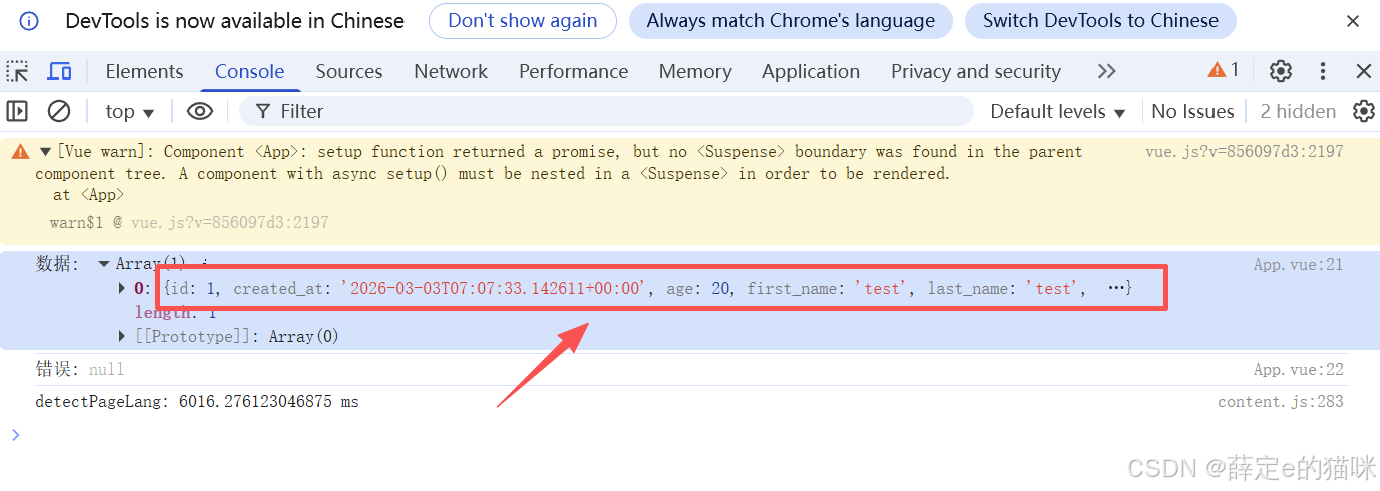
现在可以把查询语句直接写到前端代码里边,从 user_info 表中查询所有 first_name 字段值为 tech 的记录。
select(‘*’) 表示返回匹配记录的所有字段。
const { data, error } = await supabase
.from('user_info')
.select('*')
.eq('first_name', 'tech')
console.log('数据:', data)
console.log('错误:', error)
运行后数据被查询出来:
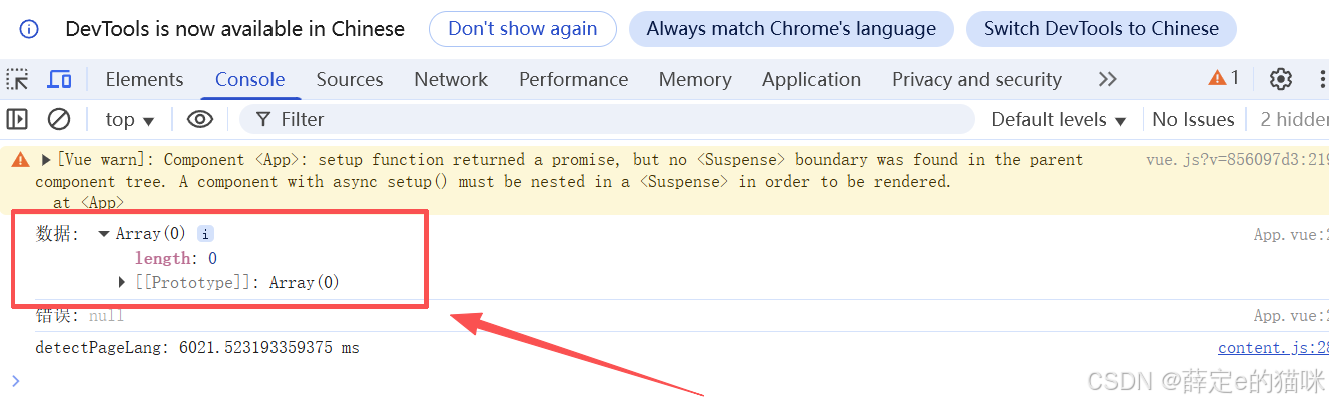
将 first_name 换成其他人的测试:数据变为空
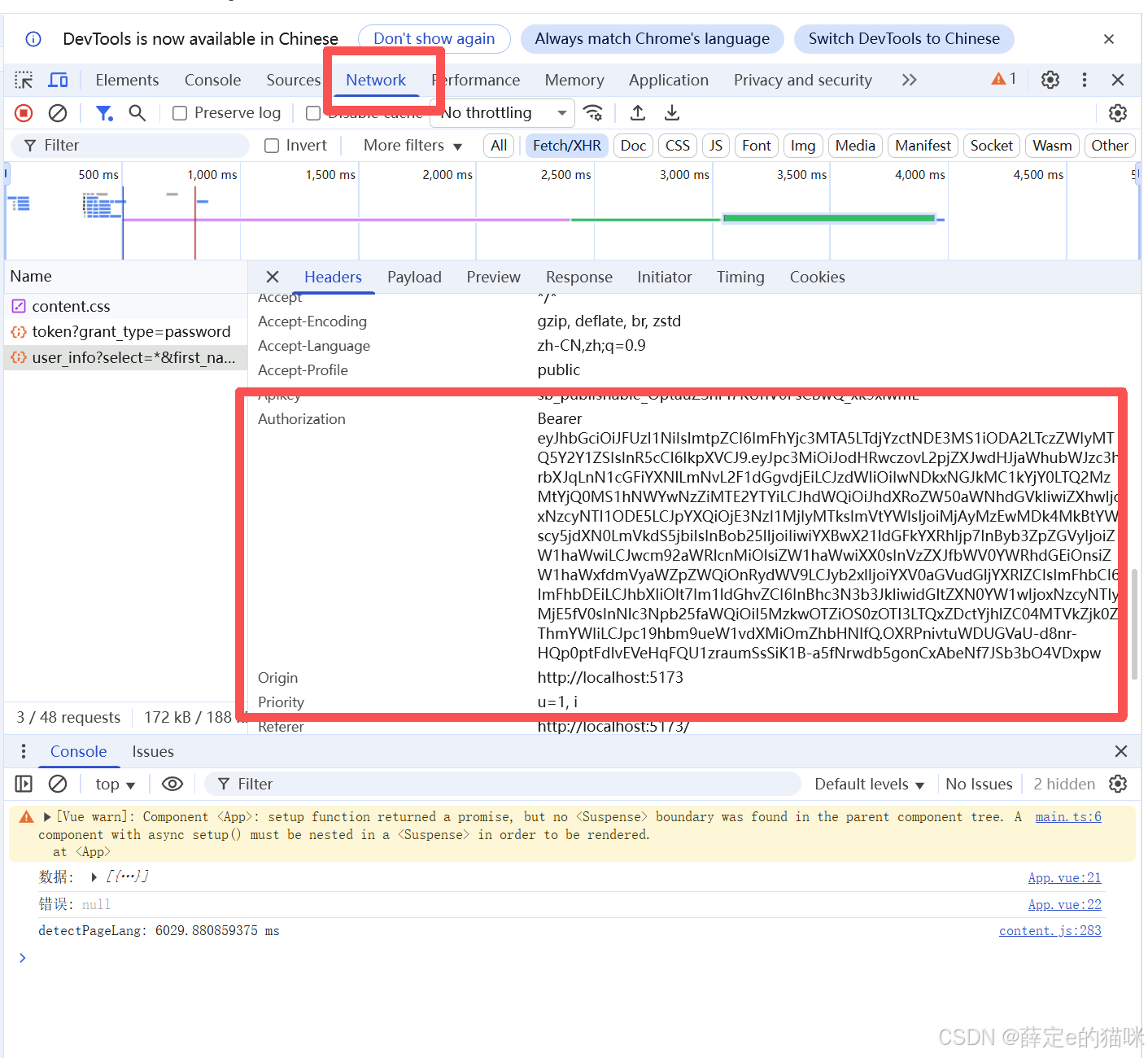
在控制台 -> network -> Headers 中的Authorization有一个bearer,包含JWT token(当前登录用户的令牌),这个令牌和后面的行级安全策略匹配才能查询到数据。
本地 / 私有部署
如果不想使用云服务,可以通过 Docker 自托管:
如果没有安装docker可以查看这篇文章:2026 最新 Docker 教程:Docker Desktop 安装(非系统盘)+ 命令 + 网络 + Docker Compose 一站式学习
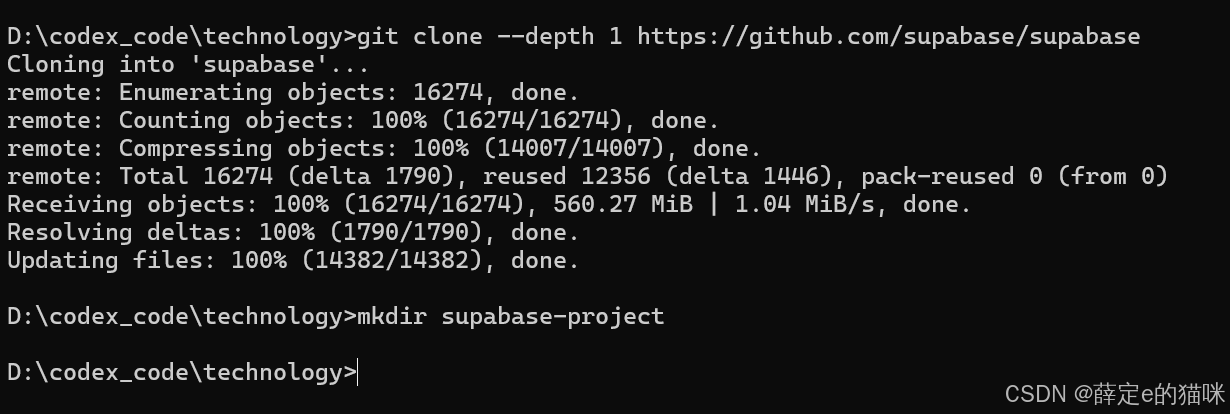
将docker Desktop启动起来后,在一个新建文件夹中输入下面的命令:
# Get the code
git clone --depth 1 https://github.com/supabase/supabase
# Make your new supabase project directory
mkdir supabase-project
手动将supabase -> docker 中的文件都复制到supabase-project中:

创建.env文件,将.env.example文件复制。 同时需要修改.env文件中的前端端口,需要设的大一些:

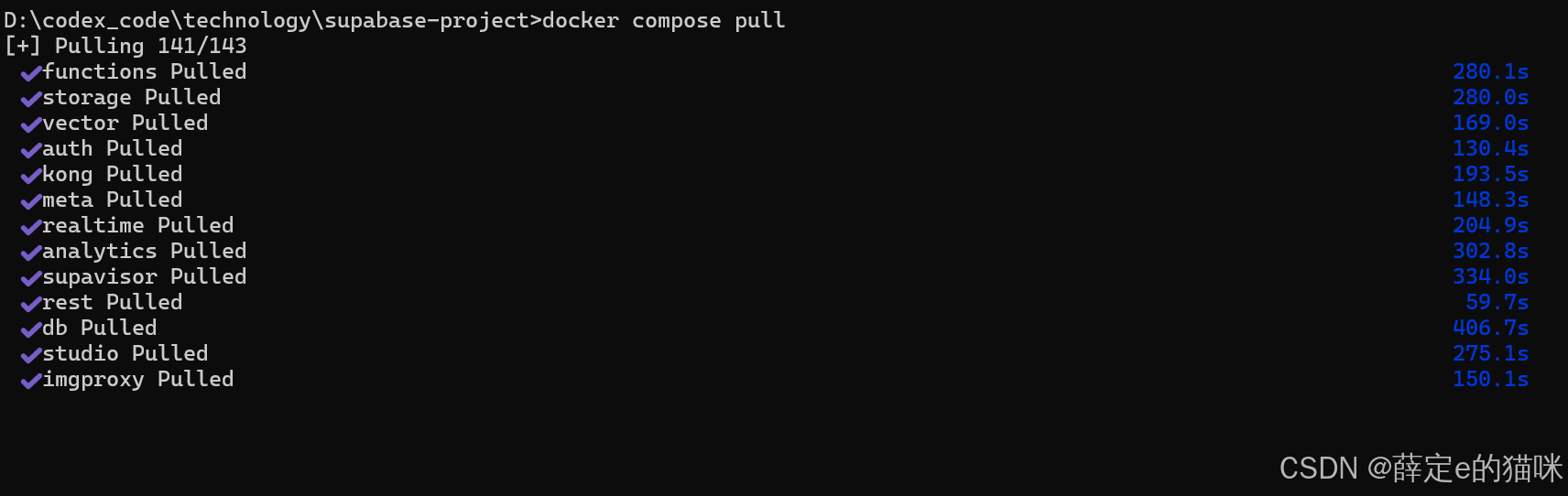
接下来拉取镜像:执行下面的命令
# Switch to your project directory
cd supabase-project
# Pull the latest images
docker compose pull
把容器都启动起来:
docker compose up -d
访问端口(http://localhost:18000)后需要填写账号和密码,可以在.env中查看:
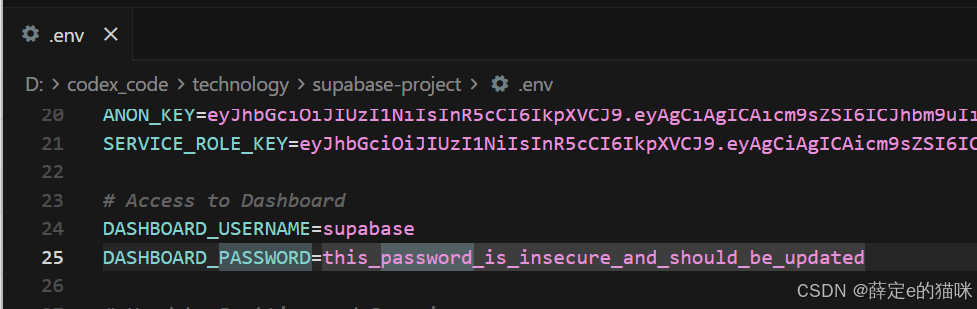
#账号
supabase
#密码
this_password_is_insecure_and_should_be_updated
PostgreSQL
下载安装
没有复杂配置,都直接next即可。其中PostgreSQL的默认端口号:5432
在下载过程中需要对数据库进行用户密码设置,完成后点击 -> next

游览文件路径及数据库信息,点击下一步 -> next

如果在安装界面没有勾选Stack Builder(可视化界面),可以点击安装目录中的stackbuilder.exe来进行安装。

环境变量配置:
将PostgreSQL安装目录中的bin路径复制到系统变量的Path变量中:

在用户变量中设置PG_HOME 和 PGDATA:

测试是否安装成功:

登录指令格式为:psql -U 用户名 -d 数据库名 -h 主机地址 -p 5432
基础登录(默认用户 postgres,默认数据库 postgres)
运行如下命令:
psql -U postgres -p 5432

丰富的内置数据类型 + 自定义类型
PostgreSQL 被定义为“开源对象关系型数据库”(Open Source Object-Relational Database),兼具传统关系型数据库的严谨性和面向对象的灵活性,从根源上解决了很多开发痛点。
连接工具使用(navicat)
创建新连接,选择 PostgreSQL,点击下一步。端口默认 5432(需在服务器防火墙开放 5432 端口),密码为刚才设置的 postgres 密码。
PostgreSQL 是“数据库 → schema → 表”三级结构,而 MySQL 只有“数据库 → 表”两级结构,schema 相当于数据库内的“子目录”,方便管理多组表。
Navicat 对 PostgreSQL 的 Schema 做了 “默认隐藏” 处理。为了让习惯 MySQL 的用户快速上手,Navicat 会自动展开默认的 public Schema,并将其下的对象直接展示
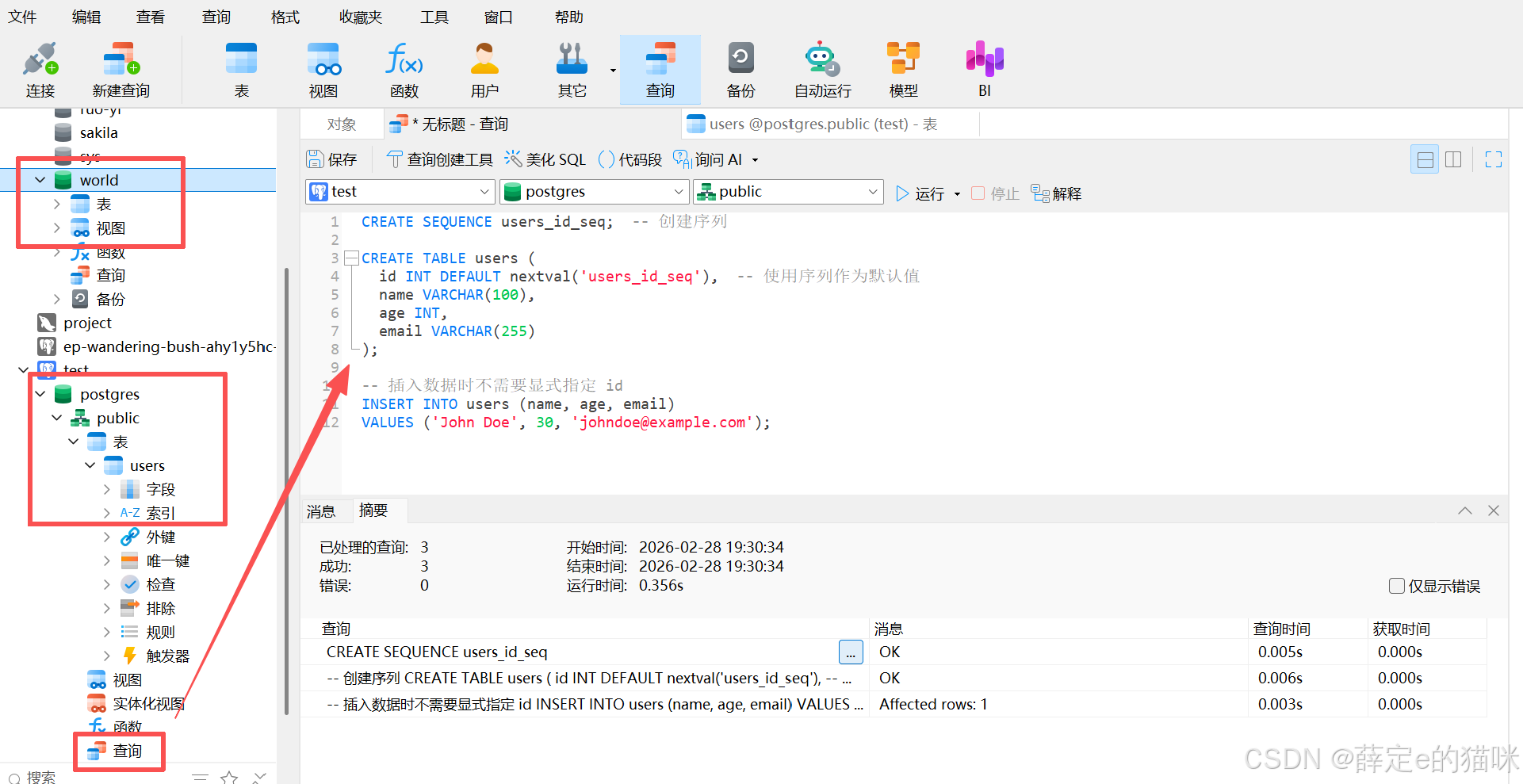
PostgreSQL 内置上百种数据类型,覆盖日常开发所有场景,甚至包含很多 MySQL 没有的特有类型:
- 网络相关:CIDR(存储网段)、inet(IP 地址)、macaddr(Mac 地址),支持直接对网段进行包含查询(用 >> 操作符)。
示例:创建存储网段的表,插入网段数据后,可直接查询包含某个子网的所有网段。
创建一个 network_segments的表,用于存储网络网段信息。 SERIAL 是PostgreSQL的伪数据类型,本质上是一个自增的INTEGER,会自动创建一个序列来生成唯一的整数值。 PRIMARY KEY 表示该列是表的主键,用于唯一标识每一条记录,且不允许为空。
CIDR 是 PostgreSQL 特有的网络地址类型,专门用于存储IPv4或IPv6网段。
CREATE TABLE network_segments (
id SERIAL PRIMARY KEY,
segment CIDR NOT NULL,
description TEXT
);
INSERT INTO network_segments (segment, description)
VALUES ('192.168.1.0/24', '本地局域网');
插入数据:
SELECT * FROM network_segments WHERE segment >> '192.168.1.128/26'::CIDR;
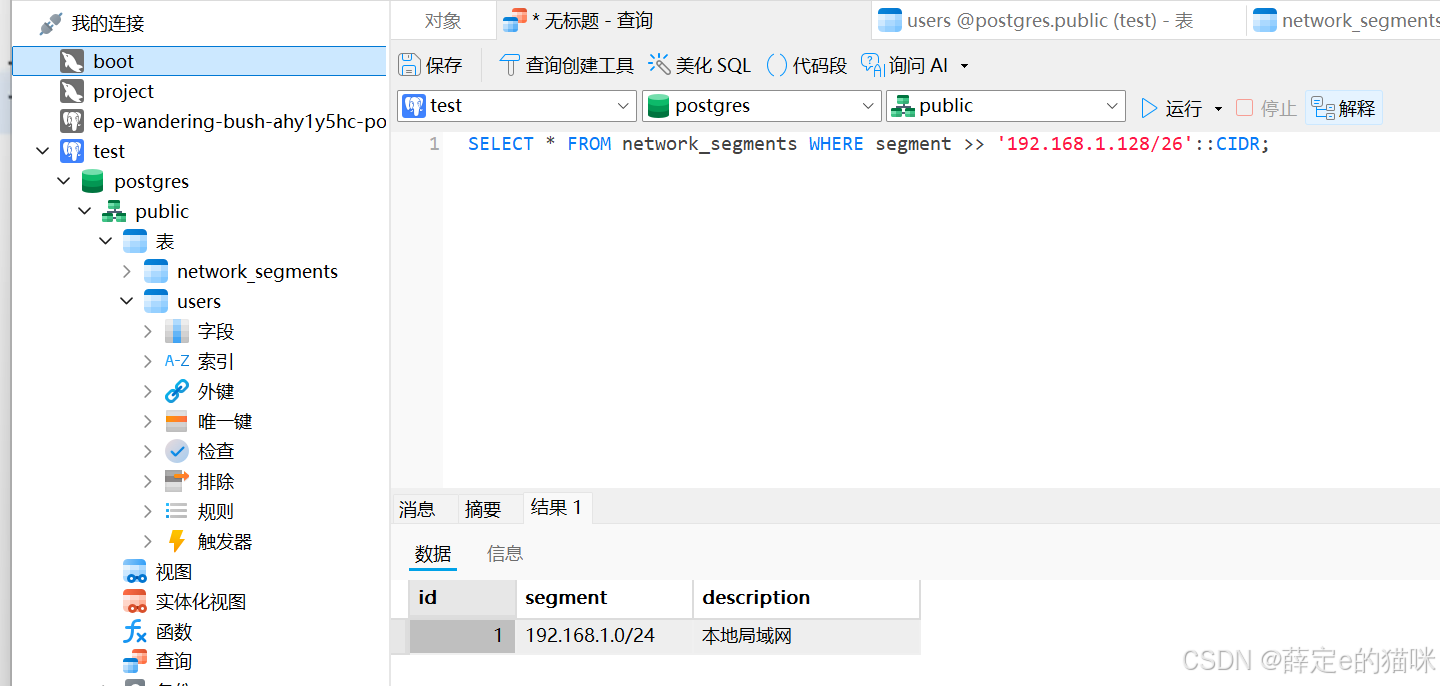
- 自定义类型:用 SQL 语句直接定义自定义对象类型,解决“阻抗失配”问题(避免将复杂对象压扁到二维表格)。
示例:定义 employee 类型(包含 name、age、skills 数组),再创建表时直接使用该类型作为字段,实现复杂对象的高效存储。
创建一个名为 employee 的符合数据类型:
CREATE TYPE employee AS (
name VARCHAR,
age INT,
skills TEXT[]
);
创建表,使用之前定义的复合数据类型employee。
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
employee employee
);
插入数据,构造一个复合employee类型的复合值,ROW()是PostgreSQL复合类型构造器,ARAY构造文本数组,::employee负责显示类型转换:
INSERT INTO employees (employee)
VALUES (
ROW(
'Tech Shrimp',
30,
ARRAY['Excel', 'English']
)::employee
);
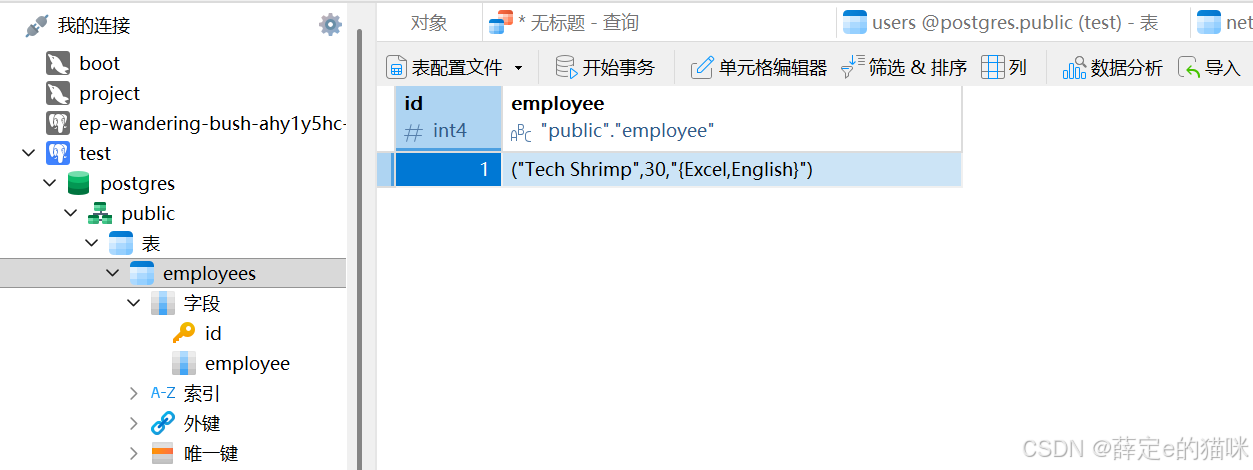
表继承:模拟面向对象的多态性
PostgreSQL 支持表之间的继承关系,完美模拟面向对象编程中的继承特性,更贴合真实业务场景:
示例:创建 developers 表(存储软件开发人员),继承自 employees 表(存储所有员工),developers 表可拥有自己的独特字段(如编程语言),同时继承 employees 表的所有字段。插入 developer 表的数据,会自动同步到父表 employees 中,体现“开发人员首先是员工”的业务逻辑。
利用表继承特性,创建一个名为developers的子表,继承自emplouees表。
CREATE TABLE developers (
programming_language TEXT[]
) INHERITS (employees);
插入数据:
INSERT INTO developers (employee, programming_language)
VALUES (
ROW(
'Rick',
30,
ARRAY['Excel', 'Combat Magi']
)::employee, -- 补全ROW构造器的闭合括号
ARRAY['Python', 'Java']
);
原生支持 JSON 数据
而 PostgreSQL 原生支持 JSON/JSONB 数据类型(推荐用 JSONB,二进制存储,查询效率更高),可直接替代 MongoDB 处理 JSON 文档场景:
创建一个名为message_log的表,用于存储JSON格式的信息日志:
CREATE TABLE message_log (
id SERIAL PRIMARY KEY,
data JSONB
);
插入JSONB数据,记录一条完成的API请求日志:
INSERT INTO message_log (data) VALUES (
'{
"timestamp": "2023-10-27T10:30:05+08:00",
"remote_addr": "192.168.1.10",
"request": "GET /api/v1/products?category=electronics&limit=10 HTTP/1.1",
"status": "200",
"request_data": {
"user": "tech",
"age": 15,
"skill": ["Python", "Java"]
}
}'
);
查询语句:
SELECT * FROM message_log WHERE data->>'remote_addr' = '192.168.1.10';
| 运算符 | 返回类型 | 适用场景 | 示例 |
|---|---|---|---|
| -> | JSONB | 保留 JSON 类型(用于嵌套查询、数组操作) | data->‘request_data’->‘user’ |
| ->> | TEXT | 转为文本(用于等值判断、模糊查询) | data->>‘remote_addr’ = ‘192.168.1.10’ |

是否替代 MongoDB,需结合项目实际场景,PostgreSQL 更适合 JSON 数据与关系型数据混合存储的场景。
全文检索
传统 SQL 的 LIKE 语法无法高效实现全文检索(无法使用索引,只能全表扫描),通常需要部署Elasticsearch,但 PostgreSQL 可通过原生功能,实现高效全文检索,无需额外部署工具:
创建一个documents的表,用于存储文档类文本数据:
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT
);
批量插入多行文本内容:
INSERT INTO documents (content) VALUES
('This guide explains how to use PostgreSQL''s powerful full-text search capabilities.'),
('Learn the basics of database systems and SQL.'),
('Explore advanced SQL features like window functions and common table expressions.');
向 documents 表中添加一个名为 tsv 的新列,数据类型为 TSVECTOR。TSVECTOR 是 PostgreSQL 中用于全文搜索的特殊数据类型
ALTER TABLE documents
ADD COLUMN tsv TSVECTOR
GENERATED ALWAYS AS (to_tsvector('english', content)) STORED;
为 documents 表的全文搜索列 tsv 建立高性能索引:
CREATE INDEX idx_documents_tsv ON documents USING GIN (tsv);
全文搜索查询:
SELECT id, content
FROM documents
WHERE tsv @@ plainto_tsquery('english', 'powerful');

PostgreSQL 与 SQL 的区别
索引设计:架构底层的本质区别
两者基础索引都基于 B+ 树(PostgreSQL 文档称 B-tree,功能等价 B+ 树),但存储架构天差地别。
- MySQL:聚簇索引架构
主键索引为聚簇索引(数据本身按照主键顺序存放在B+树的叶子节点上),叶子节点直接存储完整数据,主键查询效率极高。
二级索引叶子节点仅存主键 ID,查询需回表(二级索引查主键 → 主键索引查数据)。插入数据需按主键顺序调整,易引发数据页分裂,影响写入性能。

- PostgreSQL:堆表 + 全二级索引架构
所有索引都是二级索引,数据独立存储在堆表中,索引叶子节点仅存堆表指针。主键索引与普通索引实现一致,无性能差异。
插入数据直接追加到堆表末尾,避免数据页分裂,写入更稳定。索引与数据分离,扩展性极强,支持 MySQL 没有的高级索引能力。

- PostgreSQL 独有高级索引
- GIN 通用倒排索引

传统索引是从行到值进行查找,而倒排索引建立从值到行的反向映射,适合 JSON、全文检索场景。

基于JSON的倒排索引就是把每行的词项提取出来,记录这些词项在哪行出现过。根据查询的信息,倒排索引能够迅速的定位到行号,对这些行号取一个交集。
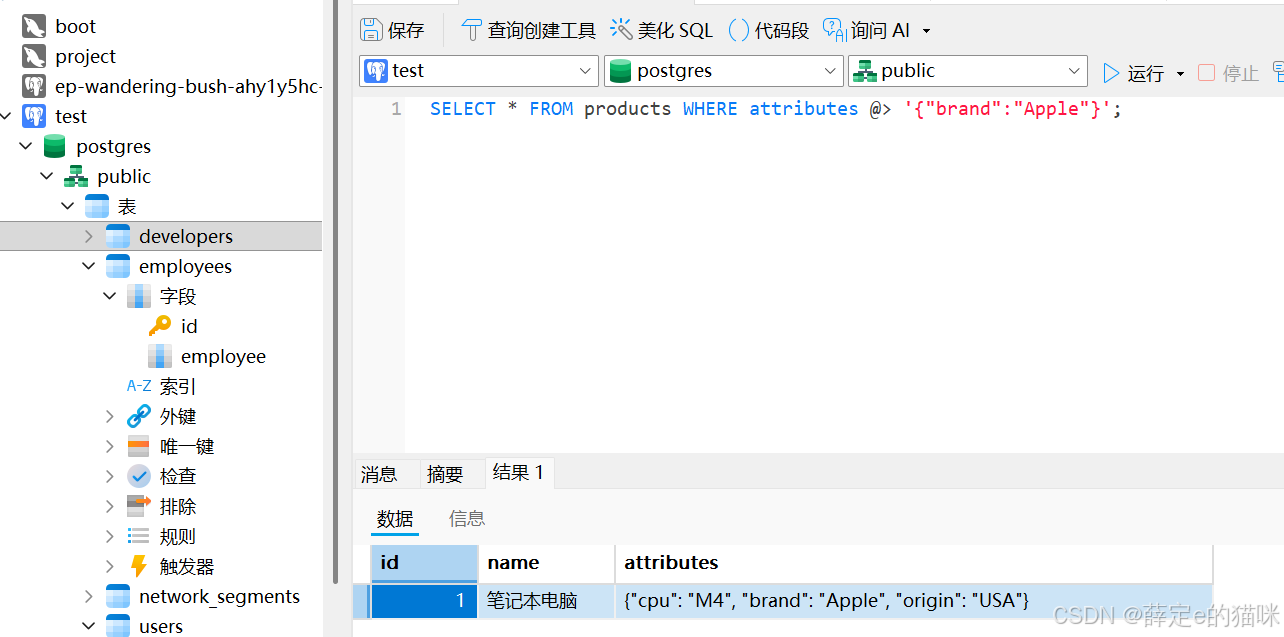
创建products表:
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
attributes JSONB
);
插入商品测试数据:
INSERT INTO products (name, attributes)
VALUES
('笔记本电脑', '{"brand": "Apple", "origin": "USA", "cpu": "M4"}'),
('智能手机', '{"brand": "Xiaomi", "color": "black", "weight_g": 300}'),
('咖啡豆', '{"color": "brown", "origin": "Colombia", "weight_g": 500}');
创建一个名为products_attr_gin的索引,指定索引建立在products表上,指定使用GIN类型索引,指定索引的对象是attributes这一JSONB列。
CREATE INDEX products_attr_gin ON products USING GIN (attributes);
查询JSONB数据:
SELECT * FROM products WHERE attributes @> '{"brand":"Apple"}';
- GiST 通用搜索树
GiST不是具体索引,而是索引扩展框架,任何数据类型只要能够实现GiST要求的接口,就可以利用GiST框架创建索引。
GiST索引非常适合对于非线性数据,比如几何图形,地理位置,IP地址,时间范围等进行是否有重叠,还有距离远近的查询。
GiST索引内部也是平衡树,但是跟B树不同,节点里面存储的不是具体的值,而是一个范围。

创建一个名为project_plan的表:
CREATE TABLE project_plan (
id SERIAL PRIMARY KEY,
plan_period DATERANGE NOT NULL -- DATERANGE 类型表示一个日期范围
);
插入多条日期范围数据
INSERT INTO project_plan (plan_period) VALUES
('[2023-01-01, 2023-01-05)'),
('[2023-01-03, 2023-01-07)'),
('[2023-01-10, 2023-01-12)'),
('[2023-01-08, 2023-01-09)'),
('[2023-01-02, 2023-01-06)');
为DATERANGE类型列创建GiST索引,创建一个名为plan_gist的索引,指定索引建立在project_plan表上,指定使用GiST索引类型,指定索引的对象是plan_period这一DATERANGE列。
GiST 索引可以极大地加速对 DATERANGE 数据的查询操作,例如使用 &&(重叠)、@>(包含)、<@(被包含)等操作符来检查日期范围的关系。
CREATE INDEX plan_gist ON project_plan USING GIST (plan_period);
查询与指定日期范围重叠的项目计划:
SELECT id, plan_period
FROM project_plan
WHERE plan_period && '[2023-01-08, 2023-01-13)'::DATERANGE;

- 部分索引(条件索引)
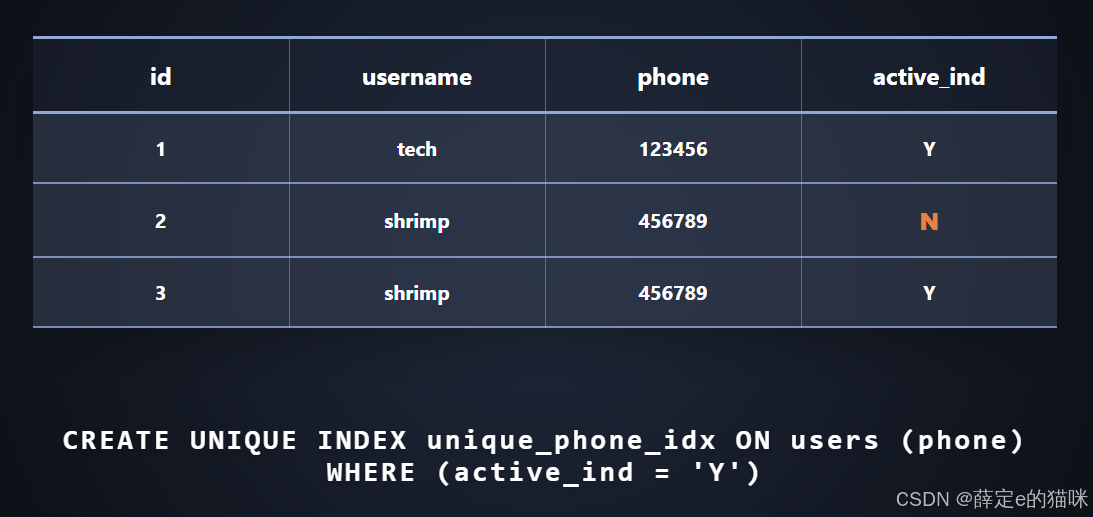
上面图片展示的表中有用户名,电话,active三个字段,如果想删除一个字段,可以把active字段设置成N(逻辑删除)。
有一个需求需要在电话号码这个字段上面建立索引,并且希望电话号码在表里是不重复的(加上unique表示唯一索引)。
现在把ID为2的用户删除掉,但是因为唯一索引的缘故,这个电话号码在表里一直被占用着,没有办法再插入一条跟之前电话号码相同的数据。PostgreSQL应对这种场景会把这个索引变成一个部分索引,这个索引仅对active等于Y的记录生效,被逻辑删除的数据不再纳入索引的管理。
mySQL不支持部分索引,只能使用生成列或者索引表达式的方式变通实现,在磁盘占用还有查询速度方面的表现不如部分索引。
- 表达式索引
直接对计算结果建索引。PostgreSQL 原生支持;
CREATE INDEX users_email_lower ON users ((lower(email)));
SELECT * FROM users WHERE LOWER(email) = 'john.doe@example.com';
数据一致性:
事务是保障数据一致性的核心机制,事务把一系列的操作作为一个整体单元,它们要么全部成功提交,要么全部失败回滚。
在PostgreSQL内部所有关于数据库结构的信息,比如表,表的列,表的索引等等都存储在一系列特殊的系统表里面。
- 比如pg_class存储了表,索引,视图等对象的信息。
- pg_attribute存储了所有表的列的信息。
当我们执行表结构的修改语句(DDL数据库定义语句)时,等同于往几个系统表里面修改几条数据。

建表的操作等同于往系统表里进行了一条插入,所有对表的操作都能被事务管理。
CREATE TABLE products2 (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL
);
SELECT * FROM pg_class WHERE relname = 'products2';
可延迟约束
PostgreSQL 支持:约束检查延迟到事务提交时,可解决唯一性字段互换等 “先有鸡还是先有蛋” 问题。MySQL 无此功能,操作中临时违反约束会直接报错。
事务隔离级别行为差异
PostgreSQL 默认:读已提交(RC),读写行为一致,符合直觉。MySQL 默认:可重复读(RR),存在读写快照不一致问题:同一事务内,SELECT 读旧快照查不到数据,UPDATE 却能修改当前数据。高并发下间隙锁会导致性能退化,大厂实践中通常强制改为 RC 级别。
扩展性
| 扩展点 | MySQL | PostgreSQL |
|---|---|---|
| 存储引擎 | 可插拔(如 InnoDB、MyISAM 等) | 单一引擎(PostgreSQL 原生存储引擎) |
| 自定义数据类型 | 不支持 | 支持(可创建复合、枚举等复杂类型) |
| 自定义函数 | 支持 | 支持 |
| 自定义运算符 | 不支持 | 支持 |
| 自定义索引 | 不支持 | 支持(如 GIN、GiST 等专用索引) |
| 社区插件数量 | 47 | 375 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)