AI融入测试提效之测试用例生成
豆包AI初步且简单的需求分析、用例编写、xmind生成。
引言
传统测试用例编写依赖人工经验,效率低且易遗漏边界场景。AI通过自然语言处理与机器学习技术,可自动化分析需求文档、历史用例及代码逻辑,快速生成覆盖更全面的测试用例,显著提升测试效率与质量。
核心方法:需求语义解析
利用NLP模型(如BERT、GPT)解析用户需求文档,提取功能点、输入输出参数及约束条件。通过实体识别与关系抽取技术,将非结构化文本转化为结构化测试要素。例如:
# 示例:基于NLP的需求解析
from transformers import pipeline
nlp = pipeline("text-classification", model="bert-base-uncased")
requirements = "用户登录需验证手机号格式为11位数字"
analysis_result = nlp(requirements) # 输出参数标签:{"action": "verify", "input": "phone", "constraint": "11 digits"}
边界条件自动挖掘
基于代码覆盖率分析工具(如JaCoCo)与变异测试(Mutation Testing),识别代码中的分支路径和异常处理逻辑。结合遗传算法生成边界值组合:
边界值公式:f(x) = {min, min+, normal, max-, max}
历史用例智能复用
通过向量化检索(如FAISS)匹配相似历史用例。将已有测试用例嵌入为高维向量,计算与新需求的余弦相似度,优先复用高匹配度用例并动态调整参数。
输出结构化用例模板
生成符合行业标准(如Gherkin语法)的用例描述,包含前置条件、操作步骤、预期结果三要素。示例:
Scenario: 验证手机号格式
Given 用户进入登录页面
When 输入"1380013800a"
Then 显示错误提示"手机号需为11位数字"
持续优化闭环
建立反馈机制:将测试执行结果(通过/失败)回流至AI模型,通过强化学习动态调整生成策略。重点关注失败用例的根因分析,迭代优化生成。
范例一:使用豆包生成测试用例
-
把原始需求丢给豆包
-
让豆包输出结构化需求分析
-
让豆包输出标准测试用例
-
让豆包输出脑图格式(Markdown 层级)
-
复制到 XMind/ProcessOn 一键生成脑图
【举例子:】
一、发送需求描述或者原型图片给豆包,然后发送以下文字
请对以上需求做正式需求分析,输出:
1. 功能模块
2. 业务规则
3. 输入输出
4. 约束条件
5. 界面/交互要点
发送需求描述文字,截图1示例如下:

【备注】当前生成的需求分许有出入,则需要拆分需求,进行逐个需求描述,结合原型图进行需求分析。
eg:通过自己的需求了解,整理成易理解的输入

二、生成测试用例
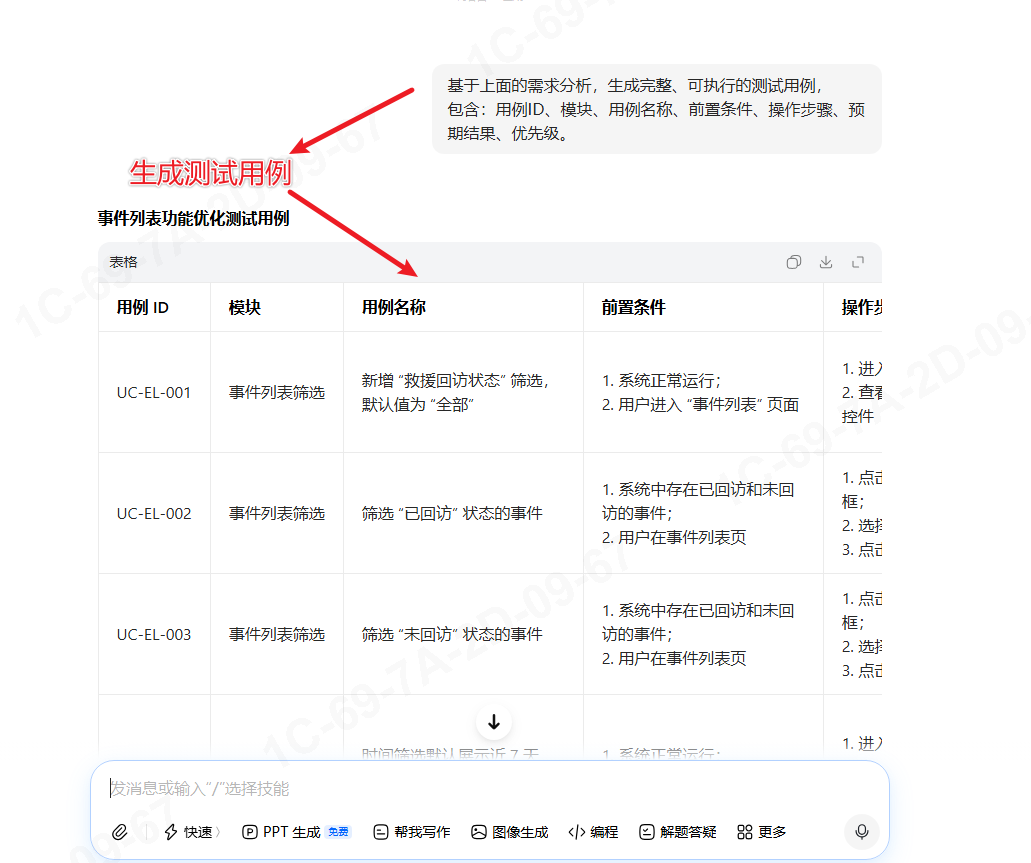
基于上面的需求分析,生成完整、可执行的测试用例, 包含:用例ID、模块、用例名称、前置条件、操作步骤、预期结果、优先级。
生成用例截图如下:
【注意】如果你在这里就想直接获取测试用例,excel模板,可以做以下操作
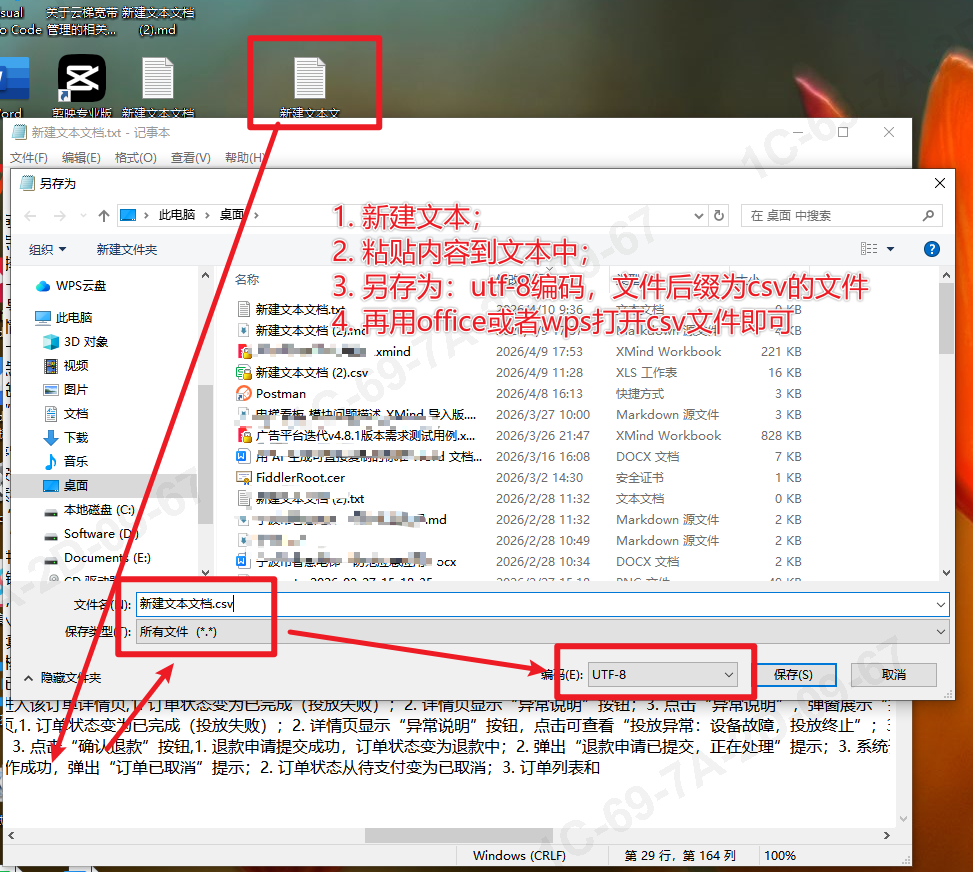
1. WPS/office办公软件工具打开csv文件
若在这一步需要将测试用例导出,可以直接点击下载按钮,导出csv文件,可用WPS直接打开,另存为标准的.xlsx格式。
2. office办公软件打开CSV 纯文本内容
在使用豆包进行需求用例生成过程中,有时候生成的并不是自己想要的;比如这种格式
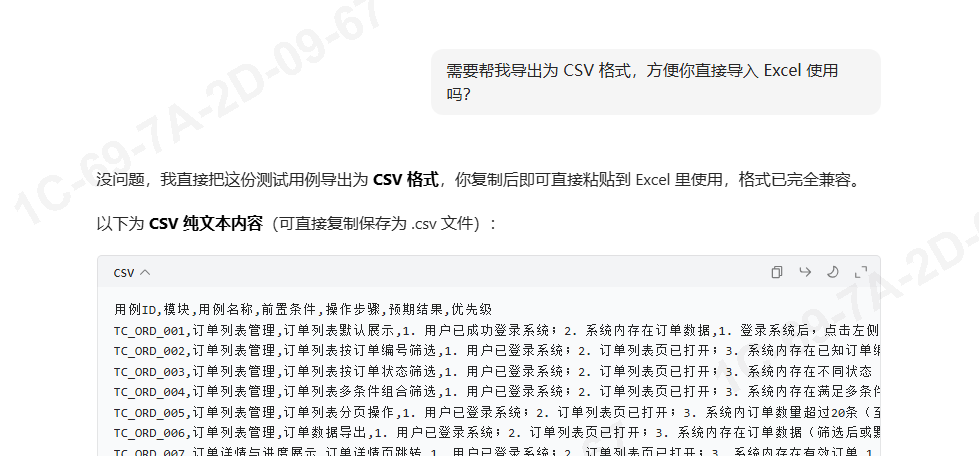
如果生成的是csv纯文本文件,则点击复制,复制到记事本txt,另存为:utf-8编码的csv后缀的文件,最后用wps或者office打开即可。
三、生成脑图大纲
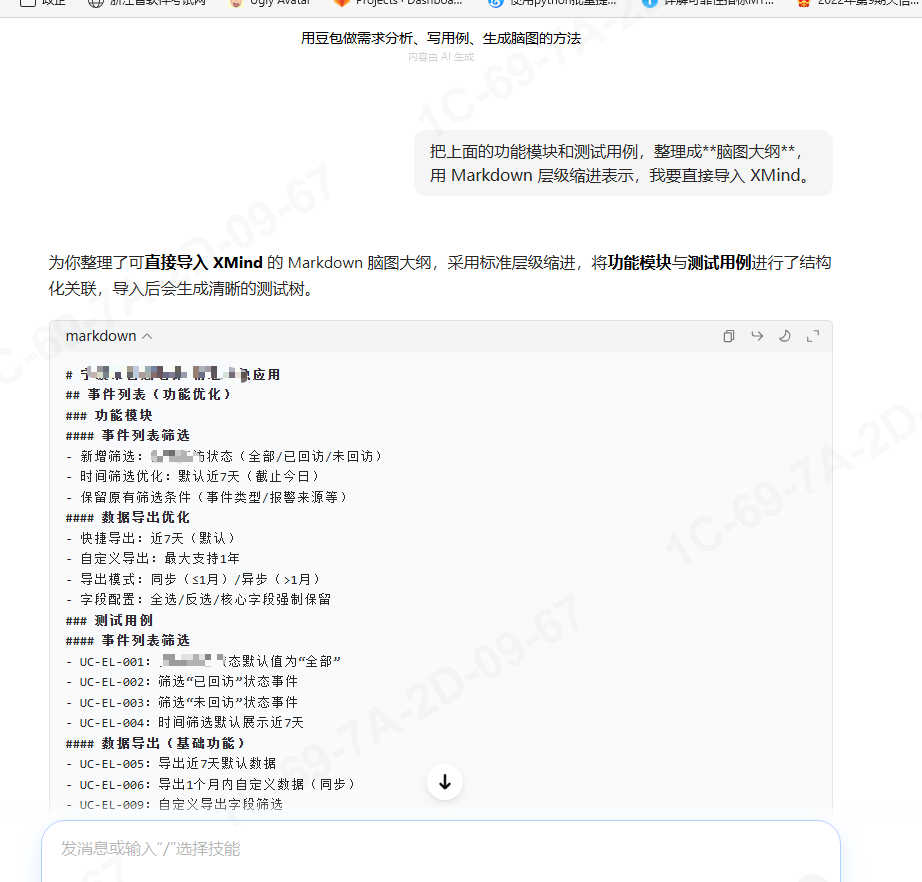
把上面的功能模块和测试用例,整理成**脑图大纲**, 用 Markdown 层级缩进表示,我要直接导入 XMind
生成可直接复制使用的脑图:
四、将生成的文本,复制粘贴到txt记事本中,以utf-8格式保存成md格式文件;再用xmind文件导入打开;再保存成xmind文档。
1. 复制步骤3中的markdown文件,保存文本
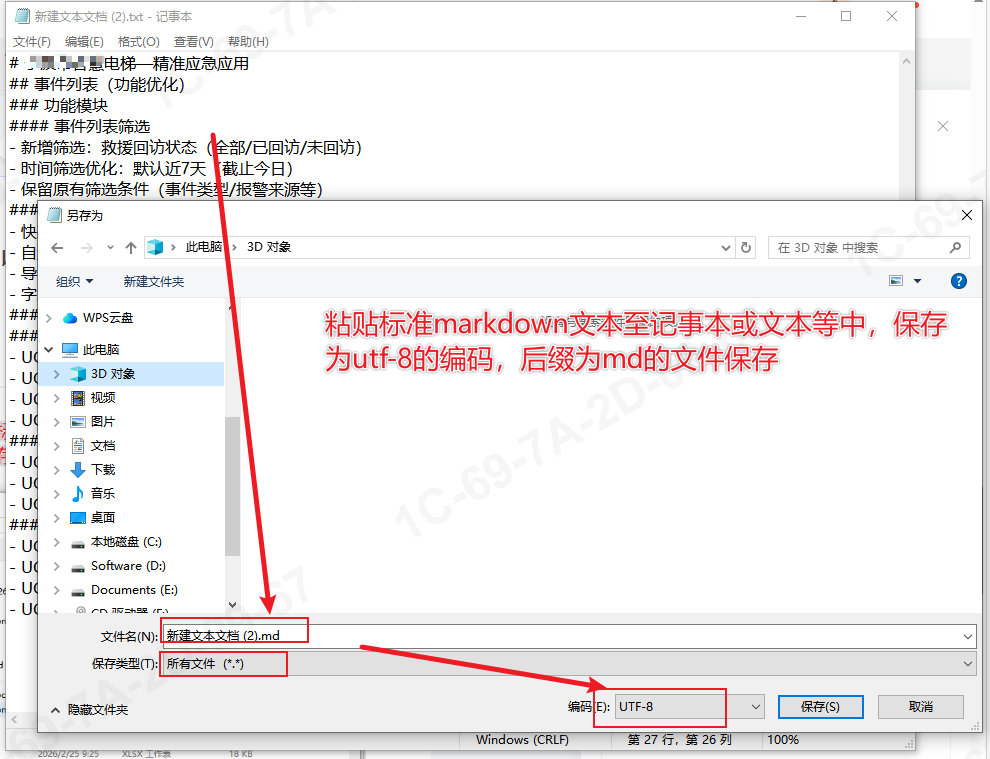
2. xmind工具导入:
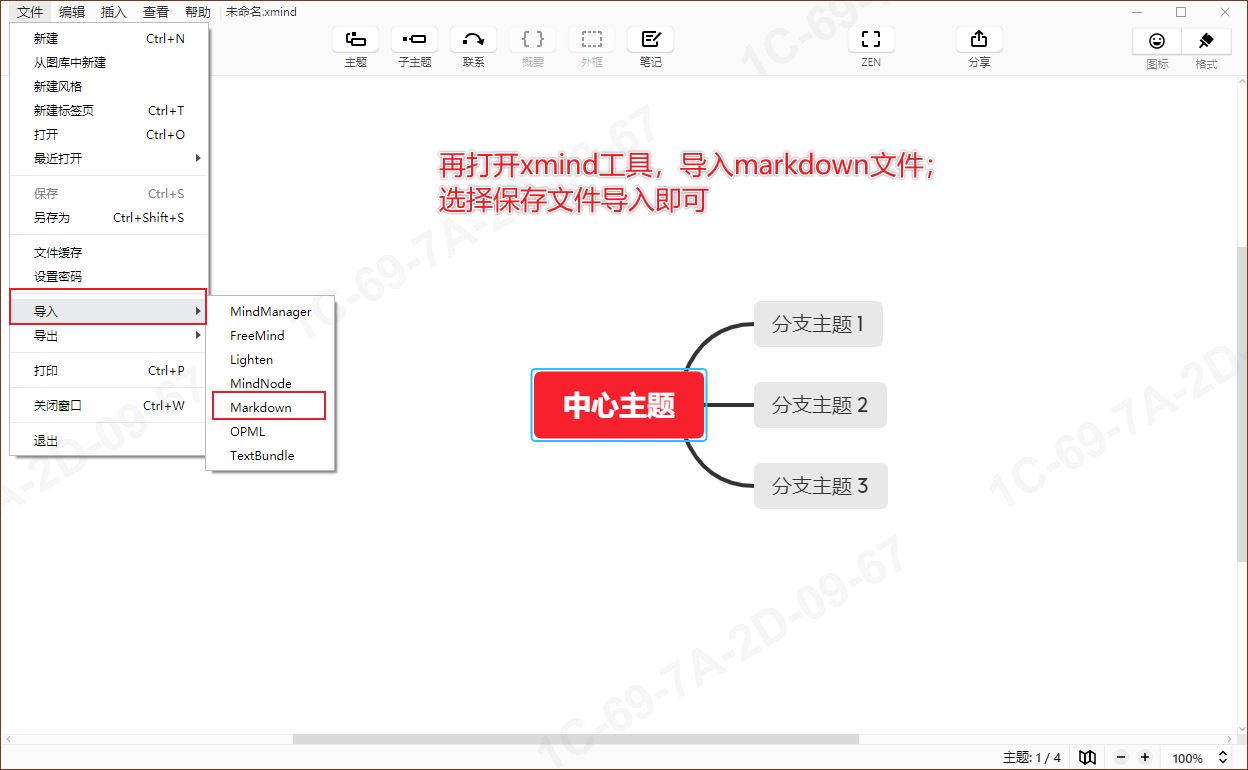
最后导入的效果如下:
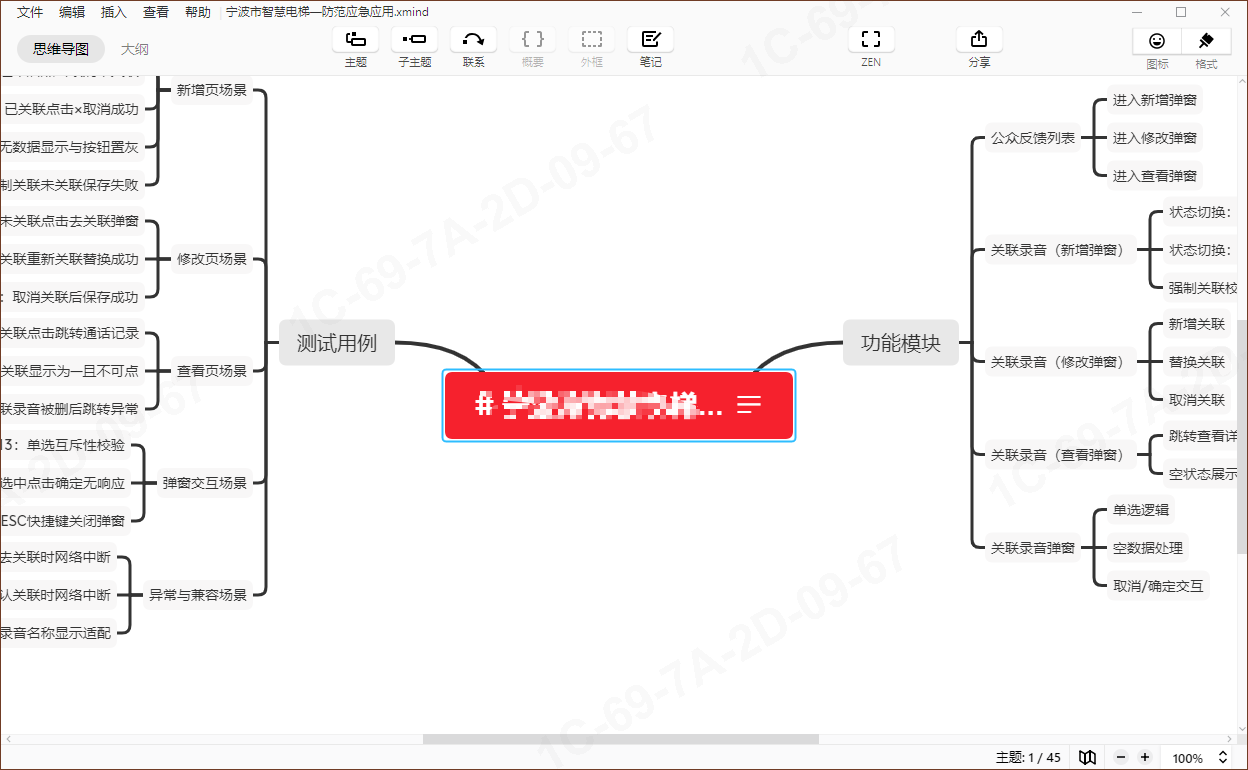
【说明】使用xmind工具导入时,需注意使用的版本,本人用的版本是: 可直接导入生成。如果用processon,方法一样,但保存xmind格式文本,需要开通会员。
可直接导入生成。如果用processon,方法一样,但保存xmind格式文本,需要开通会员。
总结:使用AI进行需求分析,生成用例以及思维导图,简单明了的需求准确率较高,可以替代普通测试的用例的输出时间,提高测试效率;但涉及到复杂业务场景,则需要不断的修正喂养,其耗时也不少。AI能替代简单重复性的需求分析,用例生成;但涉及深层次的需求分析则需要测试把关。测试后续将持续性针对AI提效相关进行了解学习。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)