WeMM多模态大模型在MindIE-LLM框架上的迁移适配实践
WeMM 是 WeChatCV 推出的最新一代多模态大语言模型。WeMM 具备动态高分辨率图片下的中英双语对话能力,在多模态大语言模型的榜单中是百亿参数级别最强模型,整体测评结果(Avg Rank)位居第一梯队。本文记录了将WeMM多模态大模型适配到MindIE-LLM推理框架的完整过程,迁移过程中重点解决了模型结构分析、权重转换、Embedding融合和服务化对接等关键技术挑战。
作者:昇腾实战派 x 哒妮滋
关注公众号:AI模力圈
背景概述
WeMM 是 WeChatCV 推出的最新一代多模态大语言模型。WeMM 具备动态高分辨率图片下的中英双语对话能力,在多模态大语言模型的榜单中是百亿参数级别最强模型,整体测评结果(Avg Rank)位居第一梯队。本文记录了将WeMM多模态大模型适配到MindIE-LLM推理框架的完整过程,迁移过程中重点解决了模型结构分析、权重转换、Embedding融合和服务化对接等关键技术挑战。
模型仓库
视觉大语言模型
| 模型 | 日期 | 下载 | 摘要 |
|---|---|---|---|
| WeMM-Chat-2K-CN | 2024.06.27 | 🤗 HF link | 🚀🚀支持2K分辨率的图片输入 |
| WeMM-Chat-CN | 2024.06.21 | 🤗 HF link | 🚀🚀加强了中英双语对话能力 |
| WeMM-1.2(VL) | 2024.06.09 | 🤗 HF link | 🚀🚀在多模态大语言模型全部基准测试中的百亿参数模型里排名第一 |
软硬件环境
| 软硬件 | 版本 |
|---|---|
| 服务器 | Atlas 800I A2 |
| MindIE | T71 |
| CANN | T63 |
| Pytorch | 2.1.0 |
推理流程梳理
迁移步骤
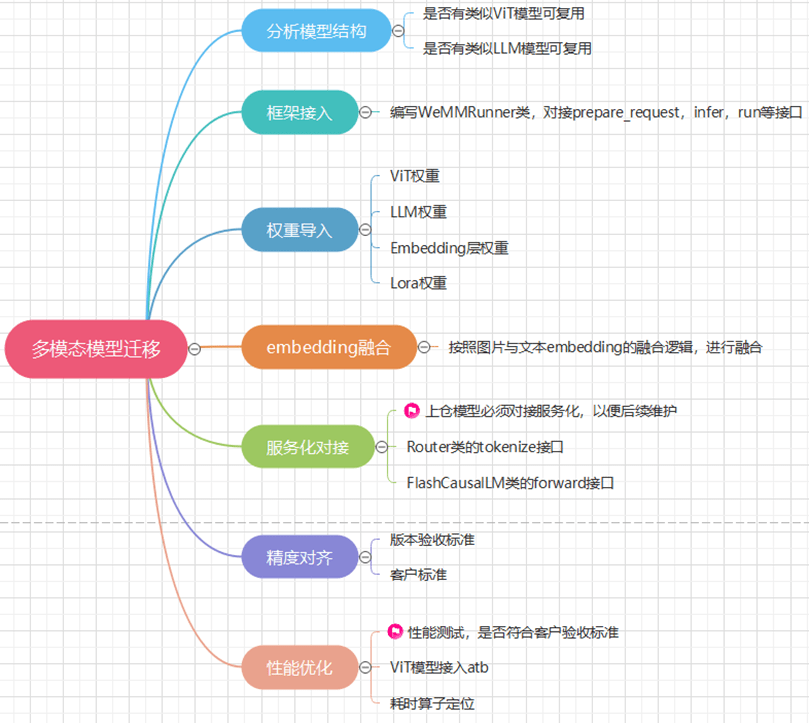
分析模型结构

【分析】:对比MindIE-LLM库中已有的模型结构可知,其中的InternLM-Xcomposer2(浦语·灵笔2)相似,都是用lora微调后的模型,且模型权重中都单独包含了lora权重,而且底层的LLM都为intermlm2。只有ViT部分用的是不同的模型,因此可以复用该模型的框架。
框架接入
WeMMRunner类,继承MultimodalPARunner,重写init_processor、precision_save、infer方法
class WeMMRunner(MultimodalPARunner):
def __init__(self, **kwargs):
self.processor = None
super().__init__(**kwargs)
self.adapter_id = kwargs.get("lora_adapter_id", None)
def init_processor(self):
self.processor = self.model.tokenizer
def precision_save(self, precision_inputs, **kwargs):
all_generate_text_list = precision_inputs.all_generate_text_list
image_file_list = precision_inputs.image_file_list
image_answer_pairs = {}
for image_file, generate_text in zip(image_file_list, all_generate_text_list):
image_answer_pairs[image_file] = generate_text
image_answer_pairs = dict(sorted(image_answer_pairs.items()))
super().precision_save(precision_inputs, answer_pairs=image_answer_pairs)
def infer(self, mm_inputs, batch_size, max_output_length, ignore_eos, **kwargs):
input_texts = mm_inputs.input_texts
image_path_list = mm_inputs.image_path
if len(input_texts) != len(image_path_list):
raise RuntimeError("input_text length must equal input_images length")
if not ENV.profiling_enable:
if self.max_batch_size > 0:
max_iters = math.ceil(len(mm_inputs.image_path) / self.max_batch_size)
else:
raise RuntimeError("f{self.max_batch_size} max_batch_size should > 0, please check")
return super().infer(mm_inputs, batch_size, max_output_length, ignore_eos, max_iters=max_iters)
为了后续在WeMMRunner类复用父类run和``prepare_request`方法,在主函数中预先处理与批处理相关的逻辑。
...
if len(texts) != image_length:
texts.extend([texts[-1]] * (image_length - len(texts)))
remainder = image_length % args.max_batch_size
if remainder != 0:
num_to_add = args.max_batch_size - remainder
image_path.extend([image_path[-1]] * num_to_add)
texts.extend([texts[-1]] * num_to_add)
...
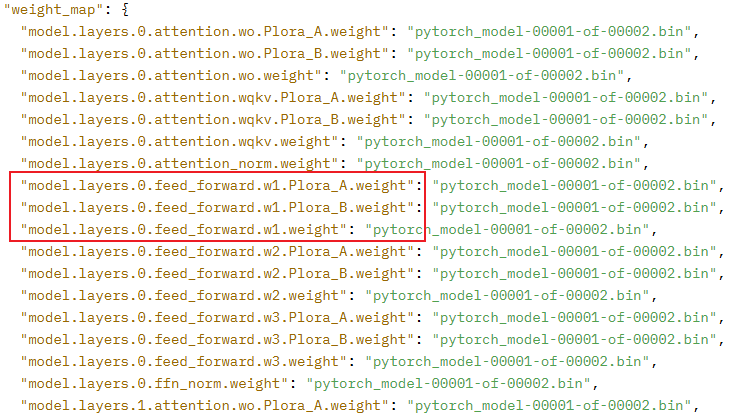
权重导入
InternLM-Xcomposer2的权重命名结构如下图所示:
WeMM-Chat-2k-CN的权重命名结构如下图所示:
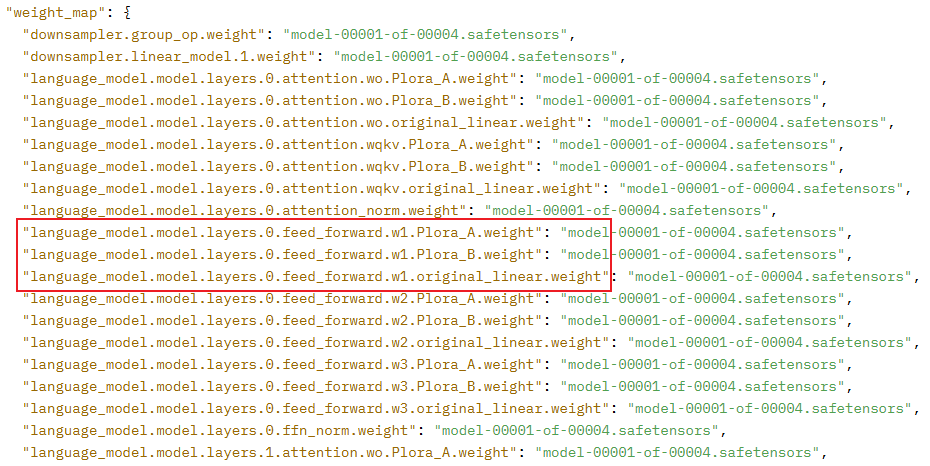
可以发现,两者权重命名风格不一样,WeMM的lora微调前的原始权重命名中多了一个original_linear,而且这个original_linear是插在名字中间,无法通过传入prefix来解决,为了不修改公共组件中的代码(遵循开闭原则),最终选择自写权重重命名脚本,将WeMM的权重中的original_linear去掉后重新保存。
# Copyright Huawei Technologies Co., Ltd. 2023-2024. All rights reserved.
import argparse
import os
from datetime import datetime, timezone
from pathlib import Path
import shutil
from typing import List
import torch
from safetensors.torch import save_file, load_file
from atb_llm.utils.hub import weight_files
from atb_llm.utils.log import logger
from atb_llm.utils import file_utils
from atb_llm.utils.convert import _remove_duplicate_names
MAX_TOKENIZER_FILE_SIZE = 1024 * 1024 * 1024
INFIX_WEIGHT_NAME = "original_linear."
def copy_remaining_files(model_dir, dest_dir):
model_dir = file_utils.standardize_path(model_dir, check_link=False)
file_utils.check_path_permission(model_dir)
if os.path.exists(dest_dir):
dest_dir = file_utils.standardize_path(dest_dir, check_link=False)
file_utils.check_path_permission(dest_dir)
else:
os.makedirs(dest_dir, exist_ok=True)
dest_dir = file_utils.standardize_path(dest_dir, check_link=False)
suffix = '.safetensors'
for filename in file_utils.safe_listdir(model_dir):
if not filename.endswith(suffix):
src_filepath = os.path.join(model_dir, filename)
src_filepath = file_utils.standardize_path(src_filepath, check_link=False)
file_utils.check_file_safety(src_filepath, 'r', max_file_size=MAX_TOKENIZER_FILE_SIZE)
dest_filepath = os.path.join(dest_dir, filename)
dest_filepath = file_utils.standardize_path(dest_filepath, check_link=False)
file_utils.check_file_safety(dest_filepath, 'w', max_file_size=MAX_TOKENIZER_FILE_SIZE)
shutil.copyfile(src_filepath, dest_filepath)
def rename_safetensor_file(src_file: Path, dst_file: Path, discard_names: List[str]):
src_file = file_utils.standardize_path(str(src_file), check_link=False)
file_utils.check_file_safety(src_file, 'r', is_check_file_size=False)
loaded_state_dict = load_file(src_file)
if "state_dict" in loaded_state_dict:
loaded_state_dict = loaded_state_dict["state_dict"]
to_remove_dict = _remove_duplicate_names(loaded_state_dict, discard_names=discard_names)
metadata = {"format": "pt"}
for kept_name, to_remove_list in to_remove_dict.items():
for to_remove in to_remove_list:
if to_remove not in metadata:
metadata[to_remove] = kept_name
del loaded_state_dict[to_remove]
renamed_loaded_state_dict = {}
for k, v in loaded_state_dict.items():
if INFIX_WEIGHT_NAME in k:
k = k.replace(INFIX_WEIGHT_NAME, "")
renamed_loaded_state_dict[k] = v.contiguous()
os.makedirs(os.path.dirname(dst_file), exist_ok=True)
dst_file = file_utils.standardize_path(str(dst_file), check_link=False)
file_utils.check_file_safety(dst_file, 'w', is_check_file_size=False)
save_file(renamed_loaded_state_dict, dst_file, metadata=metadata)
reloaded_state_dict = load_file(dst_file)
for k, pt_tensor in loaded_state_dict.items():
k = k.replace(INFIX_WEIGHT_NAME, "")
sf_tensor = reloaded_state_dict[k]
if not torch.equal(pt_tensor, sf_tensor):
raise RuntimeError(f"The output tensors do not match for key {k}")
def rename_safetensor_files(src_files: List[Path], dst_files: List[Path], discard_names: List[str]):
num_src_files = len(src_files)
for i, (src_file, dst_file) in enumerate(zip(src_files, dst_files)):
blacklisted_keywords = ["arguments", "args", "training"]
if any(substring in src_file.name for substring in blacklisted_keywords):
continue
start_time = datetime.now(tz=timezone.utc)
rename_safetensor_file(src_file, dst_file, discard_names)
elapsed_time = datetime.now(tz=timezone.utc) - start_time
try:
logger.info(f"Rename: [{i + 1}/{num_src_files}] -- Took: {elapsed_time}")
except ZeroDivisionError as e:
raise ZeroDivisionError from e
def rename_weights(model_path, save_directory):
local_src_files = weight_files(model_path, extension=".safetensors")
local_dst_files = [
Path(save_directory) / f"{s.stem}.safetensors"
for s in local_src_files
]
rename_safetensor_files(local_src_files, local_dst_files, discard_names=[])
_ = weight_files(model_path)
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--src_model_path', type=str, help="model and tokenizer path")
parser.add_argument('--save_directory', type=str)
return parser.parse_args()
if __name__ == '__main__':
args = parse_arguments()
model_path = args.src_model_path
save_directory = args.save_directory
input_model_path = file_utils.standardize_path(model_path, check_link=False)
file_utils.check_path_permission(input_model_path)
if not os.path.exists(save_directory):
os.makedirs(save_directory, exist_ok=True)
input_save_directory = file_utils.standardize_path(save_directory, check_link=False)
file_utils.check_path_permission(input_save_directory)
rename_weights(input_model_path, input_save_directory)
copy_remaining_files(input_model_path, input_save_directory)
Embedding融合
WeMM模型作为多模态模型,最终需要将视觉ViT模型处理后的特征和文本Embedding按一定规则融合,最后输入LLM中推理得到最终输出。在flash_causal_wemm.py中的FlashWemmForCausalLM类下实现prepare_inputs_labels_for_multimodal函数。
def prepare_inputs_labels_for_multimodal(
self,
llm,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
clip_embeddings: Optional[torch.FloatTensor] = None
):
if pixel_values is None and clip_embeddings is None:
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"inputs_embeds": None,
"labels": labels,
}
_labels = labels
_attention_mask = attention_mask
if attention_mask is None:
attention_mask = torch.ones_like(input_ids, dtype=torch.bool)
else:
attention_mask = attention_mask.bool()
if labels is None:
labels = torch.full_like(input_ids, IGNORE_INDEX)
input_ids = [
cur_input_ids[cur_attention_mask]
for cur_input_ids, cur_attention_mask in zip(input_ids, attention_mask)
]
labels = [
cur_labels[cur_attention_mask]
for cur_labels, cur_attention_mask in zip(labels, attention_mask)
]
new_inputs_embeds = []
new_labels = []
new_img_masks = []
cur_image_idx = 0
for batch_idx, cur_input_ids in enumerate(input_ids):
num_images = (cur_input_ids == IMAGE_TOKEN_INDEX).sum()
if num_images == 0:
cur_pixel_values = pixel_values[cur_image_idx] if pixel_values is not None else None
cur_clip_emb = clip_embeddings[cur_image_idx] if clip_embeddings is not None else None
cur_inputs_embeds_1 = llm.model.tok_embeddings(cur_input_ids)
if cur_clip_emb is not None and cur_pixel_values is not None:
cur_inputs_embeds = torch.cat(
[cur_inputs_embeds_1, cur_pixel_values[0:0], cur_clip_emb[0:0]], dim=0
)
elif cur_pixel_values is not None:
cur_inputs_embeds = torch.cat([cur_inputs_embeds_1, cur_pixel_values[0:0]], dim=0)
elif cur_clip_emb is not None:
cur_inputs_embeds = torch.cat([cur_inputs_embeds_1, cur_clip_emb[0:0]], dim=0)
else:
raise ValueError
new_inputs_embeds.append(cur_inputs_embeds)
new_labels.append(labels[batch_idx])
new_img_masks.append(torch.zeros(cur_inputs_embeds.shape[0], device=cur_inputs_embeds.device).bool())
cur_image_idx += 1
continue
image_token_indices = (
[-1] + torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0].tolist() + [cur_input_ids.shape[0]]
)
cur_input_ids_noim = []
cur_labels = labels[batch_idx]
cur_labels_noim = []
for i in range(len(image_token_indices) - 1):
cur_input_ids_noim.append(cur_input_ids[image_token_indices[i] + 1 : image_token_indices[i + 1]])
cur_labels_noim.append(cur_labels[image_token_indices[i] + 1 : image_token_indices[i + 1]])
split_sizes = [x.shape[0] for x in cur_labels_noim]
cur_inputs_embeds = llm.model.tok_embeddings(torch.cat(cur_input_ids_noim))
cur_inputs_embeds_no_im = torch.split(cur_inputs_embeds, split_sizes, dim=0)
cur_new_inputs_embeds = []
cur_new_labels = []
cur_img_masks = []
for i in range(num_images + 1):
cur_new_inputs_embeds.append(cur_inputs_embeds_no_im[i])
cur_new_labels.append(cur_labels_noim[i])
cur_img_masks.append(
torch.zeros(cur_inputs_embeds_no_im[i].shape[0], device=cur_inputs_embeds_no_im[i].device).bool()
)
if i < num_images:
cur_pixel_values = pixel_values[cur_image_idx] if pixel_values is not None else None
cur_clip_emb = clip_embeddings[cur_image_idx] if clip_embeddings is not None else None
cur_image_idx += 1
# discrete token embeddings
if cur_pixel_values is not None:
cur_new_inputs_embeds.append(cur_pixel_values)
cur_img_masks.append(
torch.ones(cur_pixel_values.shape[0], device=cur_pixel_values.device).bool()
)
cur_new_labels.append(
torch.full(
(cur_pixel_values.shape[0],),
IGNORE_INDEX,
device=cur_labels.device,
dtype=cur_labels.dtype,
)
)
# clip embeddings
if cur_clip_emb is not None:
cur_new_inputs_embeds.append(cur_clip_emb)
cur_img_masks.append(torch.ones(cur_clip_emb.shape[0], device=cur_clip_emb.device).bool())
cur_new_labels.append(
torch.full(
(cur_clip_emb.shape[0],), IGNORE_INDEX, device=cur_labels.device, dtype=cur_labels.dtype
)
)
cur_new_inputs_embeds = torch.cat(cur_new_inputs_embeds)
cur_new_labels = torch.cat(cur_new_labels)
cur_img_masks = torch.cat(cur_img_masks)
new_inputs_embeds.append(cur_new_inputs_embeds)
new_labels.append(cur_new_labels)
new_img_masks.append(cur_img_masks)
# Combine them
max_len = max(x.shape[0] for x in new_inputs_embeds)
batch_size = len(new_inputs_embeds)
new_inputs_embeds_padded = []
new_labels_padded = torch.full(
(batch_size, max_len), IGNORE_INDEX, dtype=new_labels[0].dtype, device=new_labels[0].device
)
attention_mask = torch.zeros((batch_size, max_len), dtype=attention_mask.dtype, device=attention_mask.device)
new_img_masks_padded = torch.zeros((batch_size, max_len), device=new_img_masks[0].device).bool()
for i, (cur_new_embed, cur_new_labels, cur_new_img_masks) in enumerate(
zip(new_inputs_embeds, new_labels, new_img_masks)
):
cur_new_embed = cur_new_embed[:max_len]
cur_new_labels = cur_new_labels[:max_len]
cur_new_img_masks = cur_new_img_masks[:max_len]
cur_len = cur_new_embed.shape[0]
new_inputs_embeds_padded.append(
torch.cat(
(
cur_new_embed,
torch.zeros(
(max_len - cur_len, cur_new_embed.shape[1]),
dtype=cur_new_embed.dtype,
device=cur_new_embed.device,
),
),
dim=0,
)
)
if cur_len > 0:
new_labels_padded[i, :cur_len] = cur_new_labels
attention_mask[i, :cur_len] = True
new_img_masks_padded[i, :cur_len] = cur_new_img_masks
new_inputs_embeds = torch.stack(new_inputs_embeds_padded, dim=0)
if _labels is None:
new_labels = None
else:
new_labels = new_labels_padded
if _attention_mask is None:
attention_mask = None
else:
attention_mask = attention_mask.to(dtype=_attention_mask.dtype)
prepared_data = {
"input_ids": None,
"attention_mask": attention_mask,
"inputs_embeds": new_inputs_embeds,
"labels": new_labels,
}
# if pixel_values is not None:
prepared_data.update({"im_mask": new_img_masks_padded})
return prepared_data
服务化对接
当前多模态模型优先适配到MindIE-LLM仓上的examples下(后续称为模型侧),多模态模型接入服务化的目的是为了能够通过URL请求后端(MindIE-LLM下的mindie_llm目录下的架构,后续称为自研推理后端)的模型端到端推理,这会涉及到另一个仓MindIE-Service下的组件MindIE-Server(后续称为服务侧)。当前主流的一些三方推理后端包括 Triton、TGI、VLLM和OpenAI,每个推理后端都有各自的URL请求格式。
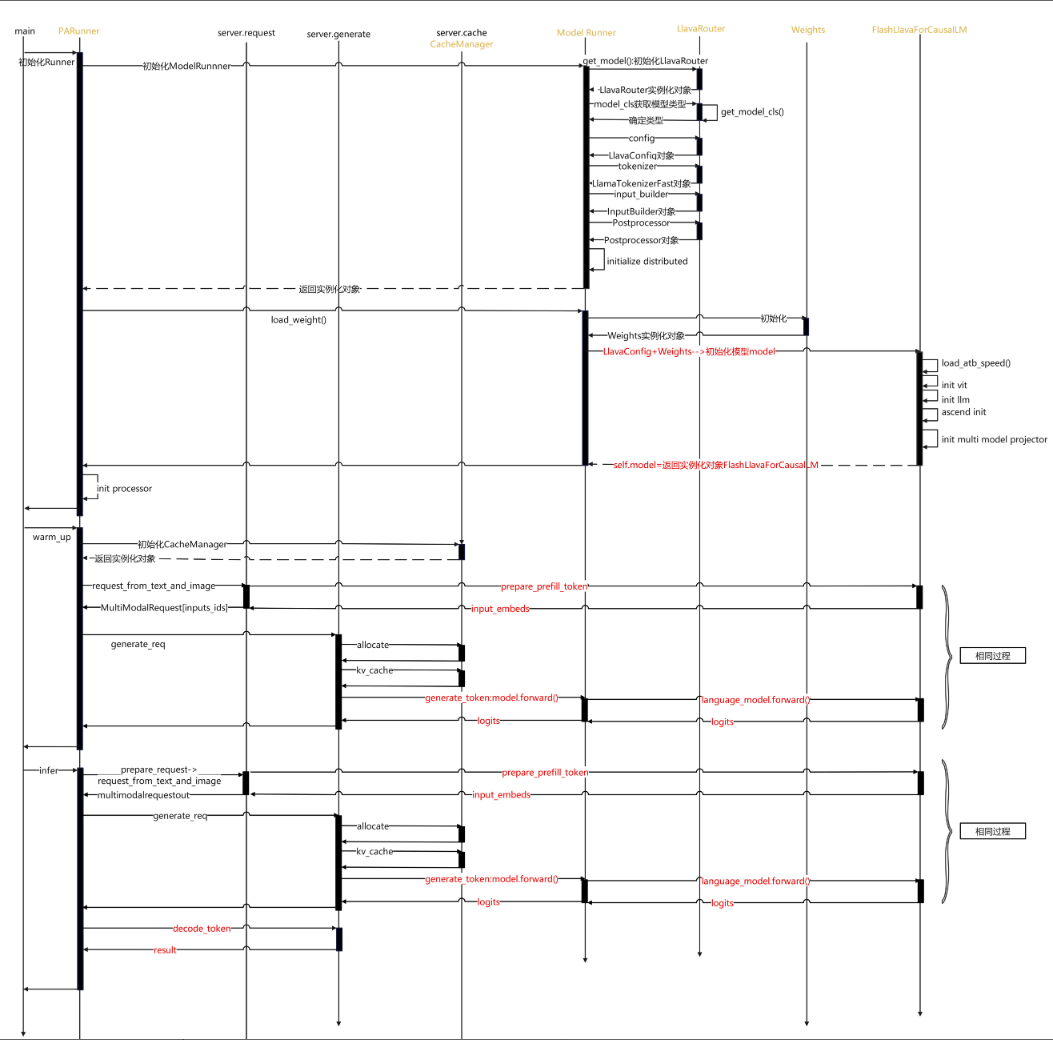
【模型侧 VS 服务化】的推理流程对比(Llava为例)
模型侧推理流程
在模型侧,通常模型的运行是通过脚本执行run_pa.py文件,run_pa.py中通过PARunner类或其子类来控制推理流程:
- 包括
processor的初始化; - 通过
FlashcausalXXX类中实现prepare_prefill_token一类的函数,调用ViT或者其他处理多媒体格式的模型,从而token_ids的生成; - 将
token_ids送入模型forward等操作。
因此模型侧可以在FlashcausalXXX类中实现一些prepare_prefill_token之类的操作供送入forward之前调用,还可以在forward入参中通过kwargs传入其它参数。
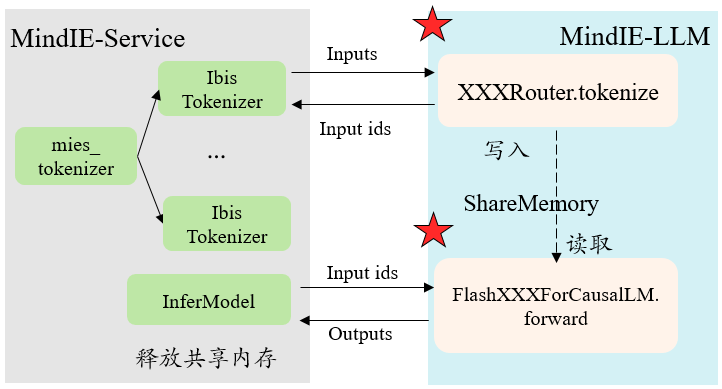
服务化推理流程
与模型侧不同的是,服务侧只会调用推理后端的接口,因此并不会走run_pa.py,也不会调用PARunner类。从对接服务化流程角度简单来说,大概有几个步骤:
- 服务侧会使用多个线程初始化多个
mies_tokenizer下的IbisTokenizer类; - 服务侧收到一个请求之后,首先会调用
IbisTokenizer类中的encode()接口获取input_ids,注意送入tokenize()的是单个Batch; - 得到的
input_ids在自研后端进行continuous batching之后,直接送入相应FlashcausalXXX类的forward。
这里服务化处理输入获得input_ids的途径只有通过encode()接口,这个接口中实际上就是调用了模型侧Router的tokenize()接口,得到input_ids之后就是组batch,之后就直接送入forward()了,这个流程的推动都是有自研后端来负责,作为模型侧适配我们无法感知和更改,因此就无法通过kwargs传入额外的参数。
1.tokenize() 接口实现
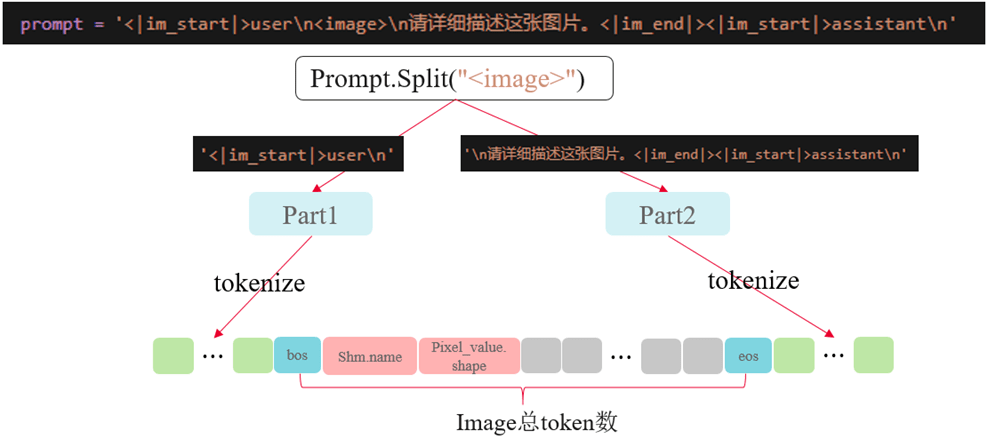

在tokenize()函数中要做以下几件事:
- 对输入
prompt用tokenizer分词后,得到token_ids; - 遍历输入,加载并处理图片数据,计算图片经过
image_preprocessor、ViT等处理后最终转换成的token的数量,进行padding; - 将处理好的
pixel_value数据存入共享内存,注意:1)需要将数据转换为numpy.addray才能存入共享内存;2)dtype不做限制但是在后续读取数据时需要保持一致; - 将共享内存
name和存入数据的shape编码,涉及到的编码函数已提到公共代码中; - 将编码好的
name和shape嵌入input_ids中,返回一维的torch.Tensor(cpu)类型的input_ids。
代码实现
# Copyright Huawei Technologies Co., Ltd. 2024-2028. All rights reserved.
import math
import os
from dataclasses import dataclass
from typing import Any
import numpy as np
import torch
from PIL import Image
from atb_llm.utils.log import logger
from atb_llm.utils.log.error_code import ErrorCode
from atb_llm.utils.shm_utils import encode_shm_name_to_int64, encode_shape_to_int64, create_shm
from atb_llm.utils.multimodal_utils import safe_open_image
from atb_llm.models.base.router import BaseRouter
from atb_llm.models.base.model_utils import safe_get_tokenizer_from_pretrained
from atb_llm.models.wemm.data_preprocess_wemm import recover_navit_subimages_with_pos_emb
from .image_processor_2k import Idefics2ImageProcessor
_IMAGE = "image"
_TEXT = "text"
DEFAULT_IMAGE_TOKEN = "<image>"
IMAGE_TOKEN_INDEX = -200
DEFAULT_IMAGE_BEGIN_TOKEN = "<img>"
IMAGE_BEGIN_TOKEN_INDEX = -300
DEFAULT_IMAGE_END_TOKEN = "</img>"
IMAGE_END_TOKEN_INDEX = -400
EOS_TOKEN_ID = 92542
def process_shared_memory(pixel_values, shm_name_save_path, data_type):
shm = create_shm(pixel_values.nbytes, shm_name_save_path)
shared_array = np.ndarray(pixel_values.shape, dtype=data_type, buffer=shm.buf)
shared_array[:] = pixel_values
shm_name = encode_shm_name_to_int64(shm.name)
shape_value = encode_shape_to_int64(pixel_values.shape)
return shm_name, shape_value
@dataclass
class WemmRouter(BaseRouter):
_image_processor: Any = None
def __post_init__(self):
super().__post_init__()
self.tokenizer.eos_token_id = EOS_TOKEN_ID
@property
def image_processor(self):
if not hasattr(self, "_image_processor"):
self._image_processor = self.get_image_processor()
elif self._image_processor is None:
self._image_processor = self.get_image_processor()
return self._image_processor
def get_config(self):
config_cls = self.get_config_cls()
config = config_cls.from_dict(self.config_dict)
super().check_config(config)
return config
def get_tokenizer(self):
tokenizer = safe_get_tokenizer_from_pretrained(
self.tokenizer_path,
revision=self.revision,
padding_side="left",
trust_remote_code=self.trust_remote_code,
use_fast=True,
)
return tokenizer
def get_image_processor(self):
return Idefics2ImageProcessor(self.config.image_processor)
def tokenize(self, inputs, **kwargs):
text = ""
image_num = sum(1 for d in inputs if _IMAGE in d)
shm_name_save_path = kwargs.get("shm_name_save_path", None)
if image_num > 1:
logger.error("Input image numbers can not be greater than 1!", ErrorCode.ATB_MODELS_PARAM_OUT_OF_RANGE)
raise KeyError("Input image numbers can not be greater than 1!")
for single_input in inputs:
if single_input.get(_TEXT, None):
text = single_input.get(_TEXT)
continue
if single_input.get(_IMAGE, None):
image_path = single_input[_IMAGE]
if shm_name_save_path is None:
shm_name_save_dir = os.path.dirname(os.path.dirname(image_path))
shm_name_save_path = os.path.join(shm_name_save_dir, "shm_name.txt")
image_obj = None
image_obj = safe_open_image(Image, image_path)
if image_obj is None:
raise ValueError(f"Unrecognized image path input, only support local path, got {image_path}")
image_rgb = image_obj.convert("RGB")
image_size = self.config.image_processor["size"]
navit980_images = self.image_processor(
[[image_rgb]],
size=image_size,
return_tensors="pt",
do_image_splitting=self.config.do_image_splitting,
)
image_obj.close()
dim = navit980_images["navit_pixel_values"].shape
patch_size = self.config.vision_config.patch_size
visual_dim = math.ceil(dim[2] / patch_size) * math.ceil(dim[3] / patch_size)
clip_visual_outputs_fake = torch.ones(
(dim[0], visual_dim, self.config.vision_config.hidden_size), dtype=torch.float16
)
super_image_hidden_states, _, _ = recover_navit_subimages_with_pos_emb(
clip_visual_outputs_fake,
navit980_images["pixel_attention_mask"],
num_sub_images=-1,
visual_embedding_group=16,
pos_hidden_size=4096,
thumbnail_only=True,
)
img_token_num = math.ceil(super_image_hidden_states.shape[1] / 4) * math.ceil(
super_image_hidden_states.shape[2] / 4
)
values_shm_name, values_shape_value = process_shared_memory(
navit980_images["navit_pixel_values"], shm_name_save_path, np.float32
)
mask_shm_name, mask_shape_value = process_shared_memory(
navit980_images["pixel_attention_mask"], shm_name_save_path, np.bool8
)
else:
logger.error(
"The input field currently only needs to support 'image' and 'text'.",
ErrorCode.ATB_MODELS_PARAM_OUT_OF_RANGE,
)
raise TypeError("The input field currently only needs to support 'image' and 'text'.")
prompt = "<image>" + "\n" + text
prompt = f"<|im_start|>user\n{prompt}<|im_end|><|im_start|>assistant\n"
chunk_encode = []
for idx, chunk in enumerate(prompt.split(DEFAULT_IMAGE_TOKEN)):
if idx == 0:
cur_encode = self.tokenizer.encode(chunk)
else:
cur_encode = self.tokenizer.encode(chunk, add_special_tokens=False)
chunk_encode.append(cur_encode)
if len(chunk_encode) != 2:
raise ValueError("The length of chunk_encode should be 2")
ids = []
for idx, cur_chunk_encode in enumerate(chunk_encode):
ids.extend(cur_chunk_encode)
if idx != len(chunk_encode) - 1:
ids.append(IMAGE_BEGIN_TOKEN_INDEX)
ids.extend([IMAGE_TOKEN_INDEX] * img_token_num)
ids.append(IMAGE_END_TOKEN_INDEX)
input_ids = torch.tensor(ids)
bos_pos = torch.where(torch.eq(input_ids, IMAGE_BEGIN_TOKEN_INDEX))[0]
if input_ids.size(0) < bos_pos + 5:
msg = "tokenize error, input_ids length is too short."
logger.error(msg, ErrorCode.ATB_MODELS_PARAM_OUT_OF_RANGE)
raise ValueError(msg)
input_ids[bos_pos + 1] = values_shm_name
input_ids[bos_pos + 2] = values_shape_value
input_ids[bos_pos + 3] = mask_shm_name
input_ids[bos_pos + 4] = mask_shape_value
return input_ids
2.forward() 多媒体数据处理
在forward()中,实际就是tokenize()的逆变换:
- 通过特殊的
token找到图片数据的插入位置; - 解码共享内存的
name和数据的shape,从共享内存取出处理好的数据,需要注意get_pixel_value_from_shm()的第三个入参dtype是指存入共享内存时的类型,需要与存入时保持一致才能正确取出,这个函数返回tensor; - 将上一步取出的
pixel_value送入ViT得到image embedding; - 将
image embedding和text embedding融合后送入LLM。
def prepare_prefill_token_service(self, ids):
if not torch.any(torch.eq(ids, IMAGE_BEGIN_TOKEN_INDEX)):
inputs_embeds = self.language_model.model.tok_embeddings(ids)
self.im_mask = torch.zeros(inputs_embeds.shape[0], 1, device=inputs_embeds.device).to(torch.float16)
return inputs_embeds
bos_pos = torch.where(torch.eq(ids, IMAGE_BEGIN_TOKEN_INDEX))[0]
eos_pos = torch.where(torch.eq(ids, IMAGE_END_TOKEN_INDEX))[0]
values_shm_name = ids[bos_pos + 1]
values_shape_value = ids[bos_pos + 2]
mask_shm_name = ids[bos_pos + 3]
mask_shape_value = ids[bos_pos + 4]
navit980_images = {}
navit980_images["navit_pixel_values"] = get_data_from_shm(
values_shm_name, values_shape_value, np.float32, self.device
)
navit980_images["pixel_attention_mask"] = get_data_from_shm(
mask_shm_name, mask_shape_value, np.bool8, self.device
)
merged_visual_embeddings = merge_visual_embed(
navit980_images, self.vision_tower, self.downsampler, self.visual_source_spliter_emb
)
pixel_values = None
in_ids = []
in_ids.extend(ids[:bos_pos].cpu().numpy().tolist())
in_ids.append(IMAGE_TOKEN_INDEX)
in_ids.extend(ids[eos_pos + 1 :].cpu().numpy().tolist())
in_ids = torch.tensor(in_ids).npu().unsqueeze(0)
mm_inputs = self.prepare_inputs_labels_for_multimodal(
llm=self.language_model,
input_ids=in_ids,
pixel_values=pixel_values,
clip_embeddings=merged_visual_embeddings,
)
self.im_mask = mm_inputs.get("im_mask", None)
if self.im_mask is not None:
self.im_mask = self.im_mask.view(1, -1)
self.im_mask = self.im_mask.squeeze(0).unsqueeze(-1).to(torch.float16)
inputs_embeds = mm_inputs.get("inputs_embeds", None)
inputs_embeds = inputs_embeds.view(inputs_embeds.shape[0] * inputs_embeds.shape[1], inputs_embeds.shape[2])
return inputs_embeds
def forward(
self,
input_ids: torch.Tensor,
position_ids: torch.Tensor,
is_prefill: bool,
kv_cache: List[Tuple[torch.Tensor, torch.Tensor]],
block_tables: torch.Tensor,
slots: torch.Tensor,
input_lengths: torch.Tensor,
max_seq_len: int,
lm_head_indices: Optional[torch.Tensor] = None,
**kwargs,
):
self.language_model.adapter_manager = self.adapter_manager
kwargs.update({"adapter_ids": ["wemm"]})
if is_prefill and input_ids.dim() == 1:
inputs_embeds = self.prepare_prefill_token_service(input_ids)
else:
inputs_embeds = input_ids
return self.language_model.forward(
inputs_embeds,
position_ids,
is_prefill,
kv_cache,
block_tables,
slots,
input_lengths,
max_seq_len,
lm_head_indices,
im_mask=self.im_mask,
**kwargs,
)
迁移时遇到的问题
Token数量预计算问题
**问题描述:**在WemmRouter一侧,由于无法调用ViT等图片处理相关模型,比较难计算最终图片的Token数,所以想通过插入1个占位符,到FlashWemmForCausalLM这一侧再处理图片。但是在模型侧forward()函数的输入position_ids、kv_cache、block_tables等参数都需要根据tokenize() 返回的input_ids的大小来计算分配。
**解决办法:**在tokenize()函数中提前计算好图片的token数,再通过特殊token来占位,并且将存放图片Tensor的共享内存文件名称和数据shape两个参数嵌入到占位ids中,供服务侧分配kv_cache等资源和后续模型侧的数据读取。
encode()方法内格式转换问题
**问题描述:**在tokenize()方法中将计算得到的input_ids放到了npu上,但服务侧的IbisTokenizer类下的encode()方法收到Tensor格式的input_ids会把其转成list,导致了转换出错。

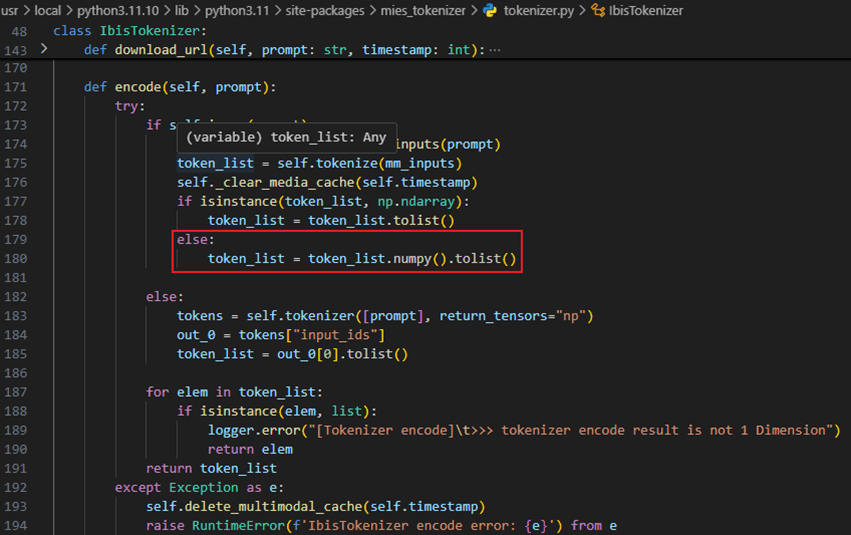
**解决办法:**将tokenize()方法的返回input_ids的device设置成cpu,问题得到解决。
服务化参数传递限制
**问题3:**与纯模型推理不同,服务化推理时,服务侧只会调用推理后端的接口,因此不会走run_pa.py,也不会调用PARunner类,因此无法通过forward()接口的kwargs传入额外的参数,故而传入的lora adapter的id为None,框架使用了默认id:“base”。

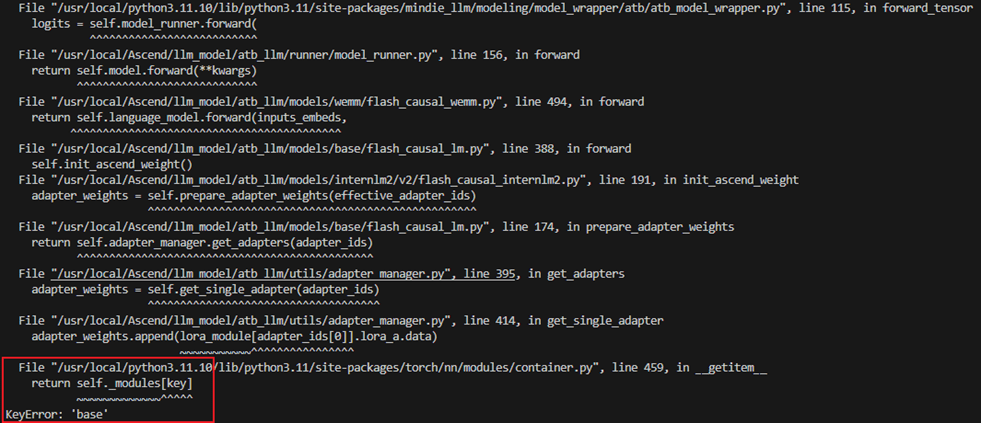
**解决办法:**将forward()接口下判断是否是服务化的prefill阶段,如果是则添加参数{“adapter_ids”:[“wemm”]}。
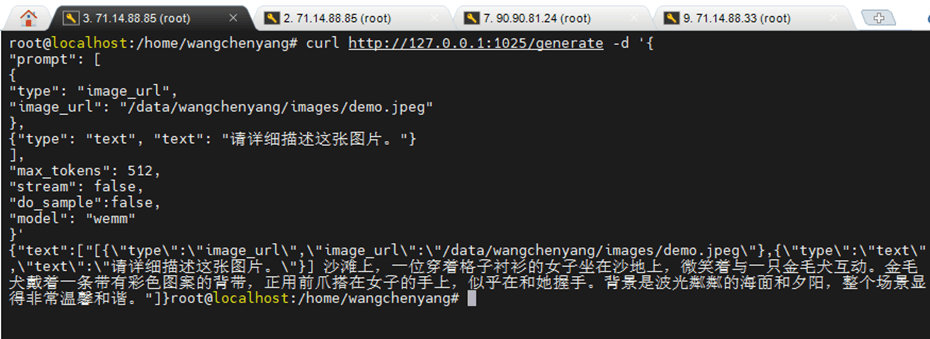
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注【AI模力圈】。
我们会持续更新:
- 多模态模型结构拆解
- 强化学习算法原理与实践
- 昇腾 NPU 迁移部署与踩坑复盘
- 模型训练与推理性能优化
图解版、速读版内容也会同步更新到公众号 / 小红书。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)