基于claude-code生成本地小数字人
先上效果,后面文档是AI生成的一个完整的 AI 数字人视频生成与交互系统,支持语音合成、图像生成、视频生成、智能对话和联网搜索。: 支持多种大语言模型 (Ollama, OpenAI, 智谱AI等): 实时获取网络信息,支持新闻、天气、知识查询: 使用 Edge-TTS 高质量中文语音合成: 支持云端 API (SiliconFlow, Replicate, Stability AI): 支持语音
AI数字人助手说明文档
1. 环境说明
1.1 运行环境概述
AI数字人助手系统采用前后端分离架构,需要以下运行环境支持:
|
环境类型 |
组件名称 |
版本要求 |
用途说明 |
|
后端运行环境 |
Python |
3.9+ |
核心服务运行环境,提供API服务 |
|
前端运行环境 |
Chrome/Edge |
最新版 |
浏览器扩展运行环境 |
|
AI推理环境 |
CUDA |
11.8+ |
GPU加速,用于本地模型推理(可选) |
|
本地模型环境 |
Ollama |
0.1.26+ |
本地大模型运行环境 |
|
开发环境 |
Node.js |
16+ |
前端开发构建(可选) |
1.2 Python环境依赖包
1.2.1 核心依赖包
|
依赖包名称 |
版本 |
角色 |
使用场景 |
说明 |
|
fastapi |
0.100+ |
Web框架 |
API服务路由处理 |
高性能异步Web框架,支持自动文档生成 |
|
uvicorn |
0.23+ |
ASGI服务器 |
异步HTTP服务 |
提供高性能的异步HTTP服务 |
|
httpx |
0.24+ |
HTTP客户端 |
API请求转发 |
支持HTTP/2的异步HTTP客户端 |
|
pyyaml |
6.0+ |
配置解析 |
读取YAML配置文件 |
解析settings.yaml和api_keys.yaml |
|
loguru |
0.7+ |
日志管理 |
系统日志记录 |
提供结构化日志输出 |
1.2.2 AI模型相关依赖
|
依赖包名称 |
版本 |
角色 |
使用场景 |
说明 |
|
torch |
2.0+ |
深度学习框架 |
Fara模型推理 |
PyTorch深度学习框架 |
|
transformers |
4.37+ |
NLP库 |
Fara模型加载 |
HuggingFace Transformers库 |
|
accelerate |
0.25+ |
模型加速 |
模型推理优化 |
提供模型加载和推理加速 |
|
ollama |
0.1.0+ |
Ollama客户端 |
本地LLM调用 |
Python Ollama客户端库 |
1.2.3 语音处理依赖
|
依赖包名称 |
版本 |
角色 |
使用场景 |
说明 |
|
edge-tts |
6.1+ |
语音合成 |
TTS服务 |
微软Edge TTS免费语音合成 |
|
openai-whisper |
202311+ |
语音识别 |
STT服务 |
OpenAI Whisper本地语音识别 |
|
pyaudio |
0.2.13+ |
音频录制 |
音频输入 |
Python音频I/O库 |
1.2.4 文档处理依赖
|
依赖包名称 |
版本 |
角色 |
使用场景 |
说明 |
|
python-pptx |
0.6+ |
PPT操作 |
PPT文档生成 |
创建和编辑PowerPoint文件 |
|
python-docx |
1.1+ |
Word操作 |
Word文档生成 |
创建和编辑Word文件 |
|
openpyxl |
3.1+ |
Excel操作 |
Excel文档生成 |
创建和编辑Excel文件 |
|
reportlab |
4.0+ |
PDF生成 |
PDF文档生成 |
Python PDF生成库 |
|
Pillow |
10.0+ |
图像处理 |
图像编辑和转换 |
Python图像库 |
1.3 浏览器扩展环境
1.3.1 Chrome扩展API
|
API名称 |
角色 |
使用场景 |
|
chrome.runtime |
扩展运行时 |
消息通信、扩展生命周期管理 |
|
chrome.storage |
数据存储 |
用户配置存储、会话信息缓存 |
|
chrome.tabs |
标签页管理 |
获取当前标签页信息 |
|
chrome.contextMenus |
右键菜单 |
添加右键菜单快捷操作 |
1.3.2 前端技术栈
|
技术/库 |
版本 |
角色 |
使用场景 |
|
HTML5 |
- |
页面结构 |
对话界面、悬浮球UI |
|
CSS3 |
- |
样式设计 |
界面美化、动画效果 |
|
JavaScript ES6+ |
- |
交互逻辑 |
消息处理、音频录制 |
|
Web Audio API |
- |
音频处理 |
录音、音频播放 |
1.4 硬件环境要求
|
硬件组件 |
最低要求 |
推荐配置 |
说明 |
|
CPU |
4核 |
8核+ |
影响整体服务性能 |
|
内存 |
8GB |
16GB+ |
运行多个模型时需要更多内存 |
|
GPU |
- |
NVIDIA 8GB+ VRAM |
本地模型推理加速(Fara-7B需要) |
|
存储 |
10GB |
50GB+ |
模型文件和输出文件存储 |
1.5 环境配置检查
检查脚本示例:
# 检查Python版本
python --version # 需要 3.9+
# 检查CUDA是否可用(可选)
python -c "import torch; print(torch.cuda.is_available())"
# 检查Ollama服务
curl http://localhost:11434/api/tags
# 检查依赖包
pip list | grep -E "fastapi|torch|transformers"
2. 功能点说明
2.1 业务功能

2.1.1 智能对话功能
功能描述:
- 支持多轮自然语言对话
- 支持上下文记忆和会话管理
- 支持多模型切换(Ollama/DeepSeek/OpenAI)
- 支持流式响应(SSE实时推送)
配置说明:
配置文件:config/settings.yaml
- llm.provider:选择主模型提供商
- llm.call_mode:调用模式(ollamaAPI/zeroToken/deepseekAPI)
- llm.ollama.model:Ollama模型名称
操作说明:
1. 点击浏览器扩展悬浮球打开对话窗口
2. 在输入框输入问题,或点击麦克风使用语音输入
3. AI助手实时返回回复内容
4. 支持复制回复内容、语音播报等操作
快捷操作:
- Ctrl+Enter:发送消息
- Esc:关闭对话窗口
- 点击麦克风图标:开始语音输入

2.1.2 文档生成功能
功能描述:
- 支持多种文档格式生成(Word/PPT/Excel/PDF/Markdown)
- 支持自动生成文档大纲和内容
- 支持为PPT自动生成配图
- 支持文档模板和样式定制
支持文档类型:
|
文档类型 |
文件格式 |
适用场景 |
特点 |
|
Word文档 |
.docx |
报告、计划、文章 |
支持标题层级、段落格式 |
|
PowerPoint |
.pptx |
演示文稿、课件 |
自动配图、主题样式 |
|
Excel表格 |
.xlsx |
数据表格、统计表 |
自动列宽、表头格式 |
|
PDF文档 |
|
正式文档、合同 |
中文字体支持 |
|
Markdown |
.md |
技术文档、笔记 |
轻量级标记格式 |
操作说明:
1. 输入指令,如:'帮我生成一份项目计划书PPT'
2. 系统自动识别文档类型
3. 调用LLM生成文档内容结构
4. (可选)自动生成配图
5. 输出文档文件并提供下载链接
使用示例:
用户输入:帮我生成一份关于AI技术的PPT,需要配图
系统处理:
1. 识别文档类型:PPT
2. 生成PPT大纲(5-12页)
3. 为每张幻灯片生成配图
4. 输出PPT文件
返回:outputs/documents/AI技术演示.pptx


2.1.3 图像生成功能
功能描述:
- 支持文字生成图像(文生图)
- 支持多种图像风格和尺寸
- 支持批量生成图像
- 支持图像编辑和优化
支持模型:
|
提供商 |
模型名称 |
特点 |
适用场景 |
|
SiliconFlow |
Qwen/Qwen-Image |
中文理解强 |
通用图像生成 |
|
SiliconFlow |
Kwai-Kolors/Kolors |
细节丰富 |
高质量图像 |
|
Replicate |
flux-dev |
专业级质量 |
专业创作 |
|
Stability AI |
stable-diffusion |
经典模型 |
多样化风格 |
配置说明:
配置文件:config/credentials/api_keys.yaml
- image.provider:图像生成提供商
- image.siliconflow.api_key:SiliconFlow API密钥
- image.siliconflow.base_url:API地址
操作说明:
1. 输入图像描述,如:'生成一张日落海滩的图片'
2. 系统自动选择配置的图像生成服务
3. 调用图像生成API
4. 下载并保存图像到 outputs/images/
5. 返回图像路径或显示图像
图像规格:
- 默认尺寸:1024x1024
- 支持尺寸:512x512, 768x768, 1024x1024, 1536x1536, 2048x2048
- 支持格式:PNG, JPG, WEBP
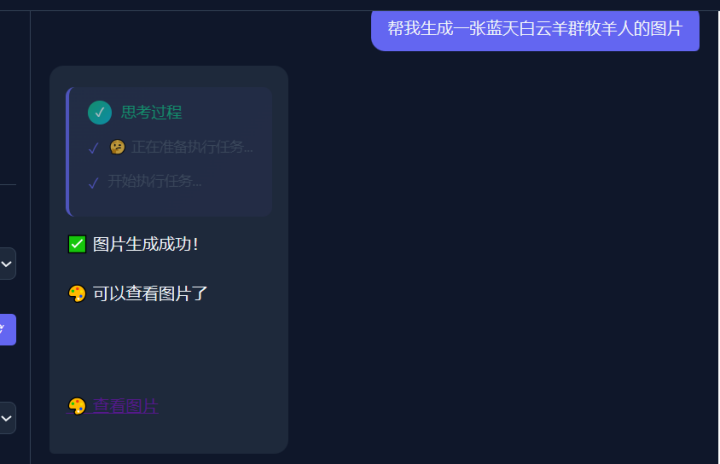

2.1.4 视频生成功能
功能描述:
- 支持文本生成视频(文生视频)
- 支持图像生成视频(图生视频)
- 支持数字人视频生成
- 支持视频预览和下载
支持视频类型:
|
类型 |
模型 |
说明 |
输出格式 |
|
文本转视频 |
Wan-AI/Wan2.2-T2V |
文字描述生成视频 |
MP4 |
|
图像转视频 |
Wan-AI/Wan2.2-I2V |
静态图片转动态视频 |
MP4 |
|
数字人视频 |
SadTalker |
语音驱动数字人 |
MP4 |
|
动画生成 |
AnimateDiff |
动画视频(本地GPU) |
MP4 |
视频规格:
- 默认分辨率:1280x720 (720p)
- 帧率:24fps
- 时长:根据模型支持(通常4-16秒)



2.1.5 网络操作功能(Fara-7B)⭐
功能描述:
- 支持计算机自动化操作(点击、输入、按键等)
- 支持网页自动浏览和操作
- 支持信息提取和数据采集
- 支持复杂任务规划和执行
核心特性:
- ��️ 视觉理解:基于屏幕截图理解当前界面
- �� 智能决策:自主决定操作步骤
- �� 任务回退:Fara不可用时回退到LLM提供建议
- �� 预定义任务:支持常见任务的快捷执行
支持的网络操作:
|
任务类型 |
描述 |
示例 |
|
网页搜索 |
自动搜索指定内容 |
在百度搜索:人工智能最新进展 |
|
打开网站 |
打开指定URL |
打开 https://github.com |
|
填写表单 |
自动填写网页表单 |
在当前页面填写注册表单 |
|
下载文件 |
从网页下载文件 |
下载最新版本的安装包 |
|
自动登录 |
自动填写登录信息 |
登录网站,用户名:xxx |
|
数据提取 |
从网页提取信息 |
提取页面中的所有邮箱地址 |
|
滚动阅读 |
自动滚动阅读内容 |
向下滚动阅读文章 |
|
自定义任务 |
任意计算机操作 |
帮我整理桌面文件 |
配置说明:
- 模型路径:E:\AI\models\fara(可配置)
- 硬件要求:NVIDIA GPU 8GB+ VRAM(推荐)
- 回退模型:配置的LLM(Ollama/DeepSeek/OpenAI)
API调用示例:
POST /api/fara/execute
{
"task": "在百度搜索AI技术",
"context": "可选的上下文信息"
}
// 响应
{
"success": true,
"response": "操作步骤说明...",
"actions": [
{"type": "open_url", "url": "https://www.baidu.com"},
{"type": "input", "text": "AI技术"},
{"type": "key", "key": "Enter"}
],
"fallback_used": false
}
2.1.6 语音交互功能
语音识别(STT):
|
模型 |
特点 |
适用场景 |
语言支持 |
|
Whisper-tiny |
快速识别 |
快速转写 |
多语言 |
|
Whisper-base |
平衡性能 |
日常转写 |
多语言 |
|
Whisper-medium |
高精度 |
专业转写 |
多语言 |
|
Whisper-large |
最高精度 |
专业场景 |
多语言 |
|
Whisper API |
云端服务 |
无需本地部署 |
多语言 |
语音合成(TTS):
|
服务/模型 |
音色 |
特点 |
语言支持 |
|
Edge-TTS |
晓晓(女声) |
自然流畅 |
中文 |
|
Edge-TTS |
云希(男声) |
自然流畅 |
中文 |
|
Edge-TTS |
Jenny |
自然流畅 |
英文 |
2.2 配置功能
2.2.1 模型配置
主配置文件:config/settings.yaml
|
配置项 |
说明 |
可选值 |
默认值 |
|
llm.provider |
主模型提供商 |
ollama/openai/deepseek |
ollama |
|
llm.call_mode |
调用模式 |
ollamaAPI/zeroToken/deepseekAPI |
ollamaAPI |
|
llm.ollama.model |
Ollama模型 |
qwen2.5:7b, llama3:8b等 |
qwen2.5:7b |
|
stt.provider |
语音识别提供商 |
whisper/azure/baidu |
whisper |
|
tts.provider |
语音合成提供商 |
edge-tts |
edge-tts |
|
image.provider |
图像生成提供商 |
siliconflow/replicate/stability |
siliconflow |
|
video.provider |
视频生成提供商 |
siliconflow |
siliconflow |
2.2.2 凭证配置
凭证配置文件:config/credentials/api_keys.yaml
⚠️ 重要提示:
此文件包含敏感信息,已添加到 .gitignore
请勿提交到版本控制系统
首次使用请复制 api_keys.example.yaml 并填写API Keys
- 智能体梳理
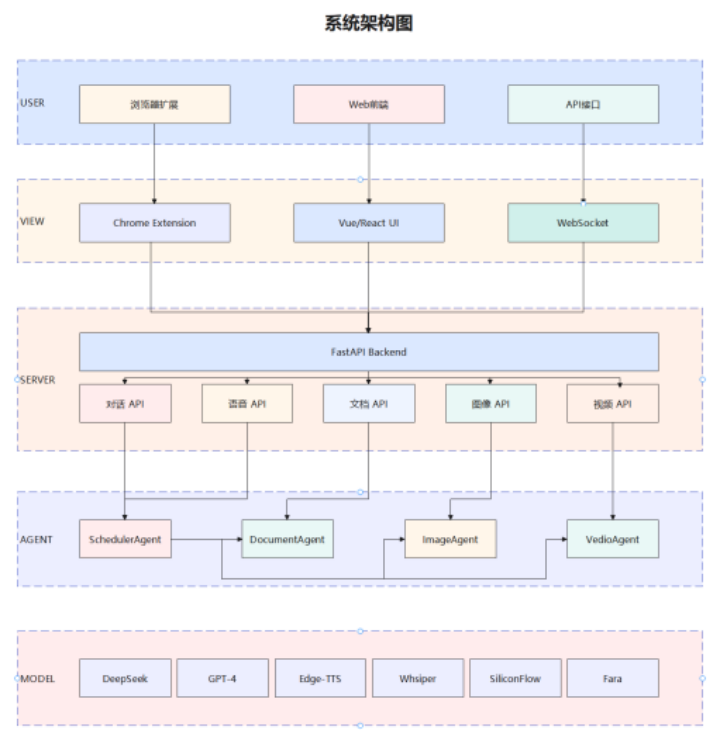
3.1 智能体架构总览
系统采用多智能体架构,通过SchedulerAgent进行统一调度:
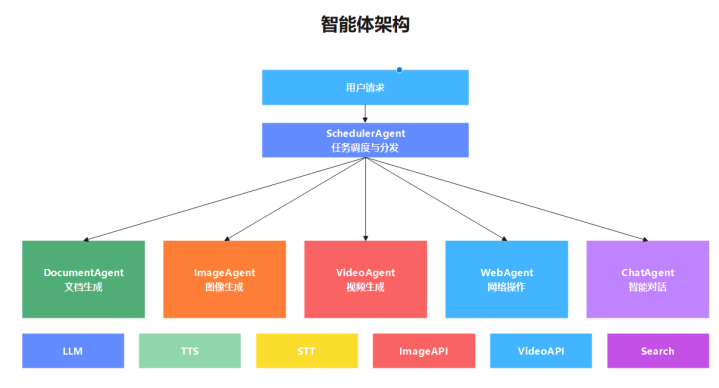
3.2 SchedulerAgent(调度智能体)
|
属性 |
说明 |
|
类型 |
scheduler |
|
描述 |
核心调度器,负责意图识别和智能体分发 |
|
文件位置 |
core/scheduler_agent.py |
|
核心能力 |
意图识别、智能体选择、任务协调、多智能体协作 |
工作原理:
步骤1:意图识别 - 基于关键词匹配和语义分析识别用户意图
步骤2:智能体分发 - 根据识别的意图选择对应的智能体
步骤3:执行任务 - 调用智能体执行任务并返回结果
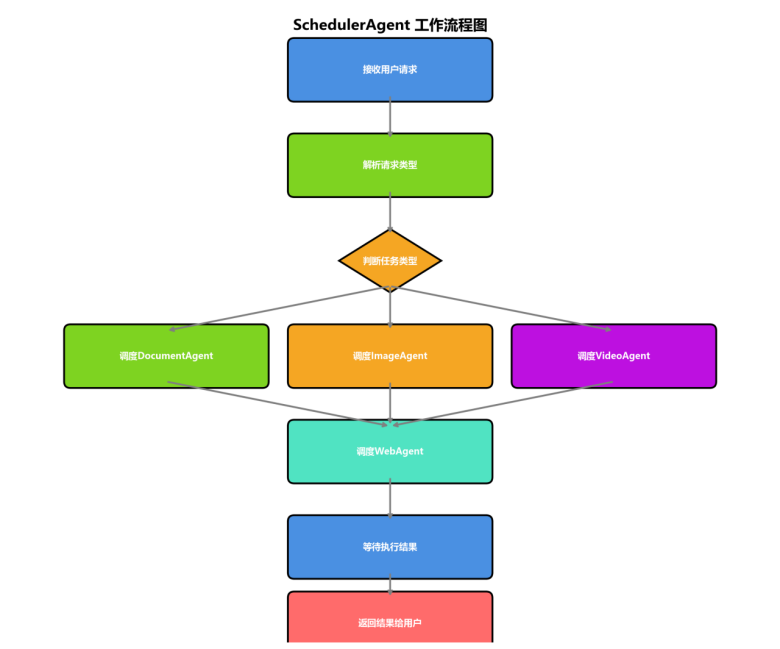
3.3 DocumentAgent(文档智能体)
|
属性 |
说明 |
|
类型 |
document |
|
描述 |
文档生成智能体,支持生成Word、Excel、PPT、PDF等格式文档 |
|
文件位置 |
core/agents/document_agent.py |
|
核心能力 |
文档生成、内容创作、格式转换、文档解析 |
工作技能:
- 技能1:文档类型识别 - 自动识别用户需要的文档类型
- 技能2:内容生成 - 调用LLM生成文档大纲和章节内容
- 技能3:文档格式化 - 应用预设样式和主题
- 技能4:配图生成 - 为PPT自动生成配图
模型交互:
- 交互点1:内容生成 - 调用LLM生成文档内容
- 交互点2:配图生成 - 调用ImageAgent生成插图
- 交互点3:文档解析 - 上传文档后调用LLM进行分析和问答
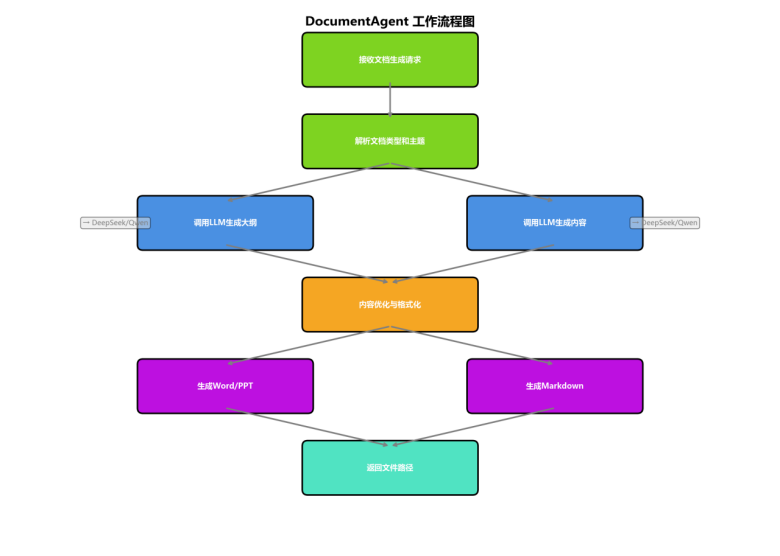
3.4 ImageAgent(图像智能体)
|
属性 |
说明 |
|
类型 |
image |
|
描述 |
图像生成智能体,支持文字生成图像、图像编辑、视觉问答 |
|
文件位置 |
core/agents/image_agent.py |
|
核心能力 |
文生图、图生图、图像编辑、视觉理解 |
工作技能:
- 技能1:提示词理解 - 解析用户的图像描述
- 技能2:模型选择 - 根据配置选择图像生成模型
- 技能3:图像生成 - 调用图像生成API
- 技能4:图像处理 - 图像缩放和裁剪、格式转换
模型交互:
- 交互点1:图像生成API调用 - 调用SiliconFlow/Replicate/Stability API
- 交互点2:视觉理解 - 调用OpenAI Vision API进行图片理解
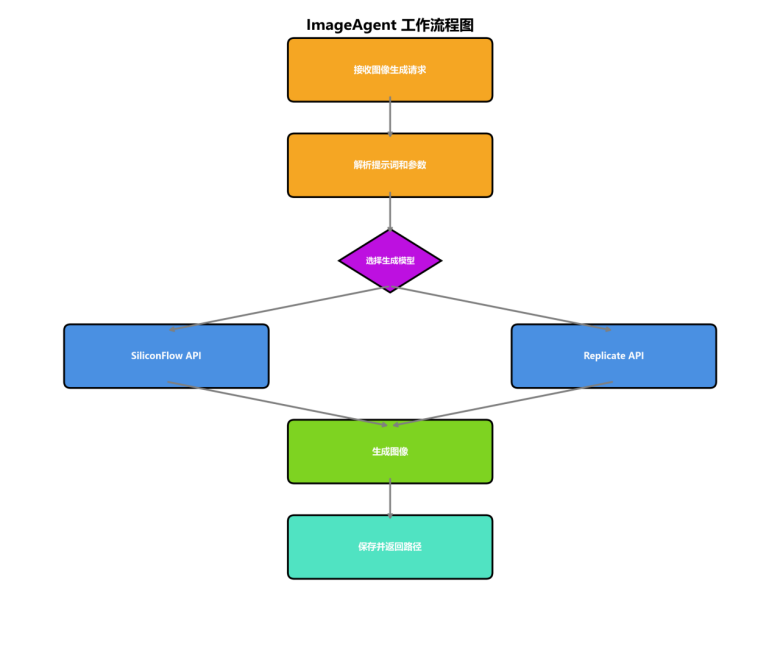
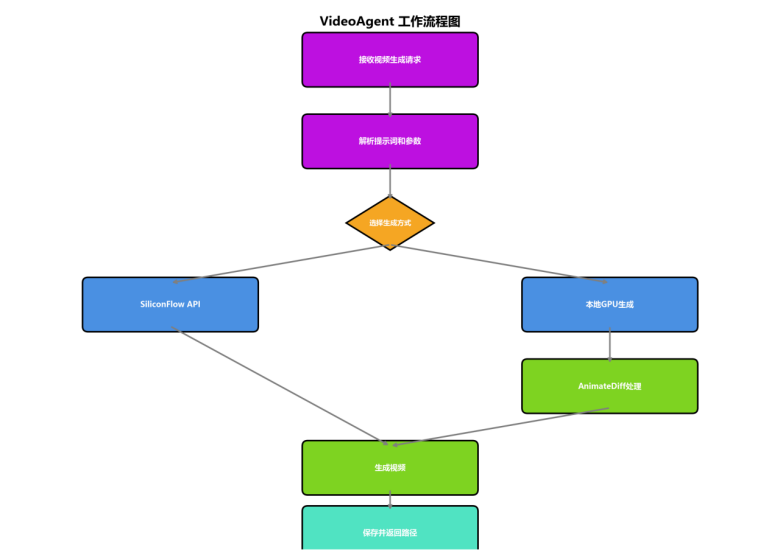
3.5 VideoAgent(视频智能体)
|
属性 |
说明 |
|
类型 |
video |
|
描述 |
视频生成智能体,支持文本生成视频、图像生成视频、数字人视频 |
|
文件位置 |
core/agents/video_agent.py |
|
核心能力 |
文生视频、图生视频、数字人视频 |
工作技能:
- 技能1:视频类型识别 - 识别用户需要的视频类型
- 技能2:视频生成 - 调用云端视频生成API或本地GPU
- 技能3:视频处理 - 视频格式转换、压缩和优化
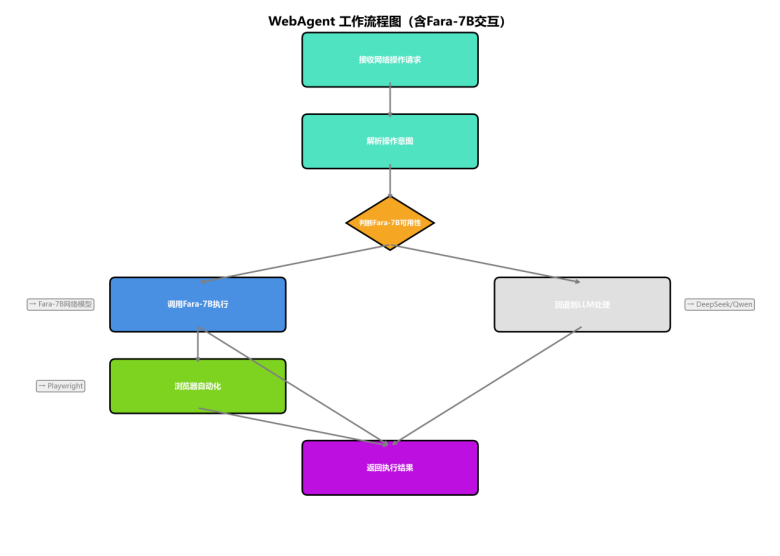
3.6 WebAgent(网络智能体)+ Fara-7B ⭐
|
属性 |
说明 |
|
类型 |
web |
|
描述 |
网络操作智能体,支持网页搜索、浏览、数据提取、自动填表等 |
|
文件位置 |
core/agents/web_agent.py |
|
核心能力 |
网络搜索、信息提取、网页自动化、计算机操作 |
|
特殊能力 |
Fara-7B模型驱动的智能网络操作 |
工作技能:
- 技能1:搜索引擎操作 - 支持多搜索引擎
- 技能2:网页浏览 - 打开指定URL、自动滚动阅读
- 技能3:表单操作 - 自动填写表单、提交表单、登录操作
- 技能4:数据提取 - 提取页面文本内容、链接和图片
- 技能5:Fara智能操作 - 视觉理解屏幕内容、智能决策操作步骤
Fara-7B模型交互原理
Fara-7B是微软专门为计算机操作设计的视觉语言模型(VLM),基于Qwen2.5-VL架构:
|
组件 |
功能 |
|
视觉编码器 |
处理屏幕截图,提取UI元素特征 |
|
语言模型 |
Qwen2.5-VL-7B,理解任务描述并生成操作指令 |
|
操作解析器 |
将模型输出解析为具体操作(坐标、按键、输入等) |
Fara工作流程:
1. 任务理解:用户输入 → 自然语言理解 → 任务分解
2. 视觉感知:屏幕截图 → 图像编码 → 理解当前界面
3. 决策生成:任务+视觉 → Transformer推理 → 操作指令
4. 执行与反馈:操作指令 → 执行动作 → 观察结果 → 循环
回退机制:
当Fara-7B模型不可用时,系统自动回退到配置的LLM(Ollama/DeepSeek/OpenAI),提供操作建议而非自动执行。
4. 模型梳理
4.1 模型统一管理 ⭐
所有模型的URL和API Key统一在 config/credentials/api_keys.yaml 中配置:
- ✅ 统一管理,方便切换模型服务
- ✅ 支持代理地址配置
- ✅ API Key和URL分离,安全可控
- ✅ 支持多服务商备份
4.2 大语言模型(LLM)
4.2.1 Ollama本地模型
|
模型名称 |
参数规模 |
应用场景 |
特点 |
硬件要求 |
|
qwen2.5:7b |
7B |
通用对话、代码生成 |
中文能力强 |
8GB RAM |
|
qwen2.5:14b |
14B |
复杂推理、专业任务 |
性能优秀 |
16GB RAM |
|
llama3:8b |
8B |
轻量对话、快速响应 |
低资源消耗 |
8GB RAM |
|
mistral:7b |
7B |
英文对话、推理 |
英文能力强 |
8GB RAM |
|
codellama:7b |
7B |
代码生成、代码补全 |
代码专精 |
8GB RAM |
4.2.2 DeepSeek API
|
模型名称 |
应用场景 |
特点 |
价格 |
|
deepseek-chat |
通用对话、推理 |
中文能力强、推理能力优秀 |
¥1/百万token |
|
deepseek-reasoner |
复杂推理任务 |
带推理过程展示 |
¥2/百万token |
4.2.3 OpenAI API
|
模型名称 |
应用场景 |
特点 |
价格 |
|
gpt-4o-mini |
通用对话、简单任务 |
响应快速、成本低 |
$0.15/1M tokens |
|
gpt-4o |
复杂任务、专业应用 |
性能强大 |
$2.5/1M tokens |
|
gpt-4-turbo |
专业应用、代码生成 |
高性能 |
$10/1M tokens |
4.3 Fara-7B 网络操作模型 ⭐
|
属性 |
说明 |
|
模型名称 |
Fara-7B (Qwen2.5-VL) |
|
开发者 |
Microsoft |
|
模型类型 |
视觉语言模型 (VLM) |
|
参数规模 |
7B |
|
应用场景 |
计算机自动化操作、网页交互、任务执行 |
|
许可协议 |
MIT License |
支持的操作类型:
|
操作类型 |
格式 |
说明 |
|
点击 |
{"type": "click", "x": 100, "y": 200} |
鼠标点击指定坐标 |
|
输入 |
{"type": "input", "text": "文本"} |
输入文本内容 |
|
按键 |
{"type": "key", "key": "Enter"} |
按下指定按键 |
|
滚动 |
{"type": "scroll", "direction": "down"} |
滚动页面 |
|
等待 |
{"type": "wait", "seconds": 3} |
等待指定秒数 |
|
打开URL |
{"type": "open_url", "url": "..."} |
打开指定网页 |
配置要求:
- 硬件要求:GPU:NVIDIA GPU with 8GB+ VRAM(推荐)
- CPU:可运行但速度较慢
- RAM:16GB+
- 软件要求:Python 3.9+、PyTorch 2.0+、Transformers 4.37+
性能特点:
- ✅ 支持复杂多步骤任务
- ✅ 基于视觉理解的智能决策
- ✅ 自然语言指令控制
- ⚠️ 需要GPU加速(推荐8GB+显存)
- ⚠️ 首次加载较慢(约1-2分钟)
4.4 语音合成模型(TTS)
|
音色名称 |
语言 |
性别 |
特点 |
使用场景 |
|
zh-CN-XiaoxiaoNeural |
中文 |
女 |
自然流畅、甜美 |
中文女声播报 |
|
zh-CN-YunxiNeural |
中文 |
男 |
自然流畅、磁性 |
中文男声播报 |
|
zh-CN-YunjianNeural |
中文 |
男 |
新闻播报风格 |
专业播报 |
|
en-US-JennyNeural |
英文 |
女 |
自然流畅 |
英文播报 |
|
en-US-GuyNeural |
英文 |
男 |
自然流畅 |
英文播报 |
4.5 语音识别模型(STT)
4.5.1 Whisper本地模型
|
模型大小 |
参数量 |
速度 |
精度 |
内存占用 |
使用场景 |
|
tiny |
39M |
最快 |
较低 |
~1GB |
快速转写 |
|
base |
74M |
快 |
中等 |
~1GB |
日常转写 |
|
small |
244M |
中等 |
较高 |
~2GB |
标准转写 |
|
medium |
769M |
较慢 |
高 |
~5GB |
高精度转写 |
|
large |
1550M |
慢 |
最高 |
~10GB |
专业转写 |
4.6 图像生成模型
|
提供商 |
模型名称 |
特点 |
分辨率 |
价格 |
使用场景 |
|
SiliconFlow |
Qwen/Qwen-Image |
中文理解强 |
1024x1024 |
¥0.02/张 |
通用图像生成 |
|
SiliconFlow |
Kwai-Kolors/Kolors |
细节丰富 |
1024x1024 |
¥0.03/张 |
高质量图像 |
|
SiliconFlow |
stable-diffusion-3 |
专业级 |
1024x1024 |
¥0.05/张 |
专业创作 |
|
Replicate |
flux-dev |
专业级质量 |
1024x1024 |
$0.025/张 |
专业创作 |
|
Replicate |
flux-schnell |
快速生成 |
1024x1024 |
$0.003/张 |
快速原型 |
4.7 视频生成模型
|
提供商 |
模型名称 |
类型 |
分辨率 |
时长 |
价格 |
使用场景 |
|
SiliconFlow |
Wan2.2-T2V |
文生视频 |
1280x720 |
4-6秒 |
¥0.5/次 |
文字生成视频 |
|
SiliconFlow |
Wan2.2-I2V |
图生视频 |
1280x720 |
4-6秒 |
¥0.5/次 |
图片生成视频 |
|
AnimateDiff |
v3 |
动画生成 |
可变 |
可变 |
免费 |
本地GPU动画 |
5. 配置说明
5.1 配置文件结构
config/
├── settings.yaml # 功能配置(模型选择、参数设置)
└── credentials/
├── api_keys.yaml # 统一的URL和API Key配置 ⭐
└── api_keys.example.yaml # 配置示例
5.2 主配置文件详解
文件:config/settings.yaml
llm:
provider: "ollama" # 主提供商
call_mode: "ollamaAPI" # 调用模式
ollama:
model: "qwen2.5:7b"
timeout: 60
openai:
model: "gpt-4o-mini"
deepseek:
model: "deepseek-chat"
tts:
provider: "edge-tts"
edge_tts:
voice: "zh-CN-XiaoxiaoNeural"
rate: "+0%"
stt:
provider: "whisper"
whisper:
model: "base"
language: "zh"
use_api: false
image:
provider: "siliconflow"
video:
provider: "siliconflow"
5.3 凭证配置文件详解
文件:config/credentials/api_keys.yaml
llm:
ollama:
base_url: "http://localhost:11434"
openai:
api_key: "your-openai-api-key"
base_url: "https://api.openai.com/v1"
deepseek:
api_key: "your-deepseek-api-key"
base_url: "https://api.deepseek.com/v1"
image:
siliconflow:
api_key: "your-siliconflow-api-key"
base_url: "https://api.siliconflow.cn/v1"
video:
siliconflow:
api_key: "your-siliconflow-api-key"
base_url: "https://api.siliconflow.cn/v1"
speech:
whisper:
api_key: "your-openai-api-key"
base_url: "https://api.openai.com/v1"
6. 附录
6.1 API端点列表
|
端点 |
方法 |
说明 |
智能体 |
|
/api/chat |
POST |
对话接口 |
ChatAgent |
|
/api/chat/audio |
POST |
语音对话 |
ChatAgent |
|
/api/tts |
POST |
语音合成 |
- |
|
/api/stt |
POST |
语音识别 |
- |
|
/api/document/generate |
POST |
文档生成 |
DocumentAgent |
|
/api/image/generate |
POST |
图像生成 |
ImageAgent |
|
/api/video/text-to-video |
POST |
文生视频 |
VideoAgent |
|
/api/video/image-to-video |
POST |
图生视频 |
VideoAgent |
|
/api/search |
POST |
网络搜索 |
WebAgent |
|
/api/fara/execute |
POST |
Fara网络操作 ⭐ |
WebAgent+Fara |
|
/api/fara/tasks |
GET |
Fara预定义任务 |
- |
|
/api/fara/status |
GET |
Fara模型状态 |
- |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)