LLM学习笔记9——Qwen-VL多模态系列(Qwen-VL、Qwen2-VL、Qwen2.5-VL、Qwen3-VL)
Qwen-VL是阿里巴巴通义实验室推出的开源多模态视觉语言模型系列,旨在构建“看得懂、听得清、说得出”的通用多模态智能体。该系列从基础的图文理解逐步演进到支持全感官感知,在开源社区和工业界广受关注。
系列文章目录
前言

随着人工智能技术的飞速发展,我们正在进入一个多模态信息的时代。文本、图像、声音等多种形式的数据交织在一起,构成了我们对世界更完整的认知。大型语言模型在处理和生成文本方面取得了巨大成功,但它们本质上是“盲人”,无法理解图像等视觉信息。为了打破这一局限,视觉语言模型VLM应运而生,它能够同时理解和处理文本与图像,实现了从“读懂文字”到“看懂世界”的跨越。
VLM是一种能够同时处理和理解多种模态(通常是图像和文本)信息的人工智能模型。它结合了计算机视觉和自然语言处理的技术,旨在让 AI 像人类一样,能够通过“看图说话”的方式来理解世界。与一次只能处理一种信息类型的单模态语言模型不同,VLM 能够接收图像和文本作为输入,并根据这些输入生成文本、边界框或其他形式的输出。这种能力使其能够完成更复杂的任务,例如:
视觉问答(VQA):根据图片内容回答问题。
图像描述(Image Captioning):为图片生成一段描述性文字。
多模态对话:与用户进行基于图片内容的连续对话。
VLM 的出现极大地扩展了 AI 的应用场景,使其在自动驾驶、智能客服、内容创作和人机交互等领域展现出巨大潜力。

Qwen-VL是阿里巴巴通义实验室推出的开源多模态视觉语言模型系列,旨在构建“看得懂、听得清、说得出”的通用多模态智能体。该系列从基础的图文理解逐步演进到支持全感官感知,在开源社区和工业界广受关注。
以下内容主要是Qwen公布的VL论文或者技术报告中的重点解读与学习记录。
一、Qwen-VL
渐进式三阶段训练流程

Qwen-VL的整体网络架构分别由三个组件构成:
语言模型QwenLM:Qwen-VL采用一个Qwen语言模型架构作为其基础组件,该模型使用Qwen-7B的预训练权重进行初始化。
视觉编码器ViT:Qwen-VL采用一个Vision Transformer架构作为其基础组件,该架构使用Openclip的ViT-bigG的预训练权重进行初始化。
位置感知的视觉-语言适配器CrossAttn:Qwen-VL采用一个单层交叉注意力模块作为其基础组件,该模块使用一组Learnable Query Embs或者QwenLM的文本特征作为查询向量,将ViT输出的视觉特征作为键和值,分别进行交叉注意力操作。

Qwen-VL的图像-文本对输入的构成:
视觉编码:图像通过视觉编码器和视觉-语言适配器处理,将224*224大小的图像以14的步长分割成块,生成压缩成一组固定256长度的图像特征序列。
图像输入:为了区分图像特征输入和文本特征输入,将使用和作为特殊标记分别添加到图像特征序列的开头和结尾,以表示图像内容的开始和结束。
边界框输入:为了增强模型对细粒度视觉理解与定位的能力,将使用和或者和作为特殊标记分别添加到坐标值的的开头和结尾,以表示图像某个区域的二维位置。其中(x1,y1),(x2,y2)表示矩形边界框的左上角和右下角坐标,通常用于标注物体。而(x1,y1),(x2,y2),(x3,y3),(x4,y4)表示四边形边界框的四个顶点坐标,通常用于标注不规则或倾斜的文本区域。
视觉关联文本输入:为了区分普通文本和视觉区域有关联的描述文本的输入,将使用和作为特殊标记分别添加到对应文本特征序列的开头和结尾,以表示对应文本特征序列的开始和结束,用于标记边界框所指代的内容。
训练样本输入:为了区分不同训练样本的输入,将使用作为特殊标记添加到每段训练样本的结尾,以表示一个训练样本的结束。
不同任务的训练样本构成:
图像描述:图片+指令文本+描述文本+。
视觉问答:图片+问答文本+。
OCR视觉问答:图片+问答文本+。
为描述文本提供视觉定位:图片+指令文本+文本+描述文本+(x1,y1),(x2,y2)+文本+。
语言-视觉定位:图片+描述文本+(x1,y1),(x2,y2)+。
对视觉定位进行文本描述:图片+This+(x1,y1),(x2,y2)+描述文本+。
OCR带定位:图片+指令文本+文本+(x1,y1),(x2,y2),(x3,y3),(x4,y4)+。
Qwen-VL模型的训练过程包含三个阶段:两个预训练阶段和一个最终的指令微调训练阶段。
1、Pretraining 预训练

在第一阶段预训练中,使用海量图像-文本对,建立视觉特征与语言模型之间的基本对齐。
在此阶段中,首先冻结QwenLM语言模型的参数,只优化视觉编码器ViT和视觉-语言适配器CrossAttn。将图像-文本对中的图像调整为224×224大小的低分辨率图像,将图像-文本对数据分别传入ViT模型和QwenLM模型中。将ViT的输出和Learnable Query Embs可学习的查询嵌入传入CrossAttn交叉注意力模块中进行对齐,再将CrossAttn输出和文本传入QwenLM语言模型中进行训练。
第一阶段预训练目标是最小化文本标记的交叉熵,其中最大学习率为2e-4,训练过程对图文对使用30720的批次大小,整个第一阶段预训练持续50,000步,消耗大约15亿个图文样本。
2、Multi-task Pretraining 多任务预训练

在第二阶段的多任务预训练中,依旧使用大量图像-文本对,但是引入了具有更大输入分辨率的高质量、细粒度视觉-语言标注数据以及交错的图文数据。
在此阶段中,不再冻结任何模型的参数,优化语言模型QwenLM、视觉编码器ViT和视觉-语言适配器CrossAttn。将视觉编码器的输入分辨率从224×224增加到448×448,减少了图像下采样带来的信息损失。在7个任务上混合训练Qwen-VL,训练目标是为模型注入细粒度视觉理解和复杂任务处理能力,最终得到一个具有强大、通用细粒度视觉理解与推理能力的“全能”模型。
3、Supervised Finetuning 监督微调

在第三阶段的监督微调训练中,使用35万条指令微调数据进行微调,模态指令调优数据主要来自描述数据或通过大语言模型自指令生成的对话数据,这些数据通常只处理单图像对话和推理,并且仅限于图像内容理解。
此阶段中,首先冻结ViT编码器模型的参数,只优化语言模型QwenLM和视觉-语言适配器CrossAttn。通过人工标注、模型生成和策略拼接构建了一组额外的对话数据,将定位和多图像理解能力融入Qwen-VL模型。确保模型有效地将这些能力迁移到了更广泛的语言和问题类型中。此外,在训练过程中混合了多模态和纯文本对话数据,以增强其遵循指令和对话的能力,确保模型对话能力的通用性,从而得到交互式的Qwen-VL-Chat模型。
二、Qwen2-VL
Qwen2-VL沿用了Qwen-VL的逻辑,该框架主要集成了视觉编码器、基于MLP的视觉-语言融合模块和语言模型。
视觉编码器使用的是优化过的OpenCLIP预训练的ViT-bigG架构,参数量为675M,该编码器中移除绝对位置嵌入并引入2D-RoPE以支持原生动态分辨率输入。
视觉-语言融合模块使用更简洁的MLP压缩机制替代CrossAttn机制。
语言模型使用的是Qwen2系列LLM,能力更强。
1、Naive Dynamic Resolution 原生动态分辨率

在视频编码器中引入了2D-RoPE二维旋转位置嵌入机制,使得能够处理任意分辨率的图像,并将其动态转换为数量可变的视觉token。
8204×1092分辨率的Picture1、28×224分辨率的Picture2、700×1260分辨率的Picture3、336×644×16s大小的video1都分别通过旋转位置编码将数据动态转化为一组长度不一的特征序列,且保留了对应的视觉数据的原生分辨率信息。
在ViT之后采用了一个简单的MLP层,将相邻的2×2 token压缩为单个token,并在压缩后的视觉token序列的首尾分别放置特殊的<|vision_start|>和<|vision_end|> token。分辨率为224×224的图像,在使用patch_size为14的ViT进行编码后,进入大语言模型之前会被压缩为64+2个token。
2、Multimodal Rotary Position Embedding 多模态旋转位置嵌入 M-RoPE

在语言解码器中引入了M-RoPE多模态旋转位置嵌入机制,将原始的旋转嵌入分解为三个正交的组件:时间t、高度h、宽度w。使LLM能够在一个统一的序列中,精确感知不同模态Token之间的复杂关系,从而实现深度的多模态对齐与推理。
对于文本Token:三个维度使用相同的位置ID,功能上退化为标准的1D-RoPE。
对于图像Token:时间ID保持不变,高度和宽度ID根据该Token在原始图像中的像素位置分配。
对于视频Token:时间ID随帧序递增,高度和宽度ID的分配规则与图像相同。
在模型输入包含多种模态的场景中,每种模态的位置编号通过将前一种模态的最大位置ID加一来初始化。
M-RoPE不仅增强了位置信息的建模,还降低了图像和视频的位置ID数值,从而使模型在推理过程中能够外推到更长的序列。
3、Unified Image and Video Understanding 统一的图像和视频理解
Qwen2-VL采用包含图像和视频数据的混合训练机制,在训练数据集中,既包含海量图像-文本对,也包含视频-文本对,确保模型在图像理解和视频理解方面的能力。
为了尽可能保留足够时序信息和控制计算成本之间取得平衡,因为相邻帧之间信息高度冗余,使用使用每秒两帧的频率对视频进行采样。
此外使用了深度为2的3D卷积来处理视频输入,使模型能够处理3维数据,使得在不增加序列长度的情况下处理更多的视频帧,为模型注入了关键的时序理解能力,提升了动作识别和视频内容理解的性能。
为了保持图像输入和视频输入的处理一致性,对于一张静态图片,将其复制一份,当作一个“两帧的、内容完全相同的视频”来处理。
长视频即使经过采样,帧数依然很多,所以模型会动态调整每个视频帧的分辨率,比如通过缩放分辨率的方法将每个视频的总token数限制在16384以内。这种训练方法在模型对长视频的理解能力与训练效率之间取得了平衡。
4、训练流程
在第一阶段预训练中,Qwen2-VL在包含约6000亿个token的语料库上进行了训练。Qwen2-VL的大语言模型组件利用Qwen2的参数进行初始化,而其视觉编码器则使用基于DFN训练的ViT架构进行初始化,ViT中的固定位置嵌入被替换为了RoPE-2D。这一预训练阶段主要侧重于学习图像-文本关系、通过OCR识别图像内的文本内容以及图像分类任务,这种基础训练对于使模型能够建立对核心视觉-文本相关性和对齐的稳健理解至关重要。
在第二阶段的多任务预训练中,引入了额外的8000亿个图像相关数据的token。该阶段引入了更大量的图文混合内容,有助于更细致地理解视觉与文本信息之间的相互作用,视觉问答数据集的加入优化了模型回答图像相关问题的能力。此外,包含多任务数据集对于培养模型并发处理多种任务的能力至关重要,而这一技能在处理复杂的现实世界数据时尤为重要,同时,纯文本数据在维持和提升模型语言能力方面继续发挥着关键作用。
在两个预训练阶段中,Qwen2-VL累计处理了1.4万亿个token,具体而言,这些token不仅包含文本token,还包含图像和视频token,然而在训练过程中,论文仅对文本token提供监督,这种对广泛且多样的语言和视觉场景的接触,确保了模型能够深入理解视觉和文本信息之间错综复杂的关系,从而为各种多模态任务奠定了坚实的基础。
在第三阶段的监督微调训练中,论文采用ChatML格式来构建指令跟随数据,该数据集不仅包含纯文本对话数据,还包含多模态对话数据,其中的多模态内容涵盖图像问答、文档解析、多图比较、视频理解、视频流对话以及基于智能体的交互。论文这种全面的数据构建方法旨在增强模型理解和执行跨各种模态的广泛指令的能力,通过整合多样化的数据类型,论文旨在开发出一种更通用、更稳健的语言模型,使其除了传统的基于文本的交互外,还能处理复杂的多模态任务。
三、Qwen2.5-VL
Qwen2.5-VL沿用了Qwen2-VL的部分设计,同时进行了多项重要升级:
保持了视觉编码器、基于MLP的视觉-语言融合模块和语言模型的串联结构。
视觉编码器依然采用以CLIP为基础的ViT架构,并沿用了2D-RoPE以支持原生动态分辨率输入。
视觉-语言融合模块依然采用MLP压缩机制。
语言模型使用的是Qwen2.5系列LLM,沿用了M-ROPE捕捉文本、图像和视频的位置信息。

在视觉输入中,将8204×1092分辨率的Picture1、28×224分辨率的Picture2、700×1260分辨率的Picture3、336×644×8s大小的video1都分别通过Conv3D操作进行图像块划分和2D-RoPE二维旋转位置编码将数据动态转化为一组长度不一的特征序列,且保留了对应的视觉数据的原生分辨率信息。
从零开始训练重新设计的 ViT视觉编码器,训练过程分为以下几个阶段:
CLIP 预训练(CLIP Pre-training):通过对比学习训练视觉编码器,使其具备初步的视觉理解能力。
视觉-语言对齐(Vision-Language Alignment):调整视觉与语言模态的特征表示,使它们能够在共享特征空间中对齐。
端到端微调(End-to-End Fine-tuning):在完整的多模态任务上进行微调,以进一步优化两种模态的融合效果。
1、视觉编码器架构

1. 模型输入处理部分
训练和推理期间,输入图像的高度和宽度都会调整为28的整数倍,然后再输入ViT。
使用Conv3D三维卷积操作,使用一个大小为14×14,步长为14的卷积核对两张帧图像进行卷积计算,并通过3D卷积提取这些块的初始视觉特征,捉物体的运动和变化。其中2×表示每次操作同时查看连续的2帧图像,如果是视频帧就是连续的两个视频帧,如果是静态图像就复制一份作为一个连续两帧但内容完全相同的视频帧来处理。最终将图像分割成一个个 14×14像素的图像patch块。
原始图像数据经过Conv3D分块处理得到视觉特征序列,并在Transformer的注意力机制中,使用2D-RoPE为这些特征序列编码位置信息。
2. 模型分层特征提取部分
使用RMSNorm均方根层归一化操作,对单个特征向量进行标准化,使其数值分布更稳定,从而加速模型训练并提升效果。相比传统的LayerNorm,RMSNorm计算更简单高效。

使用Window Attention窗口注意力操作,通过window partition将所有图像patch块组合拼接成多个不重叠的、固定大小的窗口,注意力计算仅在每个窗口内部进行。每个图像块大小为14×14,通过8×8个图像块组合得到一个112×112大小的窗口。最大窗口大小为 112×112,对于小于 112×112 的区域,模型在处理时不会使用填充操作,而是保持其原始分辨率。这使得计算成本与图像块数量呈线性关系,而非二次方极大地降低了计算量,让模型能够处理高分辨率的图像,并专注于学习局部区域的细节特征。经过M次堆叠Window-Attention层得到的特征数据,最终模型还能够在多个层级上逐步融合和提炼局部视觉信息。
使用FFN前馈网络操作, 在每个注意力层后都会使用一个FFN,通常为两层全连接层,主要对每个位置的特征进行独立变换,增加模型的非线性表达能力。
使用SwiGLU激活函数, 通过一个门控机制 S w i s h ( x ) ∗ ( W x + b ) Swish(x) * (Wx + b) Swish(x)∗(Wx+b)来更精细地控制信息流动,比传统的ReLU或GELU效果更好,能有效提升模型性能。
3. 模型全局特征提取部分
使用RMSNorm均方根层归一化操作,对单个特征向量进行标准化,使其数值分布更稳定,从而加速模型训练并提升效果。相比传统的LayerNorm,RMSNorm计算更简单高效。
使用Full Attention 全局注意力操作,经过M层局部的窗口注意力处理后,统一使用一层全局注意力。在这一层,任何一个图像块都可以关注到序列中的所有其他图像块。让模型整合全局的上下文信息,理解不同局部区域之间的关系。并且由于前面已经通过下采样和局部处理减少了序列长度,此时进行全局注意力计算的开销是可接受的。
使用FFN前馈网络操作, 在每个注意力层后都会使用一个FFN,通常为两层全连接层,主要对每个位置的特征进行独立变换,增加模型的非线性表达能力。
使用SwiGLU激活函数, 通过一个门控机制 S w i s h ( x ) ∗ ( W x + b ) Swish(x) * (Wx + b) Swish(x)∗(Wx+b)来更精细地控制信息流动,比传统的ReLU或GELU效果更好,能有效提升模型性能。
4. 动态帧率采样与绝对时间对齐

MRoPE Time IDs(MRoPE时间ID):对于输入的8秒视频数据,先建立一个与视频绝对时间轴对齐的时序表示基础,将8秒的视频时长均匀分割为16个绝对时间片段,每0.5秒一个片段,然后为每个时间片段分配一个唯一的MRoPE Time ID,从0到15共16个,也就是每秒2个标记。注意这16个ID代表了一个高分辨率的绝对时间编码基础,是系统理解时间流逝的“绝对标尺”,而不是必须处理的16帧图像。
Dynamic FPS sampling(动态FPS采样):虽然将视频划分为16个片段,但是并非固定处理所有16个时间点,而是会根据任务的需求或效率进行动态采样:
稀疏采样(0.5 FPS):仅取首尾两个关键帧,对应时间ID (0, 15),适用于视频分类、视频级描述生成的任务。
中等采样(1 FPS):均匀地每秒取一帧,对应时间ID (0, 5, 10, 15),适用于视频问答、基础的动作识别的任务。
密集采样(2 FPS):接近原始密度,取更多帧(如0, 2, 4, 6, 9, 11, 13, 15),适用于动作定位、复杂的行为理解、需要帧间推理的任务。
Sampled MRoPE Time IDs(采样的MRoPE时间ID):从MRoPE Time IDs的划分基础上选择性地采样一部分时间片段,再通过Dynamic FPS sampling选择的时间片段中采样得到真正的视频帧输入。目的是为了允许模型灵活适配不同任务对时间分辨率的要求,实现计算效率与理解深度的权衡。避免僵硬地处理所有帧。
所以16个Time ID提供了时间编码的精细粒度能力,使模型能够精准地定位到视频中任何0.5秒的片段。但在实际特征提取时,模型会根据任务需求,像经验丰富的剪辑师一样,只选择性地“观看”最具信息量的关键片段,这是一种“按需索取”的高效策略。
Conv3D with 2x temporal merging(Conv3D与2x时间合并):对这些采样得到的视频帧进行三维卷积,在时间维度上进行下采样,将相邻时间步的特征进行融合,进一步压缩和抽象时序信息,形成更高级的时空特征表示。
2、与绝对时间对齐的MRoPE多模态旋转位置编码
MRoPE 将位置嵌入分解为时间维度、高度维度、宽度维度。
对于文本输入,所有三个部分使用相同的位置 ID,因此在功能上,MRoPE 相当于传统的 1D RoPE。
对于图像输入,时间维度的 ID 在所有视觉 token 上保持不变,而高度和宽度维度的 ID 则根据每个 token 在图像中的空间位置分别进行唯一分配。
对于视频输入,时间维度的 ID 在每帧之间递增,而高度和宽度维度的分配模式与静态图像相同。
在Qwen2-VL中,MRoPE,的时间位置ID与输入帧的数量绑定,因此无法考虑视频内容变化的速度或事件发生的绝对时间,而在Qwen2.5-VL中,将MRoPE的时间位置ID与绝对时间对齐,通过利用时间 ID 之间的间隔,模型能够在不同FPS采样率的视频中学习到一致的时间对齐。
3、MLP-based Vision-Language Merger 基于 MLP 的视觉-语言融合模块
不直接使用 Vision Transformer提取的原始图像块特征,而是首先将空间上相邻2×2的四个图像patch块特征进行分组,然后将这些分组后的特征拼接起来,再通过一个两层的多层感知机(MLP),将它们投影到与 LLM 使用的文本嵌入对齐的维度。这种方法不仅降低了计算成本,还为动态压缩不同长度的图像特征序列提供了灵活的方法。
4、训练流程
与Qwen2-VL相比,Qwen2.5-VL预训练数据的规模,从 1.2 万亿 token 增加到约 4 万亿 token。
从头开始训练了一个 Vision Transformer视觉编码器,以 DataComp 和一些内部数据集作为视觉编码器的初始化权重,同时通过预训练的 Qwen2.5 大型语言模型作为语言模型组件的初始化权重。
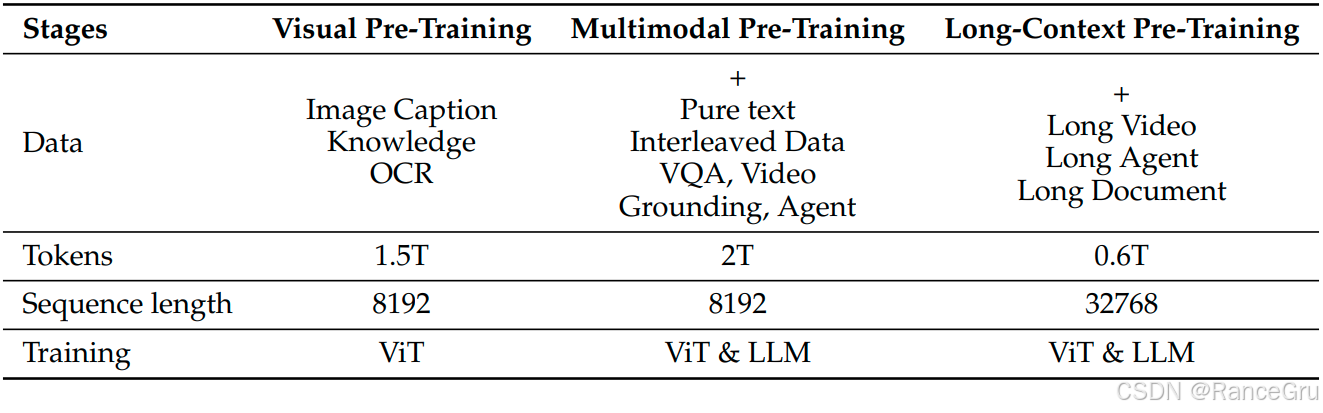
在第一阶段预训练中,冻结语言模型Qwen2.5-LM模型参数,仅训练ViT视觉编码器和MLP视觉-语言融合模块。改善视觉编码器与语言模型的对齐,从而为多模态理解奠定坚实基础。这些数据集经过精心挑选,以促进 ViT 提取具有意义的视觉表示,这些表示能够有效地与文本信息集成。
在第二阶段的多任务预训练中,解冻所有模型参数。并在多样化的多模态图像数据上训练模型,以增强其处理复杂视觉信息的能力。这些数据集加强了模型在视觉和语言模态之间建立深层连接的能力,使其能够处理日益复杂的任务。
在第三阶段的长上下文预训练中,解冻所有模型参数。进一步增强模型在长序列上的推理能力,同时引入视频和基于代理的数据,并增加序列长度。序列长度从第一阶段和第二阶段的8192增加到第三阶段的32768,通过延长序列长度,模型能够处理更长的上下文,这对于需要长期依赖和复杂推理的任务特别有利。
在第四阶段的SFT监督微调后训练中,冻结ViT视觉编码器参数,仅训练语言模型Qwen2.5-LM模型和MLP视觉-语言融合模块。通过使用了一个精心设计的数据集和有针对性的指令优化,弥补预训练表示与下游任务需求之间的差距,让模型能够理解复杂的人类指令,并按照要求的格式和内容生成回应。将模型暴露于经过精心设计的多模态指令-响应样本之下,SFT 在保持预训练特征完整性的同时,实现了高效的知识迁移。
在第五阶段的DPO直接偏好优化后训练中,冻结ViT视觉编码器参数,仅训练语言模型Qwen2.5-LM模型和MLP视觉-语言融合模块。专注于图文数据和纯文本数据,利用偏好数据,在损失函数中最大化优选回答的概率,同时最小化劣选回答的概率。这个过程能有效将人类的隐性判断标准,如安全性、有用性、无害性等概念注入模型。每个样本仅处理一次,以确保优化效率。
四、Qwen3-VL
Qwen3-VL沿用了Qwen2.5-VL的部分设计,同时进行了多项重要升级:
保持了视觉编码器、基于MLP的视觉-语言融合模块和语言模型的串联结构。
视觉编码器采用以SigLIP-2为基础的ViT架构,并沿用了2D-RoPE以支持原生动态分辨率输入。
视觉-语言融合模块依然采用MLP压缩机制,引入DeepStack机制加强视觉-语言对齐。
语言模型使用的是Qwen3系列LLM,使用interleaved-MRoPE捕捉文本、图像和视频的位置信息。

在视觉输入中,将9376×1248分辨率的Picture1、32×256分辨率的Picture2、800×1440分辨率的Picture3、448×736×8s大小的video1都分别通过图像块划分和2D-RoPE二维旋转位置编码将数据动态转化为一组长度不一的特征序列,且保留了对应的视觉数据的原生分辨率信息。
语言模型Qwen3-LM:Qwen3-VL采用一个Qwen3语言模型架构作为其基础组件,分别采用三种稠密变体(Qwen3-VL-2B/4B/8B/32B)和两种 MoE 变体(Qwen3-VL-30B-A3B、Qwen3-VL-235B-A22B),均基于 Qwen3 骨干网络构建。
视觉编码器ViT:Qwen3-VL采用SigLIP-2 架构作为视觉编码器,并基于官方预训练检查点进行初始化,使用动态输入分辨率继续对其进行训练。为了有效地适应动态分辨率,论文采用 2D-RoPE,并遵循 CoMP 的方法,根据输入大小对绝对位置嵌入进行插值。默认使用 SigLIP2-SO-400M 变体,并针对小规模 LLM(2B 和 4B)使用 SigLIP2-Large (300M)。
视觉-语言融合器MLP:与Qwen2.5-VL一样集成在语言模型的Transformer层中,先使用一个两层MLP将来自视觉编码器的2×2视觉特征压缩为单个视觉 token,使用DeepStack机制将视觉特征与语言特征进行对齐。
1、Interleaved MRoPE 交错多模态旋转位置嵌入

传统MRoPE按轴切分维度的方式,将嵌入维度划分为时间、高度、宽度三个独立的子空间,每个子空间分配不同的旋转频率。这种同质性虽然简单,但导致了频谱分配的不均衡。
Interleaved MRoPE摒弃了按轴切分的方式,采用细粒度轮转分配策略。在任何单一时间点上,模型用于位置编码的特征维度是不同轴的频率混合。确保了在整个时间序列上,时间、高度、宽度的频谱信息被均匀、平衡地编织到模型的每一个位置表示中。
打破了传统MRoPE中某个维度,尤其是WH空间维度可能长时间主导位置编码的局面,迫使模型在任何时候都必须同时关注并融合多个轴的信息,从而实现了更鲁棒的长程依赖建模和更均衡的频谱覆盖。
2、DeepStack 深度堆叠机制

DeepStack并非一个独立网络,而是一种多层级ViT特征融合机制,用于增强视觉编码器对图像细节的捕捉能力和图文对齐精度。
DeepStack先从ViT视觉编码器的三个不同层级中分别提取出多层级视觉特征输出,分别代表浅层、中层和深层的视觉特征图。
通过一个VisionPatchMerger模块对视觉特征进行处理,先将视觉编码器输出的高分辨率图像patch块进行相邻2×2合并,减少视觉序列的长度,再通过归一化和MLP多层感知机等操作,将视觉特征的维度和数据分布转换到与语言模型文本特征相匹配的特征空间,便于两者后续无缝结合。
通过VisionPatchMerger模块将各层特征映射到与LLM隐藏层一致的维度后,再使用残差连接将这些特征逐层注入到语言模型的对应层级的文本隐藏状态中,使其与语言模型的隐藏维度对齐。而不是仅使用视觉编码器的最后一层输出与语言模型进行特征融合。
3、Video Timestamp 视频时间戳
在 Qwen2.5-VL 中,采用了一种绝对时间同步的MRoPE变体来赋予模型时间感知能力,但是存在两个主要局限性:
通过将时间位置 ID 直接与绝对时间绑定,该方法会在长视频中产生过大且稀疏的时间位置 ID,从而降低模型理解长时序上下文的能力。
在该方案下进行有效学习需要跨各种帧率进行广泛且均匀分布的FPS采样,这显著增加了训练数据构建的成本。
使用Qwen3-VL不再使用Qwen2.5-VL中的绝对时间同步MRoPE方法,而是将时间信息转化为显式文本token插入到输入序列中。
每个视频时间片段前添加固定格式的文本时间戳,生成<3.0 seconds>秒制时间戳或<00:00:02>HMS格式时间戳,并在训练过程中混合使用秒制和HMS两种时间格式,确保模型能够理解多样化的时间表示
用显式时间戳 token 替换了 Qwen2.5-VL 中使用的通过位置编码进行的绝对时间对齐来标记帧组,提供了更简单、更直接的时间表示。
先将视频被分割为时间块,再给每个块前面添加对应时间戳标记,后面再跟视觉标记序列,虽然这种方法导致上下文长度适度增加,但能使模型能够更有效、更精确地感知时间信息,从而促进如视频定位和密集描述等时间感知视频任务。
4、训练流程
Qwen3-VL的视觉编码器是基于预训练的 SigLIP-2 模型,通过进行动态分辨率的持续训练来增强视觉编码器。整体 Qwen3-VL 模型采用三模块架构,包含该视觉编码器、基于 MLP 的视觉-语言融合器以及 Qwen3 大语言模型骨干。
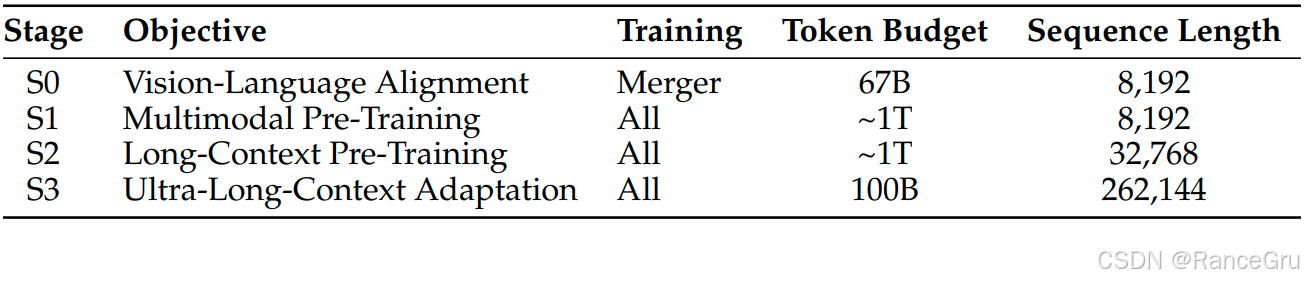
在第一阶段Vision-Language Alignment视觉-语言对齐预训练中,冻结ViT视觉编码器和语言模型Qwen2.5-LM模型参数,仅训练MLP视觉-语言融合模块。利用了一个包含大约67B token 的精选数据集,该数据集由高质量的图像-描述对、视觉知识集合以及OCR数据组成。所有训练均在序列长度为8192的情况下进行。这种对齐优先的方法在进行全参数训练之前为跨模态理解奠定了坚实的基础。
在第二阶段的Multimodal Pre-Training多模态任务预训练中,解冻所有模型参数。并在1T token的多模态图像数据上训练模型,以增强其处理复杂视觉信息的能力。这些数据集加强了模型在视觉和语言模态之间建立深层连接的能力,使其能够处理日益复杂的任务。序列长度保持在8192。
在第三阶段的Long-Context Pre-Training长上下文预训练中,解冻所有模型参数。将序列长度增加至四倍,进一步增强模型在长序列上的推理能力,同时引入视频和基于代理的数据,并增加序列长度。序列长度从第一阶段和第二阶段的8192增加到第三阶段的32768,通过延长序列长度,模型能够处理更长的上下文,这对于需要长期依赖和复杂推理的任务特别有利。
在第四阶段的Ultra-Long-Context Adaptation超长上下文预训练中,解冻所有模型参数。将模型的上下文窗口拓展至其运行极限,序列长度从第三阶段的32768增加到第四阶段的262144。数据由纯文本数据和视觉-语言数据组成,并重点侧重于长视频和长文档理解任务。适应巩固Qwen3-VL在处理和分析极长序列输入方面的能力,这对于综合文档分析和长视频摘要等应用而言是一项关键能力。
在第五阶段的SFT监督微调后训练中,冻结ViT视觉编码器参数,仅训练语言模型Qwen3-LM模型和MLP视觉-语言融合模块。通过使用了一个精心设计的数据集和有针对性的指令优化,弥补预训练表示与下游任务需求之间的差距,让模型能够理解复杂的人类指令,并按照要求的格式和内容生成回应。在SFT初始阶段先在32k上下文长度下进行微调,随后扩展到256k上下文窗口,专注于长文档和长视频数据。除此之外,还将训练数据分为用于非思考模型的标准格式和用于思考模型的思维链 (CoT) 格式,从而引出和精炼复杂的推理能力。
在第六阶段的Strong-to-Weak Distillation强对弱蒸馏中,强大的教师模型将其能力迁移至论文的学生模型,先通过Off-policy Distillation异策略蒸馏,让教师模型生成的输出被组合以提供响应蒸馏,使得轻量级学生模型能够获取基础推理能力。然后使用On-policy Distillation同策略蒸馏,使得学生模型能够基于提供的提示词生成响应,从而微调学生模型。
在第七阶段的RL强化学习训练中,冻结ViT视觉编码器参数,仅训练语言模型Qwen3-LM模型和MLP视觉-语言融合模块。采用了一种多任务 RL 范式,一方面通过评估模型对明确用户指令的遵循情况,另一方面对于开放式或主观查询,该维度通过优化有用性、事实准确性和风格适宜性,使模型的输出与人类偏好对齐。RL 过程的反馈通过结合两种互补方法的混合奖励系统来传递:
Rule-Based Rewards基于规则的奖励:该方法为具有可验证真值的任务(如格式遵循和指令遵循)提供明确且高精度的反馈。通过使用定义明确的启发式方法,该方法提供了一种评估正确性的稳健机制,并有效缓解了奖励黑客行为,即模型可能会利用学习到的奖励函数中的歧义。
Model-Based Rewards基于模型的奖励:该方法采用 Qwen2.5-VL-72B-Instruct 或 Qwen3 作为高级裁判。裁判模型对照基准真实参考评估每个生成的响应,并在多个维度上对其质量进行评分。对于严格的基于规则的匹配显得不足的那些具有细微差别或开放式的任务,该方法提供了卓越的灵活性。它在最小化假阴性方面特别有效,这些假阴性原本会惩罚具有非常规格式或措辞的有效响应。
五、Qwen3.5-VL
未完待续。。。
总结
在以上论文中可以看见Qwen-VL的核心工作聚焦在视觉编码器、基于MLP的视觉-语言融合模块、语言模型,以及训练工程上。如何提取更好更深的视觉特征,如何学习更丰富更详细的语义特征,如何更好的融合文本和图像之间的特征信息,如何通过有效的训练手法和完善的样本数据去训练模型去完成更复杂的多模态任务,这就是现在Qwen-VL多模态系列的主要贡献。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)