【117页PPT】大数据实时流处理场景化解决方案:技术框架与项目实战、四大核心组件(Flume、Kafka、Flink、Structured Streaming)
定义:数据从生成、采集、缓存、计算到落地与展示的全流程在秒级甚至毫秒级内完成。核心价值:数据的价值随时间迅速衰减,实时处理能更快提供洞察,支撑业务决策。。核心能力:实时采集、低延迟计算、高可靠传输、灵活存储技术栈整合:Flume + Kafka + Flink + Structured Streaming + Redis 构建完整实时流处理链路业务价值:支撑实时大屏、实时风控、实时推荐等场景未来方
该培训方案系统介绍了大数据实时流处理的场景化解决方案,涵盖技术框架与项目实战。方案首先阐述了实时处理的意义(秒级响应、价值时效性)及核心诉求(高吞吐、低延迟、可靠性、水平扩展)。
随后详细讲解了四大核心组件:Flume(日志采集与聚合)、Kafka(高吞吐消息队列)、Flink(流批一体计算引擎,支持事件时间、窗口、CEP、Exactly-once容错)与Structured Streaming(基于Spark SQL的微批/持续处理模型),并辅以Redis作为高速缓存与结果存储。最后通过电商交易统计实战案例(实时总销售额与Top10商品统计),完整演示了从数据采集、消息队列、流式计算到结果存储与可视化的全链路技术整合方案。
相关参考资料合集:

一、大数据实时流处理概述
1.1 什么是数据实时处理?
-
定义:数据从生成、采集、缓存、计算到落地与展示的全流程在秒级甚至毫秒级内完成。
-
核心价值:数据的价值随时间迅速衰减,实时处理能更快提供洞察,支撑业务决策。
1.2 实时处理与其他解决方案的关系
-
六大类处理场景:
-
离线处理
-
实时流处理
-
交互查询
-
实时检索
-
数据迁移
-
数据容灾备份
-
1.3 业务场景示例:信用卡反欺诈
-
流程:交易渠道 → 欺诈识别(清洗、特征提取、神经网络/规则判断)→ 实时拦截 → 主机账务处理
-
核心诉求:实时采集、实时分析、实时应对
1.4 实时数据处理系统的核心诉求
-
处理速度快:秒级响应,单节点TPS > 2000
-
吞吐量高:数十MB/秒/节点
-
可靠性高:数据不丢失、不重复
-
水平扩展:支持节点扩展提升性能
-
多数据源支持:文件、网络流、数据库、IOT等
-
权限与资源隔离:多租户支持
-
第三方工具对接:规则引擎、推荐系统等
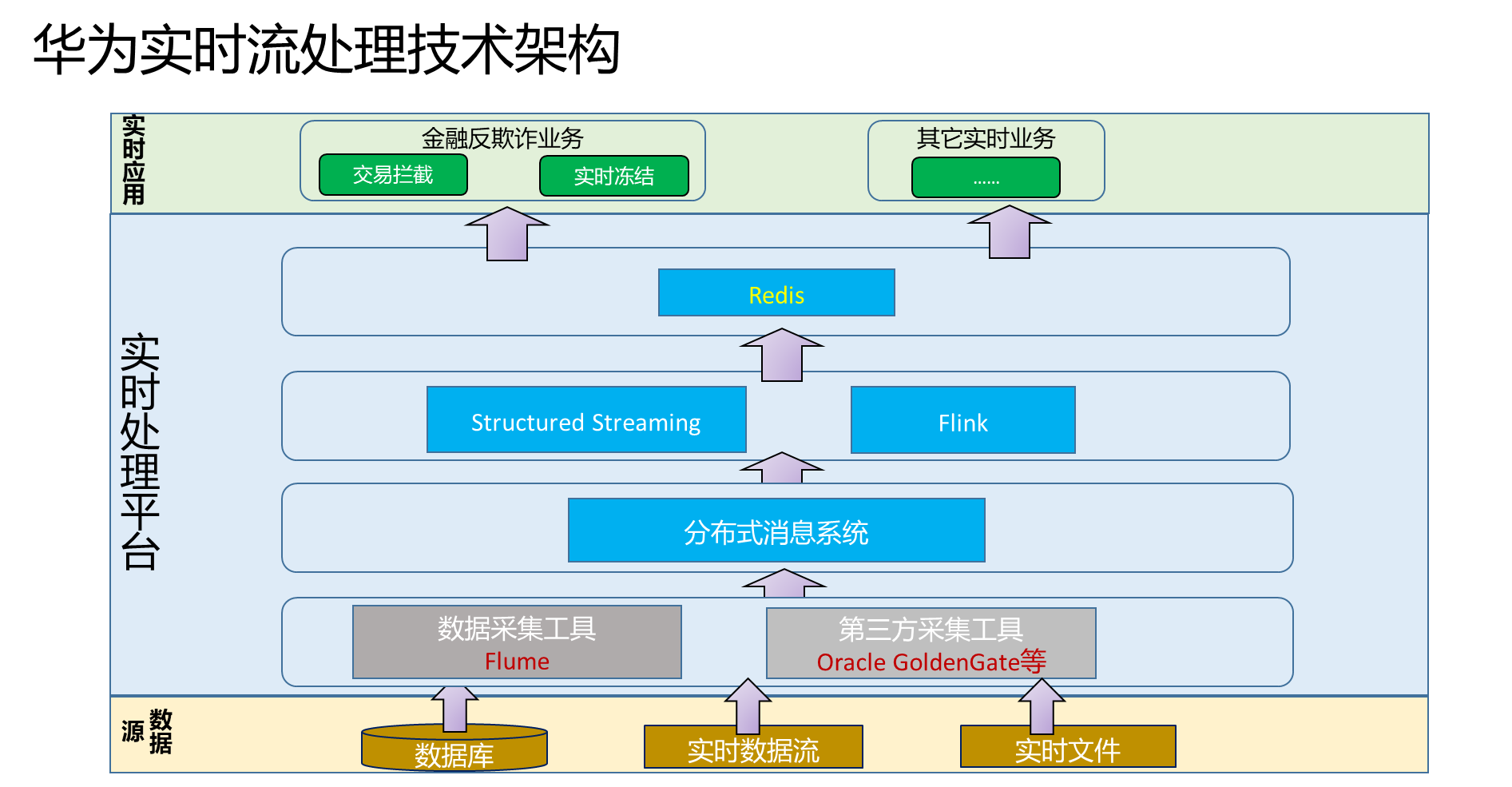
1.5 华为实时流处理技术架构
-
整体架构:涵盖采集、传输、计算、存储、展示全链路
二、实时处理技术框架介绍
本部分逐一介绍了五大核心组件:Flume、Kafka、Flink、Structured Streaming、Redis。
2.1 Flume:日志采集与聚合
2.1.1 基本概念
-
Event:数据传输基本单元(Header + Body)
-
Source:数据源(驱动型/轮询型)
-
Channel:缓冲区(Memory、File、JDBC)
-
Sink:数据输出目的地
2.1.2 架构模式
-
单Agent架构:适用于集群内采集
-
多Agent级联架构:适用于跨集群数据传输
2.1.3 高级组件
-
Interceptor(拦截器):在Source阶段修改/删除Event(如添加时间戳、主机信息)
-
Channel Selector:控制Event分发策略(Replicating / Multiplexing)
-
Sink Processor:Sink组策略(Default / Failover / Load Balance)
2.1.4 配置示例
-
演示了Source(spooldir)、Channel(memory)、Sink(hdfs)的完整配置流程
2.2 Kafka:分布式消息队列
2.2.1 核心概念
-
Topic:消息类别
-
Broker:缓存代理,Kafka集群节点
-
Partition:Topic的分区,支持并行消费
-
Consumer Group:多个消费者组成组,独立订阅Topic
2.2.2 特性
-
高吞吐、分布式、持久化、支持消息回溯
-
无状态Broker,依赖Zookeeper管理集群
2.2.3 应用场景
-
消息队列
-
用户行为追踪
-
日志收集
-
流式数据处理前序缓冲
2.3 Flink:流式计算引擎
2.3.1 核心特性
-
批流一体
-
事件驱动、有状态计算
-
Exactly-once语义
-
高吞吐、低延迟(毫秒级)
2.3.2 关键概念
-
事件时间 vs 处理时间
-
窗口机制:滚动、滑动、会话窗口
-
状态快照与Checkpoint:保障容错与一致性
2.3.3 API体系
-
DataStream API
-
Table API & SQL
-
CEP(复杂事件处理)
2.3.4 新特性
-
Flink 1.11+ Hive Streaming:实现基于Hive的流批一体
2.4 Structured Streaming:Spark流式计算引擎
2.4.1 核心模型
-
无界表模型:将流数据视为不断追加的数据库表
-
结果集(Result Table):每次触发计算后更新
2.4.2 处理模式
-
微批处理(默认):高吞吐,秒级延迟
-
持续处理:毫秒级延迟,牺牲一定一致性
2.4.3 输出模式
-
Complete Mode:全量输出
-
Append Mode:仅输出新增行
-
Update Mode:仅输出更新行(待完善)
2.4.4 特性
-
支持事件时间与Watermark
-
支持流与流Join
-
支持多种Source/Sink
2.5 Redis:内存数据库
2.5.1 核心特性
-
高性能、低延迟
-
丰富的数据结构
-
支持持久化(RDB / AOF)
-
支持主从、集群模式
2.5.2 数据结构与应用场景
|
类型 |
应用场景 |
|---|---|
|
String |
缓存、计数器 |
|
Hash |
对象存储 |
|
List |
消息队列 |
|
Set |
去重、标签系统 |
|
Sorted Set |
排行榜、TOP N |
2.5.3 高级功能
-
Expire:键过期(验证码、限时优惠)
-
Pipeline:批量命令提高性能
-
持久化:RDB快照 / AOF日志
三、大数据实时流处理项目实战
3.1 项目背景
-
平台:某电商平台
-
需求:
-
实时统计交易总金额(大屏展示)
-
每10分钟统计一次Top10商品及销售额
-
3.2 数据格式
-
字段:ID、用户名、年龄、性别、商品ID、购物行为、电话、邮箱、购买日期
-
行为类型:pv(点击)、buy(购买)、cart(加购)、fav(收藏)、scan(浏览)
3.3 技术架构
Python(模拟数据) → Flume(采集) → Kafka(缓冲) → Flink(实时计算总金额) → Redis(存储) → 可视化 ↓ Structured Streaming(Top10统计) → MySQL → 可视化
3.4 技术分工
-
Flume:采集日志数据
-
Kafka:消息队列,削峰填谷
-
Flink:实时计算总交易额
-
Structured Streaming:每10分钟统计Top10商品
-
Redis:存储实时结果
-
MySQL:存储维度表与历史结果
四、总结与展望
-
核心能力:实时采集、低延迟计算、高可靠传输、灵活存储
-
技术栈整合:Flume + Kafka + Flink + Structured Streaming + Redis 构建完整实时流处理链路
-
业务价值:支撑实时大屏、实时风控、实时推荐等场景
-
未来方向:流批一体、实时数仓、AI与实时计算融合

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 16
16 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)