2026 生产级生成式 AI 全栈架构:从 Demo 到商用,你需要的从来不止一个大模型
核心定位:把 AI 系统打包成高可用、高性能、可扩展的生产级服务,因为生产级 AI 应用,本质上也是一个基础设施问题。再完善的 AI 系统,如果无法稳定、高效地部署到生产环境,也无法创造任何业务价值。API 接口开发:FastAPI,已经成为 AI 应用接口开发的事实标准,高性能、易扩展、支持异步,完美适配 AI 应用的接口开发需求;模型打包与部署:BentoML,解决了模型打包、版本管理、环境依
AI stacks look “simple” on a slide. In production, they’re a full system.
2026 年,生成式 AI 已经彻底完成了从 “概念验证” 到 “企业级规模化落地” 的跃迁,但行业里依然存在一个致命的认知误区:太多团队把 80% 的精力投入到 “选哪个大模型” 的军备竞赛里,却忽略了支撑 AI 应用稳定、安全、可靠运行的完整技术体系。
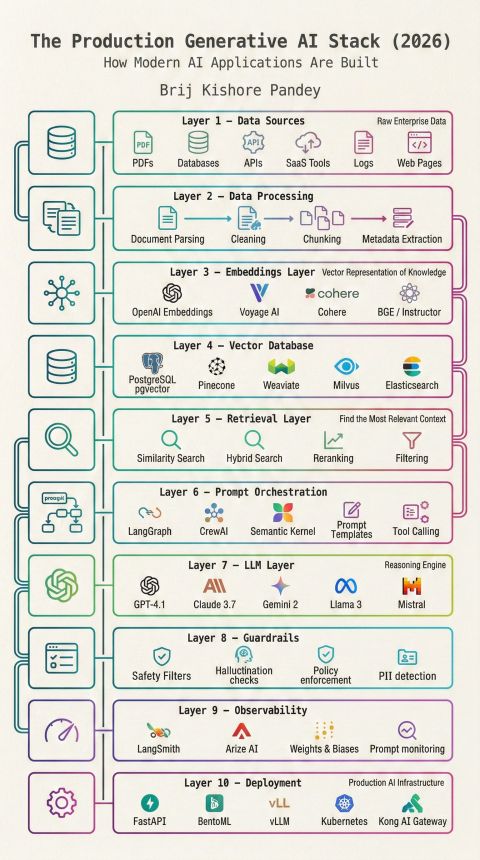
就像这套生产级生成式 AI 技术栈全景图所揭示的:大模型只是整个架构的第 7 层。一个 AI 应用的最终性能、可靠性、安全性与业务价值,从来不是由单一模型决定的,而是由围绕模型的完整技术栈共同定义的。真正能从 Demo 走向商用的 AI 产品,从来不是靠一个强大的大模型撑起来的,而是一套分层解耦、协同闭环的全栈工程化体系。
本文将完整拆解 2026 年生产级生成式 AI 的 10 层核心架构,逐层讲清每一层的定位、核心能力、主流工具栈与生产级落地考量,帮你建立对生成式 AI 工程化的完整认知。
先搞懂核心:为什么生成式 AI 的竞争,早已不是模型的竞争?
当我们回顾生成式 AI 的发展历程,会清晰地看到行业的核心矛盾已经发生了本质变化:
- 2023 年,行业的核心问题是 “有没有能用的大模型”;
- 2024 年,行业的核心问题是 “怎么把大模型和业务场景结合”;
- 2026 年,行业的核心问题已经变成了 “怎么让 AI 应用稳定、安全、低成本地在生产环境规模化运行”。
今天,任何团队都能通过 API 调用 GPT-4o、Claude 3.7 等顶尖大模型,也能通过一行命令在本地部署 Llama 3、Mistral 等开源模型,模型能力已经成为同质化的基础设施。但为什么绝大多数 AI 应用,最终都停留在了 Demo 阶段,无法真正落地到业务中创造价值?
核心答案就藏在这套 10 层架构里:Demo 级应用只需要 “选个模型、写个提示词、跑通一次流程”,而生产级应用需要解决数据治理、检索精准度、流程编排、安全合规、可观测性、高可用部署等一系列工程化问题。模型只是整个系统的推理引擎,而真正决定产品生死的,是引擎之外的完整车身、刹车、方向盘与控制系统。
2026 生产级生成式 AI 全栈架构:10 层核心能力全拆解
第一层:数据源层(Layer 1 - Data Sources)—— AI 应用的价值源头
核心定位:整个生成式 AI 系统的原始数据入口,是企业 AI 应用与通用大模型形成差异化的核心根基。
企业级 AI 应用的核心价值,从来不是重复通用大模型已经具备的知识,而是基于企业的私有专属数据,解决具体的业务问题。这一层的核心,就是打通企业内部所有异构的数据源,为 AI 系统提供专属的知识燃料,覆盖的核心数据源包括:
- 非结构化文档:PDF 合同、产品手册、制度规范、财报文档等;
- 结构化数据:企业内部数据库、数据仓库、业务系统中的结构化数据;
- 接口与 SaaS 数据:企业内部 API、CRM、ERP、OA 等 SaaS 工具中的业务数据;
- 实时数据:系统日志、用户行为数据、网页内容、实时业务流数据。
生产级核心考量:
- 数据权限最小化:严格遵循 “业务需要什么数据,就接入什么数据” 的原则,避免全量数据无差别接入带来的合规与安全风险;
- 增量数据实时同步:生产级应用绝非一次性的静态数据导入,必须实现增量数据的实时同步,确保 AI 系统的知识始终是最新的;
- 多源数据统一治理:建立标准化的数据接入规范,避免不同数据源的格式混乱、元数据缺失,为后续的数据处理打好基础。
第二层:数据处理层(Layer 2 - Data Processing)—— 决定 AI 系统的效果下限
核心定位:AI 系统的 “数据提纯工厂”,是解决 “垃圾进、垃圾出” 的核心环节。
行业里有一句被反复验证的真理:如果你的解析、清洗、分块、元数据提取能力很弱,那么你的检索效果永远不会好。再强的大模型,也无法基于混乱、错误、残缺的上下文,生成准确的回答。这一层的核心,就是把原始的异构数据,转化为 AI 系统可利用的高质量结构化知识,分为四大核心环节:
- 文档解析:绝非简单的文本提取,而是要精准还原文档的层级结构、表格、公式、图片注释、页眉页脚等信息,尤其针对法律、医疗、金融等专业文档,需要定制化的解析能力;
- 数据清洗:去重、去噪、过滤无效内容、修正乱码与格式错误,剔除对 AI 回答无价值的冗余信息;
- 文本分块:按照业务场景适配的分块策略,把长文本拆分为合适大小的文本块,平衡语义完整性与检索精度,是后续检索环节的核心基础;
- 元数据提取:为每个文本块提取对应的元数据,比如文档类型、发布时间、所属业务线、作者、权限范围等,为后续的检索过滤、权限管控提供支撑。
生产级核心考量:
- 拒绝一刀切的固定分块策略,必须根据文档类型、业务场景定制分块规则,比如代码文档、合同文档、产品手册的分块逻辑完全不同;
- 垂直领域必须使用定制化的解析工具,比如法律合同需要专门的条款解析能力,财报文档需要表格与公式的精准还原;
- 建立数据处理的全链路质检机制,确保每一份进入向量库的文档,都符合高质量标准。
第三层:嵌入层(Layer 3 - Embeddings Layer)—— 语义检索的核心底座
核心定位:把人类语言的文本内容,转化为大模型与向量数据库可理解的高维向量表征,是实现 “语义匹配” 而非 “关键词匹配” 的核心。
嵌入模型的质量,直接决定了检索环节的准确率 —— 哪怕你的向量数据库性能再强,用了不合适的嵌入模型,也根本无法召回与用户问题相关的上下文,最终的回答自然会偏离预期。2026 年,嵌入层已经形成了闭源商用与开源自研两大阵营,覆盖了不同场景的需求:
- 闭源商用嵌入模型:OpenAI Embeddings、Voyage AI、Cohere,开箱即用、通用能力强、维护成本低,适合快速落地的商用场景,其中 Voyage AI 专为 RAG 场景优化,在长文档、垂直领域的表现尤为突出;
- 开源嵌入模型:智源 BGE、Instructor 等,其中 BGE 系列已经成为中文场景的绝对首选,中文语义表征能力远超通用开源模型,支持本地私有化部署、可针对垂直领域微调,完美适配数据敏感、合规要求高的企业场景。
生产级核心考量:
- 中文场景优先选择适配中文优化的嵌入模型,避免用纯英文嵌入模型处理中文内容,导致检索准确率大幅下降;
- 私有化部署、数据敏感场景,必须选择可本地部署的开源嵌入模型,确保数据不会离开企业内网;
- 嵌入模型的维度、上下文窗口,必须与后续的向量数据库、分块策略匹配,避免出现语义断裂、检索精度下降的问题。
第四层:向量数据库层(Layer 4 - Vector Database)—— AI 应用的专属记忆中枢
核心定位:生成式 AI 系统的核心存储组件,是连接企业私有数据与大模型的核心桥梁,负责存储嵌入模型生成的高维向量,支持高效的相似性检索。
2026 年,向量数据库赛道已经从 “百家争鸣” 走向了 “场景化分层”,不再是一味追求性能参数,而是形成了清晰的选型边界,覆盖了从原型开发到企业级大规模部署的全场景:
- 轻量化快速落地:PostgreSQL pgvector,作为 PostgreSQL 的向量扩展插件,完美适配已经在使用 PostgreSQL 的业务场景,无需额外部署一套独立的数据库,大幅降低架构复杂度与运维成本,已经成为中小企业与存量业务的首选;
- 云端 SaaS 化托管:Pinecone,零运维、弹性扩缩容、高并发低延迟,无需关注底层部署,专注于业务逻辑,是目前商用 RAG 场景最主流的选择;
- 企业级私有化部署:Weaviate、Milvus、Elasticsearch,开源企业级向量数据库,支持分布式集群扩展、多模态数据存储、丰富的检索策略,能应对亿级向量的高并发检索场景,是企业级生产环境的核心选型。
生产级核心考量:
- 优先选择支持 “向量 + 结构化数据” 统一存储的方案,避免多套数据库带来的架构复杂度与数据一致性问题;
- 大规模场景必须提前规划向量索引的优化策略、分片与分布式部署方案,保障检索延迟与吞吐量的稳定;
- 建立完善的数据备份、容灾、权限管控机制,确保企业核心知识资产的安全。
第五层:检索层(Layer 5 - Retrieval Layer)—— RAG 系统的胜负手
核心定位:决定 AI 系统能不能找到与用户问题最相关的上下文,是 RAG 系统的核心胜负手,直接决定了最终回答的准确率与相关性。
太多开发者对检索的认知,还停留在 “简单的相似度搜索”,但在生产级场景中,混合搜索、重排序、过滤的重要性,远比大多数人想象的高得多。单一的相似度搜索,只能解决最基础的语义匹配问题,面对专业术语、缩略词、权限管控、多维度筛选等生产级场景,完全无法满足需求。完整的检索层,包含四大核心能力:
- 相似度搜索:基于向量的语义匹配,召回与用户问题语义相关的文本块,是检索的基础能力;
- 混合搜索:结合语义搜索与关键词搜索,解决专业术语、缩略词、特定编号的匹配问题,大幅提升召回的全面性;
- 重排序:通过专门的重排序模型,对初步召回的数十条结果做二次精排,把最相关的内容排在最前面,解决 “召回了但排不到前面” 的核心问题,是提升检索精度的关键;
- 过滤:基于元数据做精准过滤,比如时间范围、业务线、用户权限、文档类型,确保用户只能检索到自己有权限访问的内容,同时缩小检索范围,提升准确率。
生产级核心考量:
- 必须建立检索效果的量化评估体系,用召回率、精准率等核心指标,持续优化检索策略,而不是凭感觉调整;
- 多轮对话场景必须实现上下文感知的检索,结合历史对话内容优化检索 query,避免单轮检索的上下文缺失;
- 把企业的权限管控体系与检索环节深度融合,从根源上避免越权访问敏感数据。
第六层:提示词编排层(Layer 6 - Prompt Orchestration)—— 从 Demo 到产品的核心跃迁
核心定位:把零散的 LLM 调用,变成可复用、可管控、可扩展的业务流程,是 AI 应用从 “一次性 Demo” 变成 “标准化产品” 的核心环节,也是智能体应用的核心骨架。
Demo 级应用,往往是单轮的 “提示词 + LLM 调用”,而生产级应用,需要处理多轮对话、复杂工作流、多工具调用、异常处理、多智能体协同等一系列场景,这就需要一套成熟的编排框架来支撑。2026 年,编排层已经形成了清晰的产品矩阵,覆盖了不同的业务场景:
- 复杂工作流与状态机编排:LangGraph,已经成为多轮对话、复杂智能体工作流的事实标准,基于状态机的设计,完美解决了循环、分支、异常重试、回滚等生产级需求,适配绝大多数复杂 AI 应用场景;
- 多智能体协同编排:CrewAI,专为多智能体协同场景优化,支持角色定义、任务分工、智能体间通信,完美适配需要多个专业智能体协同完成的复杂任务;
- 企业级微软生态适配:Semantic Kernel,微软官方推出的编排框架,完美适配.NET、Java 等企业级开发语言,与微软 365、Azure 生态深度融合,是微软体系企业开发的首选;
- 基础能力支撑:提示词模板管理、工具调用(Tool Calling),其中工具调用是编排层的核心能力,让 AI 能对接外部系统、执行实际动作,从 “只会生成文本的助手” 变成 “能落地执行的智能体”。
生产级核心考量:
- 编排流程必须内置完善的异常处理、重试、降级、兜底机制,避免单次调用失败导致整个工作流崩溃;
- 建立提示词的版本管理、灰度发布、A/B 测试体系,避免提示词修改导致的效果波动;
- 工具调用必须遵循最小权限原则,严格管控每个工具的调用权限、参数范围,避免越权执行风险。
第七层:大模型层(Layer 7 - LLM Layer)—— 系统的推理引擎
核心定位:整个 AI 系统的推理与生成引擎,负责基于上下文、提示词与业务规则,生成最终的回答与执行逻辑,是整个架构的核心组件,但绝非唯一核心。
2026 年,大模型赛道已经形成了 “闭源与开源双向趋同” 的格局,闭源模型在复杂推理、长上下文、多模态能力上依然保持优势,而开源模型在私有化部署、成本控制、定制化微调上已经具备了不可替代的价值。企业级应用的主流方案,已经从 “单一模型全场景覆盖”,变成了 “多模型智能调度”:
- 复杂推理、长文档场景:优先选择 GPT-4.1、Claude 3.7、Gemini 2 等闭源强模型,保障推理效果与长上下文处理能力;
- 简单任务、高频调用场景:优先选择 Llama 3、Mistral 等轻量开源模型,大幅降低调用成本,提升响应速度;
- 中文场景、私有化部署:优先选择 DeepSeek、Qwen 等国产开源模型,中文理解能力与适配性远超通用开源模型。
生产级核心考量:
- 建立多模型容灾备份机制,避免单一模型 API 故障导致整个应用不可用;
- 基于场景做模型选型,平衡成本与效果,避免 “大材小用” 导致的成本失控;
- 针对垂直业务场景,用专属数据做微调优化,大幅提升模型在特定场景的表现,而非直接使用通用模型。
第八层:护栏层(Layer 8 - Guardrails)—— 生产级应用的安全底线
核心定位:AI 应用的安全闸门与合规底线,没有这一层,你就是在向用户交付风险,而非产品。
2026 年,随着《生成式 AI 服务管理暂行办法》《个人信息保护法》等合规要求的全面落地,护栏已经从可选的附加功能,变成了生产级 AI 应用的必选核心模块。它的核心职责,是在 AI 应用的全链路,建立安全与合规的防护网,确保输出内容安全、合规、准确、符合企业要求,四大核心能力包括:
- 安全过滤:前置拦截色情、暴力、歧视、违法违规等有害内容,避免违规输出;
- 幻觉检查:校验模型的回答是否与检索到的上下文一致,识别并纠正模型凭空捏造的虚假信息,从根源上降低幻觉风险;
- 策略执行:落地企业的合规规则、业务要求、品牌话术,确保模型的输出符合企业的管理规范,避免出现不符合业务要求的内容;
- PII 检测与脱敏:自动识别用户输入与模型输出中的个人敏感信息,比如身份证号、手机号、银行卡号等,自动做脱敏处理,符合个人信息保护的合规要求。
生产级核心考量:
- 建立 “前置拦截 + 后置校验” 的双重防护机制,在用户输入环节与模型输出环节都做护栏校验,不留安全死角;
- 针对垂直行业的合规要求,定制专属的护栏规则,比如金融行业的投资建议合规、医疗行业的诊疗规范约束;
- 持续优化护栏的误拦截率,避免过度防护导致的用户体验下降,平衡安全与可用性。
第九层:可观测性层(Layer 9 - Observability)—— 生产级系统的生命线
核心定位:让黑盒的 AI 系统,变成可观测、可追踪、可优化、可排障的透明系统,是生产级 AI 应用与 Demo 的核心区别之一。
没有可观测性的 AI 系统,就像没有仪表盘的汽车,你根本不知道它什么时候会出问题、哪里出了问题、为什么出问题。生产级 AI 应用,绝对不能是 “输入 - 输出” 的黑盒,必须实现全链路的可观测,核心能力包括:
- 全链路追踪:记录从用户提问到最终回答的完整链路,包括用户输入、检索到的上下文、调用的模型、消耗的 Token、执行的工具调用、每一步的耗时,出现问题可完整回溯;
- 效果监控:实时监控 AI 回答的准确率、幻觉率、用户满意度、检索召回率等核心指标,出现效果下滑及时告警;
- 成本与性能监控:统计每个用户、每个场景、每个模型的 Token 消耗与调用成本,监控接口延迟、吞吐量、成功率等性能指标;
- 提示词与模型监控:跟踪不同版本提示词、不同模型的效果变化,为优化迭代提供数据支撑。
主流的工具栈包括 LangSmith、Arize AI、Weights & Biases,其中 LangSmith 已经成为 LangChain/LangGraph 生态的标配可观测性工具,完美适配 AI 应用的全链路追踪需求。
生产级核心考量:
- 建立完善的异常告警机制,当核心指标出现异常波动时,及时通知运维与研发团队,避免故障扩大;
- 全链路日志必须满足合规审计要求,可追溯、不可篡改,留存时长符合行业监管要求;
- 把可观测性数据与优化迭代闭环结合,用数据驱动检索策略、提示词、模型选型的持续优化。
第十层:部署层(Layer 10 - Deployment)—— 从代码到服务的最后一公里
核心定位:把 AI 系统打包成高可用、高性能、可扩展的生产级服务,因为生产级 AI 应用,本质上也是一个基础设施问题。
再完善的 AI 系统,如果无法稳定、高效地部署到生产环境,也无法创造任何业务价值。2026 年,生成式 AI 的部署生态已经完全成熟,形成了从接口开发、模型打包、推理优化、容器编排到 API 网关的完整工具链:
- API 接口开发:FastAPI,已经成为 AI 应用接口开发的事实标准,高性能、易扩展、支持异步,完美适配 AI 应用的接口开发需求;
- 模型打包与部署:BentoML,解决了模型打包、版本管理、环境依赖、部署的全流程问题,实现 “一次打包,到处部署”,大幅降低 AI 应用的部署难度;
- 推理性能优化:vLLM,已经成为大模型推理部署的标配工具,通过 PagedAttention 等技术,大幅提升模型推理的吞吐量、降低延迟,让开源模型的部署效率实现质的飞跃;
- 容器编排与扩缩容:Kubernetes,实现 AI 服务的容器化部署、弹性扩缩容、高可用容灾,应对流量波动,保障服务的稳定性;
- API 网关:Kong AI Gateway,实现 AI API 的统一管控、鉴权、限流、缓存、成本管控,是企业级 AI 服务的统一入口。
生产级核心考量:
- 建立服务的高可用与容灾方案,避免单点故障导致整个服务不可用;
- 针对流量波动,设计合理的弹性扩缩容策略,既保障高峰时期的服务性能,又避免低峰时期的资源浪费;
- 做好 API 的安全管控、限流、鉴权,避免接口被滥用、数据泄露等安全风险。
端到端全链路:生产级 AI 应用的完整执行流程
讲完 10 层架构的核心能力,我们通过一个企业内部的常见场景,把整个架构串联起来,看清楚一个用户请求,在生产级 AI 系统中是如何流转的:
场景:企业员工在内部 AI 助手,提问 “2026 年 Q1 华东区域的销售费用报销制度是什么?”
- 请求接入:用户的提问通过前端传入部署层,经过 Kong AI 网关的鉴权、限流校验,进入后端服务;
- 流程触发:编排层(LangGraph)接收到请求,触发对应的 RAG 工作流,启动全流程处理;
- 查询向量化:编排层把用户的提问传入嵌入层,通过 BGE 嵌入模型,生成查询向量;
- 上下文检索:检索层首先通过 pgvector 向量数据库做混合搜索,结合元数据过滤(时间:2026 年 Q1、区域:华东、文档类型:报销制度),召回相关的制度文档,再通过重排序模型做二次精排,筛选出最相关的 3 条上下文;
- 推理生成:编排层把用户问题、检索到的制度上下文、企业专属的提示词模板整合,传入大模型层,通过调度策略选择轻量开源模型完成本次回答生成;
- 安全合规校验:大模型生成的回答,传入护栏层,做幻觉校验(确保回答与制度内容一致)、合规校验、敏感信息检测,确保回答符合企业规范;
- 结果返回:经过校验的最终回答,通过部署层的 API,返回给前端用户;
- 全链路观测与归档:整个过程的全链路日志、指标数据,全部流入可观测性层,完成记录、监控与归档,同时用户的满意度反馈会进入优化闭环,持续迭代系统效果;
- 底层支撑:整个流程的基础,是数据源层与数据处理层,提前把企业的报销制度、财务规范等文档完成解析、清洗、分块、嵌入,存入向量数据库,为检索提供高质量的知识基础。
这就是一个生产级 AI 应用的完整执行流程,它绝非 “用户提问→大模型回答” 的简单链路,而是 10 个层级协同工作、环环相扣的完整工程体系。
结尾:2026 年,做 AI 要像搭系统,而不是写提示词
回到开头的核心论点:AI 栈在 PPT 上看起来很简单,但在生产环境中,它是一套完整的系统。
2026 年,生成式 AI 的竞争,早已不是大模型的军备竞赛,而是全栈工程化能力的比拼。那些能真正落地、持续创造业务价值的 AI 产品,从来不是靠一个遥遥领先的大模型,而是靠一套分层解耦、协同闭环、可观测、可管控、可优化的完整技术栈。
对于所有正在构建生成式 AI 应用的开发者与企业来说,最重要的建议就是:treat it like a stack, not a prompt. 不要再把 AI 应用当成一个 “提示词工程”,而是要把它当成一套完整的企业级软件系统,从全栈的视角去设计、构建、优化每一个环节。
只有这样,你才能把一个只能跑通一次的 Demo,变成一个能稳定服务用户、创造业务价值的生产级产品,在生成式 AI 的规模化落地浪潮中,真正抓住核心红利。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献104条内容
已为社区贡献104条内容

所有评论(0)